В ходе многих дискуссий о применимости паттерна Repository я заметил, что люди разделены на два лагеря. В рамках этого текста я, условно, их назову абстракционистами и конкретистами. Разница между ними заключается в том, как они относятся к значению паттерна. Первые считают, что репозиторй стоит иметь, т.к. он позволяет абстрагироваться от деталей хранения данных. Вторые считают, что мы не можем полностью абстрагироваться от этих деталей, поэтому сама идея репозитория бессмыслена, а его использование пустая трата времени. Спор между ними обычно превращается в холивар.
Что не так с репозиторием? Очевидно, что с самим паттерном все нормально, но разница в его понимании разработчиками. Я попробовал исследовать это и наткнулся на два основных момента, которые, на мой взгляд, являются причиной разного к нему отношения. Одним из них является «скользящая» ответственность репозитория, а другой связан с недооценкой unit testing. Под катом я объясню первый.
Когда речь заходит о построении архитектуры приложения у всех в голове сразу возникает представление о трех слоях: слой представления (Presentation Layer), бизнес логики (Business Layer) и слой данных (Data Layer) (см MSDN). В таких системах объекты бизнес логики используют репозитории для извлечения данных из физических хранилищ. Репозитории возвращают бизнес-сущности вместо сырых рекордсетов. Очень частно это обосновывается тем, что если бы нам нужно было заменить тип физического хранилища (база, файл или сервис), то мы сделали бы абстрактный класс репозитория и реализовали бы специфичный для нужного нам хранилища. Выглядит примерно так:
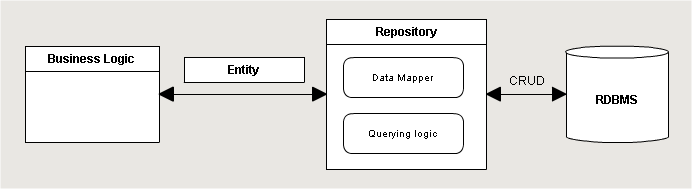
О таком же разделении говорит Мартин Фаулер и MSDN. Как обычно, описание — это, всего лишь, упрощенная модель. Поэтому, хотя это выглядит правильно для небольшого проекта, это вводит в заблуждение, когда вы пытаетесь перенести этот паттерн на более сложный. Существующие ORM еще сильнее сбивают с толку, т.к. реализуют многие вещи из коробки. Но представим, что разработчик знает только как использовать Entity Framework (или другой ORM) только для получения даных. Куда, например, он должен поместить кеш второго уровня, или логирование всех бизнес-операций? В попытке сделать это, очевидно, что он будем стараться разделить модули по функционалу, следую SPR из SOLID, и построить из них композицию, которая, возможно, будет выглядеть так:
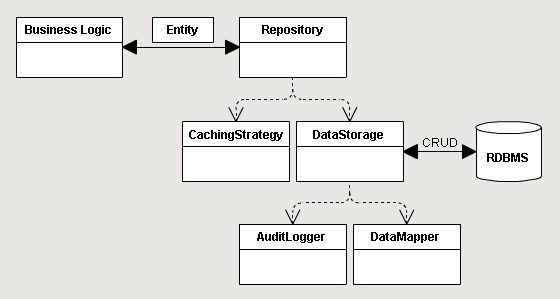
Выполняет ли репозиторий ту же роль, что и ранее? Очевидный ответ «НЕТ», так как теперь он не извлекает данные из хранилища. Эта ответственность была перенесена в другой объект. На этой почве возникает первая нестыковка между лагерями абстракционистов и конкретистов.
Если принять за правило, что все термины должна сохранять свое значение вне зависимости от модификаций кода, то было бы правильно на первом этапе не называть репозиторием объект, который просто возвращает данные. Это DAO паттерн чистой воды, т.к. его задача спрятать конкретный интерфейс доступа к данным (ling, ADO.NET, или что-то еще). В то же время репозиторий может не знать о таких деталях вообще ничего, собирая в единую композицию все подсистемы доступа к данным.
Считаете ли вы, что такая проблема существет?
Что не так с репозиторием? Очевидно, что с самим паттерном все нормально, но разница в его понимании разработчиками. Я попробовал исследовать это и наткнулся на два основных момента, которые, на мой взгляд, являются причиной разного к нему отношения. Одним из них является «скользящая» ответственность репозитория, а другой связан с недооценкой unit testing. Под катом я объясню первый.
Скользящая Ответственность Репозитория
Когда речь заходит о построении архитектуры приложения у всех в голове сразу возникает представление о трех слоях: слой представления (Presentation Layer), бизнес логики (Business Layer) и слой данных (Data Layer) (см MSDN). В таких системах объекты бизнес логики используют репозитории для извлечения данных из физических хранилищ. Репозитории возвращают бизнес-сущности вместо сырых рекордсетов. Очень частно это обосновывается тем, что если бы нам нужно было заменить тип физического хранилища (база, файл или сервис), то мы сделали бы абстрактный класс репозитория и реализовали бы специфичный для нужного нам хранилища. Выглядит примерно так:
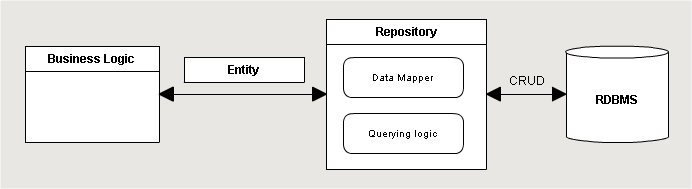
О таком же разделении говорит Мартин Фаулер и MSDN. Как обычно, описание — это, всего лишь, упрощенная модель. Поэтому, хотя это выглядит правильно для небольшого проекта, это вводит в заблуждение, когда вы пытаетесь перенести этот паттерн на более сложный. Существующие ORM еще сильнее сбивают с толку, т.к. реализуют многие вещи из коробки. Но представим, что разработчик знает только как использовать Entity Framework (или другой ORM) только для получения даных. Куда, например, он должен поместить кеш второго уровня, или логирование всех бизнес-операций? В попытке сделать это, очевидно, что он будем стараться разделить модули по функционалу, следую SPR из SOLID, и построить из них композицию, которая, возможно, будет выглядеть так:

Выполняет ли репозиторий ту же роль, что и ранее? Очевидный ответ «НЕТ», так как теперь он не извлекает данные из хранилища. Эта ответственность была перенесена в другой объект. На этой почве возникает первая нестыковка между лагерями абстракционистов и конкретистов.
Вместо анализа
Если принять за правило, что все термины должна сохранять свое значение вне зависимости от модификаций кода, то было бы правильно на первом этапе не называть репозиторием объект, который просто возвращает данные. Это DAO паттерн чистой воды, т.к. его задача спрятать конкретный интерфейс доступа к данным (ling, ADO.NET, или что-то еще). В то же время репозиторий может не знать о таких деталях вообще ничего, собирая в единую композицию все подсистемы доступа к данным.
Считаете ли вы, что такая проблема существет?
