Comments 69
Оно файлы к себе затягивает или просто строит индекс?
Доступ к файлу напрямую осуществляется или проксируется?
Что если у пользователя нет праа на какую-то папку?
Неплохо!
Спасибо!
Оно файлы к себе затягивает или просто строит индекс?
Ambar затягивает к себе все файлы и хранит у себя
Доступ к файлу напрямую осуществляется или проксируется?
Доступ к файлу через Ambar из его базы данных
Что если у пользователя нет праа на какую-то папку?
В настройках краулера можно указать из под какой учетки ходить. Во время поиска нет разделения файлов по правам
но rbac присутствует?
Ambar затягивает к себе все файлы и хранит у себя
Получается если помойка на терабайт, надо еще терабайт на Ambar выдать?
Вопрос скорее концептуальный (идеи, предложения?): как быть с отсканированными документами? Доков много, секретари сканят все пачками в одну папку, не всегда все разбирается — адищенский ад в итоге.
Ну если ваши секретари уже отсканировали все документы то все просто — натравливаете на эту папку Ambar, он автоматически распознает текст со сканов и позволяет по нему искать. Вот скриншот как это выглядит: 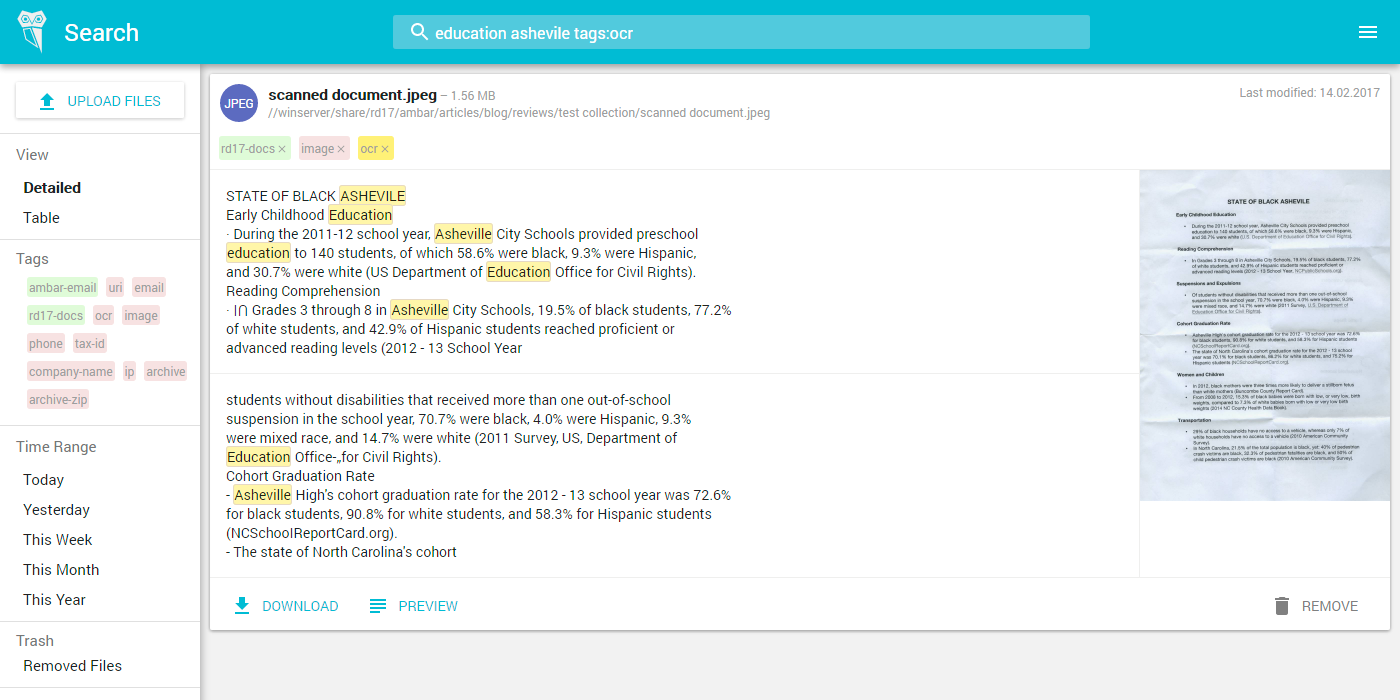
Прошу прощения за интимный вопрос, а что это вообще за рабочий процесс в котором несколько человек сканят в одну папку?
Просто мы делаем программу для работы с хотфолдерами и мне интересны пользовательские кейсы в этой области.
Если, конечно же, это не секретно.
Заранее спасибо.
Очень интересная идея сделать полнотекстовый кеш всего и отдавать его же всем.
Как наяву вижу следующие запросы: *парол*, *зарплат*директор*, и так далее.
На дворе 2017 год. И информационная безопасность это не последний, а первый вопрос, который должен быть у разработчика приложений.
Здорово заново изобрести Microsoft Search Server для *nix платформ, но безопасность, господа.
Докер-докер-докер-докер-докер. Убунту-убунту-убунту-убунту-убунту.
А если я хочу, например, на macOS развернуть это все? Или на OpenBSD? Или на RHEL? А ничего, говорят мне авторы этого проекта, ставь убунту и разворачивай там докер, потому что это стильно-модно-молодежно.
Нет ничего более идиотского, чем ПО, которое безальтернативно распространяется в виде докер-контейнера.
Знавал я одну помойку, стихийно образовавшуюся лет двенадцать назад.
«ШараСекретарь» называется.
Создавалась исключительно с целью файлообмена между начальником одного органа гос.власти с его приемной ибо принтер ставить начальнику было совершенно нецелесообразно, и даже настраивать печать на принтер в приемной не хотелось по соображениям — пусть секретарь допиливает напильником за шефом перед печатью.
(Да, я мог сказать что _Шефу_ не нужно ставить всё самое лучшее, и даже «так» посмотреть на завсклада, чтобы она перестала спорить).
Но блин, я не ожидал что эта папочка превратиться в главную файлопомойку предприятия.
Обнаружив что на этом компе висит больше файлов чем на штатной файлопомойке на большом толстом сервере с рейдом и т.п. я пытался бороться. Пару лет пытался. И ярлыки людям переправлял и разговоры разговаривал. Лет семь назад плюнул я на это дело и тупо переобозвал «Секретаря» в «Приемную» а файлсервер в «Секретарь».
Я там уже лет пять не появлялся, но шара живет…
Админа у них там не было, да и навряд ли кто-то в здравом уме согласился бы там работать на полную ставку.
У меня 300ГБ инфы на файловом сервере + у каждого пользователя еще свой профиль, который тоже можно засунуть для поиска инфы (папку Docs + Desktop).
Документы лежат в нужных папках по темам, но все равно их бывает хрен найдешь.
Осталось придумать как подтягивать разграничение по правам доступа и будет готовое решение.
А проект хороший, да.
Я вас не понял, про какой золотой образ вы говорите?
мы решились на создание своего продукта, конечно же open-source'ного.
А проект хороший, да.
Только вот он ни разу не "open source", там fair source с "Use Limitation: 1 user". Так что "хороший" при наличии массы разумных open source альтернатив — по-моему, преувеличение.
Я не уверен насчет gpl'ных, но там все как-то весьма сурово, да. Как минимум, у них в лицензировании должен быть отдельный (и большой, по идее, учитывая Docker) файлик с кучей всяких лицензий хотя бы на всякое такое. Впрочем, конкретно проект ambar-crawler у них вообще без явно указанной лицензии.
Тщательно настроенный tesseract
Да, проблема появляется, когда захочешь это на NAS поставить. Идея хороша, но реализация хромает (как с сисадминской стороны — докерпомойка, так и с программной — хранение всех файлов в кастомной бд дубликатом)
Интересно, а вы контрибьютите в проекты, которые используете? Как-то учитываете лицензии проектов, на которые опираетесь?
Например, я не вижу файла с перечислением лицензий зависимостей от слова совсем. Как минимум, часть зависимостей у вас под Apache License v2, но никакого указания этого я не вижу.
Ну и хвалиться тем, что у вас "Поддержка всех офисных форматов (в т.ч. openoffice), pdf с картинками и старых кодировок вроде CP866" довольно глупо, это есть у всех кто использует Apache Tika. Собственно, поддержку cp866/ibm866 я добавлял когда-то ради лексиконовских файлов.
Формально они правы, свободная лицензия и открытый код хоть и коррелируют, но не синонимы. Но в целом это некрасиво конечно.
А нарушение чужих лицензий? Ну бывает. Но кто же будет судиться?
Мгновенно искать по именам файлов умеет everything (voidtools.com). Строит индекс, к себе ничего не копирует, умеет прикидываться http- и ftp-сервером.
Это минимальные?! Чем вызвано? Просто хотел бы попробовать на старенькой машине.
Поиск документов в сетевых шарах и файловых помойках