Comments 35
Отличчя стаття. Особенно гениальны примеры. Не смотря на знание предметной области, прочитал от начала до конца для того, что б освежить память. Продолжайте в том же духе!
Вот классная анимация методов оптимизации. Там интересно поиграться с шагом градиентного спуска.

Стиль изложения нравится, единственное – напрягает такое отображение формул. Хабр нынче и LaTeX поддерживает.
очень хороший стиль изложения, буду ждать продолжения… прямо даже интерес появился к теме нейросетей
Очень полезная статья. Хорошее продолжение первой части
Бывают ли ситуации, когда разные элементы обучающей выборки двигают веса в противоположные стороны, и сеть не обучается?
Есть разные способы/формулы для вычисления ошибки результата НС: половина квадрата Евклидового расстояния, логарифмическое подобие и т.д. Возможно я это упустил, но какой тип используется здесь? И как изменяться формулы в статье, если мы захотим использовать другой тип?
По сути это вполне логично, так как если входной сигнал какого-то нейрона — 0, то и веса всех исходящих ребер домножатся на 0 и не повлияют на ответ, а значит, мы не сможем оценить, какую ошибку внес вес этого ребра. Или я чего-то не понимаю?
Если я все-же прав, то в общем случае outA в формуле градиента можно выразить как wAB * outputA, где outputA = f(inputA), при этом для входных нейронов f(x) = x, для остальных f(x) = sigmoid(x)?
Автору большое спасибо за статью! Жду продожения
Первая статья читалась легко, с этой есть непонимание
Вопросы:
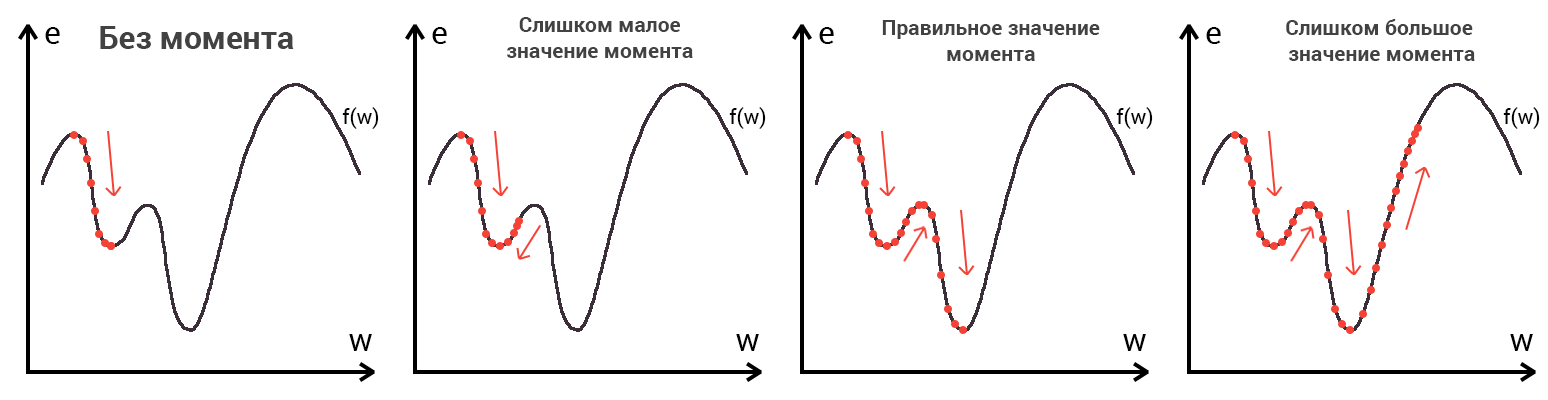
1. В поиске минимума Вы упоминаете момент. Не понятно что это.
2. Насколько я понимаю, в зависимости от вида функции, у нее может быть очень много минимумов, причем глобальный минимум может быть очень узким. В таком случае найти его будет сложно — не зная устройства функции нужно фактически делать перебор огромного количества значений.
При этом, насколько я понимаю, входные параметры (это W(i) ) могут меняться в широких пределах (каких?).
Почему тут
нас не устроил последний вариант? Ведь там может быть спуск еще ниже.
Отсюда выводы:
а. либо нам на самом деле не так важно найти глобальный минимум
б. либо мы что-то знаем о функции, из-за чего можем считать, что этот минимум — нужный.
2. Вы упоминаете «дельту», но не ввели это понятие. Судя по формуле 1: ДельтаО=(Идеальное значение — реальное значение)* производную функции активации,
Эта ДельтаО по сути — то, насколько (и куда, это же вектор?) надо сместиться, чтобы предположительно попасть в минимум.
Что такое Дельтаh и Дельтаi — не понял.
Видимо, вы описываете то, насколько изменится выход конкретного нейрона (Делтаh) при изменении его входов (Делтаi). Но непонятно почему тогда это не работает с выходным нейроном — он же работает по тому же принципу.
Дельта это просто обозначение параметра. За ним нет никакого глубокого значения. Некоторые НС вообще используют другой алгоритм, в котором нет такого параметра как дельта.
Если мы не опираемся на вид функции f(w), то давайте представим эту функцию так:

Точка старта обозначена пересечением красных линий. Я не понимаю как этот алгоритм найдет глобальный минимум на указанном интервале.
Соответственно, где-то я ошибаюсь.
Я подозреваю, что функция не может иметь такого вида (для любого одного нейрона с обычной функцией активации эта функция должна имеет более простой график, чем я указал) и в следствие этого алгоритм градиентного спуска видимо работает корректно.
Про момент написано почти в конце, а в этом месте уже очень большой накопившийся градус непонимания.
Первая картинка (анимация) после «Что такое Метод Обратного Распространения (МОР)?» показывает совсем другие формулы. При вычислении ошибки там не умножают на производную. Умножение на производную происходит при коррекции весов, при этом результат будет уже другим.
И такая строчка
«Запомните, что после подсчета дельты нейрона мы обязаны сразу обновить веса всех исходящих синапсов этого нейрона. Так как в случае с O1 их нет, мы переходим к нейронам скрытого уровня ...»
Вроде, зная дельту нейрона, мы можем обновить веса не исходящих, а входящих синапсов этого нейрона, в случае О1 они есть и их можно обновить.
Сейчас, конечно, 2023 уже, но статьи хорошие. Для не математиков в самый раз.
Нейронные сети для начинающих. Часть 2