Настоящая статья является продолжением предыдущей публикации «Инструменты DataScience как альтернатива классической интеграции ИТ систем». Основная цель — заострить внимание как разработчиков, так и руководителей среднего звена, на широком спектре возможностей, которые предоставляют современные инструменты из сферы Data Science за рамками классических задач статистических вычислений и модной нынче темы машинного обучения. В частности, возможности экосистемы R по состоянию на август 2016 года и применение этих возможностей на примере двух задач: одной из прикладной науки, другой – из среднего бизнеса.
Выбор остановился на R отнюдь не случайным образом, а явился результатом взвешенного анализа. Мой предыдущий опыт исполнения проектов в различных отраслях и областях человеческой деятельности, как правило, приходился на междисциплинарные стыки, поэтому ситуация отсутствия специально созданного инструмента была привычной и требовала принятия оперативного решения.
Ключевые пункты, по которым проводилась оценка выбираемого инструмента выглядели следующим образом:
Если уж и придется вкладывать время в изучение системы, то надо это делать максимально эффективно, выбирая системы, обладающие гибкостью и широтой возможного применения. Забегая вперед, скажу, для подобного класса задач это был решающий аргумент в пользу победы R в финале. Хотя Python, хоть и занял второе место, был есть и останется активным универсальным инструментом.
Оценка и сравнение подходов к решению задачи проводилась с точки зрения бизнеса, для которого первостепенным показателем является достижение результата в заданный срок за минимальную стоимость. Поскольку по пути в финал технически неполноценные решения отсеялись сами, будем считать, что решение-финалист удовлетворяет запросам как бизнес-заказчиков, так и технических исполнителей.
Минимальный набор, который нас полностью устроил — язык R, IDE – RStudio, интеграционный шлюз — DeployR, сервер клиентских веб-приложений — Shiny.
Естественно, что R, будучи языком программирования, практически не ограничен в возможностях по созданию логически и математически сложных компонент. Все зависит от глубины познаний, навыков работы и использованных пакетов.
Классическая расчетно-производственная задача, когда для формирования опытных образцов сложных слоистых структур, необходимо определить целый ряд параметров, необходимых для технологического производства. Чтобы определить параметры необходимо провести весьма нетривиальные квантово-механические расчеты. И из различных комбинаций подобрать набор параметров, оптимально удовлетворяющих набору исходных оптических требований к образцу. Непосредственно для самих аналитических расчетов использовался пакет Wolfram Mathematica.
Все бы ничего, но была существенная проблема — сложность расчетов приводила к весьма трудоемким и длительным вычислениям. А для анализа характеристик материала необходимо было проанализировать, в первую очередь визуально, спектральные характеристики объекта на разных длинах волн, полученные в результате цикла расчетов. Максимально, что удалось достичь по оптимизации в расчетной части в пределах доступного множества вычислителей и лицензий на ПО Wolfram — распараллелить расчет на несколько компьютеров и достичь времени обсчета одной конфигурации параметров 4-6 часов.
Но на втором этапе, включающем постпроцессинг полученного множества данных, визуализацию и интерактивный анализ спектров, справиться средствами только Wolfram Mathematica было крайне затруднительно. Подготовка одного спектра занимала ~ 20 часов и требовала дополнительного рутинного ручного труда (вероятность внесения ошибок!). Графические результаты при этом нерепрезентативны и очень плохо считывались визуально (см. рисунок).
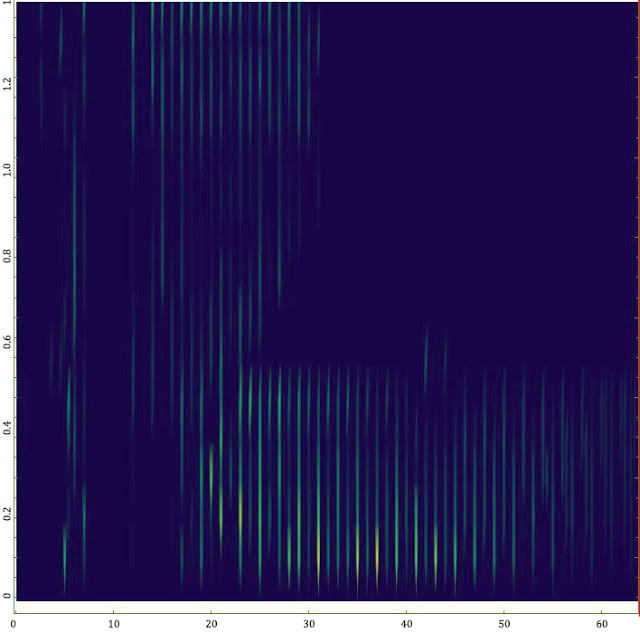
Применение известного спектра функций, мантр и рекомендаций с форумов к полезному результату не привели. Не буду утверждать, что пакет Wolfram Mathematica однозначно не обладает нужными средствами, тем более, что только что вышедшая 11-ая версия имеет много улучшений именно в этой области. Но в условиях ограниченного времени на решение задачи и необходимости получить результат к заданному сроку, заниматься профилировкой кода и оптимизацией памяти без прозрачного понимания внутренних принципов работы сложного проприетарного математического ядра физически было совершенно некогда. Собственно говоря, задачи у пакета Mathematicа, как и его сильные стороны, несколько другие.
Ровно поэтому за пару дней на фреймворке R был написан модуль для сборки, обработки визуализации и экспресс-анализа расчетных данных. По результатам анализа формировался файл с параметрами для нового расчета. В результате процесс предобработки и визуализации с 20 часов сократился до 5-7 секунд, визуализация в ходе 3-4 десятков итераций была полностью изменена и приобрела следующий вид, понятный и очевидный всем исполнителям:
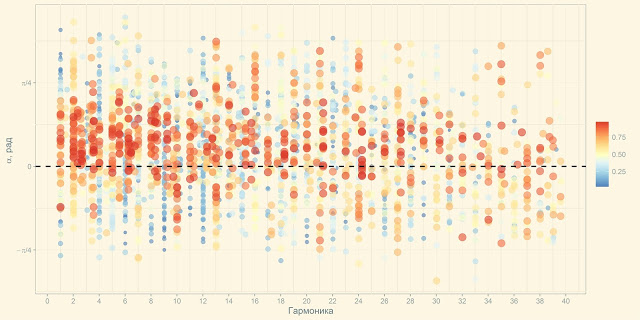
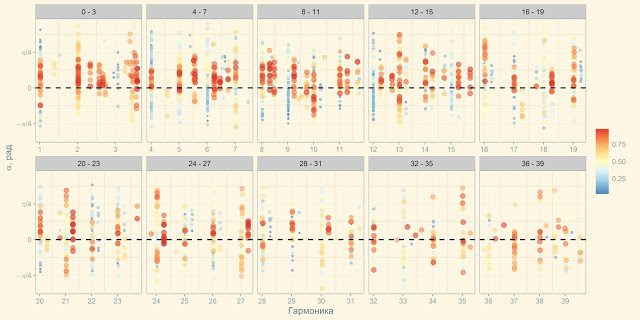
GUI был собран на базе Shiny RStudio, благодаря использованию пакетов для высокоуровневой комплексной обработки данных и визуализации, элементов потоковой передачи значений и функционального программирования, содержательный код на R уместился менее чем в 100 строк.
Если смотреть только с технической точки зрения, то задача может казаться мелкой. Нет никаких Больших Данных, нет машинного обучения, даже стат. методы не используются.
С точки зрения бизнеса эффект применения внушительный и показательный. В условиях жесткого временного прессинга работа была исполнена в срок. При этом на это не было затрачено никаких денежных средств, если не считать время сотрудников, которое так или иначе уже входит в ФОТ.
Постановка задачи достаточно простая и классическая для задач любого мониторинга – собрать данные и уведомить ответственных о каких-либо проблемах. И, естественно, отобразить это все в дружественном пользовательском веб-интерфейсе. Классическая ручная обработка в Excel давно потеряла свою актуальность, поскольку требовала постоянных человеческих затрат, была крайне медленной, допускались ошибки, анализ осуществлялся по простым моделям и путем пристального взгляда в данные.
Также было несколько нюансов, весьма усложняющих работу:
Поскольку первостепенной задачей была обработка данных и прогнозная аналитика, то для решения задачи был выбран язык R. Для обеспечения непрерывной работы можно было пойти классическим вариантом – R скрипты на запуск по расписанию. Но мы пошли другим, более элегантным путем.
Согласно требованиям, необходимо было обеспечить GUI на базе Web. Для его создания мы использовали Shiny Server. А специфика Shiny приложений такова, что они реактивные (реагируют на события) и, будучи запущенным, инстанс приложения остается активным. И тут мы вспоминаем мантру классических Windows API приложений:
Вот он ответ. Наше приложение и будет само выступать в качестве планировщика. Вешаем обработчик таймера + используем событийно запускаемый перечет реактивных структур данных и инвалидацию графических элементов. Добавляем обработку исключений и шпигуем логированием. Все, включая сбор данных, их обработку, математические алгоритмы, выгрузку наружу и запуск внешних исполнительных элементов, GUI и интерактивная визуализация реализуются в рамках языка R и среды RStudio. Также, развитые средства профилирования и анализа объектов позволяют оптимизировать программы по времени исполнения и объему используемой памяти.
Прототип GUI на синтетических данных появился в течение 1.5 недель. Финальный портал, стабильно работающий 24x7 доработали в течение 1.5 месяцев. Пока особой нужды нет, но в случае необходимости сможем в пару кликов выдать наружу для мобильного приложения всю аналитику через REST API средствами DeployR.
В 2014-м году мы использовали язык R только как инструмент для проведения расчетов по сложным математическим алгоритмам на ограниченном наборе структурированных данных.
В 2016-м году мы успешно применяли экосистему R для решения локальных, но сложных задач по автоматизации работы с данными и можем уверенно утверждать, что средства R в конфигурации 2016 года обладают всеми необходимыми свойствами для успешного решения этих задач.
Интенсивное развитие пакетов R по работе с данными и средств интерактивной визуализации, приобретение Microsoft коммерческой ветки R дает все основания полагать, что в ближайшие 2-3 года возможности экосистемы R многократно вырастут. В частности, активное развитие PowerBI и включение R в SQL Serever 2016, обязательная поддержка ведущими системами визуализации (из популярных в России это Qlik и Tableau) тесной интеграции с R, поддержка кластерных вычислений работа с Big Data платформами в enterprise редакциях и прочие интересные инициативы явно указывают на большой потенциал R экосистемы в бизнес-задачах.
Но ждать чудес еще несколько лет нет никакого смысла. Уже сейчас можно засучить рукава и попробовать заняться автоматизацией бизнес-задач на R, каковых в любой компании может быть не один десяток. Экономия средств для компании обеспечена, фан и вызов для исполнителей – обеспечен в квадрате.
Предыдущий пост: «Инструменты Data Science как альтернатива классической интеграции ИТ систем»
Следующий пост: «Джентельменский набор пакетов R для автоматизации бизнес-задач»
Выбор остановился на R отнюдь не случайным образом, а явился результатом взвешенного анализа. Мой предыдущий опыт исполнения проектов в различных отраслях и областях человеческой деятельности, как правило, приходился на междисциплинарные стыки, поэтому ситуация отсутствия специально созданного инструмента была привычной и требовала принятия оперативного решения.
Ключевые пункты, по которым проводилась оценка выбираемого инструмента выглядели следующим образом:
- Основное содержание задач сводилось к стандартному циклу: сбор данных — очистка и препроцессинг — математическая обработка разной степени сложности — визуализация — выдача управляющих команд во внешние системы.
- Весь обмен информацией с внешним миром осуществлялся по стандартизованным протоколам (ODBC, REST) и файлами разнообразных форматов. Информации не очень много (максимум, десятки гигабайт в сутки), ~70% представлено в структурированном виде, потоковая обработка в режиме реального времени совершенно не требуется.
- Обязательно должен быть интерактивный веб-интерфейс пользователя с инструментами экспресс-аналитики обрабатываемых данных.
- Бюджет на приобретение чего бы то ни было = 0. Время на реализацию = Еще вчера. Пользовательские требования появятся после первой демонстрации прототипа.
- Любая система, покупная или open-source, требует времени на изучение. Даже при наличии «интуитивно-понятных» интерфейсов пользователя, шаг влево-вправо потребует глубокого погружения и привязки к идеологии архитектуры выбранной системы. И, к сожалению, нет никаких гарантий, что через некоторое время ограничения этой системы не окажутся тормозом.
Если уж и придется вкладывать время в изучение системы, то надо это делать максимально эффективно, выбирая системы, обладающие гибкостью и широтой возможного применения. Забегая вперед, скажу, для подобного класса задач это был решающий аргумент в пользу победы R в финале. Хотя Python, хоть и занял второе место, был есть и останется активным универсальным инструментом.
Оценка и сравнение подходов к решению задачи проводилась с точки зрения бизнеса, для которого первостепенным показателем является достижение результата в заданный срок за минимальную стоимость. Поскольку по пути в финал технически неполноценные решения отсеялись сами, будем считать, что решение-финалист удовлетворяет запросам как бизнес-заказчиков, так и технических исполнителей.
R фреймворк
Минимальный набор, который нас полностью устроил — язык R, IDE – RStudio, интеграционный шлюз — DeployR, сервер клиентских веб-приложений — Shiny.
Естественно, что R, будучи языком программирования, практически не ограничен в возможностях по созданию логически и математически сложных компонент. Все зависит от глубины познаний, навыков работы и использованных пакетов.
Задача #1. Расчет оптических свойств материалов
Классическая расчетно-производственная задача, когда для формирования опытных образцов сложных слоистых структур, необходимо определить целый ряд параметров, необходимых для технологического производства. Чтобы определить параметры необходимо провести весьма нетривиальные квантово-механические расчеты. И из различных комбинаций подобрать набор параметров, оптимально удовлетворяющих набору исходных оптических требований к образцу. Непосредственно для самих аналитических расчетов использовался пакет Wolfram Mathematica.
Все бы ничего, но была существенная проблема — сложность расчетов приводила к весьма трудоемким и длительным вычислениям. А для анализа характеристик материала необходимо было проанализировать, в первую очередь визуально, спектральные характеристики объекта на разных длинах волн, полученные в результате цикла расчетов. Максимально, что удалось достичь по оптимизации в расчетной части в пределах доступного множества вычислителей и лицензий на ПО Wolfram — распараллелить расчет на несколько компьютеров и достичь времени обсчета одной конфигурации параметров 4-6 часов.
Но на втором этапе, включающем постпроцессинг полученного множества данных, визуализацию и интерактивный анализ спектров, справиться средствами только Wolfram Mathematica было крайне затруднительно. Подготовка одного спектра занимала ~ 20 часов и требовала дополнительного рутинного ручного труда (вероятность внесения ошибок!). Графические результаты при этом нерепрезентативны и очень плохо считывались визуально (см. рисунок).
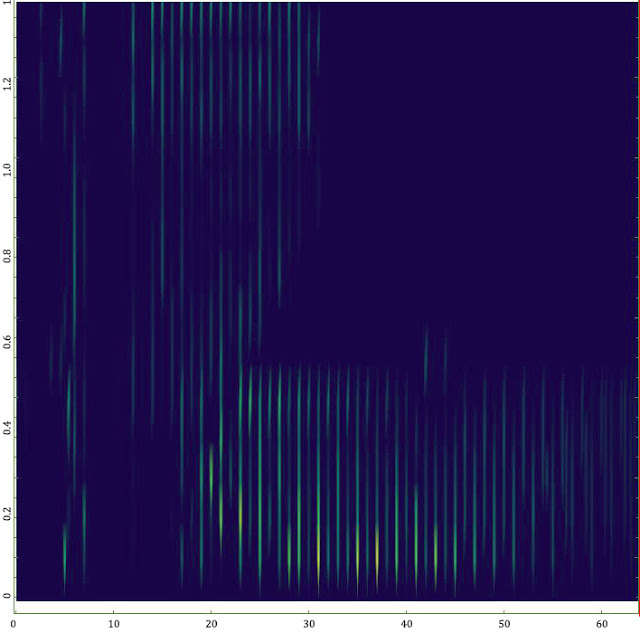
Применение известного спектра функций, мантр и рекомендаций с форумов к полезному результату не привели. Не буду утверждать, что пакет Wolfram Mathematica однозначно не обладает нужными средствами, тем более, что только что вышедшая 11-ая версия имеет много улучшений именно в этой области. Но в условиях ограниченного времени на решение задачи и необходимости получить результат к заданному сроку, заниматься профилировкой кода и оптимизацией памяти без прозрачного понимания внутренних принципов работы сложного проприетарного математического ядра физически было совершенно некогда. Собственно говоря, задачи у пакета Mathematicа, как и его сильные стороны, несколько другие.
Ровно поэтому за пару дней на фреймворке R был написан модуль для сборки, обработки визуализации и экспресс-анализа расчетных данных. По результатам анализа формировался файл с параметрами для нового расчета. В результате процесс предобработки и визуализации с 20 часов сократился до 5-7 секунд, визуализация в ходе 3-4 десятков итераций была полностью изменена и приобрела следующий вид, понятный и очевидный всем исполнителям:
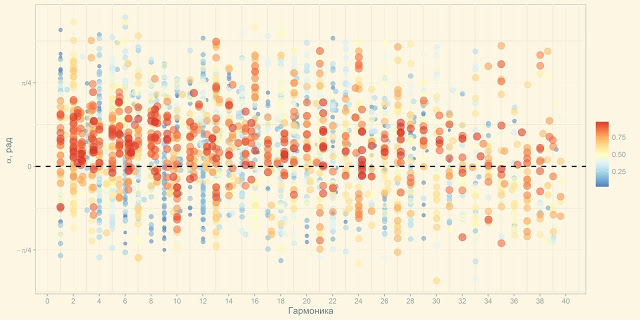
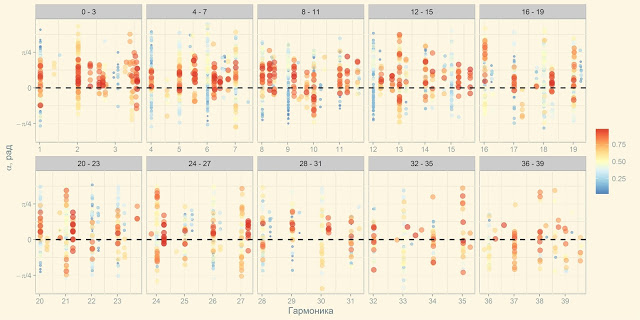
GUI был собран на базе Shiny RStudio, благодаря использованию пакетов для высокоуровневой комплексной обработки данных и визуализации, элементов потоковой передачи значений и функционального программирования, содержательный код на R уместился менее чем в 100 строк.
Если смотреть только с технической точки зрения, то задача может казаться мелкой. Нет никаких Больших Данных, нет машинного обучения, даже стат. методы не используются.
С точки зрения бизнеса эффект применения внушительный и показательный. В условиях жесткого временного прессинга работа была исполнена в срок. При этом на это не было затрачено никаких денежных средств, если не считать время сотрудников, которое так или иначе уже входит в ФОТ.
Задача #2. Мониторинг источников данных на предмет поиска аномалий и прогнозируемых отклонений
Постановка задачи достаточно простая и классическая для задач любого мониторинга – собрать данные и уведомить ответственных о каких-либо проблемах. И, естественно, отобразить это все в дружественном пользовательском веб-интерфейсе. Классическая ручная обработка в Excel давно потеряла свою актуальность, поскольку требовала постоянных человеческих затрат, была крайне медленной, допускались ошибки, анализ осуществлялся по простым моделям и путем пристального взгляда в данные.
Также было несколько нюансов, весьма усложняющих работу:
- Источники были весьма разнородные, включая github, локальные файлы, json ответы по REST API.
- Временные метки в источниках могли идти в произвольном порядке, могли поступать данные за уже «закрытые» периоды (отгрузки приходили пачками).
- Пропущенные данные, разные форматы данных, нерегулярные временн`ые ряды, получение агрегатных метрик вместо исходных данных (например, скользящее среднее вместо значения).
- Это не разовые вычисления, а постоянный процесс 24x7.
Поскольку первостепенной задачей была обработка данных и прогнозная аналитика, то для решения задачи был выбран язык R. Для обеспечения непрерывной работы можно было пойти классическим вариантом – R скрипты на запуск по расписанию. Но мы пошли другим, более элегантным путем.
Согласно требованиям, необходимо было обеспечить GUI на базе Web. Для его создания мы использовали Shiny Server. А специфика Shiny приложений такова, что они реактивные (реагируют на события) и, будучи запущенным, инстанс приложения остается активным. И тут мы вспоминаем мантру классических Windows API приложений:
WHILE(GETMESSAGE(&MSG, NULL, 0, 0) > 0)
{
TRANSLATEMESSAGE(&MSG);
DISPATCHMESSAGE(&MSG);
}
Вот он ответ. Наше приложение и будет само выступать в качестве планировщика. Вешаем обработчик таймера + используем событийно запускаемый перечет реактивных структур данных и инвалидацию графических элементов. Добавляем обработку исключений и шпигуем логированием. Все, включая сбор данных, их обработку, математические алгоритмы, выгрузку наружу и запуск внешних исполнительных элементов, GUI и интерактивная визуализация реализуются в рамках языка R и среды RStudio. Также, развитые средства профилирования и анализа объектов позволяют оптимизировать программы по времени исполнения и объему используемой памяти.
Прототип GUI на синтетических данных появился в течение 1.5 недель. Финальный портал, стабильно работающий 24x7 доработали в течение 1.5 месяцев. Пока особой нужды нет, но в случае необходимости сможем в пару кликов выдать наружу для мобильного приложения всю аналитику через REST API средствами DeployR.
Заключение
В 2014-м году мы использовали язык R только как инструмент для проведения расчетов по сложным математическим алгоритмам на ограниченном наборе структурированных данных.
В 2016-м году мы успешно применяли экосистему R для решения локальных, но сложных задач по автоматизации работы с данными и можем уверенно утверждать, что средства R в конфигурации 2016 года обладают всеми необходимыми свойствами для успешного решения этих задач.
Интенсивное развитие пакетов R по работе с данными и средств интерактивной визуализации, приобретение Microsoft коммерческой ветки R дает все основания полагать, что в ближайшие 2-3 года возможности экосистемы R многократно вырастут. В частности, активное развитие PowerBI и включение R в SQL Serever 2016, обязательная поддержка ведущими системами визуализации (из популярных в России это Qlik и Tableau) тесной интеграции с R, поддержка кластерных вычислений работа с Big Data платформами в enterprise редакциях и прочие интересные инициативы явно указывают на большой потенциал R экосистемы в бизнес-задачах.
Но ждать чудес еще несколько лет нет никакого смысла. Уже сейчас можно засучить рукава и попробовать заняться автоматизацией бизнес-задач на R, каковых в любой компании может быть не один десяток. Экономия средств для компании обеспечена, фан и вызов для исполнителей – обеспечен в квадрате.
Предыдущий пост: «Инструменты Data Science как альтернатива классической интеграции ИТ систем»
Следующий пост: «Джентельменский набор пакетов R для автоматизации бизнес-задач»
