Comments 29
А что касается тематики и нумерации формул: эта статья «база» для дальнейших более IT-шных статей по анализу данных (чтобы ставить ссылки на конкретные формулы, собранные вместе).
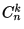 , либо как
, либо как  , но не как
, но не как  .
.Вот исходник:
\begin{tikzpicture}[mark=*,mark size=1,only marks]
\begin{axis}[
yticklabel style={/pgf/number format/fixed},
ymax=0.25,
width=10cm,
declare function={binom(\k, \n, \p)=(\p^(\k))*((1-\p)^(\n-\k))*factorial(\n)/(factorial(\n-\k)*factorial(\k));}
]
\addlegendimage{blue}
\addlegendimage{green}
\addlegendimage{red}
\foreach \n/\p/\c in {20/0.5/blue, 20/0.7/green, 40/0.5/red} {
\foreach \k in {0,...,\n} {
\edef\temp{\noexpand
\addplot[\c] coordinates {(\k,{binom(\k, \n, \p)})};
}\temp
}
\edef\temp{\noexpand
\addlegendentry{$p=\p, n=\n$}
}\temp
}
\end{axis}
\end{tikzpicture}
В тексте была откуда-то скопированная png-картинка. Моя svg-картинка сделана в латехе с пакетом tikz. Способ не без проблем: человеку без опыта тяжело сразу готовить такие картинки. Зато исходник можно править на лету, не перерисовывая картинку. Я вот за 5 минут поменял точки на столбцы, и диаграмма стала понятнее:
Такие диаграммы красивее. Я взял материал со страниц википедии (в тексте приведены ссылки). Если для кого-нибудь действительно совсем несложно переделать графики — Вы можете улучшить Вики.
Сам бы занялся, но не владею технологией построения настолько красивых диаграмм :)
(Хотя, уже захотелось освоить)
Переделать — не сложно, но и не просто :)
Хотите освоить — посмотрите введение к официальной документации tikz. В нем последовательным усложнением строятся полноценные примеры графиков и диагамм. Это хорошая отправная точка.
Кстати, в R есть прекрасные библиотеки. Тот же «классический уже» ggplot2 или seaborn + несколько библиотек интерактивных графиков.
Ну и R, по ощущениям, очень прекрасен для статистики и EDA. Самое главное— побороть непонимание синтаксиса самого R.
Вот очень хорошая вводная статья про виды распределений: Common Probability Distributions: The Data Scientist’s Crib Sheet.
Что касается «дз» это тизер готовящейся к публикации работы. Идея такова: мы не можем знать всё обо всех стратегиях, но может поступить по аналогии с тем, как строятся другие стат.тесты, а именно, построить распределение профитфактора для системы, торгующей случайно. Тогда значение профитфактора реальной системы должно быть таковым, чтобы случайное достижения такого значения являлось маловероятным.
Домашнее задание смахивает на задачку с подвохом. Требуется смоделировать множество биржевых систем (тут требуются знания предметной области на уровне бога) и напрямую получить распределения аналитически или откуда-то взять статистику по биржевым системам, подобрать для нескольких дающих надежду распределений оптимальные параметры (оптимизационная задача) и выбрать среди полученных конкретных распределений наиболее точные?
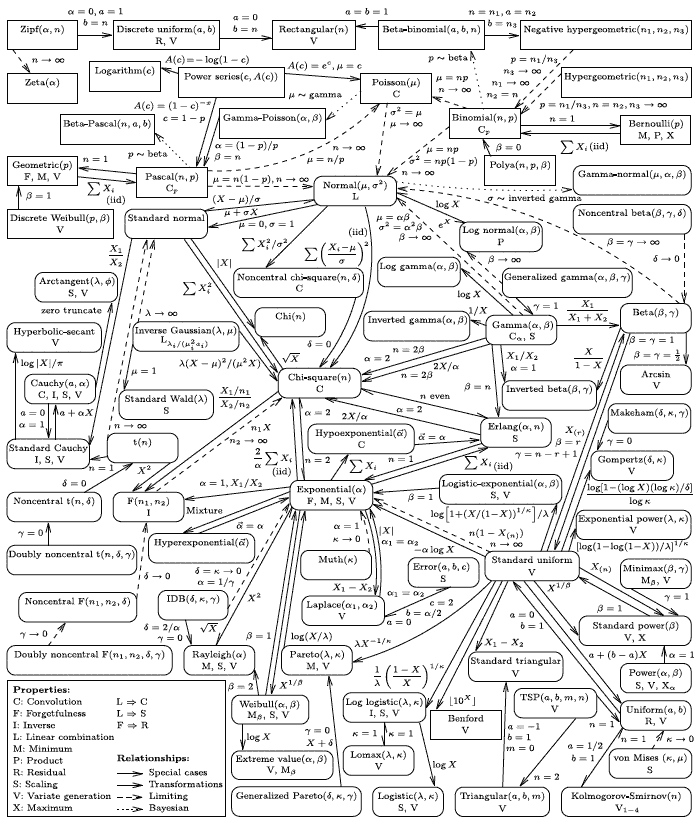
Ну, и с подробностями: http://www.math.wm.edu/~leemis/chart/UDR/UDR.html
Спасибо!
У меня вообще подозрение, что почти все непрерывные распределения должны укладываться в форму , где
и
— полиномы. Либо являться подстановкой функции (например, нецелой степени либо логарифма) от
вместо аргумента в эту формулу.
Кто-нибудь встречал подобные обобщение?
Знакомый психолог публиковала в зарубежном журнале статью, где математических претензий не было, а отфутболивали именно из-за отсутствия обоснования применимости использованных распределений, пока не были найдены необходимые подтверждающие ссылки.
Студентам буду на зачёт задание давать: воспроизвести граф по памяти :)
— например, пила вдоль линии y = int(x)-frac(x)
так и дифференцируемые отображения, для которых обратные не дифференцируемы
— например, с седловой точкой, y = x3 (при том, что оно биективно)
Откуда взял себе, к сожалению, не помню.
«Правда, чистая правда и статистика» или «15 распределений вероятности на все случаи жизни»