Кратко суть проблемы: нужно было много админок, написал генератор админок.

Как работает:
|
Содержание:
|
С чего началось
Дело в том, что мне постоянно приходилось верстать админки для разных сервисов. Новый проект, новый сервер, новая админка. Иногда они писались с нуля, иногда получались копированием. Где-то на 13й админке я приуныл. Захотелось внести разнообразия. Поэтому новая админка для отдела статистики была сверстана в стиле 98 винды. Далее, в срочном порядке, методом «почкования» была получена админка отдела лицензирования, а вслед за ней — админка нового игрового портала.
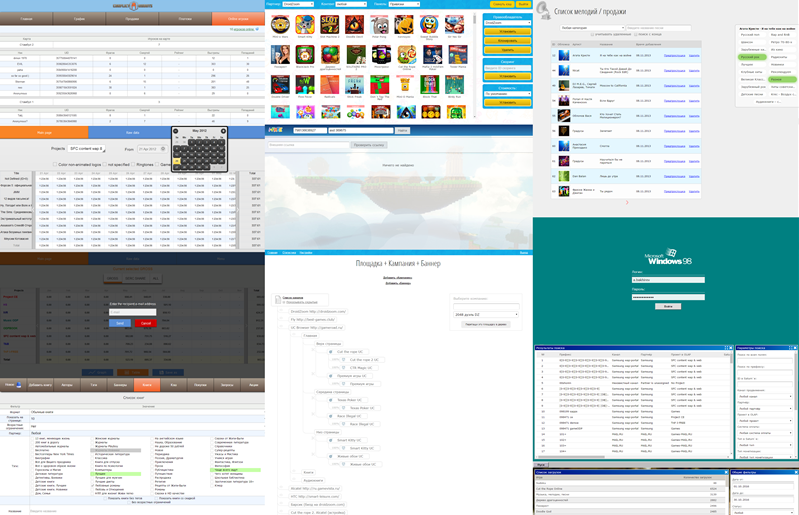
К этому моменту стало ясно, что некоторые компоненты одинаковы во всех проектах. Да и примеры использования также повторяются:
- вывести список;
- создать / редактировать / удалить элемент;
- назначить связь один ко многим или многие ко многим;
Далее был написан генератор, который по шаблонам создавал основную базу кода. Понятно, что все «хотелки» приходилось дописывать вручную, но это уже был большой шаг вперед. Ещё через три админки стало ясно, что генерировать нужно не только верстку, но, желательно, и API сервера и схему БД. Это нужно было не во всех проектах, но в мимолётных «чик чик и в продакшен» было самое то. Т.к. разные ветки админок получали фиксы разных багов, к концу лета стало очевидно, что было бы очень хорошо слить все фиксы в одну ветку и качественно обновить генератор. Именно этим я и стал заниматься по вечерам и выходным.

Масштабируемость уровня copy/past админок генератора первой версии

Есть ли готовые админки и генераторы админок?
Да, тысячи их. Что с ними не так:
- Заточенность под конкретный язык или фреймворк
Например, если вы используете Laravel (PHP-фреймворк), можете взять SleepingOwl. Но если у вас бекенд на Java, то без PHP её никак не прикрутить.
- Монолитность
Монолитность вытекает из предыдущего пункта. С одной стороны может быть очень крутая система, которая динамически меняет админку, в зависимости от схемы БД. С другой стороны, вы не можете эту связь убрать. Если вам нужна только верстка — будет больно. Так же будет больно, когда вы захотите подключить админку к вашей системе авторизации (во многих больших конторах есть единые системы авторизации, которые управляют доступом во все системы всех пользователей из одной точки управления).
- Заточенность под сайты
Наверное, половина генераторов админок собирают различные вариации CMS-систем. Некоторые из них очень крутые, но они принципиально не годятся для управления контентом. Если загнать в них базу книг, то вот так просто взять и раскидать 100 книг по категориям будет очень больно.
- Трудность кастомизации
Ну это и так понятно. «Нельзя сделать универсальную админку, каждый проект индивидуален» (с).
Чего очень сильно не хватает в админках:
Возможность создавать связь «многие ко многим» не переключаясь в режим редактирование контента. Пример: есть список из 100 игр, нужно быстро проставить им теги. В большинстве админок нужно открыть «редактирование игры», проставить тег, вернуться в «список игр».
Возможность пакетного проставления связей, удаления или редактирования. Пример: выбрать 15 баннеров и сразу назначить им другой канал продвижения.
Отсутствие логирования. Пример: смотрим контент и хотим тут же узнать, кто и когда его отредактировал, и что конкретно изменил.
Возможность сделать дубликат объекта и всех его записей одним кликом. Пример: сделать копию рекламной компании со всеми её баннерами и площадками.
Возможность импорта / экспорта данных в эксель. Пример: менеджерам нужно разово сверить в Excel контент и продажи, или отправить список чего-либо партнёрам.
Сложные фильтры поиска (по группе свойств и с исключением). Пример: выбрать все книги из категорий «Классика» и «Романы», кроме тех, чей id: 20, 30, 65, и тех, кто отмечен тегом «Хит продаж». В SQL мы такое с ходу сделаем, а у манагеров в адмике фильтры, как правило, такие фокусы сделать не дадут.
Исправлением этих проблем я и решил заняться. Понятно, что на самом деле, если ставить вопрос о кодо-генерации, то «хотелок» становится ещё больше. Тут нужен и вывод статистики, который тянет за собой анализ данных, и инструменты добавления «бизнес логики» для обработки влияния данных друг на друга и т.п. Тема очень обширна, но в виду ограниченности моей мотивации и человеко-часов разработки, все хотелки не реализовать. Пока хотелось бы закончить хотя бы минимальный базовый функционал.
Что конкретно можно сделать?
Забегая вперёд, логин/пароль: demodemo / qwerty123456 и права только на просмотр выставил (вдруг кто поломает и демки станут бесполезны раньше времени)

Прайс
Начнем с простого. Тут один парень радио-деталями оптом торгует. Нужно срочно прайс на сайте вывести с поиском. Всяких 1С-склад у него нет. Вжух, вывели: https://goo.gl/OIPQXv
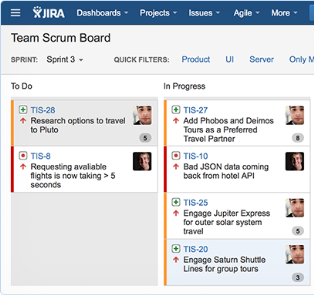
Пародию на JIRA
По традиции JavaScript разработчикам TODO лист полагается писать. Давайте напишем TODO лист группы компаний. Чтобы там были дочерние компании, подразделения, отделы. А внутри отделов уже задачи. Задачи раскиданы по работникам. У каждого работника два листа: текущие задачи и очередь задач на будущее. Ахалай-махалай, готово: https://goo.gl/6UWqRn (demodemo / qwerty123456)
Да, конечно. Ещё нужны комментарии к задачам и чтобы файлы можно было прикреплять. Это минимальный набор. Но эта админка сгенерирована на прошлой версии, которая ещё этого не поддерживала. В новой — уже исправлено.

CRM
Хотим свою CRM. Там будут компании, их офисы, и ключевые лица, раскиданные по офисам. Мы можем посмотреть описание компании или досье на каждое ключевое лицо, с которым непосредственно ведет работу наш менеджер (типа: карточка клиента). Далее нужна возможность создавать «событие», связанное с ключевым лицом (например: звонок, письмо, встреча). Ещё пусть будут отдельные списки: то что мы должны сейчас сделать, то что мы ждем от клиента, список косяков в наших взаимоотношениях. Эм… слабо всего семь объектов. Давайте ещё добавим отдельными сущностями разные типы клиентов (частны, юр. лица и т.д.) и разделение по профилю (перевозчики, тур операторы, отели и т.д.). Чик-чик, задеплоили: https://goo.gl/OcJU8g (demodemo / qwerty123456)
Наверное, нужны ещё всякие отчеты, счета и склад товара, но с одной стороны я даже не представляю как работает бухгалтерия и склад, с другой стороны, возможно им стоит сделать отдельную админку, т.к. это другие отделы с другими бизнес процессами.
Да, конечно, нужна ещё интеграция с АТС, рекламными площадками, и электро-почтой. Но это уже не «чик-чик демка» за 30 минут.
JSON на входе — редактор НСИ на выходе
В общем, суть такая — это редакторы номенклатурно-справочной информации (НСИ). Чем ближе ваш проект к редактору НСИ, тем больше вы получите «из коробки». Визуализацию данных, аналитику и логику пока придётся писать самим.
Но даже так можно набросать аля прототим ERP-системы. Собственно осознание этого очень сильно мотивировало к дальнейшим действиям. Далее путем поиска и просмотра разных демок стало понятно, что:
многие ERP системы уровня «стартап», не сильно превосходят по функционалу «чик-чик демку». Но из-за кодо-генерации «чик-чик демка» может сильно превзойти их.
многие ERP системы строятся по такому же принципу кода-генерации и развертыванию из кучи конфигов. Например, была такая штука «Эталон», которая, судя по описаниям, была один в один как этот велосипед, только под DOS. Опять же — тысячи их.
Зачем это вам?
Предположим, вы пишите на Java, и вас постоянно мучают Ангуляром. Тут вы сможете сгенерировать админку и не лезть во фронт. Ну или другой вариант — у вас по архитектуре надо создать много таблиц (да да да, я знаю что вы, Java-мены, можете схему из класса накатывать и наоборот — класс генерировать по схеме БД), но вдруг не все могут. Или схему нужно будет накатывать архитектору, который не пишет на Java, а только с базой работает. Или вы вообще чистый фронт и не можете осилить реляционные БД — тут, по крайней мере, констрейны будут и индексы хоть какие-нибудь (хотя понятно, что схему БД запорите своей «денормализацией», но вдруг). Ну или у вас руки горят от желания пилить стартап уровня «рокет сайнс», и нет желания заниматься бытовухой по созданию инфраструктуры проекта.
Ну для домашних проектов из трех таблиц сойдет. У нас бООООльшой проект, совсем другая история.
Нет :) Т.к. кодо-генерация и состав админки чуть менее чем полностью из конфигов, то можно развернуть проект из 1000 объект. Другой вопрос — зачем? Обычно больше 20 сущностей в одном проекте — боль (тут будет уже от 40 до 100 таблиц в БД). Поэтому большие проекты делят на микросервисы, а микросервис — это уже в районе 100 таблиц.
Плюс, мы можем задать отдельные настройки подключения к БД не только для каждой сущности, но и для её логов. Следовательно, «из коробки» мы можем писать логи в отдельную базу и оперировать сущностями из разных БД в одной админке.
Плюс, авторизация изначально сделана отдельным модулем, как раз из-за того, что админки собираются на конвейере и есть отдельная система управления доступом (привет любителям ЕСИА, ОИБ`у, Sonat`е, %ваша_система_управления_доступом%).
Немного о том, как это работает и сколько весит
Для начала нам нужно описать все сущности и их связи в виде JSON`а. Это один из самых трудных этапов.
{
"objects": [
{
"id": "distributionChannel",
"name": {
"logic": "DistributionChannel",
"logicSmall": "distributionChannel",
"layout": "distribution_channel"
},
"properties": {
"create": {
"name": { "tag": "input", "type": "string", "min": 1, "max": 50 },
"description": { "tag": "textarea", "type": "string", "min": 1, "max": 500 }
},
"update": {
"name": { "tag": "input", "type": "string", "min": 1, "max": 50 },
"description": { "tag": "textarea", "type": "string", "min": 1, "max": 500 }
},
"search": {}
},
"visualization": {
"main": {
"name": { "type": "string", "min": 0, "max": 50 }
},
"history": {
"name": { "type": "string", "min": 0, "max": 50 }
}
}
},
...
Далее запускаем ноду и создаем более подробные конфиги
node config
{
"objects": [
{
"id": "distributionChannel",
"name": {
"logic": "DistributionChannel",
"logicSmall": "distributionChannel",
"layout": "distribution_channel"
},
"aside": [
{
"id": "create",
"title": "Создание DistributionChannel",
"buttons": [
{ "tag":"popup_button", "icon": "menu", "value":"Меню", "id":"distribution_channel_aside_create_button_popup_menu" },
{ "tag":"popup_button", "icon": "search", "value":"Поиск", "id":"distribution_channel_aside_create_button_popup_search" }
],
"content": [
{ "tag":"input", "type":"string", "min":1, "max":50, "id":"distribution_channel_aside_create_name" },
{ "tag":"textarea", "type":"string", "min":1, "max":500, "id":"distribution_channel_aside_create_description" },
{ "tag":"button", "title":"Создать", "id":"distribution_channel_aside_create_button_create" }
]
}
Можем переставить поля, что-то добавить или вырезать. Далее генерируем уже код (который в основной своей массе тоже файлы конфигов)
node sql
node nodejs
node admin
(function () {
"use strict";
function ToggleStyleContentSearchConfig() {
return {
common: [
{ id: "content__search__processing", className: "hidden" },
{ id: "content__search__not_found", className: "hidden" },
{ id: "content__search__result", className: "hidden" }
],
processing: [
{ id: "content__search__processing", className: "loading__icon search_status__loading" }
],
notFound: [
{ id: "content__search__not_found", className: "search_status__message" }
],
result: [
{ id: "content__search__result", className: "search__container__result" }
]
};
}
module.exports = ToggleStyleContentSearchConfig;
})();
Когда файлы готовы, выполняем сгенерированный SQL (для создания схемы в БД). Копируем файлы сервера в отдельную папку. Деплоим. Осталось собрать статику
gulp
gulp easy
Статика соберется в один HTML файл, который нужно будет закинуть на сервер. Если все прошло успешно, можно попробовать пережать статику (-40% без или -8% с gzip)
gulp hard
Немного цифр:
- База данных (сейчас PostgreSQL, планирую добавить MySQL)
1 сущность = (1 таблица обьектов + таблица логов) + n * (таблица связи многие ко многим + таблица логов);
1 сущность = 5 процедур для объекта (создание + редактирование + удаление + поиск + получение одного объекта) + 4 процедуры логов (создание + удаление + поиск + получение одного лога) + n * процедуры для связей (создание + удаление + поиск) + n * логи для связей (создание + удаление + поиск);
Итого: (2 + n*2) таблиц и (9 + (n*3*3)) процедур, где n — число связей «многие ко многим»
- Сервер (сейчас NodeJS, планирую добавить PHP)
Всего шесть файлов, т.к. все удачно уложилось в экземпляр одного класса с конфигами.
- Клиент (JS ванила)
1 сущность = ~10 файлов HTML + ~50 файлов JS + n * (~25 файлов для связи многие ко многим)
Итого: Модель из 12 сущностей будет иметь примерно 50 таблиц, 160 процедур, 1000 файлов статики (HTML+CSS+JS). Статика после сборки и сжатия будет весить ~1мб (всё в одном HTML файле). Есть ещё «чудо-плагин», которым можно дожать после гугл-компилера до ~600кб, а на клиент после gzip прилетит ~85кб заменяем gzip на brotli, и дожимаем до 79кб. Большая часть файлов проекта (от 85%) — это однотипные конфиги аля JSON в обёртке. Поэтому проект можно очень гибко настроить после генерации файлов, и очень сильно сжать на сборке, и добавлять функионал copy/past`ом с поиском и заменой по папке.
Принципы, которые легли в основу велосипеда:
Верстка — это один HTML файл, не связанный с сервером. Единственное, что их связывает — формат AJAX-запросов и ответов. Хотите свой бекенд — смело заменяйте.
Бекенд не знает структуры БД, но знает названия хранимок и аргументы. Хотите свою схему БД — пишите свою.
Всё, что может быть описано конфигами — должно быть описано конфигами. Обычно они составляют более 85% файлов проекта (чем больше сущностей, тем больше процент).
Все файлы и конфиги должны быть разложены так, чтобы новый функционал можно было добавить copy/past`ом нужной папки. Понятно, что что-то все равно придется исправить руками в коде, но чем меньше этих моментов — тем лучше.
На самом деле нет. Этот аргумент уместен, если хранить бизнес логику в хранимках — тогда да. Но тут нет бизнес логики. Вся суть хранимок: отдать, создать, или изменить запись, без какой-либо логики. Ну и логирование не через тригеры, а только по запросу сервером соответствующей процедуры. Возникает вопрос: «А что делать, если мы захотим БД сменить? Хранимки придется переписать, а если бы через ORM — то нет.» Ну лично я, и никто из моих знакомых, не сталкивался с тем, что проект на ходу БД меняет. А если у вас возникнет такая ситуация, то, скорее всего, «переписать десять шаблонов генерации хранимок на другое подмножество языка SQL» будет самой меньшей проблемой.
Состояние проекта на текущий момент:
в сентябре практически с нуля пришлось все переделать. Зато поиск стал лучше, появились логи объектов, дизайн и т.п.
в ноябре начали появляться фичи и первые два сервиса с новой базой. Режим для левшей, смена позиции, лог связей, пакетная обработка и т.п.
в декабре пришлось переписать сервер, базу и поставить на раскорячку фронт. Думал, что до конца декабря успею собрать стабильную версию, но не успел. Тут уже общение с базой стало строго через процедуры, поиск по группам, поиск с исключениям, возможность добавлять комментарии и т.п.
Реализовано:
- создание/редактирование/удаление сущности;
- поиск с фильтрами, сортировкой и постраничной выдачей;
- создание/редактирование простой связи двух сущностей;
- возможность задавать/менять позицию;
- логирование создания/редактирования сущности;
- логирование создания/редактирования простой связи двух сущностей;
- просмотр логов;
- генерация кастомных селектов (список значений которых зашивается, а не подгружается);
- пакетное добавление/удаление связи (многие ко многим) для сущностей;
- симлинк на поле, чтобы пропустить его создание (для дата-биндинга, пример: одно поле партнёр, на все сущности в смалл панели). referenceElementId;
- генерация независимых списков сущностей;
- возможность менять размер рабочей зоны;
- поиск по списку id объектов;
- автоподстройка количества строк при поиске;
- подсветка поискового запроса в результатах поиска;
- режим отображения «для левшей»;
- вставка поиска (создание/редактирование) в случайное место. Например: коментарии к таске;
Мелкие баги:
- ошибка поиска: фильтр ref_channel_id. Нужно генерировать LEFT JOIN запросы для таких поисков и фильтров + доп. поля в форме поиска;
- починить вывод названия объектов в поиске для ref_ связей (пример lock, столбец cost);
- отображение детализации ошибок сервера;
- зачистка файлов + новая структура проекта. Нужно сделать более чистой финальную сборку сорцов;
- исправить поведение пакетного выделения объектов;
- починить расчет количества строка поиска для экрана;
- типизация данных в запросах;
- проверка файла перед перезаписью всегда пишет ошибку в консоль (которой по сути нет). Это напрягает, но не критично;
Не реализованный функционал:
- логирование смены позиции;
- отображение/редактирование вложенных в сущности массивов (например: список переводов, вместо названия или список платежек, вместо метода оплаты);
- определение порядка загрузки сущностей;
- определение связанных полей (автопереключение всех, при изменение одного. Например: смена партнёра или канала продвижения);
- загрузка файлов «на лету»;
- загрузка файлов «по списку»;
- выгрузить результаты поиска в CSV (экспорт);
- загрузить результаты из CSV (импорт);
- копирование реверсивное/не реверсивное;
- добавить восстановление состояний по логам (когда открыли детализацию состояния объекта);
- пакетное удаление сущностей;
- описание и вынос post-compressor`а в отдельный проект;
- удобный генератор для конфига в виде отдельного приложения;
- поправить логирование истории объектов. Поле is_remove сделать change_type (0 — создали, 1 — отредактировали, 2 — удалили)
- локализация;
- адаптация под мобильники/планшеты;
- создание клиентской витрины;
- фильтры поиска как массив, а не единственное значение (множественные «включающие» и «исключающие» выборки);
- возможность выбора экрана отображения (main/aside) для операций каждого типа;
- вложенные папки через поле parent_id. Есть поле — есть папка, есть изменение фильтра поиска;
- управление с клавиатуры;
- переделать экран приветствия. Вывести на него граф связи сущностей проекта (как в админке банеров);
- написать СЕО текст;
- подключить плагин пагинации скролом;
- продумать систему авторизации для сторонних проектов. Переделать модуль авторизации (убрать Draft User);
Не реализованный функционал по серверу:
- комментарии к таблицам в БД;
- проверка полей в объекте «сервиса», а не при создании «REST API»;
- генерация документации на методы API;
- модуль авторизации, не привязанный к Sonata;
- схема БД завязанная на доступ Партнёров или с наличием ограничений для пользователей;
- генерация сервера на PHP;
Огромным плюсом является то, что это не «теоретическая разработка». Каждый компонент уже был в старых проектах или есть на текущих. Соответственно, список «хотелок» и порядок их реализации продиктован болью эксплуатации (ну и опытом развития чужих генераторов админок).
Что в планах на ближайший месяц:
собрать в конце концов стабильную версию с процедурами
перекатиться на PHP, т.к. сервер на ноде в обычной шарашке не развернуть. Да и обслуживать проще и дешевле. (грубо говоря, за 1500 руб. на год уже можно развернуть админку на ~20 тыс. записей)
добавить работу с файлами
написать скрипт для установки из коробки, а то сейчас приходится полтора часа копаться, чтобы развернуть проект
(и это при том, что я знаю каждый файл в проекте).
Немного про UX
Писать основной функционал довольно скучно. Когда надоедает, переключаюсь на баги и фичи. Вот одна из них. Есть право-стороние и лево-стороние интерфейсы. Те кто локализацию делают — собирают два вариант (привет badoo). У меня ещё + 2 варианта: для левшей и правшей. Разница в том, что интерфейс зеркалится не полностью, а только панелями управления. Русскому левше удобнее пользоваться отзеркаленными панелями управления, но информацию в таблицах читать слева направо. А левше арабу — наоборот, европейская раскладка панелей, но обратный порядок колонок в таблице.
Правша европеец

Левша араб
Левша европеец
Правша араб
В разных проектах нужно разное соотношение зон «результаты поиска» и «редактирование элемента». Например, в книжном приложении для редактирования книг достаточно узкой панели справа. А в игровом приложении — изменение игры лучше делать в центральной части. Так же на это влияет предпочтения конкретного менеджера, который работает с проектом. Поэтому в новой версии соотношение зон «поиска» и «редактирования» можно менять в настройках.
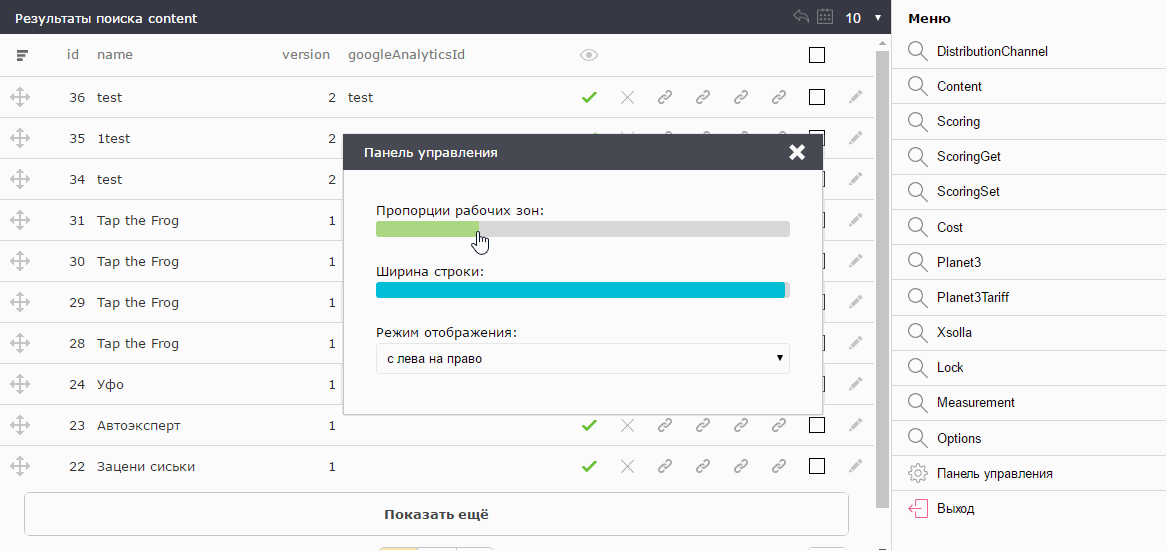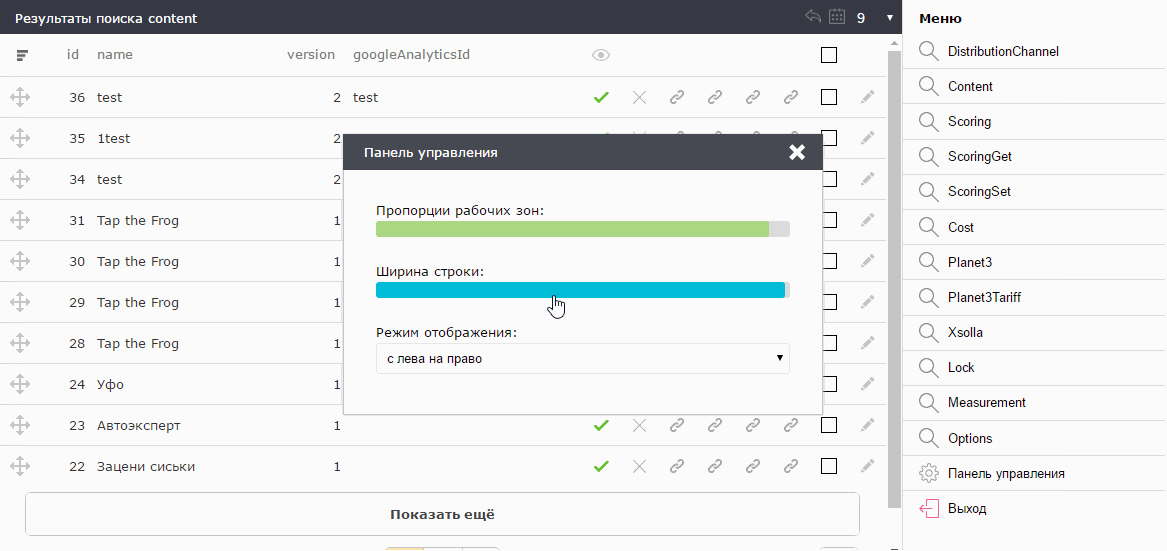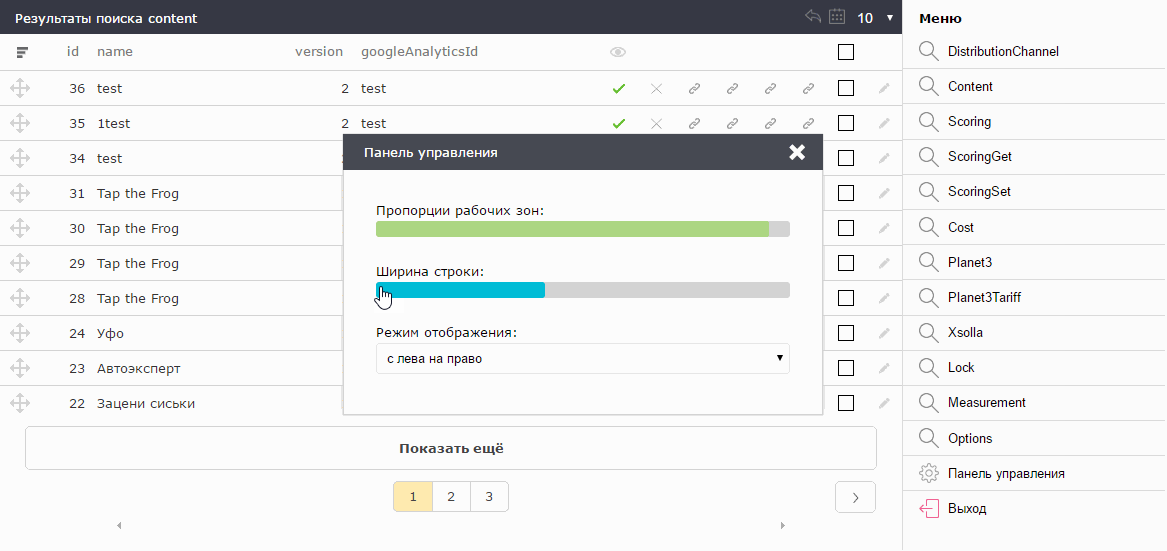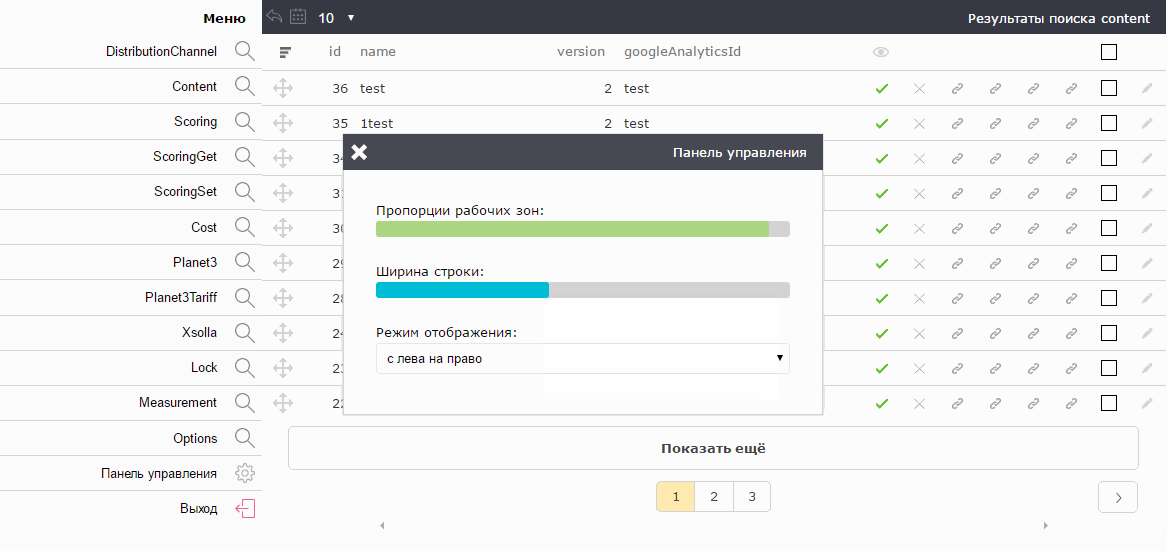
Те, кто работает со статистикой, как правило, много времени проводят в Excel или аналогичных программах. Они привыкли к строкам высотой примерно 16px. Те, кто работает с различными CMS сайтов и веб-мордами на bootstrap`е, привыкли к высоте строки в 32px. Поэтому высота строки так же вынесена в настройки.
Есть мнение, о том что скролл — зло. Почему так вышло — тема отдельной статьи. Я согласен с этим. Но указать точное количество строк, которые поместятся на экране невозможно, т.к. у всех разные мониторы. Поэтому, админка при старте вычисляет оптимальное количество строк для текущих настроек с данным монитором. Их всегда ровно столько, сколько максимально помещается на экране без создания вертикального скролла.
В заключение
Что думаете, коллеги?
Каталогизатор книг, деталей, или любой другой нормативно-справочной информации, с веб-мордой никому не нужен?
- это уже было в Django
- где ссылка на github?
- на реальном проекте не взлетит!
- фу, переписывать на PHP, ставлю минус!!!11
- где чарты? стата на главной — это база!
- нарезать конфиги != кодо-генерации
- всё глючит, продукт сырой
- интерфейс непонятный!
- почему нет React`а?
- это уже было…
- а где скачать установочный файл?
- без анализа данных оно не нужно!
- почему не MongoDB?
- LIKE это медленно!
- а документация будет?
- почему покрытие тестами нулевое?
- верстка не flexbox`ами, убей себя!
- а есть версия для мобильников?
- статья ни о чём!
- у меня вёрстка поехала!
