Comments 64
С архитектурой немного проще, для работы серверов достаточно простейших VPS (1 CPU + 512 МБ это даже с большим запасом). На серверах Nginx + PHP 7 (php-fpm) + Redis. Основной упор шел на общую отказоустойчивость и скорость получения данных.
Изначально база для учета запросов была на MySQL (точнее MariaDB), но потом от неё отказались в пользу Redis, а также схемы в которой есть пара контролирующих серверов (на них весит MySQL для общего учета, и синхронизации). Контролирующие сервера выполняют синхронизацию статистики между всеми рабочими серверами (сейчас их уже 11), она выполняется раз в минуту. Также если контролирующие сервера обнаруживают падение или неадекватное время ответа одного из рабочих серверов — с помощью API меняется DNS запись (TTL 60 секунд) и запросы идут на ближайший рабочий сервер.
На серверах Nginx
Я решил Nginx не использовать, чтобы не заморачиватся с лишним деплойментом. У меня openSSL, epoll через яву.
Насчёт Nginx, как-то в этом деле больше доверяю проверенному хайлоад решению, да и что там его деплоить. Добавить официальный репозиторий? Конфиг написан таким образом, что он подходит для любого сервера (отличие только в одном подключаемом файле, который добавляет в заголовки ответа реальное название и гео-расположение сервера).
В дальнейшем планируется перейти на Nginx + Go + Redis, пробовал Go + Redis, но пока как-то стремновато :)
В Java же сама виртуальная машина много памяти жрёт
На самом деле — нет. Жрут лишь библиотеки которые вы подключаете. Напимер hello world на java сам по себе будет потреблять лишь пару Мб памяти.
Насчёт Nginx, как-то в этом деле больше доверяю проверенному хайлоад решению
Джава тоже проверена временем и нагрузкой :). + я подключаю это через netty (готовый фреймворк). + по слухам netty быстрее Nginx (не проверял).
В дальнейшем планируется перейти на Nginx + Go + Redis, пробовал Go + Redis, но пока как-то стремновато :)
Думаю в Вашем случае должно взлететь.
В принципе.
По той причине, что DNS кэшируется.
И кто второй с кэширующего сервера возьмет ваш IP-адрес — уже никак вы к географии не привяжите.
Так что не всё так плохо, тем более, что есть возможность указать на какой конкретно сервер вы хотите заходить для получения данных.
А все 1000 вторых, кто запросят адрес в промежутках между ними (если их провайдер кэширует с того же вторичного DNS) — получат именно кэш.
Кстати, вы знали, что многие дешевые домашние роутеры кэшируют DNS намертво и игнорируют TTL вплоть до своей перезагрузки?
Так как запрос к GeoDNS идет вовсе не с клиента — то Geo может сработать только относительно DNS-серверов, а не конечных клиентов.
А еще многие используют независимый от провайдера 8.8.8.8 и т.п. — тут ситуация еще хуже.
То есть если DNS провайдера хоть о чем то может сказать, то 8.8.8.8 не говорит вообще не об чем.
;)
GeoDNS, возможно, может как-то распределять (балансировать) запросы.
Но свою функцию Geo именно в смысле DNS он выполнить не сможет в принципе, — ибо таковы принципы устройства DNS.
Многоуровневость DNS мешает это сделать.
А все 1000 вторых, кто запросят адрес в промежутках между ними (если их провайдер кэширует с того же вторичного DNS)
Так я об этом и говорил, вот есть к примеру у нас два сервера один в Нидерландах, другой в Германии, вроде как совсем рядом, но при этом в Германию трафик в 10 больше. Если бы GeoDNS не работал, то как вообще попадают на нидерландский сервак? И если бы работал именно так как Вы пишете, то трафик бы распределялся скачкообразно. Т.е. зашел чел из Германии весь трафик в течении минуты идет в Германию, в следующую минуту первым зашел из Нидерландов — минуту все идут в Нидерланды. Но такого поведения не наблюдается. Также весьма быстро в течении пары минут весь трафик перекидывается с одного сервера на другой, так что теории о том, что куча DNS игнорируют TTL также не подтверждаются на практике.
Понятное дело, что GeoDNS не идеальны, но в целом на практике показывают себя вполне неплохо. По крайней мере это справедливо для Anycast GeoDNS (возможно, если бы юзали свой сервак с патченым BINDом, было бы хуже). Да и в нашем случае, поскольку данные синхронизируются — не страшно, если человек попадет не на тот сервер.
Вот для примера выполнил с 6 серверов (Украина, Россия, Германия, Нидерланды, США, Франция).
nslookup api.sypexgeo.net 8.8.8.8
Запрос выполнялся одновременно (в Xshell, отправить команду во все сессии). Все 6 выдали разные IP, соответствующие настройкам GeoDNS, хотя все запросы идут к 8.8.8.8, и по вашей теории, все должны получить одинаковые IP.
Для нас сейчас единственная проблемка с GeoDNS — что нет разделения крупных стран на регионы. К примеру в России у нас 4 сервера раскиданных по стране, но нормально раскидать трафик по ним нельзя (чтобы люди из Владивостока не отправлялись в Москву). Хотя в Zilore и обещают добавить такой функционал.
Вы только забыли, что подобные DNS обычно работают по Anycast. Даже тот же 8.8.8.8 это не один сервак и соответственно кэширующие сервера на пути к DNS так же разные оказываются. Да и сам 8.8.8.8 из разных регионов будет выдавать разные IP серверов.
1. Провайдеровские DNS — работают без каких либо Anycast. А вот у крупных хостеров — у тех да, бывают реализации с Anycast. Но только у крупных. Это отнюдь не общепринятая практика, а редкое, но приятное исключение.
2. Но это не имеет никакого значения. На самом деле с Anycast GeoDNS работает еще хуже. Из-за временного сбоя/аварии/просто задержке на каком-то маршруте клиент свяжется вовсе не с ближайшим сервером.
3. Строго говоря, Anycast реагируется не столько на географию, сколько на связанность в интернете.
4. В цепочке определения адреса IP по имени DNS может быть вовсе два сервера.
Вывод:
GeoDNS как-то там распределяет адреса.
Но нет никакой гарантии, что делает это географически корректно.
Ошибка может быть на внесена в десятке мест.
Т.е. зашел чел из Германии весь трафик в течении минуты идет в Германию, в следующую минуту первым зашел из Нидерландов — минуту все идут в Нидерланды.
Отнюдь.
Пути в интернете не меняются каждые 60 секунд. Они не зависят от TTL DNS.
Поэтому при повторном обращении DNS-сервера хостеров стабильно перекидывают клиентов на все те же сервера (если за время предыдущего 60-ти секундного интервала не было аварий в интернете и пути не перестроились).
Понятное дело, что GeoDNS не идеальны, но в целом на практике показывают себя вполне неплохо. По крайней мере это справедливо для Anycast GeoDNS
Они всего лишь хоть как-то балансируют трафик.
Но без гарантий, что будет выбран ближайший сервер.
Люди, имеющие тяжелый трафик, для которых это важно — разбирались с вопросом гораздо глубже, чем вы. И сделали неутешительный вывод: балансировка по DNS не работает. От слова совсем.
https://habrahabr.ru/company/ivi/blog/237349/
Что касается статьи Вы вообще читали её? Они рассматривали GeoDNS на собственном отдельном сервере. Понятное дело, что если пускать весь трафик на один DNS сервер в Москве, который будет раскидывать по другим серверам, то это далеко не то же самое, что использовать Anycast GeoDNS от того же Zilore. Опять же, что касается Google DNS у человека в статье сугубо теоретические заблуждения, которые опровергаются, тем же nslookup с разных серверов, вот скриншот.
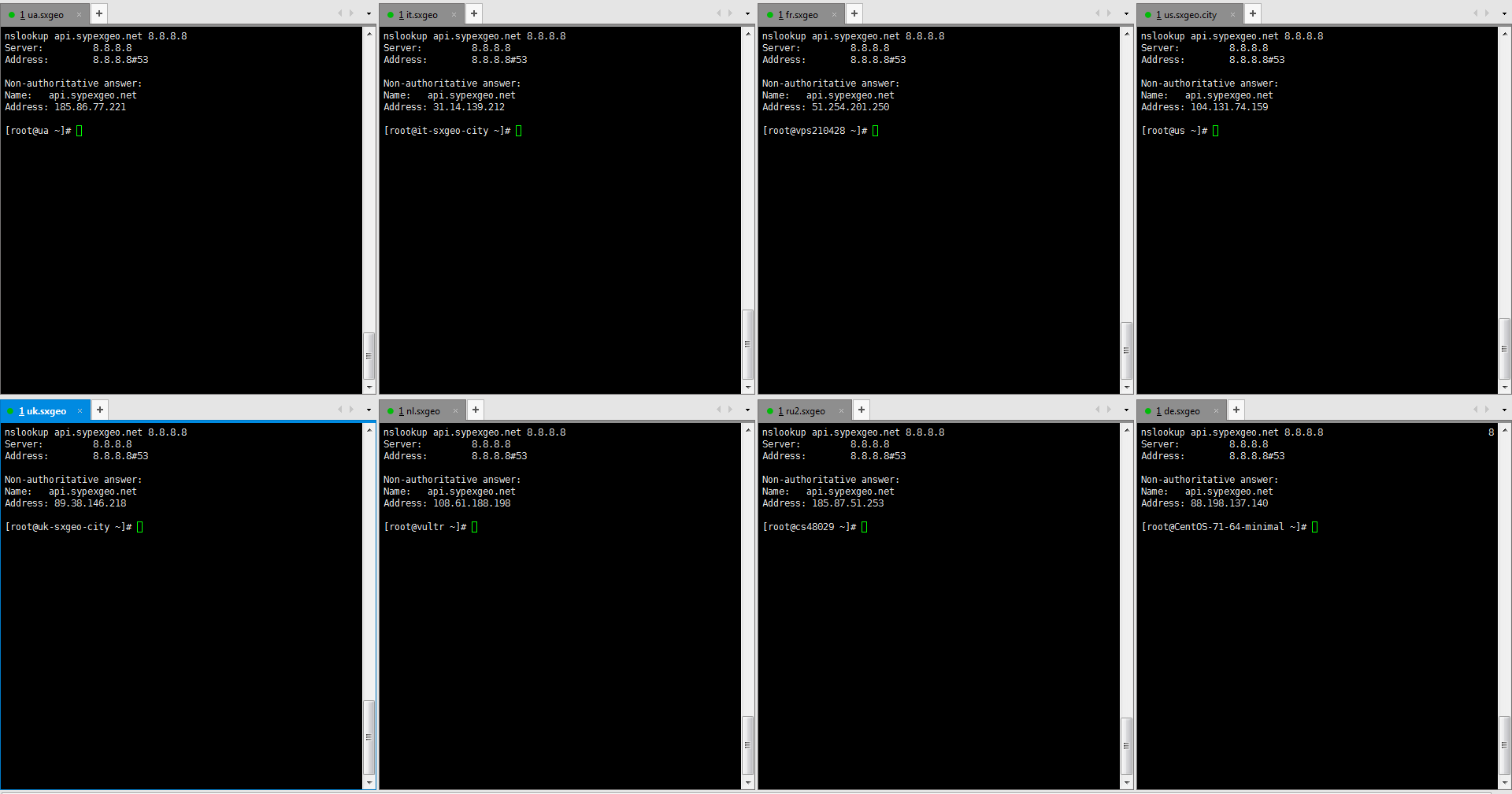
Как GoogleDNS выдал 8 разных IP для одного адреса? Так, что говорить о том, что GeoDNS не работает совсем — это заблуждение. Да я согласен, что он не всегда оптимально работает (так как у некоторых провайдеров, может трафик весьма загадочно ходить), и лучше бы было Anycast решения, но это уже зависит от рентабельности. И то, что не подходит для CDN, вполне подходит для сервисов у которых множество легких запросов, а не раздача кучи видео-контента.
Они рассматривали GeoDNS на собственном отдельном сервере.
Небольшое уточнение. Мы используем Amazon сервера из Route 53.
Кстати, вполне здравый подход.
У меня так разрабатываемый мною интернет-магазин года 3 работал.
Сейчас БД пихают где надо и не надо. А она во очень многих случаях вовсе не нужна.
Что вы так привязались к tomcat'у? Нормальный контейнер. У меня на ноуте стартует аж целых 55-60 ms, ужасно медленно.
Все пользовательские данные хранились просто в памяти и периодически сбрасывались в файлы
Дело хорошее, но предпочтительнее писать сначала во временный файл, а потом делать атомарный move. Тогда больше шансов не остаться без базы ,)
Сначала я поддался хайпу и реализовал данный подход на apache spark.
Как-то spark выглядит для такой задачи совсем странно. Не говоря уже про то, что он не относится к миру энтерпрайза.
Да, я нищеброд и наивный чукотский юноша. Я думал что смогу поднять одну ноду кассандры на самой дешевой виртуалке у ДО за 5$ — 512 MB RAM, 1 CPU. И я даже прочитал статью счастливчика, который поднимал кластер на Rasp PI. К сожалению, мне не удалось повторить его подвиг. Хотя я убрал/урезал все буферы, как было описано в статье. Поднять одну ноду кассандры мне удалось лишь на 1Гб инстансе, при этом нода сразу же упала с OOM (OutOfMemory) при нагрузке в 10 рек-сек. Более-менее стабильно кассандра себя вела с 2ГБ. Нарастить нагрузку одной ноды касандры до 1000 рек-сек так и не удалось, опять OOМ.
Вы хоть раз в её документацию-то заглядывали? "For both dedicated hardware and virtual environments: Production: 16GB to 64GB; the minimum is 8GB."
Что вы так привязались к tomcat'у? Нормальный контейнер.
Теперь уже да. Просто плохие воспоминания остались.
Дело хорошее, но предпочтительнее писать сначала во временный файл, а потом делать атомарный move. Тогда больше шансов не остаться без базы ,)
Согласен.
Как-то spark выглядит для такой задачи совсем странно.
Как по мне как раз идеально подходит под эту задачу.
Вы хоть раз в её документацию-то заглядывали?
Конечно. Та страничка из которой Вы это взяли появилась лишь в 2016 году.
Как по мне как раз идеально подходит под эту задачу.
Конечно, на вкус и цвет, но у вас очень уж ограниченное по серверным ресурсам приложение, без минимально разумного количества памяти (напомню, что spark как раз и интересен возможностью выполнения стадий в памяти) и небольшой объем данных. Почему вы считаете, что он идеально подходит?
Конечно. Та страничка из которой Вы это взяли появилась лишь в 2016 году.
Они чуток реорганизовали документацию, но это не важно. Я помню аналогичные рекомендации ещё в районе C* 0.8. Вот, например, 2013 год из cassandra-user.
Ну и распери тоже разные. Последние версии уже мощнее моих продакшн серверов.
У OVH лучше всего, с чем с ними мало кто сравним — это дешевые дедики.
Правда они на никаком железе (если другие вещи не особо критичны, то не ECC-память это существенный минус для серьезного проекта), что создает определенные риски.
Опытные люди знают, что если у вас серьезный проект — на 1 сервер в OVH полагаться нельзя. И рассчитывать на быстрое получение второго сервера в произвольный момент времени — тоже нельзя. На OVH нужно подстраховаться заранее.
Да, можно (и даже нужно если у вас серьезный проект) резервировать сервера. Современная традиция даже 3 сервера рекомендует, а не 2.
Но тут еще важный минус — при поддержании запасных серверов в актуальном состоянии вам их нужно синхронизировать. И тут в OVH вы можете запросто схлопатать бан из-за того, что пытаетесь синхронизироваться со своим же вторым сервером. Вас посчитают за хакера.
А DO — это прежде всего автоматизированные облачные технологии.
То облако, что делает OVH и в подметки не годится облаку DO.
Да и железо у DO совсем другого класса надежности.
Субъективно — их маленькие ARM-сервера довольно неплохи, с ними не видно минусов виртуальных инстансов и удобный API для управления работающими инстансами. 4 ядра о двух гигабайтах, 50 гигабайт SSD выйдут в 3 евро.
Однако меня огорчает отсутствие того же ECC и IPv6, отсутствие ARM64 и не слишком большая адекватность накопителя — он подключен из СХД по NBD.
Виртуальные инстансы в DO крутяться на Хеон-овом железе. И ресурсов DO выделяет по честному.
ARM же тянет только простую нагрузку.
За 4 евро можно взять небольшую VDS сопоставимых по памяти и намного лучших по процессору характеристик, построенную на базе системы с ECC и RAID и без страшного оверселлинга.
ARM вариант потерял всякий экономический смысл когда появились x86 виртуалки по такой же цене, и с тем же кол-вом RAM, куда я успешно и смигрировал впоследствии.
Судя по тому что я читал на местных форумах самоподдержки, люди в основном его используют для автосборок/тестирования под спец-железо.
А напишите статью о том как нашли первых пользователей, как проект начал «взлетать» и.т.п.
Очень интересно.
К сожалению, на хабре меня забанили за эти статьи. Поэтому я опубликовал их на украинском ресурсе:
Как мы запустили свой pet-проект: первый успех
Blynk: Как мы запустили свой pet-проект. 30 дней спустя
Blynk: Первые питчи, клиенты и деньги
А почему забанили? Сам проект очень интересный!
У меня ж все наоборот, придумаешь что нить потратишь время и деньги, выясняется что людям не интересно.
Но читать такие статьи как ваша, очень заряжает! Значит идеи работают, люди интересуются. А значит и у меня есть шанс :-)
Мне вот любопытно, если бы это все строить с самого начала на GAE контейнерах, и использовать гугловый сторедж (https://cloud.google.com/storage/docs/storage-classes)- на сколько дешевле это бы получилоссь?
Мне вот любопытно, если бы это все строить с самого начала на GAE контейнерах,
Нашу задачу невозможно решить с помощью GAE контейнеров. Помимо того на GAE разрабатывать очень не удобно. Говорю как человек у которого там хостится несколько проектов :).
Все проблемы монолита выше — решались, но появлялась новая — при перемещении человека в другую зону — он будет попадать на другой сервер и у него ничего не будет работать. Это был осознанный риск и мы на него пошли
Все гораздо хуже.
Человек, живущий в Европе просто устанавливал в качестве DNS-сервера модный 8.8.8.8 и после этого детектится как американец.
;)
Он детектился как житель места, где находится ближайшая точка присутствия Google DNS.
Kibana
Платная, когда нужны фильтры по юзеру.
Graphite+Grafana
Вроде такая же проблема как у Кибаны.
Ну и эластиксерч очень прожорлив сам по себе.
Хотя, конечно, надо точно знать ваш случай использования.
Нужно чтобы пользователь который лоигинится в приложение видел только свои данные.
а для него есть некоторый выбор готовых скриптиков, типа https://github.com/prestontimmons/graphitejs
т.е. вы делаете свою страничку под юзера, с которой он может вызывать вышеназванный api, фильтруете его запросы на бэкенде, чтобы он из песочницы не вылез, и получается что-то вполне культурное.
собственно, с кибаной тот же подход применим.
Или RiakTS
Я решил не разворачивать БД в каждом из датацентров, а сделать одно общее хранилище
А не быстрее/надежнее ли было чтобы каждый регион работал со своей БД? Ведь насколько я понял, данные пользователей никак не связаны между собой и можно хранить разных пользователей в разных БД, так?
Плюс, в каждом дата центре можно иметь свой локальный кэш с IP адресами юзеров (redis), которых GeoDNS периодически шлет в этот конкретный дата центр.
А не быстрее/надежнее ли было чтобы каждый регион работал со своей БД?
Так и делаем. Сохранение в БД по сути лишь бекап данных.
Плюс, в каждом дата центре можно иметь свой локальный кэш с IP адресами юзеров (redis),
Частично так и есть. То есть кеш по сути есть для всех юзеров что принадлежат этому серваку и в редис запрос для них не делается. Кеш для всех пользователей не добавляю так как хочу иметь возможность мгновенно перенаправить траффик если понадобится.
app.sh start
app.sh stop
Я бы подумал, как бы делать всё это дело бесшовно. На вскидку:
- Делаем так, чтобы могло работать два экземпляра сервера одновременно (проблемы в данном случае, как я понимаю, могут быть в основном из-за эксклюзивного доступа к файлам, в которые пишите)
- Запускаем приложение на каком-нибудь левом порту, например, 8001
- Настраиваем iptables на форвардинг 80 → 8001
- Когда хотим обновиться, поднимаем второй экземпляр, например, на порту 8002
- Перенастраиваем iptables на форвардинг 80 → 8002
- Посылаем первому экземпляру сигнал на завершение, на который оно должно дообработать текущие запросы, а больше и не придёт.
- Done.
Тут главное разобраться с iptables, чтобы оно случайно на половине TCP соединения не стало пакеты перебрасывать, а только новые. Если нельзя так — придётся свой роутер пилить.
Ваш вариант тоже рабочий. Но он не подойдет если сам провайдер отключит виртуалку.
Вы говорите, что используете одну-единственную ноду postgres. Но разве этот факт не означает, что в итоге всем клиентам, допустим, из Азии приходится всё равно ждать долгие пинги до постгреса? Или дело в том, что соединение с постгресом выполняется не на каждый запрос к вашему сервису?
Или дело в том, что соединение с постгресом выполняется не на каждый запрос к вашему сервису?
Именно. Каждый сервер вообще не делет никаких запросов по сети в момент когда получает реквест. Периодически (раз в 1 мин) все апдейты, которые накопил сервер скидываются в БД и на локальный диск. Локальный диск выступает по сути кешем, чтобы не ходить в БД (так как БД далеко и это увеличивает задержку).
Система на момент внедрения обрабатывала уже 4700 рек-сек. К кластеру постоянно были подключены ~3к устройств.
Я правильно понял, что устройства у вас посылают 1.5 запроса в секунду? Что-то как-то много.
Делаю очень похожий по сути сервис для сбора телеметрии с умных устройств, но на Python+MongoDB+Redis, поэтому ваш пост очень заинтересовал. И масштаб у меня примерно тот же — 10к устройств.
Я правильно понял, что устройства у вас посылают 1.5 запроса в секунду? Что-то как-то много.
Обычно на 1 устройство стараются повешать побольше сенсоров. 3 параметра телеметрии на 1 устройство классика, а если не ограничен батареей то можно постоянно быть онлайн и слать.
12 млрд реквестов в месяц за 120$ на java