Comments 16
Классно вы переписали код с С++ на C-и при работе со строками.
А я ведь говорил, что скатитесь к C-и и никуда не денетесь.
Про функции работы с heap вы тоже под воздействием каких-то мифов подобранных из сомнительной литературы. Если бы сподобились измерить время выполнения malloc и free, то увидели бы что они в среднем всегда выполняется за 3 мкс. И разброс этого времени не превышает 2 раз при выделении 2000! блоков одновременно. Это наверняка больше чем вы когда либо выделяли в STM32.
Программирование микроконтроллеров быстро прогрессирует, поэтому я бы на вашем месте не рисковал транслировать устаревшие знания.
Давайте лучше цифры и результаты тестов.
А я ведь говорил, что скатитесь к C-и и никуда не денетесь.
Про функции работы с heap вы тоже под воздействием каких-то мифов подобранных из сомнительной литературы. Если бы сподобились измерить время выполнения malloc и free, то увидели бы что они в среднем всегда выполняется за 3 мкс. И разброс этого времени не превышает 2 раз при выделении 2000! блоков одновременно. Это наверняка больше чем вы когда либо выделяли в STM32.
Программирование микроконтроллеров быстро прогрессирует, поэтому я бы на вашем месте не рисковал транслировать устаревшие знания.
Давайте лучше цифры и результаты тестов.
Классно вы переписали код с С++ на C-и при работе со строками.
А я ведь говорил, что скатитесь к C-и и никуда не денетесь.
По этому поводу, мне всегда вспоминается одно индийское видео. Там про программирование STM32. В куче частей. И вдруг к середине первой части автор начинает вместо рассказа про STM32 рассказывать про один приём программирования. И вся вторая часть посвящена ещё одному приёму программирования, никак не связанному с микроконтроллером. А надо-то про STM32 было! Видать, как и с индусским кодом, ему за хронометраж платят.
Тут мне надо было показать суть замены. Вместо динамики — статика. А про то, что это лучше обернуть в класс — написано ниже. Если бы я начал рассказывать про класс, показывать его тело — всё было бы уже не так. Здесь же можно наблюдать точное соответствие «старое-суть нового». А в класс — ну разумеется, упаковать. И об этом в тексте сказано.
Если бы сподобились измерить время выполнения malloc и free, то увидели бы что они в среднем всегда выполняется за 3 мкс.
Это Вы крючкотворцам расскажите, которые будут доказывать, что ОС при этом станет не реального времени, так как производительность уже не специфицирована. Посему об этом в документации предупредить — обязательно нужно.
Тем не менее, эта глава — всего лишь рекомендация. Операции new и delete как были, так и есть. Кто хочет ими пользоваться — может продолжать. Но пусть в уме держит возможные последствия. Мы предупредили, дальше — каждый сам решает.
Результаты тестов — я у ребят спрошу, проводили ли они. Тем не менее, возможную фрагментацию адресного пространства никто не отменял, независимо от результатов тестов быстродействия. А приведённый пример, который мы обсуждаем — это кусок найденного в сети http сервера для IoT. То есть, он крутится круглосуточно без перезапусков.
Думаю сервисы вашей библиотеки функций RTOS будут менее детерминированными чем free и malloc.
Хотелось бы посмотреть пример от вас где реально имела бы значение детерминированность вашей библиотеки функций реального времени
Уже много лет не могу найти в интернете кто-бы действительно показал, как он учитывает детерминированность RTOS. Кроме RTOS MQX да ThreadX я не видел серьезных тестов детерминированности.
Хотелось бы посмотреть пример от вас где реально имела бы значение детерминированность вашей библиотеки функций реального времени
Уже много лет не могу найти в интернете кто-бы действительно показал, как он учитывает детерминированность RTOS. Кроме RTOS MQX да ThreadX я не видел серьезных тестов детерминированности.
В комментариях к предыдущим публикациям, я уже отмечал, что отвечаю за «художественное» руководство по ней. И данная публикация — именно «художественное» описание. Не будем пытаться объять необъятное здесь.
Про new/delete в тексте сказано — за эти слова мне нужно отвечать, сейчас как раз уже будут метрики. А про такие серьёзные вещи — можете хоть сейчас на нашем сайте связаться с теми, кто за это дело отвечает. Ну, или когда мне поручат технический текст сделать — тогда я подготовлюсь и буду готов отвечать на такие вещи. Сейчас — не готов.
Про new/delete в тексте сказано — за эти слова мне нужно отвечать, сейчас как раз уже будут метрики. А про такие серьёзные вещи — можете хоть сейчас на нашем сайте связаться с теми, кто за это дело отвечает. Ну, или когда мне поручат технический текст сделать — тогда я подготовлюсь и буду готов отвечать на такие вещи. Сейчас — не готов.
Я бы, скорее, сказал, что подобный код является отрицательным примером. strcat каждый раз подсчитывает длину строки, к которой он добавляет второй фрагмент, поэтому вычислительная сложность такого подхода оказывается квадратичной вместо линейной, в результате чего время выполнения этого кода может даже превысить время выполнения С++ кода. Второй недостаток заключается в отсутствии проверок границ, что может привести к тому самому нарушению стека. Конечно, в примере размер взят с избытком, но этого его не оправдывает, так как этот избыток тоже может послужить причиной повреждения стека, а документация должна быть всё-таки образцовой.
«Выигрываем в скорости — проигрываем в пути», закон физики. В этом примере я специально указал, что он «крутится» в системе с 50К свободной кучи. Там я больше боялся, что рано или поздно произойдёт фатальная фрагментация адресного пространства. Получили гарантированное отсутствие фрагментации, проиграли в производительности, которая для Web-сервера не настолько критична.
Если зайти совсем в разговоры о жизни, то пример относится к любительской разработке WiFi модуля для 3D принтера. ESP8266 постоянно вис. На скорую руку, я заменил этот кусочек. Был бы виноват он — сделал бы класс. Но выяснилось, что виновата работа в контексте прерывания, которая была сделана для устранения подвисаний… Короче, долгая история, описанная мною в блоге про 3D печать. А данный кусок был реабилитирован… Но в силу его показательности (соответствие старое-новое 1:1), пошёл в книжку про нашу ОС.
Надо будет подумать над другим примером, в дополнение к этому. Этот оставить для фрагментации, а другой — для скорости. Осталось придумать что-то красивое.
Если зайти совсем в разговоры о жизни, то пример относится к любительской разработке WiFi модуля для 3D принтера. ESP8266 постоянно вис. На скорую руку, я заменил этот кусочек. Был бы виноват он — сделал бы класс. Но выяснилось, что виновата работа в контексте прерывания, которая была сделана для устранения подвисаний… Короче, долгая история, описанная мною в блоге про 3D печать. А данный кусок был реабилитирован… Но в силу его показательности (соответствие старое-новое 1:1), пошёл в книжку про нашу ОС.
Надо будет подумать над другим примером, в дополнение к этому. Этот оставить для фрагментации, а другой — для скорости. Осталось придумать что-то красивое.
Да что-то вроде этого:
typedef struct {
char *buf;
int size, len;
bool success;
} buf_t;
void init(buf_t *s, char *buf, int size) {
assert(NULL != buf);
assert(size > sizeof(void *));
s->buf = buf;
buf[0] = '\0';
s->size = size;
s->len = 0;
s->success = true;
}
bool cat(buf_t *s, char const *str) {
int i;
i = 0;
while ((s->len < s->size - 1) && (str[i] != '\0')) {
s->buf[s->len] = str[i];
s->len += 1;
i += 1;
}
s->buf[s->len] = '\0';
s->success = str[i] == '\0';
return s->success;
}
char xml[768];
buf_t buf;
bool success;
init(&buf, xml, sizeof(xml));
if (cnt > 0)
{
cat(&buf, ",");
}
cat(&buf, "{\"type\":\"");
if (entry.isSubDir())
{
cat(&buf, "dir");
} else
{
cat(&buf, "file");
}
cat(&buf, "\",\"name\":\"");
if (s->success && entry.getName(s->buf, s->size, &s->len)) {
cat(&buf, "\"}");
}
Тьфу, в силе выигрываем, проигрываем в пути. Давно физику не повторял. Прошу прощения.
По моей просьбе, разработчик, отвечающий за профилирование, провёл исследование. От себя добавлю, что на STM32 с частотой 168 МГц, на двух тысячах блоков среднее время составит 4.5 мкс. Хотя, максимальное — уже 10 мкс. Но есть и другие чипы. В частности, Миландровские. А ромбик военной приёмки — на них. И там пока частоты другие. А применительно к тому, Реальное Время у операционки или нет — лучше я дам прямую цитату от автора метрики:
Случайным образом захватывались и освобождались блоки памяти.
Профилировщик дал следующую картину:
Qty – количество блоков
Size – максимальный размер байтах (случайно, от 1 до Size)
Min – минимальное время new (здесь и далее такты процессора)
Max – максимальное время new
Dev – стандартное отклонение
Avg – среднее значение.
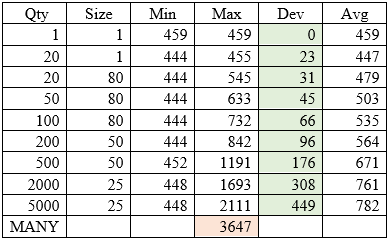
Итак, пока мы захватываем и освобождаем 1 байт – new стабильно занимает 459 тактов.
Для 20 блоков уже есть некоторый разброс.
По мере увеличения количества блоков (размер уменьшается, чтобы влезало в память) разброс растет.
Для 5000 блоков максимальное время увеличилось почти в 5 (!) раз.
Отдельно была искусственно создана довольно сильная фрагментация.
В таких условиях время выполнения new выросло в 8 (!) раз.
При этом никакой уверенности, что достигнут предел, быть не может.
Вывод: при отсутствии аналитического доказательства предельного времени отклика, динамическая память в стандартных библиотеках, идущих с компилятором, не удовлетворяет требованиям реального времени.
Случайным образом захватывались и освобождались блоки памяти.
Профилировщик дал следующую картину:
Qty – количество блоков
Size – максимальный размер байтах (случайно, от 1 до Size)
Min – минимальное время new (здесь и далее такты процессора)
Max – максимальное время new
Dev – стандартное отклонение
Avg – среднее значение.

Итак, пока мы захватываем и освобождаем 1 байт – new стабильно занимает 459 тактов.
Для 20 блоков уже есть некоторый разброс.
По мере увеличения количества блоков (размер уменьшается, чтобы влезало в память) разброс растет.
Для 5000 блоков максимальное время увеличилось почти в 5 (!) раз.
Отдельно была искусственно создана довольно сильная фрагментация.
В таких условиях время выполнения new выросло в 8 (!) раз.
При этом никакой уверенности, что достигнут предел, быть не может.
Вывод: при отсутствии аналитического доказательства предельного времени отклика, динамическая память в стандартных библиотеках, идущих с компилятором, не удовлетворяет требованиям реального времени.
Вашему автору следовало бы еще указать компилятор, его версию и параметры компиляции.
Еще надо подтвердить из какой памяти выпонялся код, и чем еще была занята шина, как были настроены шинные коммутаторы, какое выравнивание было у данных, были ли запрещены прерывания и как измерялось время. И где гарантия что измеритель времени сам был детерминированным.
Короче, хоть ваш результат и близок к истине, но особого доверия не вызывает.
У вас слишком большой разброс, отношу это на небрежность тестирования. И нет статистики с доверительными интервалами.
Но даже приняв это все, скажите почему вам так принципиально за 3 мкс или за 24 мкс выполнится выделение памяти? Вы что память в обработчиках прерывания выделяете?
Всетаки где вам важен такой детерминизм?
Еще надо подтвердить из какой памяти выпонялся код, и чем еще была занята шина, как были настроены шинные коммутаторы, какое выравнивание было у данных, были ли запрещены прерывания и как измерялось время. И где гарантия что измеритель времени сам был детерминированным.
Короче, хоть ваш результат и близок к истине, но особого доверия не вызывает.
У вас слишком большой разброс, отношу это на небрежность тестирования. И нет статистики с доверительными интервалами.
Но даже приняв это все, скажите почему вам так принципиально за 3 мкс или за 24 мкс выполнится выделение памяти? Вы что память в обработчиках прерывания выделяете?
Всетаки где вам важен такой детерминизм?
Мы сейчас не научную работу защищаем.
В книге заявлено: «Опасайтесь операций new. Если можно не использовать её при работе — не используйте».
Именно опасайтесь, и именно при возможности…
Вы попросили подтверждений, что всё это — не вчерашний день. Я их предоставил.
Если бы речь шла о том, что «мы сделали так, что операцию new нельзя использовать совсем, так что теперь никто никогда не сможет ею воспользоваться» — имело бы смысл опускаться до подтверждения всего, что Вы запросили. Пока же — просто добавлено подтверждение того, что рекомендация — не голословная. Дальше — каждый читатель самостоятельно решает, как ему поступить.
Но если вдруг из-за использования оператора new из стандартной библиотеки что-то случится — никто не скажет, что его не предупреждали. Возможные последствие должны быть задокументированы.
На этом предлагаю свернуть обсуждение данного раздела книги в рамках этой публикации.
В книге заявлено: «Опасайтесь операций new. Если можно не использовать её при работе — не используйте».
Именно опасайтесь, и именно при возможности…
Вы попросили подтверждений, что всё это — не вчерашний день. Я их предоставил.
Если бы речь шла о том, что «мы сделали так, что операцию new нельзя использовать совсем, так что теперь никто никогда не сможет ею воспользоваться» — имело бы смысл опускаться до подтверждения всего, что Вы запросили. Пока же — просто добавлено подтверждение того, что рекомендация — не голословная. Дальше — каждый читатель самостоятельно решает, как ему поступить.
Но если вдруг из-за использования оператора new из стандартной библиотеки что-то случится — никто не скажет, что его не предупреждали. Возможные последствие должны быть задокументированы.
На этом предлагаю свернуть обсуждение данного раздела книги в рамках этой публикации.
Прикинул… Допустим, принимается блок по SPI с частотой 1 МГц (я специально взял малую частоту). В STM32 размер FIFO равен двум байтам, так что забрать данные надо уже через 16 мкс.
Допустим, прикладной программист запросил буфер на стороне, а потом — начал выделять под него память оператором new. Может успеть, может — не успеть к моменту переполнения буферного регистра. Зависит от того, как оператор отработает. И при отладке может всегда отработать, а уже у Заказчика — нет.
Вы скажете: «Кто ж так делает?». Вот я и отвечу, что я в тексте и написал, что так делать не стоит. Текст показывает основные отличия программирования под железо относительно общих принципов программирования. Считается, что читатель знаком с информатикой, но не очень глубоко знаком с аппаратурой.
Неопытные программисты под железо и не такое могут. Откуда им опыта набраться? Вот и написано. Опытные же могут скачать с нашего сайта документ, соответствующий всем требованиям ЕСПД и пользоваться им.
Допустим, прикладной программист запросил буфер на стороне, а потом — начал выделять под него память оператором new. Может успеть, может — не успеть к моменту переполнения буферного регистра. Зависит от того, как оператор отработает. И при отладке может всегда отработать, а уже у Заказчика — нет.
Вы скажете: «Кто ж так делает?». Вот я и отвечу, что я в тексте и написал, что так делать не стоит. Текст показывает основные отличия программирования под железо относительно общих принципов программирования. Считается, что читатель знаком с информатикой, но не очень глубоко знаком с аппаратурой.
Неопытные программисты под железо и не такое могут. Откуда им опыта набраться? Вот и написано. Опытные же могут скачать с нашего сайта документ, соответствующий всем требованиям ЕСПД и пользоваться им.
Язык С++, на котором чаще всего пишут для микроконтроллеров...
Это мило. Микроконтроллер микроконтроллеру, конечно, рознь, но мне думалось, что на AVR или PIC16 с парой килобайт памяти все-таки больше используют старый добрый Си. Возможно, с элементами ООП типа имитации классов и т. п.
В противном случае слишком велик соблазн воспользоваться конструкциями, которые как этот самый new выглядят исключительно просто, но под собой скрывают массу лишних операций.
Не используйте PIC16. Самый дешевый PIC16 стоит 2.5$. STM32 с теми же характеристиками 1$.
У AVR нет нормальных отладчиков. Не используйте AVR. (5 секунд на загрузку 256кб. RLY?!)
Это мое личное мнение.
Моё личное мнение: Свои проекты для AVR я писал исключительно на ассемблере. Рука не поднималась писать даже на Сях. Сейчас я уже не делаю новых проектов на AVR. Есть Cortex M разных мощностей и цен.
Сегодняшние реальности по AVR: Arduino — вполне себе плюсовая библиотека. И, как ни странно, многие задачи прекрасно пашут. Если посмотрите статьи про библиотеку mcucpp, которая вообще использует подходы метапрограммирования, то увидите, что современные оптимизаторы делают код для AVR не хуже по оптимизации, чем ручная разработка на ассемблере. Я эту mcucpp для ARM использую, так что знаком с нею не только по статьям. Но исходно она явно делалась именно под AVR, на плюсах.
Так что сегодня для AVR многие пишут именно на плюсах. И это даже работает. У меня на столе стоит 3D принтер, в котором исходно была AtMega.
Но, как верно отмечено выше, эпоха 8 битной техники уходит в прошлое. Она уже ничем, кроме привычности для некоторых разработчиков, не выигрывает.
Сегодняшние реальности по AVR: Arduino — вполне себе плюсовая библиотека. И, как ни странно, многие задачи прекрасно пашут. Если посмотрите статьи про библиотеку mcucpp, которая вообще использует подходы метапрограммирования, то увидите, что современные оптимизаторы делают код для AVR не хуже по оптимизации, чем ручная разработка на ассемблере. Я эту mcucpp для ARM использую, так что знаком с нею не только по статьям. Но исходно она явно делалась именно под AVR, на плюсах.
Так что сегодня для AVR многие пишут именно на плюсах. И это даже работает. У меня на столе стоит 3D принтер, в котором исходно была AtMega.
Но, как верно отмечено выше, эпоха 8 битной техники уходит в прошлое. Она уже ничем, кроме привычности для некоторых разработчиков, не выигрывает.
Sign up to leave a comment.
Обзор одной российской RTOS, часть 4. Полезная теория