Короткая история метода
В короткой публикации [1] под названием “Авторство писателей можно узнать по специальной формуле” сообщалось, что в научном издании «New Journal of Physics», группа шведских физиков из университета Умео под руководством Себастьяна Бернгардсона описала новый метод, который позволяет на основе статистических данных определить автора текста. Исследователи проверяли, как в текстах трех писателей — Томаса Харди, Генри Мелвилла и Дэвида Лоуренса — реализуется так называемый закон Ципфа. Исследователи обнаружили, что частота появления новых слов по мере роста объема текста меняется у разных авторов по-разному, причем эта закономерность не зависит от конкретного текста, а только от автора.
Это сообщение было опубликовано 11.12.2009, а, более двадцати лет тому назад, Джон Чарльз Бейкер [2] ввел единицу для измерения способности автора использовать новые слова (здесь понятие «новые» трактуется как ранее не используемые в данном тексте). Джон доказал, что указанная единица является индивидуальной характеристикой автора.
В периодических изданиях и в сети отсутствует информация о реализации закона Зипфа для определения авторства. Поэтому моя работа является первым научным исследованием в указанной области.
Полный код программы
#!/usr/bin/python
# -*- coding: utf-8 -*-
import nltk
from nltk import *
from nltk.corpus import brown
stop_words= nltk.corpus.stopwords.words('english')
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.family'] = 'fantasy'
mpl.rcParams['font.fantasy'] = 'Comic Sans MS, Arial'
from nltk.stem import SnowballStemmer
stop_symbols = '.,!?:;"-\n\r()'
def comor_text():
# функция стемминга NLTK - быстрее яем словарна лемитизация
stemmer = SnowballStemmer('english')
# контроль корректности данных
if len(txt.get(1.0,END))!=1 and len(txt1.get(1.0,END))!=1 and len(txt2.get(1.0,END))!=1:
mrus=[txt.get(1.0,END),txt1.get(1.0,END),txt2.get(1.0,END)]
mr=3 # переменная для раздельного анализа графиков
elif len(txt.get(1.0,END))!=1 and len(txt1.get(1.0,END))!=1 and len(txt2.get(1.0,END))==1:
mrus=[txt.get(1.0,END),txt1.get(1.0,END)]
mr=2
elif len(txt.get(1.0,END))!=1 and len(txt1.get(1.0,END))==1 and len(txt2.get(1.0,END))==1:
mrus=[txt.get(1.0,END)]
mr=1
else:
txt3.insert(END,"There are no all texts")
return
# стемминг, отбор стоп слов и создание частотных словарей
for text in mrus:
v=([stemmer.stem(x) for x in [y.strip(stop_symbols) for y in text.lower().split()] if x and (x not in stop_words)])
#частотный словарь частота употребления слова - ранг
my_dictionary=dict([])
z=[]
for w in v:
if w in my_dictionary:
my_dictionary[w]+=1
else:
my_dictionary[w]=1
max_count=int(txt5.get(1.0,END))
min_count=int(txt4.get(1.0,END))
if len(my_dictionary)<max_count:
txt3.insert(END,"It is not enough of words for the analysis ")
return
#частотный словарь частота употребления слова - колличество слов
my_dictionary_z=dict([])
for key,val in my_dictionary.items():
if val in my_dictionary_z:
my_dictionary_z[val]+=1
else:
my_dictionary_z[val]=1
z.append(val)
z.sort(reverse=True)
# получение исходных данных для построения графиков частотного распределения
e=z[ min_count:max_count]
ee=[my_dictionary_z[val] for val in z][ min_count:max_count]
ee=np.arange(len(my_dictionary))[ min_count:max_count]
if text==mrus[0]: # расчёт гиперболическойй аппроксимации -a,b для первого документа + % новых слов
zz=round((float(len(my_dictionary))*100)/(float(len(v))),0)
tt=('In total of words (Text-1) --%i. New words --%i. Percen new words-- %i'%( len(v),len( my_dictionary),int(zz)))
xData1 = ee
yData1 = e
z=[1/w for w in ee]
z1=[(1/w)**2 for w in ee]
t=[ round(e[i]/ee[i],4) for i in range(0,len(ee)) ]
a=round((sum(e)*sum(z1)-sum(z)*sum(t))/(len(ee)*sum(z1)-sum(z)**2),3)
b=round((len(ee)*sum(t)-sum(z)*sum(e))/(len(ee)*sum(z1)-sum(z)**2),3)
y1=[round(a+b/w ,4) for w in ee]
s=[round((y1[i]-e[i])**2,4) for i in range(0,len(ee))]
sko=round(round((sum(s)/(len(ee)-1))**0.5,4)/(sum(y1)/len(ee)),4)
tg='Factor --a '+str(a)+' Factor--b '+str(b)+' Mistake of approximation-- '+str(sko)+"%"+"\n"+tt
txt3.delete(1.0, END)
txt3.insert(END,tg)
txt3.insert(END,'\n')
y1Data1=y1
elif text==mrus[1]:# расчёт аппроксимации -a,b для втого документа + % новых слов
zz=round((float(len(my_dictionary))*100)/(float(len(v))),0)
tt=('In total of words (Text-2) --%i. New words --%i. Percent new words-- %i'%( len(v),len( my_dictionary),int(zz)))
xData2 = ee
yData2=e
z=[1/w for w in ee]
z1=[(1/w)**2 for w in ee]
t=[ round(e[i]/ee[i],4) for i in range(0,len(ee)) ]
a=round((sum(e)*sum(z1)-sum(z)*sum(t))/(len(ee)*sum(z1)-sum(z)**2),3)
b=round((len(ee)*sum(t)-sum(z)*sum(e))/(len(ee)*sum(z1)-sum(z)**2),3)
y1=[round(a+b/w ,4) for w in ee]
s=[round((y1[i]-e[i])**2,4) for i in range(0,len(ee))]
sko=round(round((sum(s)/(len(ee)-1))**0.5,4)/(sum(y1)/len(ee)),4)
tg='Factor --a '+str(a)+' Factor--b '+str(b)+' Mistake of approximation-- '+str(sko)+"%"+"\n"+tt
txt3.insert(END,tg)
txt3.insert(END,'\n')
y1Data2=y1
elif text==mrus[2]:# расчёт аппроксимации -a,b для третьего документа + % новых слов
zz=round((float(len(my_dictionary))*100)/(float(len(v))),0)
tt=('In total of words (Text-3) --%i. New words --%i. Percent new words-- %i'%( len(v),len( my_dictionary),int(zz)))
xData3 = ee
yData3=e
z=[1/w for w in ee]
z1=[(1/w)**2 for w in ee]
t=[ round(e[i]/ee[i],4) for i in range(0,len(ee)) ]
a=round((sum(e)*sum(z1)-sum(z)*sum(t))/(len(ee)*sum(z1)-sum(z)**2),3)
b=round((len(ee)*sum(t)-sum(z)*sum(e))/(len(ee)*sum(z1)-sum(z)**2),3)
y1=[round(a+b/w ,4) for w in ee]
s=[round((y1[i]-e[i])**2,4) for i in range(0,len(ee))]
sko=round(round((sum(s)/(len(ee)-1))**0.5,4)/(sum(y1)/len(ee)),4)
tg='Factor --a '+str(a)+' Factor--b '+str(b)+' Mistake of approximation-- '+str(sko)+"%"+"\n"+tt
txt3.insert(END,tg)
txt3.insert(END,'\n')
y1Data3=y1
if mr==3: # построение графиков для первого и третьего документа + среднее расстояние между их аппроксимацией
r12=round(sum([abs(yData1[i]-yData2[i]) for i in range(0,len(xData1))])/len(xData1),3)
txt3.insert(END,"Average distances between art products of the author K--"+ str(r12))
txt3.insert(END,'\n')
r13=round(sum([abs(yData1[i]-yData3[i]) for i in range(0,len(xData1))])/len(xData1),3)
txt3.insert(END,"Average distance between art products of the authors K and M--"+ str(r13))
txt3.insert(END,'\n')
plt.title('Distribution of frequencies of use of words in the text', size=14)
plt.xlabel('Serial number of new words', size=14)
plt.ylabel('Frequency of the use of new words', size=14)
plt.plot(xData1, yData1, color='r', linestyle=' ', marker='o', label='Test art product of the author -К')
plt.plot(xData1, y1Data1, color='r',linewidth=2, label='Approximation of hyperbola y=(b/x)+a')
plt.plot(xData2, yData2, color='g', linestyle=' ', marker='o', label='Comparable art product of the author -К')
plt.plot(xData2, y1Data2, color='g',linewidth=2, label='Approximation of hyperbola y=(b/x)+a')
plt.plot(xData3, yData3, color='b', linestyle=' ', marker='o', label='Art product of the author -М')
plt.plot(xData3, y1Data3, color='b',linewidth=2, label='Approximation of hyperbola y=(b/x)+a')
plt.legend(loc='best')
plt.grid(True)
plt.show()
elif mr==2:# построение графиков для первого и второго документа + среднее расстояние между их аппроксимацией
r12=round(sum([abs(yData1[i]-yData2[i]) for i in range(0,len(xData1))])/len(xData1),3)
txt3.insert(END,"Average distances between art products of the author K--"+ str(r12))
txt3.insert(END,'\n')
plt.title('Distribution of frequencies of use of words in the text', size=14)
plt.xlabel('Serial number of new words', size=14)
plt.ylabel('Frequency of the use of new words', size=14)
plt.plot(xData1, yData1, color='r', linestyle=' ', marker='o', label='Test art product of the author -К')
plt.plot(xData1, y1Data1, color='r',linewidth=2, label='Approximation of hyperbola y=(a/x)+b')
plt.plot(xData2, yData2, color='g', linestyle=' ', marker='o', label='Comparable art product of the author -К')
plt.plot(xData2, y1Data2, color='g',linewidth=2, label='Approximation of hyperbola y=(a/x)+b')
plt.legend(loc='best')
plt.grid(True)
plt.show()
elif mr==1: # построение графика для любого загруженного документа
plt.title('Distribution of frequencies of use of words in the text', size=14)
plt.xlabel('Serial number of new words', size=14)
plt.ylabel('Frequency of the use of new words', size=14)
plt.plot(xData1, yData1, color='r', linestyle=' ', marker='o', label='Test art product of the author -К')
plt.plot(xData1, y1Data1, color='r',linewidth=2, label='Approximation of hyperbola y=(a/x)+b')
plt.grid(True)
plt.show()
def choice_text():# загрузка документов в поля формы
try:
op = askopenfilename()
f=open(op, 'r')
st=f.read()
f.close()
if len(txt.get(1.0,END))==1:
txt.insert(END,st)
elif len(txt1.get(1.0,END))==1:
txt1.insert(END,st)
elif len(txt2.get(1.0,END))==1:
txt2.insert(END,st)
except:
pass
def array_text_1 ():# чтение данных из поля уже в UNICODE
if len(txt.get(1.0,END))!=1:
u=txt.get(1.0,END)
else:
txt3.insert(END,"There are no text №1")
return
op=1
processing_subjects (u,op)
def array_text_2 ():# чтение данных из поля уже в UNICODE
if len(txt1.get(1.0,END))!=1:
u=txt1.get(1.0,END)
else:
txt3.insert(END,"There are no text №2")
return
op=2
processing_subjects (u,op)
def array_text_3 ():# чтение данных из поля уже в UNICODE
if len(txt2.get(1.0,END))!=1:
u=txt2.get(1.0,END)
else:
txt3.insert(END,"There are no text №3")
return
op=3
processing_subjects (u,op)
def processing_subjects (u,op):# определние жанра текста ( NLTK+corpusbrown)
q= nltk.word_tokenize(u)
qq=[w for w in q if len(w)>2]
z=nltk.pos_tag(qq)
m=[w[0].lower() for w in z if w[1]=="NN"]
d={}
for w in m:
if w in d:
d[w]+=1
else:
d[w]=1
pairs = list(d.items())
pairs.sort(key=lambda x: x[1], reverse=True)
modals=[]
wq=10
for i in pairs[0:wq]:
modals.append(i[0])
cfd = nltk.ConditionalFreqDist(
(genre, word)
for genre in brown.categories()
for word in brown.words(categories=genre))
#задание жанров для определения
genres=['news', 'editorial', 'reviews', 'religion', 'hobbies', 'lore', 'belles_lettres',
'government', 'learned', 'fiction', 'mystery', 'science_fiction', 'adventure', 'romance', 'humor']
sys.stdout = open('out.txt', 'w')
cfd.tabulate(conditions=genres, samples=modals)
sys.stdout.close()# перенаправление потоков
f=open('out.txt', 'r')
w=f.read()
txt3.insert(END,w)
f.close()
sys.stdout = open('out.txt', 'w')
cfd.tabulate(conditions=genres, samples=modals)
sys.stdout.close()
f=open('out.txt', 'r')
b=0
u={}
for i in f:
b=b+1
if b>=2:
d=i.split()
c=d[1:len(d)]
e=[int(w) for w in c]
u[d[0]]=sum(e)
for key, val in u.items():
if val == max(u.values()):
tex="Text № -%i- Theme-- %s. Concurrences- %i"%(op,key,val)
txt3.insert(END,tex)
txt3.insert(END,'\n')
f.close()
cfd.plot(conditions=genres, samples=modals)
def close_win():
tk.destroy()
# интерфейс tkinter + меню+индивидуальная цветоовая разметка текстов+ центрирование формы
import tkinter as T
from tkinter.filedialog import *
import tkinter.filedialog
import fileinput
tk=T.Tk()
tk.geometry('630x630')
main_menu = Menu(tk)
tk.config(menu=main_menu)
file_menu = Menu(main_menu)
main_menu.add_cascade(label="The comparative analysis of the art texts", menu=file_menu)
file_menu.add_command(label="Choice of the texts", command=choice_text)
file_menu.add_command(label="Definition of subjects of the text-1", command=array_text_1)
file_menu.add_command(label="Definition of subjects of the text-2", command=array_text_2)
file_menu.add_command(label="Definition of subjects of the text-3", command=array_text_3)
file_menu.add_command(label="Definition of the author of the text", command=comor_text)
file_menu.add_command(label="Exit from the program", command=close_win)
lab =Label(tk, text="The text for comparison author -K ", font=("Arial", 12, "bold "),foreground='red')
lab.pack()
txt= Text(tk, width=66,height=5,font=("Arial", 12, "bold "),foreground='red',wrap=WORD)
txt.pack()
lab1 = Label(tk, text="The test author -K",font=("Arial", 12, "bold "),foreground='green')
lab1.pack()
txt1= Text(tk, width=66,height=5,font=("Arial", 12, "bold "),foreground='green',wrap=WORD)
txt1.pack()
lab2 = Label(tk, text="The text author-M", font=("Arial", 12, "bold "),foreground='blue')
lab2.pack()
txt2= Text(tk, width=66,height=5,font=("Arial", 12, "bold "),foreground='blue',wrap=WORD)
txt2.pack()
lab3 = Label(tk, text="Text results of comparison", font=("Arial", 12, "bold"),foreground='black')
lab3.pack()
txt3= Text(tk, width=66,height=6,font=("Arial", 12, "bold"),foreground='black',wrap=WORD)
txt3.pack()
lab4 = Label(tk, text="Minimum quantity of words in a window ", font=("Arial", 12, "bold"),foreground='black')
lab4.pack()
txt4= Text(tk, width=8,height=1,font=("Arial", 12, "bold"),foreground='black',wrap=WORD)
wd=10
txt4.pack()
txt4.insert(END,wd)
lab5 = Label(tk, text="Maximum quantity of words in a window ", font=("Arial", 12, "bold"),foreground='black')
lab5.pack()
txt5= Text(tk, width=8,height=1,font=("Arial", 12, "bold"),foreground='black',wrap=WORD)
wd=90
txt5.pack()
txt5.insert(END,wd)
tk.title('The analysis of the art text')
x = (tk.winfo_screenwidth() - tk.winfo_reqwidth()) /4#центрирование формы
y = (tk.winfo_screenheight() - tk.winfo_reqheight()) / 16#центрирование формы
tk.wm_geometry("+%d+%d" % (x, y))#центрирование формы
tk.mainloop()
Возможности разработанной мной программой:
- Возможность раздельного анализа по первому и второму закону Зипфа каждого документа.
- Возможность отдельно определить жанр каждого документа (реализация с перераспределением потока данных).
- Подвижное, динамическое окно для выбора участка ранга или количества слов непосредственно в процессе анализа.
- Цветовая разметка анализируемых документов с их графической реализацией.
- Возможность внесения изменений в документ непосредственно в процессе анализа (при наличии в документе не индифицируемых символов).
Для проверки работы программы использовались произведения известных англоязычных писателей.
Приведен сравнительный анализ произведений Дэн Броун «Код Давинчи» и «Ангелы и демоны» и Роберт Ладлэм «Идентификация борна»
Интерфейс программы
Gример для сравнительного анализа на авторство произведений Дэна Броуна и Роберта Ладлэма.

Распечатка результатов

График
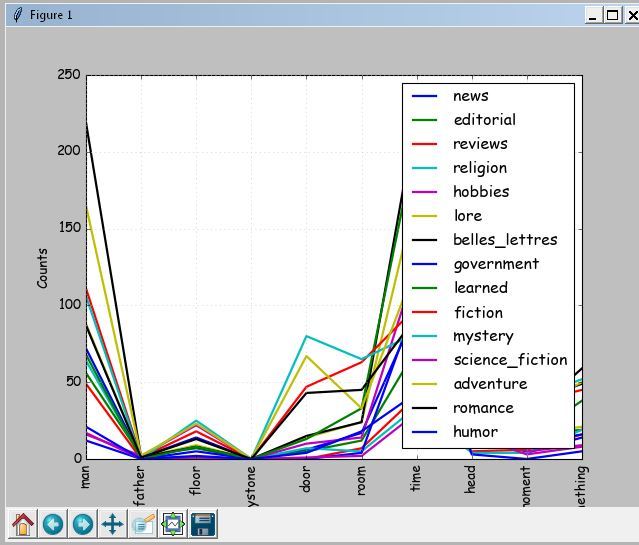
В первые два поля формы загружаем разные произведения одного автора, а в третье другого.
Для определения жанра произведений выбираем из текста произведения ключевые существительные или модальные глаголы. Это могут быть как отдельные слова, так и словосочетания. Из специально размеченного корпуса (я использовал Brown). По максимальному числу вхождений отобранных слов определяется жанр.
Убедившись, что все тексты одного жанра можно начинать анализ авторства. Для решения частных задач, например для анализа технических текстов, базу тематик можно создать свою.

Распечатка результатов
Factor --a 91.184 Factor--b 2297.14 Mistake of approximation-- 0.0511%
In total of words (Text-1) --81020. New words --11120. Percent new words-- 14
Factor --a 100.21 Factor--b 2869.22 Mistake of approximation-- 0.0965%
In total of words (Text-2) --86079. New words --11868. Percent new words-- 14
Factor --a 154.162 Factor--b 4982.418 Mistake of approximation-- 0.0433%
In total of words (Text-3) --128217. New words --10626. Percent new words-- 8
Average distances between art products of the author K--25.062
Average distance between art products of the authors K and M--138.25График для сравнения
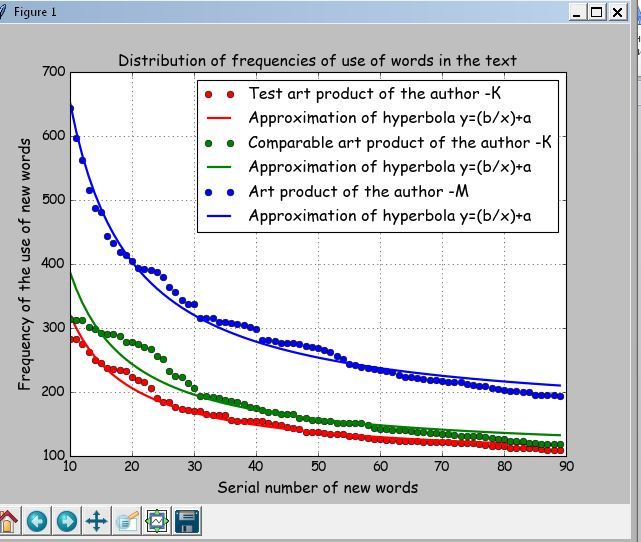
Из приведенной распечатки и графика видна индивидуальность авторов K –зелёная и красная кривые и М – синяя кривая. Среднее расстояние между аппроксимирующими гиперболами автора К составляет 25,062, а между первым произведением автора К и произведением автора М — 138,25.
Программа строит фрагмент для количества слов от 10 до 90 по второму Закону Зипфа ─ «количество — частота» [4]. Зипф установил, что частота и количество слов, входящих в текст с этой частотой, тоже связаны между собой.
Специальная формула
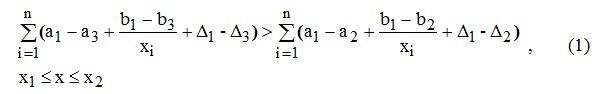
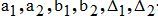 ─ коэффициенты гиперболической аппроксимации и погрешности аппроксимации для автора К;
─ коэффициенты гиперболической аппроксимации и погрешности аппроксимации для автора К;
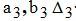 ─ коэффициенты гиперболической аппроксимации и погрешность аппроксимации для автора M;
─ коэффициенты гиперболической аппроксимации и погрешность аппроксимации для автора M;

 ─ диапазон для количества слов настраиваемый в процессе анализа графика.
─ диапазон для количества слов настраиваемый в процессе анализа графика.
Неравенство (1) я проверил на 50 тройках произведениях англоязычных авторов. Большей статистики у меня нет. Желающие в справедливости неравенства (1) могут его проверить на своих примерах.
Вывод
Рассмотрена реализация на Python метода определения авторства текстов по частоте употребления новых слов. Приведена формула для сравнительного анализа трёх текстов два из которых одного автора, а третий другого. Приведен пример для сравнительного анализа произведений Дена Броуна и Роберта Ладлэма.
Ссылки
- Авторство писателей можно узнать по специальной формуле.
- J. C. Baker A Test of Authorship Based on the Rate at which New Words Enter an Author's Text Journal Article published 1 Jan 1988 in Literary and Linguistic Computing volume 3 issue 1 on pages 36 to 39.
- Простая программа на Python для гиперболической аппроксимации статистических данных
- Законы Зипфа (Ципфа)
