В качестве предисловия: вчера представил приведенные ниже идеи на локальной сходке администраторов. После презентации ко мне подошел представитель компании, занимающейся производством сетевого оборудования и спросил: «Ты публиковал это где-то? Поделись презентацией, я отправлю коллегам посмотреть.» Собственно, а почему бы и не опубликовать? Как говорят у нас в Украине «i ми, Химко, люди». Если уж кто-то из вендоров, хотя бы отдаленно, но заинтересовался, то и в коммьюнити найдется человек, которому идеи тоже покажутся интересными. Кроме этого, я и сам планирую использовать это решение. Сразу скажу, что 100% готового результата не будет, но будет некий промежуточный, которого достаточно для эрзац-роутинга и немного информации для продолжения работ в данном направлении. Поехали!
Сразу скажу — в заголовке статьи речь идет именно о маршрутизаторе, физическом устройстве, а не протоколе BGP. И нет, без протокола BGP жить не получится, по крайней мере пока, — но это вы и сами знаете. Зачем нужен протокол, чем он хорош, что позволяет сделать и как его настраивать — об этом написаны массы книг и статей как на Хабре, так и на сторонних ресурсах, посему данную тему опущу. Если вам хватает статики или в соседней автономной системе работает тварищ, которого можно просить изменять политики анонсов, можно смело закрывать пост — вам эта информация не нужна.
Если вы все еще читаете, позволю себе начать с дизайна, так как статья больше о проектировании решения, нежели о самом решении. Итак, мы — сервис-провайдер ISP A, имеющий одноименный пул адресов и необходимость анонса этих адресов в Сеть. Общая схема логических связей приведена на рисунке.
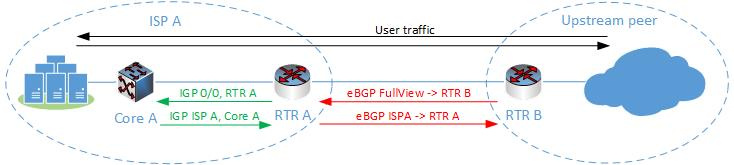
На границе нашей сети стоит маршрутизатор RTR A, который связан eBGP сессией с пиром-соседом. Через сессию протокола мы получаем FullView от соседа с указанием адреса следующейго перехода (next-hop) — IP адреса RTR B. В ответ — отдаем информацию о наших внутренних сетях с указанием next-hop RTR A. Сразу отмечу, что это лишь одна из множества возможных схем организации BGP соседства: маршрутизаторов на границе может быть несколько, равно как и соседей, сами соседи могут быть подключены не напрямую, мы можем получать больше одного FullView, резервировать каналы и прочее. Однако я позволю себе опустить анализ разнообразных схем организации пиринга и резервирования, и остановиться на простейшем случае — сути это не поменяет, а понимание упростит. Внутри нашей автономной системы работает IGP, посредством которого мы передаем достижимость сетей ISPA. Или не работает — это опять-таки лишь один из возможных вариантов.
Пользовательский трафик проходит через ядро CoreA, маршрутизатор RTR A и уходит дальше в Сеть. В моем понимании это (со всеми возможными вариациями) классический метод организации периметра сети и соседства BGP. Теперь посмотрим сколько стоит данное аппаратное решение.
Я буду отталкиваться от необходимой пропускной способности в 10Гб/с. Как минимум в решении должны присутствовать 10Гб/с интерфейсы с возможностью дальнейшего апгрейда. Juniper предлагает решение MX104-40G (или как вариант MX80) за 40 тыс.долл. с двумя (четырмя для MX80) 10Гб/с интерфейсами «на борту» и производительностью маршрутизации в 40Гб/с (80 — для MX80). Cisco отвечает устройством Cisco ASR 1001-X с базовой производительностью 2,5Гб/с и двумя 10Гб/с интерфейсами «на борту» за 17 тыс.долл + цена лицензии на улучшение производительности (до 20Гб/с) и активацию дополнительных интерфейсных слотов. Сразу скажу, что я не ставил перед собой задачу срогого сравнения устройств — в конце концов пост не об этом, но какие-то цифры нужны, так как наша основная задача снизить стоимость решения.
Итак, минимум 17 тыс.долл. Что полезное делает наш маршрутизатор RTRA? Да в общем-то немного — крутит BGP сессию (или несколько) с соседом и форвардит трафик в Сеть. Можно ли обойтись без него? Для ответа проанализируем следующую топологию.
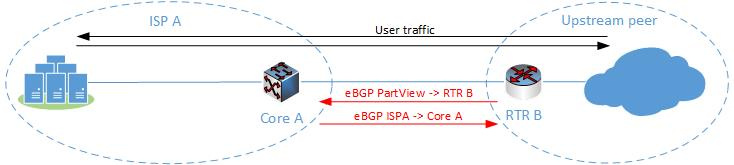
Мы убрали физический маршрутизатор и запустили пиринг BGP на устройстве ядра. Можно ли так? Да, благо сорвеменные L3 коммутаторы поддерживают запуск BGP. Однако в этом решении есть как минимум два слабых места. Первое — большинство коммутаторов не были созданы для полноценной маршрутизации, и поэтому имеют ограниченый размер таблицы маршрутизации. Например, Juniper EX4550 имеет ограничение в 14000 IPv4 юникаст-маршрутов, а Cisco Nexus3k — 16000. Второе — чтобы запустить BGP понадобится докупить лицензию, а это стоит 8 (Cisco Nexus3k) или 10 (Juniper EX4550) тыс.долл. Если нам понадобится резервирование коммутаторов, это удвоит приведенные цифры. Кроме этого, понадобится договариваться с вышестоящим провайдером для суммирования сетей, ну или получать маршрут по-умолчанию. Тем не менее, такой дизайн все-же позволятет отказаться от покупки выделенного маршрутизатора и в то же время пользоваться полезными плюшками BGP. Еще одна возможная вариация на эту тему приведена ниже.

Мы запускаем BGP процесс на физическом сервере или виртуальной машине, которая крутит eBGP сессию с RTRB и iBGP — с устройством ядра. На виртуалке устанавливаем один из доступных пакетов для запуска BGP, например Quagga, Vyatta или BIRD.
Одной из прекрасных возможностей протокола BGP является возможность изменения next-hop при анонсе обновлений, ей мы и воспользуемся для того, чтобы избежать ситуации, когда пользовательский трафик необходимо форвардить через BGP спикера. То есть мы как-бы разделяем устройства, которые обладают маршрутной информацией (виртуалка) и устройства, которые занимаются пересылкой трафика (CoreA) внутри автономной системы. Соответственно, RTRB получает в качестве next-hop адрес CoreA и наоборот. Такой себе control-plane vs forwarding-plane. Сама идея не нова и активно используется при организации точек обмена, только посредством eBGP сессий.
Это уже более интересный сценарий, так как теперь мы можем получать как FullView, так и несколько таковых, осуществлять фильтрацию и суммирование маршрутов локально, не прибегая к звонку провайдеру. Еще одной интересной особенностью решения является то, что нам не нужно даже наполнять таблицу ядра на виртуальной машине с BGP. Те, кто сталкивался с настройкой, например, Quagga знают, что нужно во-первых нужно включить опцию «ip forwarding» и затем передать маршруты, которые получил демон в ядро (ну или таблицу маршрутизации хоста) для корректного форвардинга трафика. Так вот, это все лишнее — виртуалка занимается только анонсом BGP информации и в продвижении трафика не участвует, а наполнение таблицы внутри Quagga занимает столько времени, сколько нужно для передачи непосредственно объема маршрутной таблицы — секунд 10.
Это уже больше похоже на искомое решение, но вопрос с лицензией остается, ведь виртуалка и CoreA общаются посредством BGP. Есть ли еще варианты? Можно ли обойтись без лицензионного сбора? И тут мы подходим к главной соли данного поста. Взглянем на топологию.

Основная идея та же — запустить eBGP на виртуалке, но внутри автономной системы уже использовать какой-нибудь IGP протокол, к примеру как на рисунке, OSPF. Часть с eBGP сессией осталась неизменной и здесь все еще нет проблем. А вот с IGP они есть — ведь ни один из них не был предназначен для передачи non-directly connected next-hop, уж извините за обилие английских слов. Кроме прочего, Nexus3k требует лицензию и для OSPF, но это уже детали — у меня в сети Juniper, а для Нексуса можно использовать RIP :). Так или иначе, передать другой next-hop нужно, так как в противном случае пользовательский трафик пойдет через виртуалку, а такое решение не годится. Соответственно нам нужен некий костыль, который позволит «невозможное» — передать другой, не локальный, next-hop при анонсе маршрута. При обкатке идеи я пробовал следующие варианты:
Кстати, о последнем пункте — экспорт в forwarding table — с его помощью можно осуществлять per-flow BGP ECMP, во всяком случае на Juniper. Если кому-то будет интересно, могу кинуть конфиг в благодарность за то, что вы уделили внимание посту.
Так вот, к сожалению, все вышеперечисленное не работает. Qugga и Juniper тихо игнорировали мои ковыряния в политиках, а BIRD сразу ругался при попытке изменения параметра «next-hop» в анонсе. Вот так банально и обидно моя идея разбилась о скалы непонимания со стороны производителей. В процессе работы я даже загуглил проблему и оказалось не один я такая хитрая ж., но решения по факту не было, разве что указали на то, что у Cisco есть фича «forwarding address» (почитать можно здесь), но это не то.
Уже почти отчаявшись, я обратился за помощью к коллегам. Андрушко Дмитрий, Коваленко Александр (@alk0v) и Симоненко Дмитрий, спасибо — страна должна знать своих героев! Итак, варианты есть.
Первое — есть уже готовое решение для программно-определяемых сетей под названием проект Atruim (почитать). Кроме этого, если я правильно расслышал, Mellanox занимается производством устройств с Quagga/BIRD внутри. Собственно говоря, SDN клевая штука — делай что хочешь и как хочешь. Но это SDN и новое оборудование, а у меня задача решить все на существующем.
Далее, если я правильно понял («если» — главное слово, так как я не силен в *NIXах), демоны в Quagga (например, ospfd) общаются с ядром через модуль iproute2 и чисто теоретически можно перехватить пакет на выходе из ospfd и модифицировать его. Уж не знаю правильно ли я думаю и возможно ли это, но как-то так.
Ну и напоследок железный вариант — Scapy, который позволяет генерировать пакеты с заданым содержимым. И в самом деле — структура OSPF пакета нам известна, что и на какое значение менять тоже. Дело за малым — реализовать это. Вот здесь я и остановился на данный момент.
То как я себе представляю решение — оно прежде всего должно быть динамическим. В противном случае зачем все эти танцы с протоколами? По поему мнению можно даже поднимать одну виртуалку для каждого eBGP пира — цена виртуальной машины ничтожна, а такое упрощение позволит просто модифицировать все исходящие OSPF пакеты, меняя один next-hop на другой.
Но пока я не добрался до реализации такого решения, решил что для своей задачи буду запускать eBGP на виртуалке, а на ядре (CoreA) использовать статику. Неизящно — да, но это позволит мне обойтись без покупки маршрутизатора, во всяком случае на первых порах.
Я понимаю, что такое решение не подойдет для транзитных автономных систем и мест, где нужны дополнительные сервисы вроде MPLS. Возможны еще проблемы с геофильтрацией, или точнее приоритезацией конкретного пира с несмежными блоками адресов, где оптимальное сумирование затруднено. Нужно еще учитывать сравнительно медленную передачу маршрутной информации посредством IGP. Однако для тупиковых AS и задач попроще решение вполне подойдет.
Вот такие идеи. Надеюсь кому-нибудь они покажутся интересными и найдут свое применение.
Сразу скажу — в заголовке статьи речь идет именно о маршрутизаторе, физическом устройстве, а не протоколе BGP. И нет, без протокола BGP жить не получится, по крайней мере пока, — но это вы и сами знаете. Зачем нужен протокол, чем он хорош, что позволяет сделать и как его настраивать — об этом написаны массы книг и статей как на Хабре, так и на сторонних ресурсах, посему данную тему опущу. Если вам хватает статики или в соседней автономной системе работает тварищ, которого можно просить изменять политики анонсов, можно смело закрывать пост — вам эта информация не нужна.
Если вы все еще читаете, позволю себе начать с дизайна, так как статья больше о проектировании решения, нежели о самом решении. Итак, мы — сервис-провайдер ISP A, имеющий одноименный пул адресов и необходимость анонса этих адресов в Сеть. Общая схема логических связей приведена на рисунке.

На границе нашей сети стоит маршрутизатор RTR A, который связан eBGP сессией с пиром-соседом. Через сессию протокола мы получаем FullView от соседа с указанием адреса следующейго перехода (next-hop) — IP адреса RTR B. В ответ — отдаем информацию о наших внутренних сетях с указанием next-hop RTR A. Сразу отмечу, что это лишь одна из множества возможных схем организации BGP соседства: маршрутизаторов на границе может быть несколько, равно как и соседей, сами соседи могут быть подключены не напрямую, мы можем получать больше одного FullView, резервировать каналы и прочее. Однако я позволю себе опустить анализ разнообразных схем организации пиринга и резервирования, и остановиться на простейшем случае — сути это не поменяет, а понимание упростит. Внутри нашей автономной системы работает IGP, посредством которого мы передаем достижимость сетей ISPA. Или не работает — это опять-таки лишь один из возможных вариантов.
Пользовательский трафик проходит через ядро CoreA, маршрутизатор RTR A и уходит дальше в Сеть. В моем понимании это (со всеми возможными вариациями) классический метод организации периметра сети и соседства BGP. Теперь посмотрим сколько стоит данное аппаратное решение.
Я буду отталкиваться от необходимой пропускной способности в 10Гб/с. Как минимум в решении должны присутствовать 10Гб/с интерфейсы с возможностью дальнейшего апгрейда. Juniper предлагает решение MX104-40G (или как вариант MX80) за 40 тыс.долл. с двумя (четырмя для MX80) 10Гб/с интерфейсами «на борту» и производительностью маршрутизации в 40Гб/с (80 — для MX80). Cisco отвечает устройством Cisco ASR 1001-X с базовой производительностью 2,5Гб/с и двумя 10Гб/с интерфейсами «на борту» за 17 тыс.долл + цена лицензии на улучшение производительности (до 20Гб/с) и активацию дополнительных интерфейсных слотов. Сразу скажу, что я не ставил перед собой задачу срогого сравнения устройств — в конце концов пост не об этом, но какие-то цифры нужны, так как наша основная задача снизить стоимость решения.
Итак, минимум 17 тыс.долл. Что полезное делает наш маршрутизатор RTRA? Да в общем-то немного — крутит BGP сессию (или несколько) с соседом и форвардит трафик в Сеть. Можно ли обойтись без него? Для ответа проанализируем следующую топологию.

Мы убрали физический маршрутизатор и запустили пиринг BGP на устройстве ядра. Можно ли так? Да, благо сорвеменные L3 коммутаторы поддерживают запуск BGP. Однако в этом решении есть как минимум два слабых места. Первое — большинство коммутаторов не были созданы для полноценной маршрутизации, и поэтому имеют ограниченый размер таблицы маршрутизации. Например, Juniper EX4550 имеет ограничение в 14000 IPv4 юникаст-маршрутов, а Cisco Nexus3k — 16000. Второе — чтобы запустить BGP понадобится докупить лицензию, а это стоит 8 (Cisco Nexus3k) или 10 (Juniper EX4550) тыс.долл. Если нам понадобится резервирование коммутаторов, это удвоит приведенные цифры. Кроме этого, понадобится договариваться с вышестоящим провайдером для суммирования сетей, ну или получать маршрут по-умолчанию. Тем не менее, такой дизайн все-же позволятет отказаться от покупки выделенного маршрутизатора и в то же время пользоваться полезными плюшками BGP. Еще одна возможная вариация на эту тему приведена ниже.

Мы запускаем BGP процесс на физическом сервере или виртуальной машине, которая крутит eBGP сессию с RTRB и iBGP — с устройством ядра. На виртуалке устанавливаем один из доступных пакетов для запуска BGP, например Quagga, Vyatta или BIRD.
Одной из прекрасных возможностей протокола BGP является возможность изменения next-hop при анонсе обновлений, ей мы и воспользуемся для того, чтобы избежать ситуации, когда пользовательский трафик необходимо форвардить через BGP спикера. То есть мы как-бы разделяем устройства, которые обладают маршрутной информацией (виртуалка) и устройства, которые занимаются пересылкой трафика (CoreA) внутри автономной системы. Соответственно, RTRB получает в качестве next-hop адрес CoreA и наоборот. Такой себе control-plane vs forwarding-plane. Сама идея не нова и активно используется при организации точек обмена, только посредством eBGP сессий.
Это уже более интересный сценарий, так как теперь мы можем получать как FullView, так и несколько таковых, осуществлять фильтрацию и суммирование маршрутов локально, не прибегая к звонку провайдеру. Еще одной интересной особенностью решения является то, что нам не нужно даже наполнять таблицу ядра на виртуальной машине с BGP. Те, кто сталкивался с настройкой, например, Quagga знают, что нужно во-первых нужно включить опцию «ip forwarding» и затем передать маршруты, которые получил демон в ядро (ну или таблицу маршрутизации хоста) для корректного форвардинга трафика. Так вот, это все лишнее — виртуалка занимается только анонсом BGP информации и в продвижении трафика не участвует, а наполнение таблицы внутри Quagga занимает столько времени, сколько нужно для передачи непосредственно объема маршрутной таблицы — секунд 10.
Это уже больше похоже на искомое решение, но вопрос с лицензией остается, ведь виртуалка и CoreA общаются посредством BGP. Есть ли еще варианты? Можно ли обойтись без лицензионного сбора? И тут мы подходим к главной соли данного поста. Взглянем на топологию.

Основная идея та же — запустить eBGP на виртуалке, но внутри автономной системы уже использовать какой-нибудь IGP протокол, к примеру как на рисунке, OSPF. Часть с eBGP сессией осталась неизменной и здесь все еще нет проблем. А вот с IGP они есть — ведь ни один из них не был предназначен для передачи non-directly connected next-hop, уж извините за обилие английских слов. Кроме прочего, Nexus3k требует лицензию и для OSPF, но это уже детали — у меня в сети Juniper, а для Нексуса можно использовать RIP :). Так или иначе, передать другой next-hop нужно, так как в противном случае пользовательский трафик пойдет через виртуалку, а такое решение не годится. Соответственно нам нужен некий костыль, который позволит «невозможное» — передать другой, не локальный, next-hop при анонсе маршрута. При обкатке идеи я пробовал следующие варианты:
- Изменение next-hop при редистрибуции BGP->OSPF
- Изменение next-hop в исходящей политике OSPF
- Изменение next-hop во водящей политике OSPF
- Изменение next-hop при экспорте в forwarding table на устройстве Juniper
Кстати, о последнем пункте — экспорт в forwarding table — с его помощью можно осуществлять per-flow BGP ECMP, во всяком случае на Juniper. Если кому-то будет интересно, могу кинуть конфиг в благодарность за то, что вы уделили внимание посту.
Так вот, к сожалению, все вышеперечисленное не работает. Qugga и Juniper тихо игнорировали мои ковыряния в политиках, а BIRD сразу ругался при попытке изменения параметра «next-hop» в анонсе. Вот так банально и обидно моя идея разбилась о скалы непонимания со стороны производителей. В процессе работы я даже загуглил проблему и оказалось не один я такая хитрая ж., но решения по факту не было, разве что указали на то, что у Cisco есть фича «forwarding address» (почитать можно здесь), но это не то.
Уже почти отчаявшись, я обратился за помощью к коллегам. Андрушко Дмитрий, Коваленко Александр (@alk0v) и Симоненко Дмитрий, спасибо — страна должна знать своих героев! Итак, варианты есть.
Первое — есть уже готовое решение для программно-определяемых сетей под названием проект Atruim (почитать). Кроме этого, если я правильно расслышал, Mellanox занимается производством устройств с Quagga/BIRD внутри. Собственно говоря, SDN клевая штука — делай что хочешь и как хочешь. Но это SDN и новое оборудование, а у меня задача решить все на существующем.
Далее, если я правильно понял («если» — главное слово, так как я не силен в *NIXах), демоны в Quagga (например, ospfd) общаются с ядром через модуль iproute2 и чисто теоретически можно перехватить пакет на выходе из ospfd и модифицировать его. Уж не знаю правильно ли я думаю и возможно ли это, но как-то так.
Ну и напоследок железный вариант — Scapy, который позволяет генерировать пакеты с заданым содержимым. И в самом деле — структура OSPF пакета нам известна, что и на какое значение менять тоже. Дело за малым — реализовать это. Вот здесь я и остановился на данный момент.
То как я себе представляю решение — оно прежде всего должно быть динамическим. В противном случае зачем все эти танцы с протоколами? По поему мнению можно даже поднимать одну виртуалку для каждого eBGP пира — цена виртуальной машины ничтожна, а такое упрощение позволит просто модифицировать все исходящие OSPF пакеты, меняя один next-hop на другой.
Но пока я не добрался до реализации такого решения, решил что для своей задачи буду запускать eBGP на виртуалке, а на ядре (CoreA) использовать статику. Неизящно — да, но это позволит мне обойтись без покупки маршрутизатора, во всяком случае на первых порах.
Я понимаю, что такое решение не подойдет для транзитных автономных систем и мест, где нужны дополнительные сервисы вроде MPLS. Возможны еще проблемы с геофильтрацией, или точнее приоритезацией конкретного пира с несмежными блоками адресов, где оптимальное сумирование затруднено. Нужно еще учитывать сравнительно медленную передачу маршрутной информации посредством IGP. Однако для тупиковых AS и задач попроще решение вполне подойдет.
Вот такие идеи. Надеюсь кому-нибудь они покажутся интересными и найдут свое применение.
