Краткое содержание
- Использование событийной (event-driven) архитектуры для уменьшения связанности — весьма популярная идея при проектировании микросервисов.
- Событийная бизнес-логика хорошо подходит для децентрализованных данных и решения проблем сквозной функциональности. Однако, не стоит выстраивать сложные цепочки по передаче событий из сервиса в сервис. Координация сервисов с помощью команд, а не событий — позволяет еще сильнее их развязать.
- ESB (Enterprise Service Bus, в контексте статьи — "умная шина" — прим.перев.) плохо сочетается с микросервисной архитектурой. Предпочтительнее использовать простые каналы передачи данных и умных клиентов (smart endpoints, dumb pipes). Но, не отказывайтесь от сервиса-координатора других сервисов только лишь из опасений получить один богоподобный сервис: бизнес-логике все равно нужен дом.
- Workflow engines прошлого были, в основном, вендоро-зависимы. Так называемые "zero-code" решения — на практике оборачивались сущим кошмаром для разработчиков. В настоящее время есть легковесные и простые средства управления workflow, многие из них — с открытым исходным кодом.
- Не тратьте время на написание своих собственных конечных автоматов. Напротив, используйте готовые решения во избежание сложностей.
Для достижения слабой связанности используйте event-driven архитектуру
Подобный совет нередко встречается в дискуссиях по теме микросервисов. В том числе, он популярен и поддерживается в сообществах DDD (Domain-Driven Design). Авторы статьи, будучи потенциальными сторонниками событийных моделей, тем не менее задались вопросом: какие риски может нести бездумное использование событий? Для ответа, были рассмотрены 3 популярные гипотезы:
- События уменьшают связанность
- Богоподобных (central control) сервисов следует избегать
- У workflow engines есть свои "болячки"
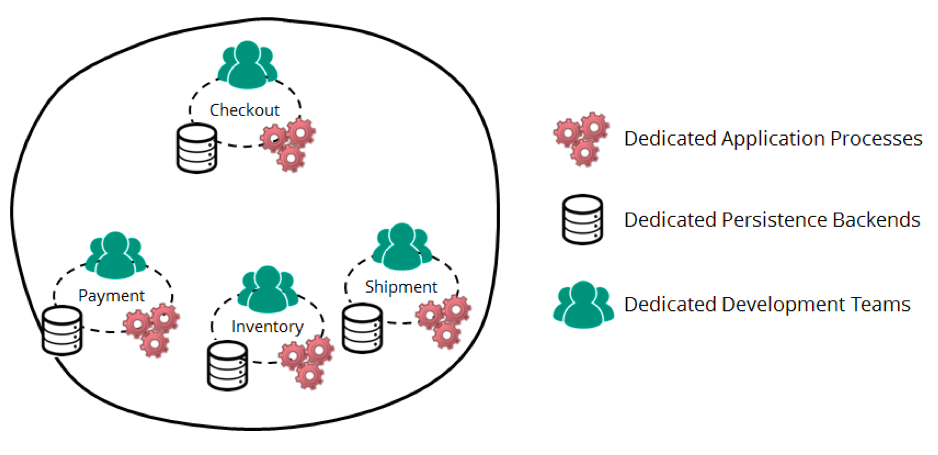
Примеры ниже — искусственные, но вдохновленные реальным бизнес-процессом обработки заказа в Zalando. Пусть имеется 4 ограниченных контекста (bounded context) в 4 изолированных приложениях (это могут быть как микросервисы, так и представители других архитектур):
Как уменьшить связанность с помощью событий
Предположим, что сервис Checkout должен уведомить пользователя, если товар появился на складе и может быть отгружен немедленно. Конечно, Checkout может напрямую опрашивать сервис Inventory о количестве товара на складе, но это бы сделало Checkout зависимым от Inventory, т.е. усилило бы связанность.
Альтернативный подход: Inventory публикует события об изменении товаров на складе. Checkout слушает события и сохраняет свежие значения в локальном кэше. Эти данные — копия, абсолютная целостность которой вовсе не обязательна. Хотя, определенный уровень событийной целостности, как правило, необходим в распределенных системах.
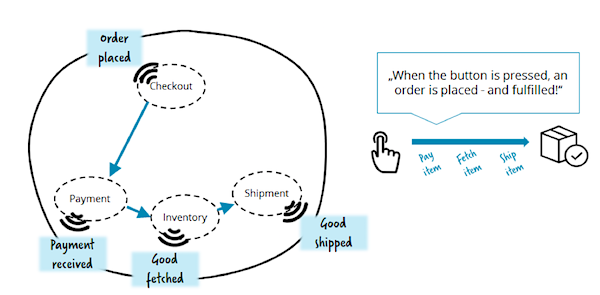
Еще один сценарий: сквозная функциональность. Пусть необходимо отправлять уведомления для заказчика на определенных шагах выполнения заказа. Мы могли бы добавить к системе полностью автономный сервис Notification, хранящий настройки и контактные данные заказчиков. Получив событие вида "платеж получен" или "заказ отгружен", этот сервис отправлял бы письма, не требуя внесения изменений в другие сервисы. Как мы видим, event-driven архитектура очень гибка, и позволяет легко добавлять новые сервисы, либо расширять старые.
Опасности сложных цепочек передачи событий
Разработчики, внедряющие event-driven архитектуру, часто становятся одержимы: события великолепно уменьшают связанность системы, так давайте же использовать события везде и всегда! Проблемы начинаются, когда команда реализует бизнес-процесс (напр. обработку заказа) через цепь сообщений от одного сервиса к другому. Рассмотрим простейший пример: пусть каждый сервис в цепочке сам решает, что ему делать и какие события отправлять:
Да, это работает. Но, проблема в том, что ни у одного из звеньев цепи нет четкого видения всего процесса. Это делает бизнес-процесс сложным для понимания, и (что еще более важно) сложным для изменения. Учтите также, что в реальном мире бизнес-процессы далеко не так просты, и обычно включают в себя куда больше сервисов. Авторам статьи доводилось видеть сложные микросервисные системы, которые никто уже не понимает в деталях.
А теперь подумаем, как бы нам реализовать резервирование товара на складе ДО проведения платежа:
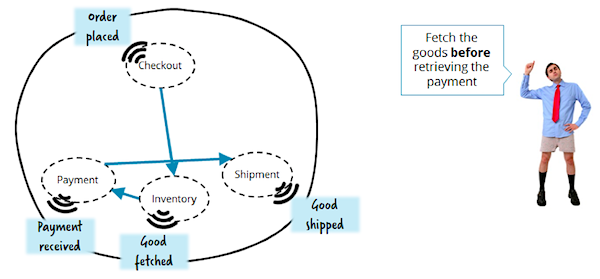
Необходимо поправить и перевыложить несколько сервисов, чтобы просто изменить последовательность шагов выполнения заказа! Это — антипаттерн для микросервисной архитектуры, поскольку ее ключевой принцип — стремиться к меньшей связанности и большей изолированности. Поэтому подумайте дважды перед использованием событий в подобных "сервис-к-сервису" процессах, особенно там, где ожидается высокая сложность.
Команды, но без необходимости в центральном контроле
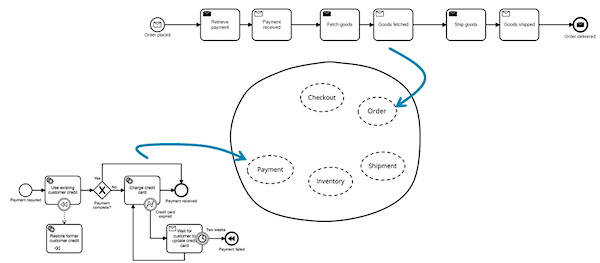
Разумнее было бы держать весь бизнес-процесс в отдельном сервисе. Такой сервис-управленец может отправлять команды остальным, например — "провести платеж". При этом, следует избегать знания микросервисов друг о друг о друге. Авторы называют этот паттерн "оркестрация" (orchestration). Например: "Order управляет (orchestrates) сервисами Payment, Inventory и Shipment".
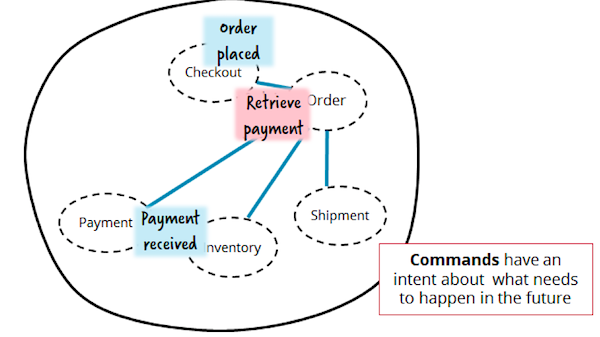
Говоря об оркестрации, многим приходят на ум чудодейственные Enterprise Service Bus (ESB) шины, а также Business Process Modelling (BPM) решения. Эти сложные, проприетарные инструменты обладают плохой репутацией, и неспроста. Зачастую они лишают нас простого, понятного тестирования и легковесной доставки приложений. В то же время, James Lewis и Martin Fowler заложили многие из основ микросервисной архитектуры, предложив использовать "умные конечные точки и простые каналы передачи" (smart endpoints, dumb pipes).
Рисунок выше — не предполагает использования "умной шины". Весь контроль над обработкой заказа возложен на отдельный сервис-управленец Order. Команда вольна реализовать этот сервис как удобно, с использованием любой технологии по вкусу. Таким образом, изменения бизнес-процесса затронут один, и только один микросервис. Более того, сосредоточенный в одном месте бизнес-процесс куда проще понять.
Sam Newman в своей книге Building Microservices рассматривает риск того, что со временем подобный сервис-управленец разрастется в богоподобного монстра. Такой god service соберет в себя всю бизнес-логику, а остальные — выродятся в анемичные сервисы, или того хуже: станут простым CRUD.
Это случилось из-за использования команд в ущерб событийной архитектуре? Или проблема в самой оркестрации? Ни то, ни другое. Давайте взглянем на "smart endpoints" Фаулера. Что определяет "умную" конечную точку? Хороший дизайн API. Для сервиса Payment можно разработать высокоуровневый API, реагирующий на команды вида "вернуть платеж", и публикующий события вида "платеж проведен", "не удалось провести платеж" и т.д. Всю чувствительную информацию (например, о кредитной карте пользователя) следует держать внутри и только внутри микросервиса. В этом случае — микросервис Payment не станет анемичным, даже если им пользуется сервис-управленец или еще кто-то.
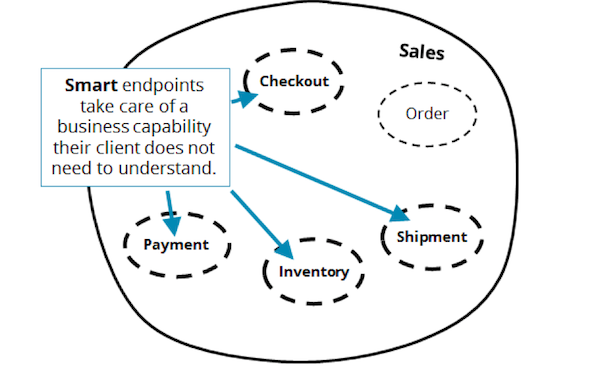
Cервисы, работающие долго
Для разработки умных конечных точек и годных клиентских API, следует допустить, что некоторые процессы могут выполняться долго — им же необходимо закулисно решать реальные бизнес-задачи! Предположим, что в случае просроченной кредитной карты — у заказчика должен быть шанс исправить ситуацию (пример навеян GitHub, где бизнес-аккаунт закрывается только через 2 недели после неуплаты). Если наш сервис Payment не собирается заниматься ожиданием действий заказчика, он может делегировать эту задачу своему потребителю — сервису Order.
Однако, если держать подобную функциональность внутри сервиса Payment, архитектура станет чище и согласованнее с идеей "bounded context" из DDD. Само факт ожидания, пока заказчик заведет новую кредитку — означает, что платеж все еще может быть проведен. Как следствие, Payment API становится чистым и простым. Иногда ожидание может составлять 2 недели — вот что мы называем "долгоиграющим" бизнес-процессом!
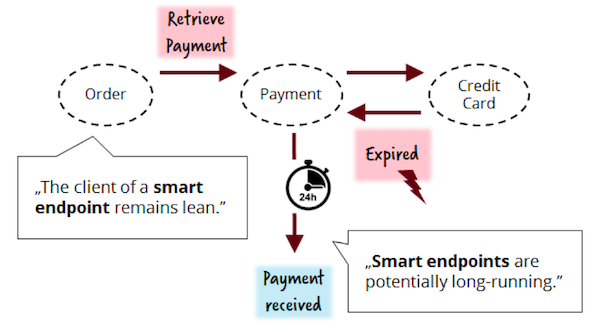
Хранение состояния сервиса
Долгоиграющие процессы должны где-то хранить свое состояние, такое как "ожидаю платеж" и т.п. Сохранить состояние приложения после перезагрузки — это далеко не новая задача, и вот два типичных ее решения:
- Создать свой механизм хранения состояния на основе паттернов Entity, Persistent Actor и т.п. Кто когда-нибудь создавал таблицу Order со столбцом Status? То-то и оно!
- Понять и принять конечный автомат или целый workflow engine. Нам доступно немало таких инструментов, в том числе довольно зрелых. Но и прогресс не стоит на месте: к примеру, Netflix и Uber разрабатывают свои решения с открытым исходным кодом.

По опыту авторов статьи, свои велосипеды для хранения состояния зачастую эволюционируют в самодельные конечные автоматы. Потому что перед написанной системой ставятся новые и новые задачи. Например:
- поддержка таймаутов ("а давайте добавим планировщик"),
- средства отчетности ("эй, почему бы парням из бизнеса просто не использовать SQL для выборки нужных данных")
- средства мониторинга.
Мы пишем свои конечные автоматы не только из-за синдрома "Not-Invented-Here", но благодаря отрицательной репутации, которую вполне заслужили старомодные средства автоматизации бизнес-процессов. У многих есть болезненный опыт работы с подобными "zero-code" инструментами. Менеджмент покупает технологию в надежде избавиться от разработчиков… чего, конечно же, не происходит. Вместо этого, поддержка тяжеловесной и проприетарной технологии сваливается на плечи IT отдела, где навеки остается чужеродным, отторгаемым элементом.
Легковесные конечные автоматы и workflow engines
Существуют простые и гибкие инструменты, для работы с которыми достаточно написать всего несколько строк кода. Это никакие не "zero-code" решения, а обычные библиотеки разработчика. Они берут на себя работу с конечными автоматами, достаточно быстро окупаются и начинают приносить пользу.

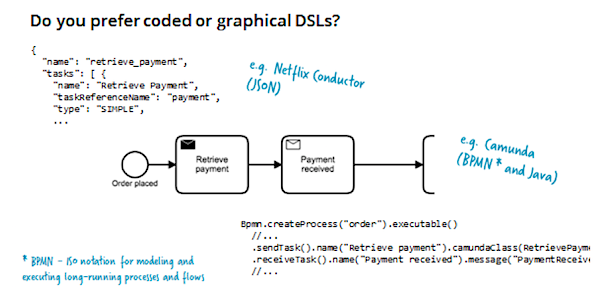
Как правило, подобные инструменты позволяют графически описать workflow с использованием ISO-нотации BPMN, либо с использованием языков на базе JSON, YAML, или DSL на основе Java, Golang и т.п. Важный момент: описание workflow — это и есть реальный код, выполняемый в процессе.
BPMN, и ей подобные — поддерживают достаточно сложные операции: управление временем работы, таймауты, бизнес-транзакции. А еще, это довольно популярная и зрелая нотация, поэтому мы можем говорить о ее пригодности для решения сложных задач.

На рисунке выше — экземпляр workflow ожидает получения события "Goods Fetched"… но время ожидания ограничено. В случае таймаута мы откатываем бизнес-транзакцию, выполнив специальное компенсирующее действие. В этом случае платеж будет возвращен отправителю — конечный автомат запоминает все ранее выполненные действия, что позволяет выполнить весь соответствующий компенсирующий код. Что позволяет конечному автомату управлять бизнес-транзакцией — идея здесь та же, что в паттерне Saga.
Графическая нотация — это и своего рода "живая документация", у которой нет ни шанса устареть и оторваться от реальной системы. А что насчет тестирования? Некоторые библиотеки поддерживают юнит-тесты, в т.ч. для долгоиграющих сценариев. К примеру, Camunda на каждый прогон теста генерирует HTML c сценарием выполнения теста, который легко вставить в обычный CI отчет. В этом случае графическая нотация приобретает еще больший смысл:

Workflow живут внутри сервисов
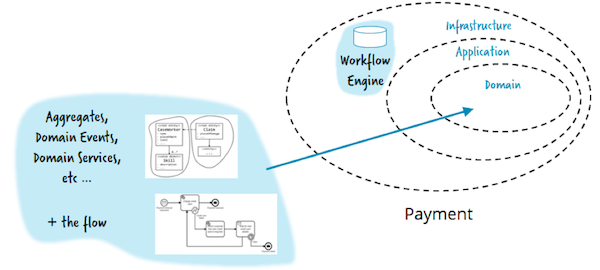
Выбор и использование конкретного workflow-фреймворка следует проводить децентрализованно, на усмотрение каждой команды разработчиков по отдельности. Конечный автомат — это детали реализации, которые не должны быть видны снаружи сервиса. Нет необходимости в одном и только одном глобальном фреймворке для компании. Конечный автомат — это просто библиотека, упрощающая разработку.
Вдобавок, конечный автомат — это часть бизнес-логики. В зависимости от инструмента, он может как встраиваться в процесс вашего приложения (напр. используя Java, Spring и Camunda), так и отдельным процессом, общаясь через библиотеку-клиента (Zeebe) или REST API (Camunda и Netflix Conductor). Имея под рукой готовый конечный автомат с поддержкой долгоиграющих бизнес-задач, можно сосредоточиться на бизнес-логике и дизайне API, реализовав настоящий smart endpoint.
Покажите код
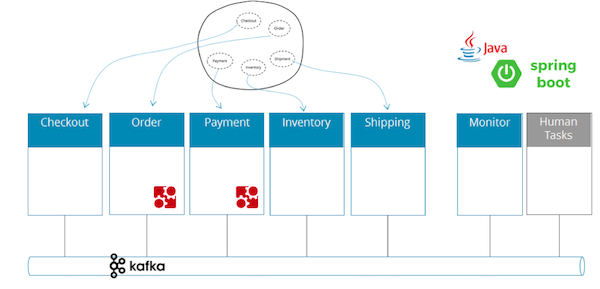
Не скатываясь в сухую теорию, авторы статьи написали демо-приложение и выложили на GitHub. Там живые примеры изложенных в статье идей.
Код на Java, с использованием только open source библиотек (Spring Boot, Camunda, Apache Kafka).
Выводы
- События уменьшают связанность? Не всегда. События отлично подходят для децентрализации и сквозной функциональности, но не стоит делать сложные цепочки по передаче сообщений от сервиса к сервису. Вместо этого используйте команды и сервисы-управленцы.
- Стоит ли избегать централизации? Без фанатизма. Умные ESB плохо сочетаются с микросервисами. Предпочитайте простые каналы передачи и умные конечные точки. Умные сервисы с бизнес-логикой внутри — помешают явиться на свет богоподобному сервису-управленцу, вобравшему всё и вся. Умный сервис сможет выполнять долгоиграющий бизнес-процесс.
- Workflow engine — это боль? Не всегда. В прошлом был вендор-лок и попытки создать "zero-code" инструменты. Сейчас есть легковесные фреймворки с открытым исходным кодом, решающие типовые задачи. Не велосипедьте конечные автоматы, пользуйтесь готовыми инструментами.
Bernd Rucker. Участвовал и обучал в огромном кол-ве проектов по разработке ПО, связанных с долгоиграющими бизнес-процессами. В том числе: в Zalando (международный продавец одежды) и нескольких телеком-компаниях. Контрибьютор нескольких workflow engines c открытым исходным кодом. Автор книги "Real-Life BPMN", сооснователь Camunda.
Martin Schimak. Более чем 10-летний опыт работы в энергетической отрасли, телекоме и… области аэродинамических труб. Контрибьютор нескольких проектов на GitHub. Докладчик на ExploreDDD, O'Reilly Software Architecture Conference и KanDDDinsky. Персональный блог plexiti.com. Организатор митапов по микросервисам и DDD (Вена).
