Сейчас проходит соревнование ML Boot Camp, в котором надо спрогнозировать время, за которое будут перемножены 2 матрицы размерами mxk и kxn на данной вычислительной системе, если известно, сколько решалась эта задача на других вычислительных системах с другими размерами матриц (точные правила). Давайте попробуем решить эту задачу регресии не с помощью стандартных инструментов и библиотек (R, Python и panda), а используя облачный продукт от Microsoft: Azure ML. Для наших целей подойдет бесплатный доступ, для которого достаточно даже trial Azure аккаунта. Все, кто хочет получить краткое руководство по настройке и использованию Azure ML в общем и ML Studio в частности на примере решения реальной живой задач, приглашаются под кат.
Откроем ML Studio:
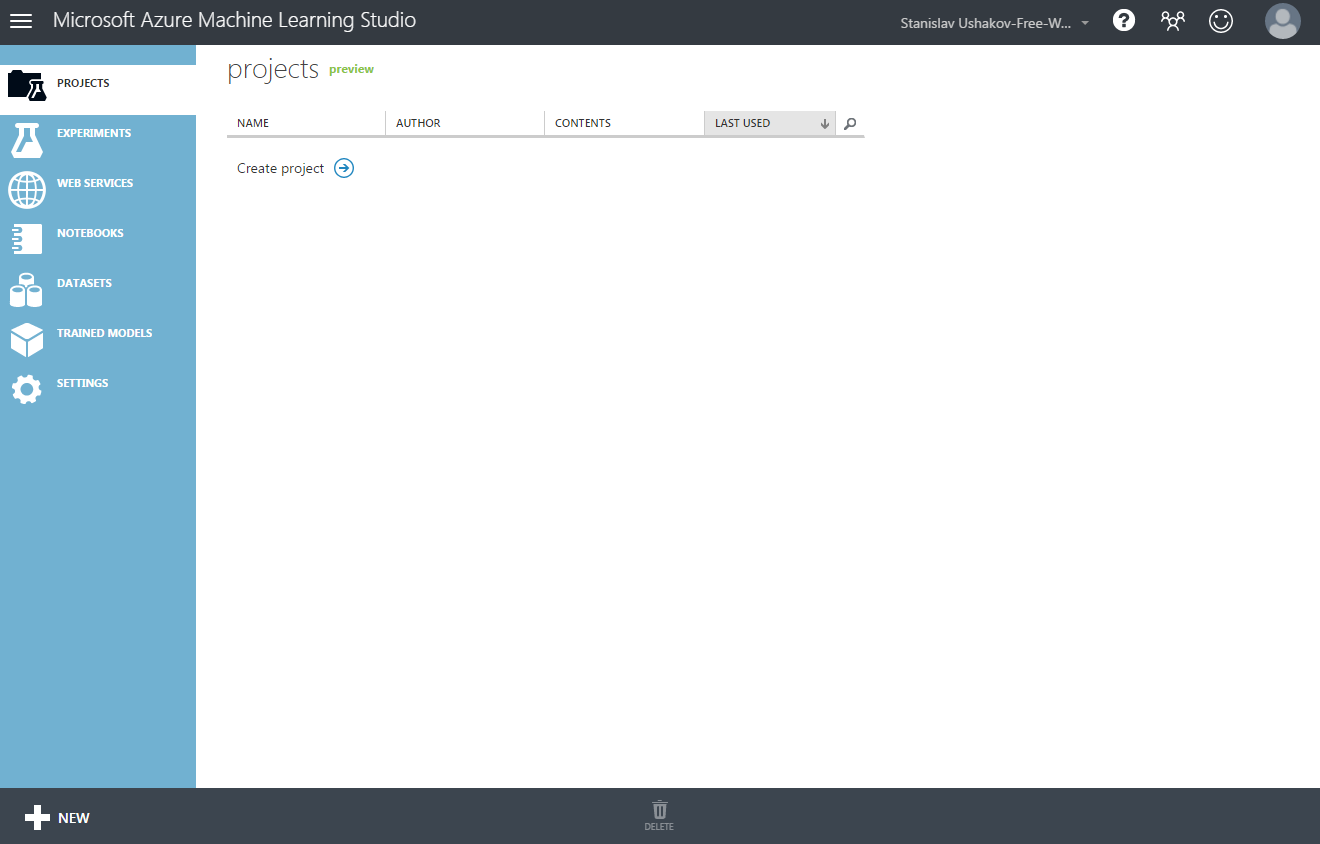
Мы с вами создадим один новый эксперимент (в терминах Azure ML представляет собой законченное решение задачи — от чтения входных данных до получения ответа, затем его можно преобразовать в Web Service) и два новых источника данных (dataset) для представления входных данных (один для набора признаков, другой для значений). Скачайте с сайта ML Boot Camp csv файлы с обучающей выборкой (x_train.csv и y_train.csv). Чтобы добавить источник данных, надо выбрать пункт «Dataset» в меню слева и нажать «New» в левом нижнем углу, появится такое окно:
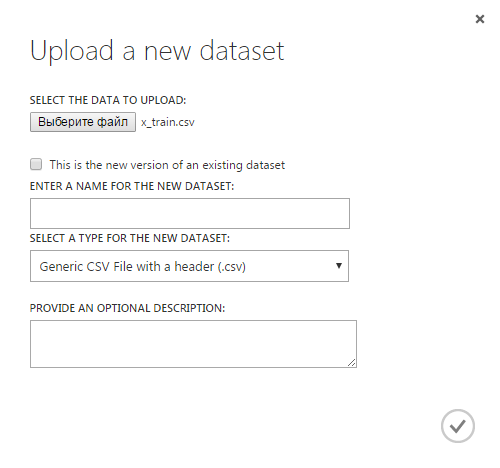
Укажем путь к файлу x_train.csv, дадим этому источнику данных имя x_train. Так же создадим источник данных y_train. Теперь оба этих источника данных показываются на вкладке «Datasets»:

Пришло время создать эксперимент, для этого в меню слева выбираем пункт «Experiments», нажимаем «New» внизу слева и выбираем «Blank Experiment». В строке вверху можно дать ему подходящее имя, в итоге получим следующий простор для наших Data Science операций:
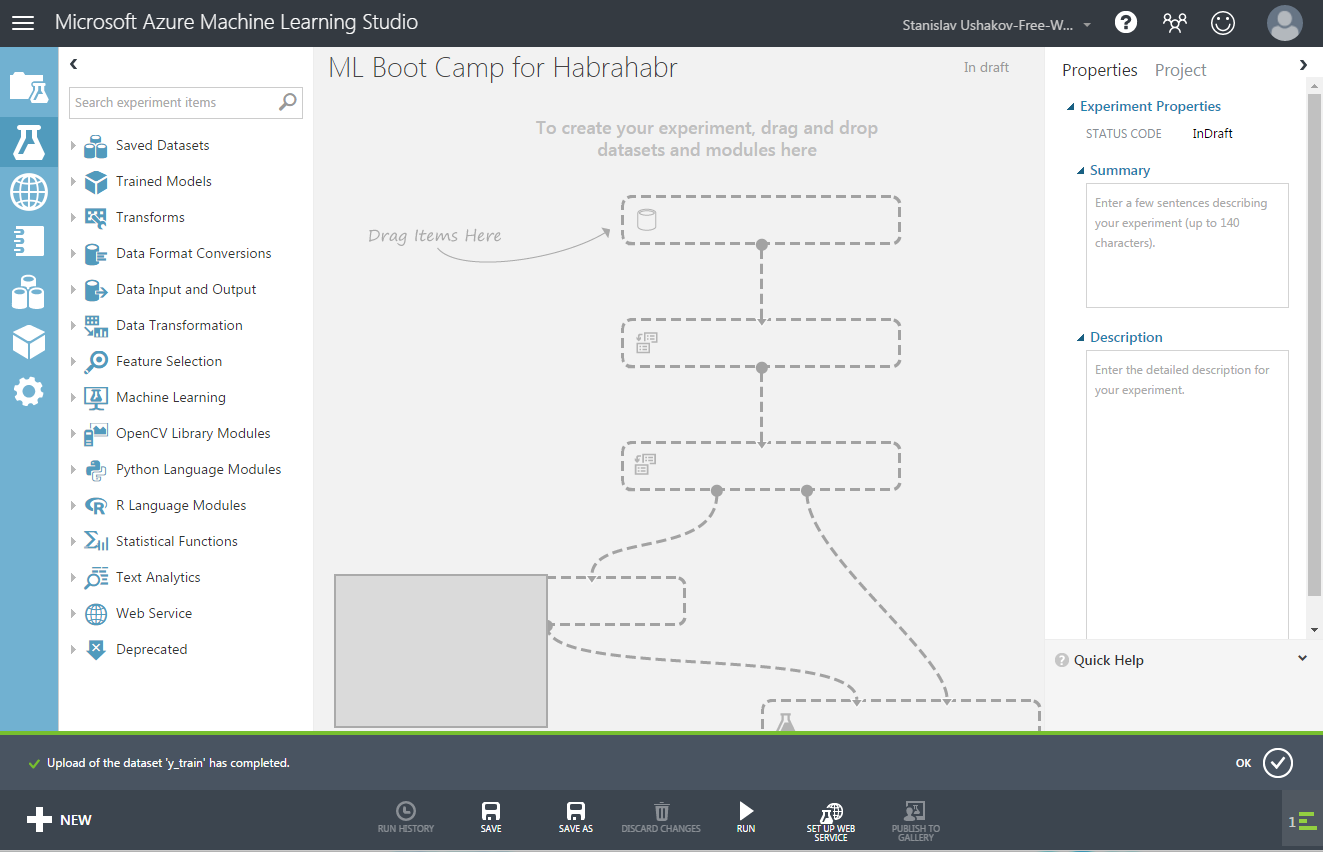
Как вы видите, слева находится меню, в котором перечислены все возможные операции, которые могут быть добавлены в эксперимент, такие как: ввод и вывод данных, выбор столбцов, различные методы регрессии, классификации и т.д. Все они будут добавлять в наш эксперимент путем простого перетаскивания мышью и соединения разных операция между собой.
Теперь нам нужно показать, что мы хотим использовать в качестве входных данных для задачи. В меню слева выберем самый верхний пункт «Saved Datasets», затем «My Datasets», в списке выберем созданные нами источники данных «x_train» и «y_train» и перетащим их в рабочую область эксперимента, в результате получим:

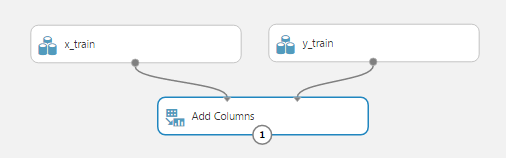
Теперь нам нужно объединить столбцы этих двух источников данных, потому что все методы Azure ML работают с одной таблицей (data frame), в которой надо указать столбец, являющийся значением обучения. Для этого воспользуемся модулем «Add Columns». Подсказка: поиск по модулям поможет найти модуль по ключевым словам или убедиться, что такого модуля еще не существует. Перетащим операцию «Add Columns» в рабочую область и соединим две его верхних точки для ввода данных с нашими источниками данных x_train и y_train соответственно. У этой операции нет параметров, поэтому дополнительно ничего настраивать не надо. Получим:
Чтобы посмотреть, как теперь выглядят наши данные. Запустим эксперимент на выполнение, нажав кнопку «Run» в нижней строке. После того, как эксперимент успешно выполнится, можно нажать на вывод операции «Add Columns» и выбрать действие «Visualize»:
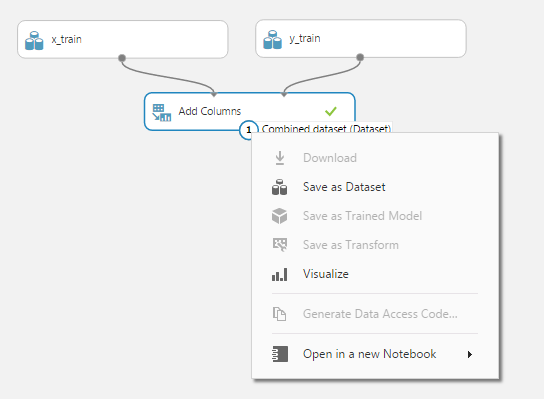

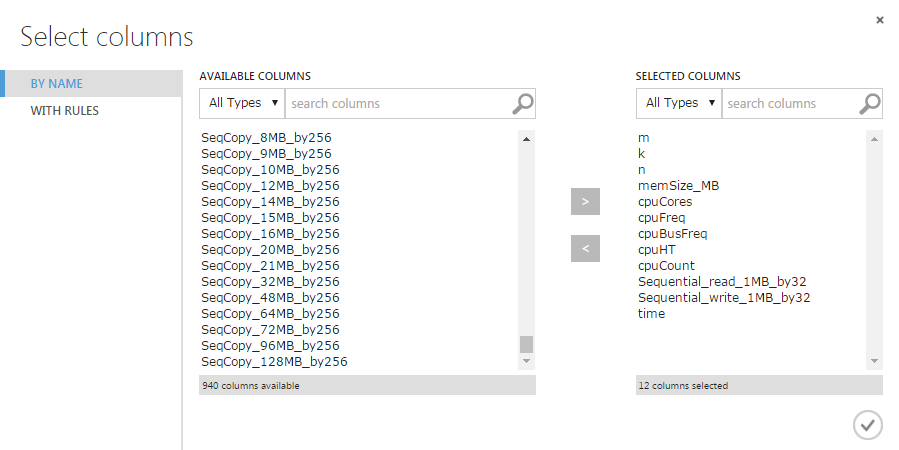
Окно свойств позволяет увидеть столбцы, первые строки, для каждого признака: среднее, медиану, гистограмму и т.д. Мы видим, что в нашей таблице 952 колонки (признака), и из них надо выбрать значимые, те, которые нам помогут в решении нашей задачи. Выбор признаков является одной из самых сложных и недетерминированных операций в Data Science, поэтому сейчас для простоты выберем несколько признаков, которые на первый взгляд являются значимыми. Модуль, который поможет нам это сделать, называется «Select Columns in Dataset». Добавим его в рабочую область, соединим с операцией «Add Columns». Теперь в параметрах «Select Columns in Dataset» укажем, какие признаки мы хотим оставить. Для этого выделим модуль «Select Columns in Dataset», в свойствах на правой панели нажмем «Launch column selector»:

Теперь добавим имена столбцов, которые мы хотим оставить (это совсем не оптимальный выбор столбцов), не забываем добавить столбец «time»:
Запустим эксперимент еще раз, убедимся, что в получившейся таблице остались Только те столбцы, которые выбрали. Теперь последний шаг по подготовке данных: разделим данные на обучающую и тестовую выборки в пропорции 70:30. Для этого найдем и поместим в рабочую область модуль «Split Data», в его настройках установим «Fraction of rows in the first output dataset» равному 0.7. Получим:
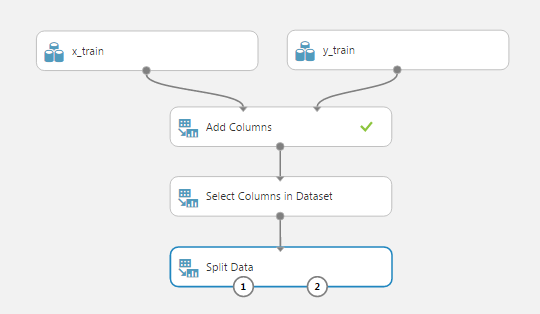
Теперь мы готовы наконец-то использовать какой-нибудь метод регрессии. Методы перечислены в меню слева: «Machine Learning», «Initialize Model», «Regression»:
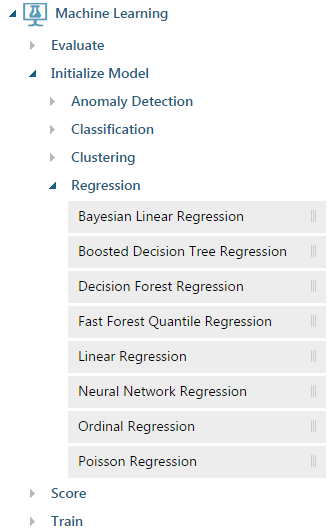
Для начала попробуем метод леса деревьев принятия решений: «Decision Forest Regression». Добавим его в рабочую область, а также модуль «Train model». У этого модуля два входа: один соединяется с алгоритмом (в нашем случае с «Decision Forest Regression»), другой — с данными обучающей выборки (левый выход модуля «Split Data»). Эксперимент теперь выглядит так:
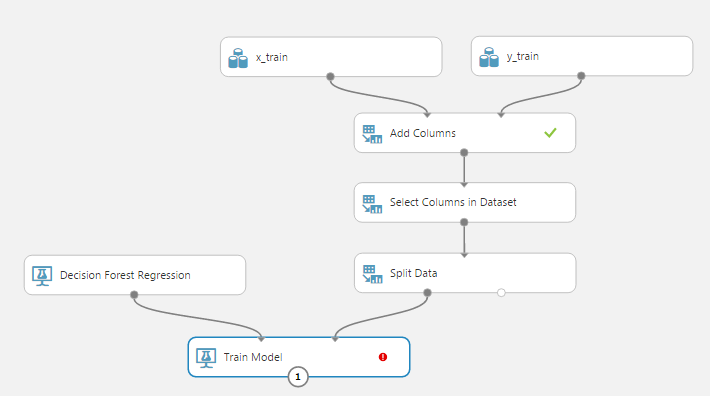
Красный кружок в модуле «Train model» говорит нам, что у него есть обязательные параметры, которые мы не донастроили: ему надо указать, какой признак мы пытаемся предсказать (в нашем случае это time). Кликнем «Launch column selector», добавим единственный столбец time. Обратим внимание, что у самого метода есть настройки по умолчанию, которые позволяют ему запускаться без ручной донастройки. Конечно же, для получения хороших результатов надо пробовать различные комбинации параметров, которые будут специфичны для каждого метода. Теперь эксперимент можно запустить, лес деревьев будет построен, их даже можно посмотреть, вызвав уже знакомое окно «Visualize». После обучения модели, ее хорошо бы проверить на тестовой (валидационной) выборке, которая представляет собой 30% от исходных данных. Для этого используем модуль «Score Model», соединив его первый вход с выходом модуля «Train model» (обученной моделью), а второй — со вторым выходом модуля «Split Data». Теперь последовательность операций выглядит так:
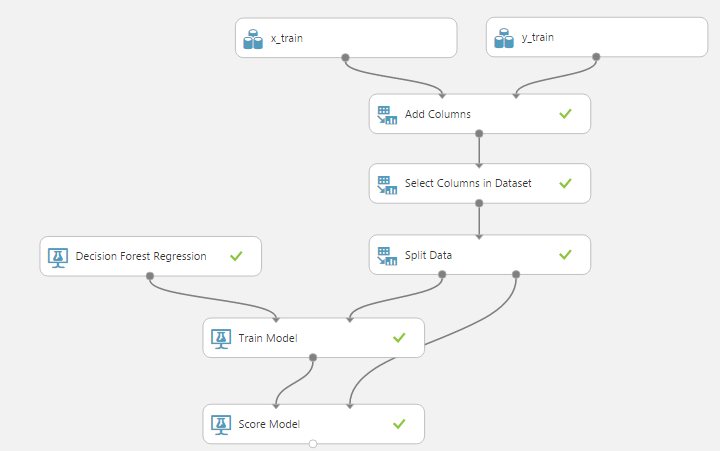
Можно опять запустить эксперимент и посмотреть вывод «Score model»:
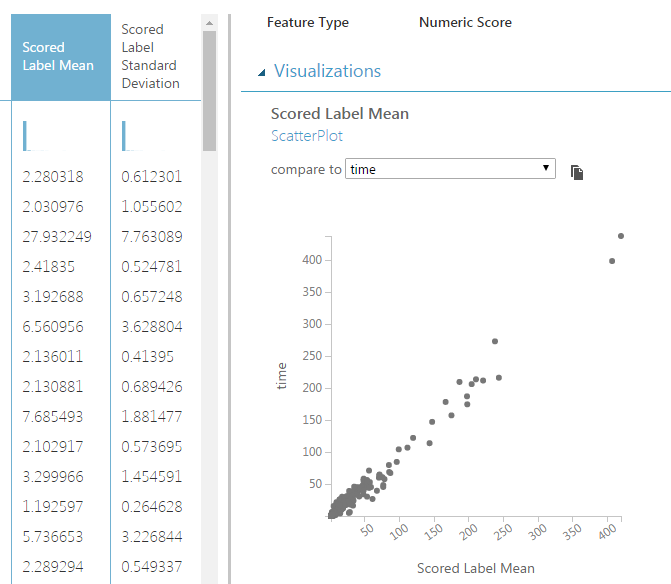
Добавились 2 новых столбца: «Scored Label Mean» (среднее предсказанного значения) и «Scored Label Standard Deviation» (стандартное отклонение предсказанного значения от фактического). Также можно построить точечную диаграмму (scatter plot, диаграмму рассеяния) для предсказанного и фактического значений (видна на рисунке). Теперь узнаем его точность с помощью модуля «Evaluate Model», который соединим с модулем «Score Model».
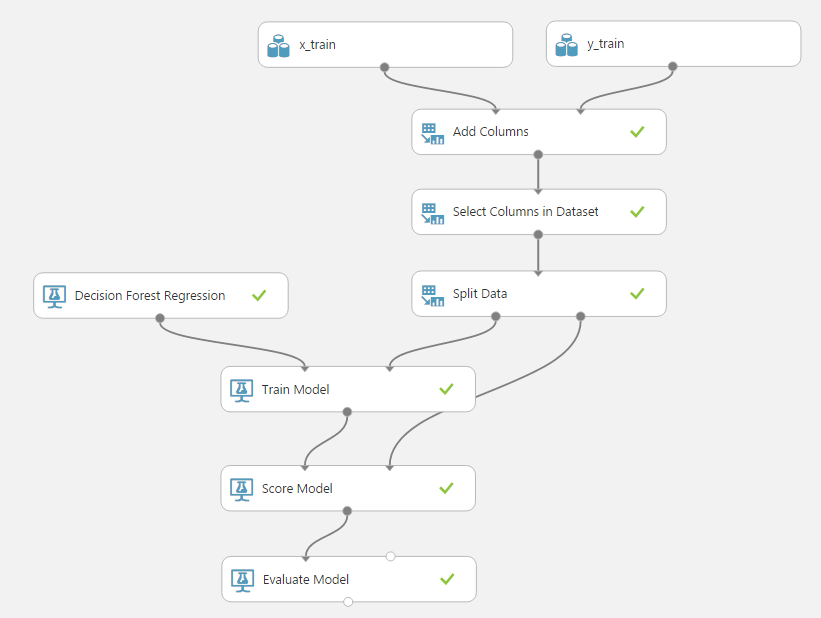
Вывод модуля «Evaluate Model» содержит информацию о точности метода на наших проверочных данных, среди которых абсолютная и относительная погрешности:

Конечно, метод не идеален, но мы совсем не занимались его настройкой.
Попробуем еще один метод на основе деревьев принятия решений: «Boosted Decision Tree Regression». Точно так же, как и для первого метода, добавим модули «Train Model» и «Score Model», запустим эксперимент, посмотрим вывод модуля «Score Model» для нового метода. Заметим, что добавился всего один столбец, представляющий предсказанное значение: «Scored Labels», для него также можно построить точечную диаграмму:
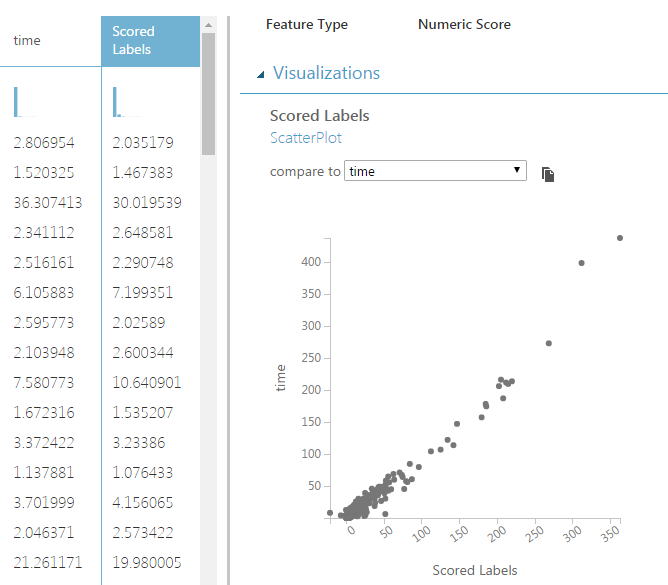
Теперь мы сравним точность этих двух методов, используя уже добавленный модуль «Evaluate Model», для этого соединим его правый вход с выводом «Score Model» второго метода. В результате получим такую последовательность операций:
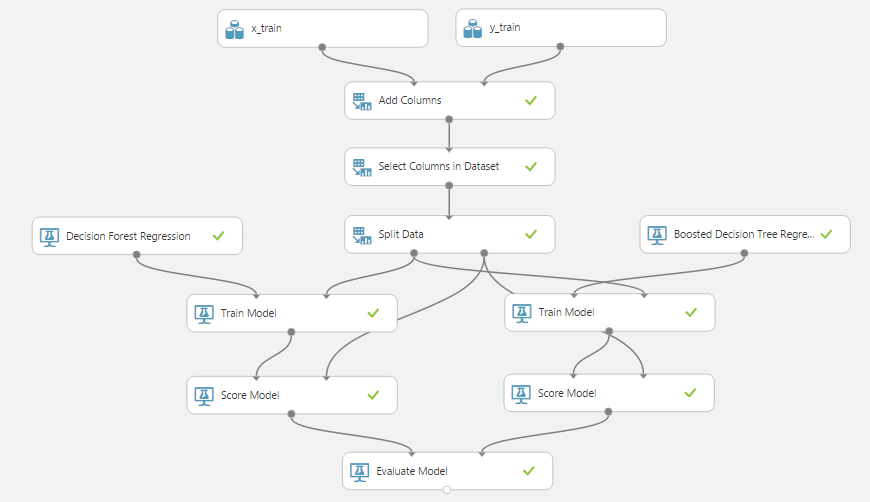
Посмотрим на вывод модуля «Evaluate Model»:

Теперь мы можем сравнить методы между собой и выбрать тот, точность которого (в нужном для нашей задачи смысле) выше.
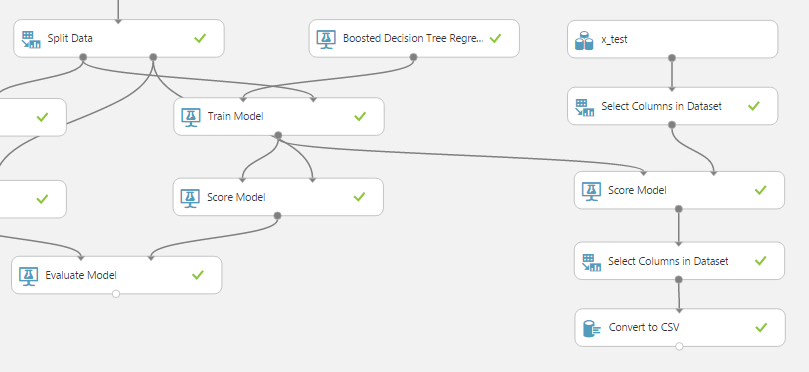
У нас есть обученные методы, мы знаем их точность — пришло время проверить их в бою. Скачем файл x_test.csv, в котором находятся данные, для которых мы должны предсказать время перемножения матриц. Чтобы использовать обученный метод, нам нужно:
В итоге получим следующий эксперимент:
Скачать полученный csv файл можно, нажав на вывод модуля «Convert to CSV» и выбрав пункт «Download». Теперь удалим первую строку (с названием) из полученного csv, загрузим ее на сайт ML Boot Camp. Работает! Но точность оставляет желать лучшего.
Рассмотрим несколько модулей, которые помогут улучшить точность регрессии.
Мне нравится Azure ML, он позволяет быстро запрототипировать решение задачи, а потом углубляться в настройку и оптимизацию ее решения.
Эксперимент выложен в галерею и открыт для всех желающих по адресу: gallery.cortanaintelligence.com/Experiment/ML-Boot-Camp-from-Mail-ru-1
Принимайте участие в контесте! Все, кто сможет получить ошибку MAPE меньше 0,1, напишите, автору будет приятно.
Создание источников данных
Откроем ML Studio:

Мы с вами создадим один новый эксперимент (в терминах Azure ML представляет собой законченное решение задачи — от чтения входных данных до получения ответа, затем его можно преобразовать в Web Service) и два новых источника данных (dataset) для представления входных данных (один для набора признаков, другой для значений). Скачайте с сайта ML Boot Camp csv файлы с обучающей выборкой (x_train.csv и y_train.csv). Чтобы добавить источник данных, надо выбрать пункт «Dataset» в меню слева и нажать «New» в левом нижнем углу, появится такое окно:
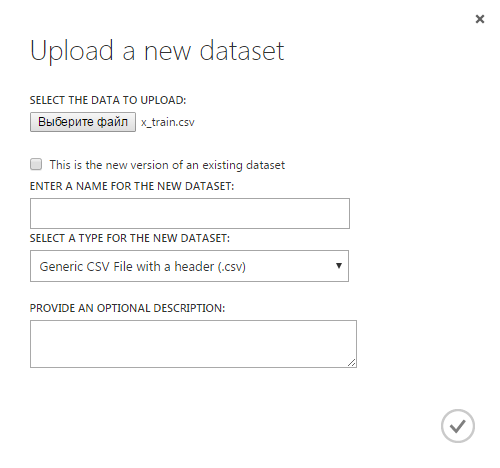
Укажем путь к файлу x_train.csv, дадим этому источнику данных имя x_train. Так же создадим источник данных y_train. Теперь оба этих источника данных показываются на вкладке «Datasets»:

Создание эксперимента, выбор характеристик
Пришло время создать эксперимент, для этого в меню слева выбираем пункт «Experiments», нажимаем «New» внизу слева и выбираем «Blank Experiment». В строке вверху можно дать ему подходящее имя, в итоге получим следующий простор для наших Data Science операций:

Как вы видите, слева находится меню, в котором перечислены все возможные операции, которые могут быть добавлены в эксперимент, такие как: ввод и вывод данных, выбор столбцов, различные методы регрессии, классификации и т.д. Все они будут добавлять в наш эксперимент путем простого перетаскивания мышью и соединения разных операция между собой.
Теперь нам нужно показать, что мы хотим использовать в качестве входных данных для задачи. В меню слева выберем самый верхний пункт «Saved Datasets», затем «My Datasets», в списке выберем созданные нами источники данных «x_train» и «y_train» и перетащим их в рабочую область эксперимента, в результате получим:
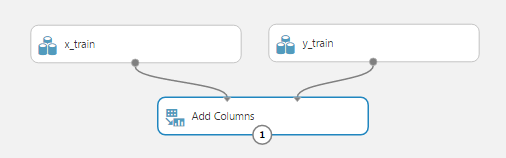
Теперь нам нужно объединить столбцы этих двух источников данных, потому что все методы Azure ML работают с одной таблицей (data frame), в которой надо указать столбец, являющийся значением обучения. Для этого воспользуемся модулем «Add Columns». Подсказка: поиск по модулям поможет найти модуль по ключевым словам или убедиться, что такого модуля еще не существует. Перетащим операцию «Add Columns» в рабочую область и соединим две его верхних точки для ввода данных с нашими источниками данных x_train и y_train соответственно. У этой операции нет параметров, поэтому дополнительно ничего настраивать не надо. Получим:
Чтобы посмотреть, как теперь выглядят наши данные. Запустим эксперимент на выполнение, нажав кнопку «Run» в нижней строке. После того, как эксперимент успешно выполнится, можно нажать на вывод операции «Add Columns» и выбрать действие «Visualize»:


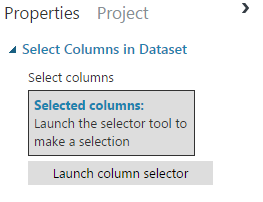
Окно свойств позволяет увидеть столбцы, первые строки, для каждого признака: среднее, медиану, гистограмму и т.д. Мы видим, что в нашей таблице 952 колонки (признака), и из них надо выбрать значимые, те, которые нам помогут в решении нашей задачи. Выбор признаков является одной из самых сложных и недетерминированных операций в Data Science, поэтому сейчас для простоты выберем несколько признаков, которые на первый взгляд являются значимыми. Модуль, который поможет нам это сделать, называется «Select Columns in Dataset». Добавим его в рабочую область, соединим с операцией «Add Columns». Теперь в параметрах «Select Columns in Dataset» укажем, какие признаки мы хотим оставить. Для этого выделим модуль «Select Columns in Dataset», в свойствах на правой панели нажмем «Launch column selector»:
Теперь добавим имена столбцов, которые мы хотим оставить (это совсем не оптимальный выбор столбцов), не забываем добавить столбец «time»:

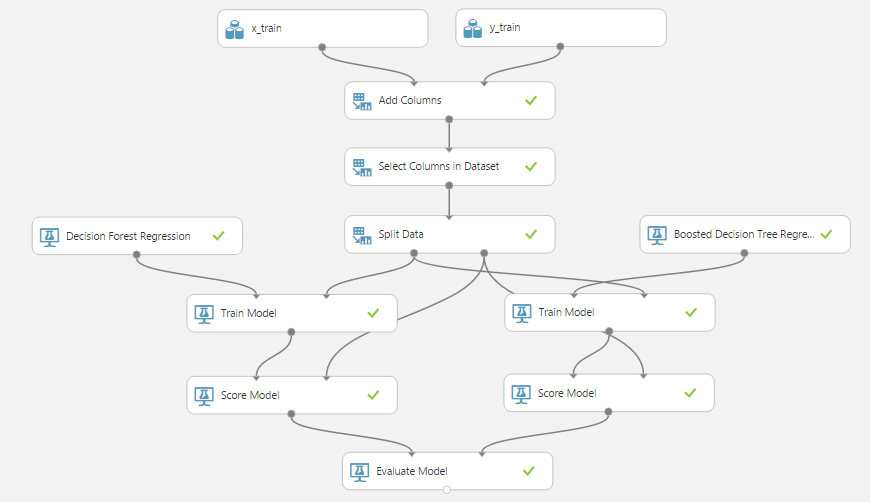
Запустим эксперимент еще раз, убедимся, что в получившейся таблице остались Только те столбцы, которые выбрали. Теперь последний шаг по подготовке данных: разделим данные на обучающую и тестовую выборки в пропорции 70:30. Для этого найдем и поместим в рабочую область модуль «Split Data», в его настройках установим «Fraction of rows in the first output dataset» равному 0.7. Получим:

Использование алгоритмов
Теперь мы готовы наконец-то использовать какой-нибудь метод регрессии. Методы перечислены в меню слева: «Machine Learning», «Initialize Model», «Regression»:

Для начала попробуем метод леса деревьев принятия решений: «Decision Forest Regression». Добавим его в рабочую область, а также модуль «Train model». У этого модуля два входа: один соединяется с алгоритмом (в нашем случае с «Decision Forest Regression»), другой — с данными обучающей выборки (левый выход модуля «Split Data»). Эксперимент теперь выглядит так:

Красный кружок в модуле «Train model» говорит нам, что у него есть обязательные параметры, которые мы не донастроили: ему надо указать, какой признак мы пытаемся предсказать (в нашем случае это time). Кликнем «Launch column selector», добавим единственный столбец time. Обратим внимание, что у самого метода есть настройки по умолчанию, которые позволяют ему запускаться без ручной донастройки. Конечно же, для получения хороших результатов надо пробовать различные комбинации параметров, которые будут специфичны для каждого метода. Теперь эксперимент можно запустить, лес деревьев будет построен, их даже можно посмотреть, вызвав уже знакомое окно «Visualize». После обучения модели, ее хорошо бы проверить на тестовой (валидационной) выборке, которая представляет собой 30% от исходных данных. Для этого используем модуль «Score Model», соединив его первый вход с выходом модуля «Train model» (обученной моделью), а второй — со вторым выходом модуля «Split Data». Теперь последовательность операций выглядит так:

Можно опять запустить эксперимент и посмотреть вывод «Score model»:

Добавились 2 новых столбца: «Scored Label Mean» (среднее предсказанного значения) и «Scored Label Standard Deviation» (стандартное отклонение предсказанного значения от фактического). Также можно построить точечную диаграмму (scatter plot, диаграмму рассеяния) для предсказанного и фактического значений (видна на рисунке). Теперь узнаем его точность с помощью модуля «Evaluate Model», который соединим с модулем «Score Model».

Вывод модуля «Evaluate Model» содержит информацию о точности метода на наших проверочных данных, среди которых абсолютная и относительная погрешности:

Конечно, метод не идеален, но мы совсем не занимались его настройкой.
Добавление нового метода и сравнение методов
Попробуем еще один метод на основе деревьев принятия решений: «Boosted Decision Tree Regression». Точно так же, как и для первого метода, добавим модули «Train Model» и «Score Model», запустим эксперимент, посмотрим вывод модуля «Score Model» для нового метода. Заметим, что добавился всего один столбец, представляющий предсказанное значение: «Scored Labels», для него также можно построить точечную диаграмму:

Теперь мы сравним точность этих двух методов, используя уже добавленный модуль «Evaluate Model», для этого соединим его правый вход с выводом «Score Model» второго метода. В результате получим такую последовательность операций:
Посмотрим на вывод модуля «Evaluate Model»:

Теперь мы можем сравнить методы между собой и выбрать тот, точность которого (в нужном для нашей задачи смысле) выше.
Решаем задачу с настоящими данным
У нас есть обученные методы, мы знаем их точность — пришло время проверить их в бою. Скачем файл x_test.csv, в котором находятся данные, для которых мы должны предсказать время перемножения матриц. Чтобы использовать обученный метод, нам нужно:
- Добавить новый источник данных с именем x_test и данными из файла x_test.csv.
- Перетащить новый источник данных x_test в рабочую область эксперимента.
- Теперь нам нужно оставит только те столбцы, которые принимали участие в обучении, скопируем модуль «Select Columns in Dataset», и удалим из списка столбцов столбец «time» (так как его нет в наших тестовых данных).
- Теперь мы можем запустить наш обученный метод на подготовленных данных, для этого добавим операцию «Score Model», первый его вход соединим с выводом модуля «Train Model» метода «Boosted Decision Tree Regression», второй вход — с выводом только что добавленного «Select Columns in Dataset».
- Теперь осталось только привести полученные данные к формату, который можно загрузить как решение на сайт ML Boot Camp. Для этого добавим еще один модуль «Select Columns in Dataset», в котором выберем всего один столбец — наши предсказанные значения «Scored Labels», а к его выводу добавим модуль «Convert to CSV».
В итоге получим следующий эксперимент:

Скачать полученный csv файл можно, нажав на вывод модуля «Convert to CSV» и выбрав пункт «Download». Теперь удалим первую строку (с названием) из полученного csv, загрузим ее на сайт ML Boot Camp. Работает! Но точность оставляет желать лучшего.
Дальнейшая оптимизация
Рассмотрим несколько модулей, которые помогут улучшить точность регрессии.
- Пробовать разные методы, которые можно найти в меню слева.
- Выбрать признаки поможет модуль «Filter Based Feature Selection», который пытается выбрать признаки, обладающие наибольшей предсказательной способностью (несколькими различными методами, которые задаются в его свойствах). Этот модуль добавляется вместо модуля «Select Columns in Dataset».
- Оценить, какие признаки более полезны в уже обученной модели поможет модуль «Permutation Feature Importance», принимающий в качестве входных параметров обученную модель и набор тестовых данных.
- Подобрать параметры метода поможет модуль «Tune Model Hyperparameters», который проведет заданное количество запусков метода с Различным наборов параметров и покажет точность каждого запуска.
- В качестве тяжелой артиллерии можно использовать любые R и Python скрипты с помощью модулей «Execute R Script» и «Execute Python Script» соответственно.
Заключение
Мне нравится Azure ML, он позволяет быстро запрототипировать решение задачи, а потом углубляться в настройку и оптимизацию ее решения.
Эксперимент выложен в галерею и открыт для всех желающих по адресу: gallery.cortanaintelligence.com/Experiment/ML-Boot-Camp-from-Mail-ru-1
Принимайте участие в контесте! Все, кто сможет получить ошибку MAPE меньше 0,1, напишите, автору будет приятно.
