Добрый день, дорогие друзья.
Недавно, сидя на диване, я задумался о том, что хочется мне сделать своего паука, который что-то бы смог качать с веб сайтов. Но качать он должен был бы не простой загрузкой, а как настоящий милый добрый браузер (т.е. JavaScript чтобы исполнялся).
В моей голове всплыли такие интересные штуки, как Selenium, PhantomJS, Splash и всякое подобное. Все эти штуки были мне немного втягость. Вот какие причины я выявил:
Собственно, к делу. Недавно вышел Headless Chrome. Это означает, что теперь мы аж использовать хром, как кравлер (но это неточно). Однако, я не нашел нормальных утилит для использования его в качестве кравлера. Нашел только chrome-remote-interface из списка сторонних клиентов (остальные были крайне скучными и совсем непонятными на первый взгляд).
Пробежавшись по документации и готовому проекту, и убедившись что никто толком не реализовал клиент под Python, я решил сделать свой клиент.
Протокол у Chrome Remote Debug достаточно простой. Для начала нам надо запустить Chrome вот с такими параметрами:

Теперь у нас есть API, доступное, по адресу http://127.0.0.1:9222/json/, в котором я обнаружил такие методы как list, new, activate, version, которые используются для управления вкладками.
Также, если мы просто перейдем на http://127.0.0.1:9222/, то сможем перейти на прекрасный веб отладчик, который полностью имитирует стандартный. В нем очень удобно отслеживать как работают апишные методы хрома (окно отладки справа эмулируется внутри окна, а окно браузера — отрисовано на канвасе).

Собственно, перейдя на вкладку list, мы можем узнать, адрес вебсокета, с помощью которого мы сможем общаться с вкладкой.
Дальше мы подсоединяемся через вебсокет к желаемой вкладке, и общаемся с нею. Мы можем:
Спустя дни мучительного написания функционала для себя у меня получилась вот такая библиотека.
Что в ней есть:

Вот так выглядит прога, которая подгружает страничку и выдает длину каждого ответа на запрос:
Тут мы используем систему колбеков. Самые интересные: start и any:
Мне мой код показался достаточно элегантным, и я буду его использовать дальше, хоть протокол немного сыроват. Если кто-то хочет обсудить, то пишите сюда, в Github или мне на почту.
Однако, было одно но, из-за которого я все таки плачу. С помощью remote API нельзя производить перехват и модификацию запросов и ответов. Насколько я понял — это возможно через mojo, который позволяет использовать хром в качестве библиотеки.
Однако, я подумал, что компиляция нестабильного хрома и отсутствие Python прослойки для меня будет большим горем (сейчас есть C++ и JavaScript в процессе разработки).
Надеюсь, статья была полезной. Спасибо.

Недавно, сидя на диване, я задумался о том, что хочется мне сделать своего паука, который что-то бы смог качать с веб сайтов. Но качать он должен был бы не простой загрузкой, а как настоящий милый добрый браузер (т.е. JavaScript чтобы исполнялся).
В моей голове всплыли такие интересные штуки, как Selenium, PhantomJS, Splash и всякое подобное. Все эти штуки были мне немного втягость. Вот какие причины я выявил:
- Дело в том, что я хотел бы писать на своем любимом питоне, потому что очень не люблю JavaScript, а это уже означает, что большая часть уже не работала бы (или пришлось их как-то склеивать, что тоже отстой).
- Еще эти безголовые браузеры обновляются как когда.
- Но вот Selenium очень милая штука, но я не нашел, как там отслеживать загрузку страниц, или хотя бы адекватного способа выдрать куку или задать её. Слышал, что многие любители селениума инжектят в страничку JavaScript, что для меня дико, потому что где-то полгода назад я делал сайтик, который отрывал любые JavaScript вызовы с сайта и потенциально мог определять моего паука. Мне бы очень не хотелось таких казусов. Хочется чтобы мой паук выглядел как браузер максимально точно.
Собственно, к делу. Недавно вышел Headless Chrome. Это означает, что теперь мы аж использовать хром, как кравлер (но это неточно). Однако, я не нашел нормальных утилит для использования его в качестве кравлера. Нашел только chrome-remote-interface из списка сторонних клиентов (остальные были крайне скучными и совсем непонятными на первый взгляд).
Пробежавшись по документации и готовому проекту, и убедившись что никто толком не реализовал клиент под Python, я решил сделать свой клиент.
Протокол у Chrome Remote Debug достаточно простой. Для начала нам надо запустить Chrome вот с такими параметрами:
chrome --incognito --remote-debugging-port=9222 --headless
Теперь у нас есть API, доступное, по адресу http://127.0.0.1:9222/json/, в котором я обнаружил такие методы как list, new, activate, version, которые используются для управления вкладками.
Также, если мы просто перейдем на http://127.0.0.1:9222/, то сможем перейти на прекрасный веб отладчик, который полностью имитирует стандартный. В нем очень удобно отслеживать как работают апишные методы хрома (окно отладки справа эмулируется внутри окна, а окно браузера — отрисовано на канвасе).
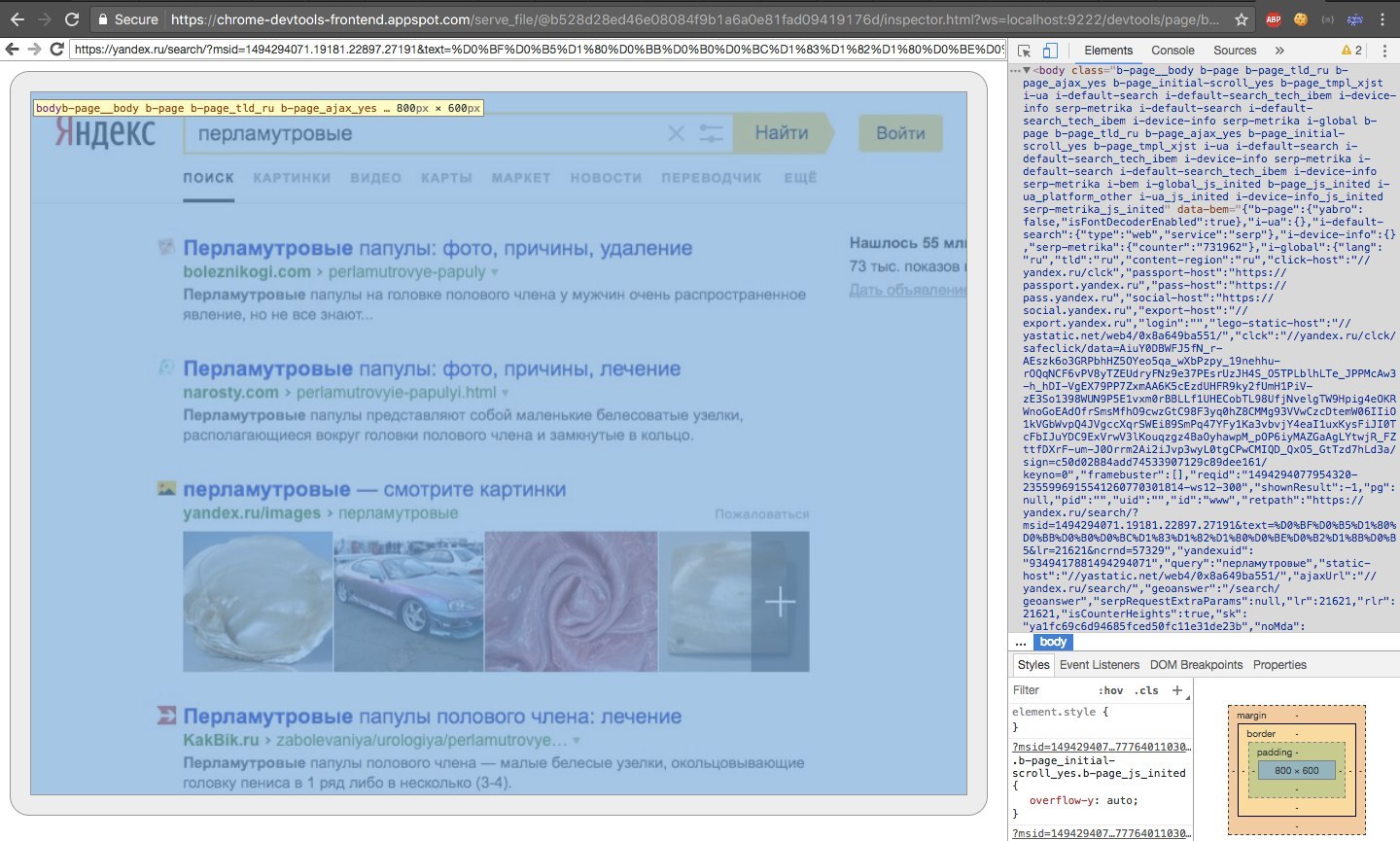
Собственно, перейдя на вкладку list, мы можем узнать, адрес вебсокета, с помощью которого мы сможем общаться с вкладкой.
Дальше мы подсоединяемся через вебсокет к желаемой вкладке, и общаемся с нею. Мы можем:
- Выполнить запрос
- Подписаться на события в вкладке
Спустя дни мучительного написания функционала для себя у меня получилась вот такая библиотека.
Что в ней есть:
- Автоматическая подкачка последней версии протокола
- Обертка протокола в питонистический вид
- Синхронный и асинхронный клиент (синхронный только для отладки)
- Надеюсь, удобная абстракция вкладок

Вот так выглядит прога, которая подгружает страничку и выдает длину каждого ответа на запрос:
import asyncio
import chrome_remote_interface
if __name__ == '__main__':
class callbacks:
async def start(tabs):
await tabs.add()
async def tab_start(tabs, tab):
await tab.Page.enable()
await tab.Network.enable()
await tab.Page.navigate(url='http://github.com')
async def network__loading_finished(tabs, tab, requestId, **kwargs):
try:
body = tabs.helpers.unpack_response_body(await tab.Network.get_response_body(requestId=requestId))
print('body length:', len(body))
except tabs.FailReponse as e:
print('fail:', e)
async def page__frame_stopped_loading(tabs, tab, **kwargs):
print('finish')
tabs.terminate()
async def any(tabs, tab, callback_name, parameters):
pass
# print('Unknown event fired', callback_name)
asyncio.get_event_loop().run_until_complete(chrome_remote_interface.Tabs.run('localhost', 9222, callbacks))Тут мы используем систему колбеков. Самые интересные: start и any:
- start(tabs, tab) — вызывается при старте.
- any(tabs, tab, callback_name, parameters) — вызывается, в случае если событие не нашлось в списке колбеков.
- network__response_received(tabs, tab, **kwargs) — пример библиотечного события Network.responseReceived.
Мне мой код показался достаточно элегантным, и я буду его использовать дальше, хоть протокол немного сыроват. Если кто-то хочет обсудить, то пишите сюда, в Github или мне на почту.
Однако, было одно но, из-за которого я все таки плачу. С помощью remote API нельзя производить перехват и модификацию запросов и ответов. Насколько я понял — это возможно через mojo, который позволяет использовать хром в качестве библиотеки.
Однако, я подумал, что компиляция нестабильного хрома и отсутствие Python прослойки для меня будет большим горем (сейчас есть C++ и JavaScript в процессе разработки).
Надеюсь, статья была полезной. Спасибо.

