Существует несколько парсеров, подходящих для русского языка. Некоторые из них могут даже выполнять синтаксический анализ, как SyntaxNet, MaltParser и AOT:
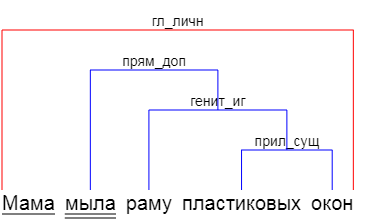
… или выявлять факты, как Tomita.
Глядя на эти парсеры, я вижу какую-то огромную сложность вычислений, требования к памяти, лицензионные ограничения и… ограниченность каждого решения, увы.
Чтобы понять, что же там такого сложного, мне захотелось сделать собственный парсер. Благо выходные оказались длинными.
Я подумал, как мы сами разбираем текст? Как выделяем из фразы ключевые элементы, строим в голове отношения между словами?
Говорят, что Tomita построен на основе GLR-парсера, который, в свою очередь расширяет LR-парсер, который читает слова по порядку, пытается строить дерево отношений между ними.
У меня же была мысль, что текст надо рассматривать как набор штампов, на которые у нас наметан глаз. "Белый мотылек на красной розе", "темное небо над синим морем", "глупый пингвин робко прячет" — везде видим существительное и относящееся к нему прилагательное. Причем мы понимаем, что «белый» относится к мотыльку, а не к розе. Как мы это делаем? Как минимум, мы видим, что «белый» мужского рода, как и «мотылек», а «красная» женского, как и роза. В случае с «небом» и «морем» нам помогает падеж, в который поставлено существительное.
Далее, находя штампы, получившееся кусочки фразы соединяем в другие штампы, и так, пока не поймем всю фразу целиком — «мотылек на розе» (мотылек — белый, роза — красная), «небо над морем» (небо — темное, море — синее).
То есть, для поиска шаблона (прилагательное, существительное) мне нужно искать пару слов в том же падеже, числе и роде. Как? Естественным решением определения характеристик (граммем) в Python использовать pymorphy2 by kmike
Слова 'femn', 'ADJF', 'sing', 'gent', 'Qual' — это обозначения для граммем, принятых в pymorphy2. Обозначения уникальны, их можно использовать для однозначного определения нужных характеристик слова.
Теперь, имея инструмент, составим простой шаблон:
Здесь ищем существительное (NOUN) в именительном падеже (nomn), за ним глагол (VERB), далее существительное в винительном падеже (accs). Не описанные в шаблоне характеристики нам не важны.
Сделаем его читалку:
Пусть вас здесь не пугает работа через StringIO — я хотел сделать потоковое чтение, просто на всякий случай, если понадобится читать большие тексты.
Приведенный кусок кода лишь считывает шаблоны, но более ничего не делает. Добавим анализируемый текст и его парсинг:
Pymorphy2 при анализе слова возвращает массив всех возможных вариантов, что это за слово может быть: «мыла» — это существительное или глагол. Поэтому наша задача проверить все эти варианты и выбрать из них такой, что характеристики слова подойдут под шаблон. Это делается в функции checkWord.
Получаем результат разбора:
Ну что же, неплохо для начала.
Нет, конечно, теперь надо описать соответствие падежей, родов и т.д. между словами. Модифицируем описание шаблона:
Появилась строка определения переменных
Добавляем разбор правил в парсинг шаблонов. Правило компилируется в две лямбды — для получения значения до символа "=", и для для получения второго значения.
И добавляем проверку правил в парсинг текста — просто вычисление лямбд и сравнение их результатов:
Прогоним на классике
Еще введем правило для имен:
Это дает разбор:
Все было так хорошо, что означало, что мы чего-то не заметили. Парсер сломался на фразе «Младшие братья Миша и Вова ходят в детский сад» — он не смог подтвердить правило
Следовательно, правило должно быть более сложным. Ну, раз я все равно компилирую лямбды из текста, то можно создать вместо двух одну, возвращающую результат проверки. Тогда это правило можно будет записать в виде выражения на чистом Python-е:
Мне показалось, что у Python должно быть встроенное средство получения имен «a» и «b», задействованных в выражении. Предчувствие не обмануло, небольшое чтение help и документации привело меня к парсеру AST, в котором было все необходимое, и следующему коду:
Все правила переписал на выражения Python. Кстати, если правило записано неправильно, то оно не компилируется еще при чтении словаря шаблонов и программа вылетает по exception, так что если словарь прочитался, то правила выполнимы.
И все получилось:
1. Как видите, я остановился на поиске отдельных шаблонов, но не стал результат разбора объединять в дерево синтаксического разбора. Тому есть несколько причин, и одна из них — я не уверен, что стоит это делать. Каждый вариант разбора дает нам маленькую крупицу информации. Объединяя их в дерево, мы пытаемся втиснуть знания в искусственную структуру. Ребенок может читать и понимать предложения, не зная, какое слово в нем подлежащее, а какое — сказуемое. Он берет крупицы и создает в своей голове картину (описываемого) мира. Зачем же нам требовать от машины большего?
2. Очевидно не хватает правила, насколько одно слово может быть удалено в тексте от другого. Так «Папа» стал «Ильей», хотя между ними стоят слова «и брат».
3. Так же очевидно, что нужно сортировать результаты между собой и отбрасывать маловероятные. Определение релевантности — вопрос открытый, как минимум можно измерять удаленность слов друг от друга.
4. В правилах, помимо остальных частей речи, не хватает знаков пунктуации. Можно ввести константные литералы «NOUN '-' NOUN», а можно, как выше в примере с учительницей, проверять знак в правиле.
5. Pymorphy2 умеет предполагать принадлежность слов к частям речи, поэтому возможны даже такие варианты:
Однако здесь пришлось оригинальные слова Петрушевской поменять местами, т.к. нет шаблона с обратным порядком слов. Не то, чтобы это проблема, шаблон ввести недолго, но перестановки слов в русском языке случаются часто и всех их шаблонами не покрыть. Поэтому имеет смысл ввести в описания шаблонов какие-то модификаторы, допускающие перестановку.
Код лежит на GitHub.
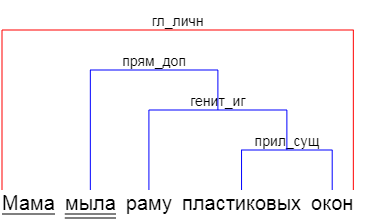
… или выявлять факты, как Tomita.
Глядя на эти парсеры, я вижу какую-то огромную сложность вычислений, требования к памяти, лицензионные ограничения и… ограниченность каждого решения, увы.
Чтобы понять, что же там такого сложного, мне захотелось сделать собственный парсер. Благо выходные оказались длинными.
Основная идея
Я подумал, как мы сами разбираем текст? Как выделяем из фразы ключевые элементы, строим в голове отношения между словами?
Говорят, что Tomita построен на основе GLR-парсера, который, в свою очередь расширяет LR-парсер, который читает слова по порядку, пытается строить дерево отношений между ними.
У меня же была мысль, что текст надо рассматривать как набор штампов, на которые у нас наметан глаз. "Белый мотылек на красной розе", "темное небо над синим морем", "глупый пингвин робко прячет" — везде видим существительное и относящееся к нему прилагательное. Причем мы понимаем, что «белый» относится к мотыльку, а не к розе. Как мы это делаем? Как минимум, мы видим, что «белый» мужского рода, как и «мотылек», а «красная» женского, как и роза. В случае с «небом» и «морем» нам помогает падеж, в который поставлено существительное.
Далее, находя штампы, получившееся кусочки фразы соединяем в другие штампы, и так, пока не поймем всю фразу целиком — «мотылек на розе» (мотылек — белый, роза — красная), «небо над морем» (небо — темное, море — синее).
Выбор правильного инструмента
То есть, для поиска шаблона (прилагательное, существительное) мне нужно искать пару слов в том же падеже, числе и роде. Как? Естественным решением определения характеристик (граммем) в Python использовать pymorphy2 by kmike
import pymorphy2 as py
def tags(word):
morph = py.MorphAnalyzer()
return morph.parse(word)
>>> print(tags('красной')[0])
Parse(word='красной', tag=OpencorporaTag('ADJF,Qual femn,sing,gent'), normal_form='красный', score=0.125, methods_stack=((<DictionaryAnalyzer>, 'красной', 86, 8),))
>>> print(tags('красной')[0].tag.grammemes)
frozenset({'femn', 'ADJF', 'sing', 'gent', 'Qual'})
Слова 'femn', 'ADJF', 'sing', 'gent', 'Qual' — это обозначения для граммем, принятых в pymorphy2. Обозначения уникальны, их можно использовать для однозначного определения нужных характеристик слова.
Первые штрихи на холсте
Теперь, имея инструмент, составим простой шаблон:
source = '''
Вася ест кашу
# сущ глагол сущ
# что/кто делает с_чем-то
NOUN,nomn VERB NOUN,accs
'''
Здесь ищем существительное (NOUN) в именительном падеже (nomn), за ним глагол (VERB), далее существительное в винительном падеже (accs). Не описанные в шаблоне характеристики нам не важны.
Сделаем его читалку:
class PPattern:
def __init__(self):
super().__init__()
import io
def parseSource(src):
def parseLine(s):
nonlocal arr, last
s = s.strip()
if s == '':
last = None
return
if s[0] == '#':
return
if last is None:
last = PPattern()
arr.append(last)
last.example = s
else:
last.tags = s.split()
arr = []
last = None
buf = io.StringIO(src)
s = buf.readline()
while s:
parseLine(s)
s = buf.readline()
return arr
s = parseSource(source)
Пусть вас здесь не пугает работа через StringIO — я хотел сделать потоковое чтение, просто на всякий случай, если понадобится читать большие тексты.
Приведенный кусок кода лишь считывает шаблоны, но более ничего не делает. Добавим анализируемый текст и его парсинг:
source = '''
Вася ест кашу
# сущ гл сущ
# что/кто делает с_чем-то
NOUN,nomn VERB NOUN,accs
Красивый цветок
ADJF NOUN
Птица сидит на крыше
# сущ гл предлог сущ
NOUN,nomn VERB NOUN,loct
'''
text = '''
Мама мыла раму
Вася разбил окно
Лара сама мыла раму
Мама мыла пластиковые окна
'''
import pymorphy2 as py
class PPattern:
def __init__(self):
super().__init__()
def checkPhrase(self,text):
def checkWordTags(tags, grams):
for t in tags:
if t not in grams:
return False
return True
def checkWord(tags, word):
variants = morph.parse(word)
for v in variants:
if checkWordTags(self.tags[nextTag].split(','), v.tag.grammemes):
return (word, v)
return None
morph = py.MorphAnalyzer()
words = text.split()
nextTag = 0
result = []
for w in words:
res = checkWord(self.tags[nextTag].split(','), w)
if res is not None:
result.append(res)
nextTag = nextTag + 1
if nextTag >= len(self.tags):
return result
return None
def parseText(pats, text):
def parseLine(line):
was = False
for p in pats:
res = p.checkPhrase(line)
if res:
print('+',line, p.tags, [r[0] for r in res])
was = True
if not was:
print('-',line)
buf = io.StringIO(text)
s = buf.readline()
while s:
s = s.strip()
if s != '':
parseLine(s)
s = buf.readline()
patterns = parseSource(source)
parseText(patterns, text)
Pymorphy2 при анализе слова возвращает массив всех возможных вариантов, что это за слово может быть: «мыла» — это существительное или глагол. Поэтому наша задача проверить все эти варианты и выбрать из них такой, что характеристики слова подойдут под шаблон. Это делается в функции checkWord.
Получаем результат разбора:
+ Мама мыла раму ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Мама', 'мыла', 'раму']
+ Вася разбил окно ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Вася', 'разбил', 'окно']
+ Лара сама мыла раму ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Лара', 'мыла', 'раму']
+ Лара сама мыла раму ['ADJF', 'NOUN'] ['сама', 'мыла']
+ Мама мыла пластиковые окна ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Мама', 'мыла', 'окна']
+ Мама мыла пластиковые окна ['ADJF', 'NOUN'] ['пластиковые', 'окна']
Ну что же, неплохо для начала.
И что, это всё?
Нет, конечно, теперь надо описать соответствие падежей, родов и т.д. между словами. Модифицируем описание шаблона:
source = '''
# Красивый цветок
ADJF NOUN
-a- -b-
# Правила выведения, разделяющие пробелы обязательны
= a.case = b.case
= a.number = b.number
= a.gender = b.gender
'''Появилась строка определения переменных
-a- -b- и строки правил, начинающиеся с "=". Вообще я не заморачивался с синтаксисом шаблонов, поэтому каждый оператор живет в одной строке, а тип оператора определяется по первому символу.Добавляем разбор правил в парсинг шаблонов. Правило компилируется в две лямбды — для получения значения до символа "=", и для для получения второго значения.
def parseFunc(v, names):
dest = v.split('.')
index = names.index(dest[0])
dest = (eval('lambda a: a.' + '.'.join(dest[1:])), index)
return dest
def parseLine(s):
...
elif s[0] == '-': # внутренние имена
s = [x.strip('-') for x in s.split()]
last.names = s
elif s[0] == '=': # правила
s = [x for x in s[1:].split() if x != '']
dest = parseFunc(s[0],last.names)
src = parseFunc(s[2],last.names)
last.rules.append(((dest[1],src[1]), dest, src))
else:
...
И добавляем проверку правил в парсинг текста — просто вычисление лямбд и сравнение их результатов:
...
res = checkWord(self.tags[nextTag].split(','), w)
if res is not None:
result.append(res)
usedP.add(wi)
if not self.checkRules(usedP, result):
result.remove(res)
usedP.remove(wi)
else:
nextTag = nextTag + 1
if nextTag >= len(self.tags):
return (result, usedP)
...
def checkRules(self, used, result):
for r in self.rules:
if max(r[0]) < len(result):
destRes = result[r[0][0]]
destV = destRes[1]
destFunc = r[1][0]
srcRes = result[r[0][1]]
srcFunc = r[2][0]
srcV = srcRes[1]
if not self.checkPropRule(destFunc,destV, srcFunc, srcV):
return False
return True
def checkPropRule(self, getFunc, getArgs, srcFunc, srcArgs, \
op = lambda x,y: x == y):
v1 = getFunc(getArgs)
v2 = srcFunc(srcArgs)
return op(v1,v2)
Прогоним на классике
+ Эти типы стали есть на нашем складе ['ADJF', 'NOUN'] ['Эти', 'типы']
+ Эти типы стали есть на нашем складе ['ADJF', 'NOUN'] ['нашем', 'складе']
+ Эти типы стали есть на нашем складе ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['типы', 'стали', 'на', 'складе']
+ Эти типы стали есть на нашем складе ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['стали', 'есть', 'на', 'складе']Еще введем правило для имен:
# хомяк Коля
NOUN Name
-a- -b-
= a.tag.case = b.tag.case
= a.tag.number = b.tag.number
Это дает разбор:
+ Сестра Татьяна - учительница ['NOUN', 'Name'] ['Сестра', 'Татьяна']Больше правил, хороших и разных
Все было так хорошо, что означало, что мы чего-то не заметили. Парсер сломался на фразе «Младшие братья Миша и Вова ходят в детский сад» — он не смог подтвердить правило
= a.gender = b.gender, потому что «младшие» не имеет родовой принадлежности и может относиться как к слову мужского рода «братья», так и к женскому «сестры».Следовательно, правило должно быть более сложным. Ну, раз я все равно компилирую лямбды из текста, то можно создать вместо двух одну, возвращающую результат проверки. Тогда это правило можно будет записать в виде выражения на чистом Python-е:
= a.tag.gender is None or a.tag.gender == b.tag.genderМне показалось, что у Python должно быть встроенное средство получения имен «a» и «b», задействованных в выражении. Предчувствие не обмануло, небольшое чтение help и документации привело меня к парсеру AST, в котором было все необходимое, и следующему коду:
import ast
def parseSource(src):
def parseFunc(expr, names):
m = ast.parse(expr)
# Получим список уникальных задействованных имен
varList = list(set([ x.id for x in ast.walk(m) if type(x) == ast.Name]))
# Найдем их позиции в грамматике
indexes = [ names.index(v) for v in varList ]
lam = 'lambda %s: %s' % (','.join(varList), expr)
return (indexes, eval(lam), lam)
Все правила переписал на выражения Python. Кстати, если правило записано неправильно, то оно не компилируется еще при чтении словаря шаблонов и программа вылетает по exception, так что если словарь прочитался, то правила выполнимы.
И все получилось:
+ Младшие братья Миша и Вова ходят в детский сад ['ADJF', 'NOUN'] ['Младшие', 'братья']Весь текст и его разбор
Фразы в основном взяты из Букваря. Ведь если начинать машину читать, то лучше пользоваться проверенным способом.
Словарь шаблонов
Разбор
# Текст, который будем парсить
text = '''
Мама мыла раму
Вася разбил окно
Лара сама мыла раму
Рано ушла наша Шура
Мама мыла пластиковые окна
Наша семья
У нас большая семья
Папа и брат Илья работают на заводе
Мама ведет хозяйство
Сестра Татьяна - учительница
Я учусь в школе
Младшие братья Миша и Вова ходят в детский сад
Эти типы стали есть на нашем складе
'''
Словарь шаблонов
# Описания шаблонов
source = '''
# Вася ест кашу
# сущ гл сущ
# что/кто делает с_чем-то
NOUN,nomn VERB NOUN,accs
# определения внутренних имен
-a- -b- -c-
= a.tag.number == b.tag.number
# Именованная сущность
:SNOUN
# Красивый цветок
ADJF NOUN
-a- -b-
# Правила сооответствия шаблону
= a.tag.case == b.tag.case
= a.tag.number == b.tag.number
= a.tag.gender is None or a.tag.gender == b.tag.gender
# Птица сидит на крыше
# сущ гл предлог сущ
NOUN,nomn VERB PREP NOUN,loct
-a- -b- -c- -d-
= a.tag.number == b.tag.number
# стали есть
VERB INFN
# хомяк Коля
NOUN Name
-a- -b-
= a.tag.case == b.tag.case
= a.tag.number == b.tag.number
# серп и молот
NOUN CONJ NOUN
-a- -c- -b-
= a.tag.case == b.tag.case
#
NOUN PNCT NOUN
-a- -c- -b-
= a.tag.case == b.tag.case
= c.normal_form == '-'
'''
Разбор
+ Мама мыла раму ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Мама', 'мыла', 'раму']
+ Вася разбил окно ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Вася', 'разбил', 'окно']
+ Лара сама мыла раму ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Лара', 'мыла', 'раму']
+ Рано ушла наша Шура ['ADJF', 'NOUN'] ['наша', 'Шура']
+ Мама мыла пластиковые окна ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Мама', 'мыла', 'окна']
+ Мама мыла пластиковые окна ['ADJF', 'NOUN'] ['пластиковые', 'окна']
+ Наша семья ['ADJF', 'NOUN'] ['Наша', 'семья']
+ У нас большая семья ['ADJF', 'NOUN'] ['большая', 'семья']
+ Папа и брат Илья работают на заводе ['NOUN', 'Name'] ['Папа', 'Илья']
+ Папа и брат Илья работают на заводе ['NOUN', 'Name'] ['и', 'Илья']
+ Папа и брат Илья работают на заводе ['NOUN', 'Name'] ['брат', 'Илья']
+ Папа и брат Илья работают на заводе ['NOUN', 'CONJ', 'NOUN'] ['Папа', 'и', 'брат']
+ Мама ведет хозяйство ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Мама', 'ведет', 'хозяйство']
+ Сестра Татьяна - учительница ['NOUN', 'Name'] ['Сестра', 'Татьяна']
+ Сестра Татьяна - учительница ['NOUN', 'PNCT', 'NOUN'] ['Сестра', '-', 'учительница']
+ Сестра Татьяна - учительница ['NOUN', 'PNCT', 'NOUN'] ['Татьяна', '-', 'учительница']
+ Я учусь в школе ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['Я', 'учусь', 'в']
+ Я учусь в школе ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['Я', 'учусь', 'в', 'школе']
+ Младшие братья Миша и Вова ходят в детский сад ['NOUN,nomn', 'VERB', 'NOUN,accs'] ['братья', 'ходят', 'в']
+ Младшие братья Миша и Вова ходят в детский сад ['ADJF', 'NOUN'] ['Младшие', 'братья']
+ Младшие братья Миша и Вова ходят в детский сад ['ADJF', 'NOUN'] ['детский', 'сад']
+ Младшие братья Миша и Вова ходят в детский сад ['NOUN', 'CONJ', 'NOUN'] ['братья', 'и', 'Вова']
+ Младшие братья Миша и Вова ходят в детский сад ['NOUN', 'CONJ', 'NOUN'] ['Миша', 'и', 'Вова']
+ Эти типы стали есть на нашем складе ['ADJF', 'NOUN'] ['Эти', 'типы']
+ Эти типы стали есть на нашем складе ['ADJF', 'NOUN'] ['нашем', 'складе']
+ Эти типы стали есть на нашем складе ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['типы', 'стали', 'на', 'складе']
+ Эти типы стали есть на нашем складе ['NOUN,nomn', 'VERB', 'PREP', 'NOUN,loct'] ['стали', 'есть', 'на', 'складе']
+ Эти типы стали есть на нашем складе ['VERB', 'INFN'] ['стали', 'есть']
Что дальше?
1. Как видите, я остановился на поиске отдельных шаблонов, но не стал результат разбора объединять в дерево синтаксического разбора. Тому есть несколько причин, и одна из них — я не уверен, что стоит это делать. Каждый вариант разбора дает нам маленькую крупицу информации. Объединяя их в дерево, мы пытаемся втиснуть знания в искусственную структуру. Ребенок может читать и понимать предложения, не зная, какое слово в нем подлежащее, а какое — сказуемое. Он берет крупицы и создает в своей голове картину (описываемого) мира. Зачем же нам требовать от машины большего?
2. Очевидно не хватает правила, насколько одно слово может быть удалено в тексте от другого. Так «Папа» стал «Ильей», хотя между ними стоят слова «и брат».
3. Так же очевидно, что нужно сортировать результаты между собой и отбрасывать маловероятные. Определение релевантности — вопрос открытый, как минимум можно измерять удаленность слов друг от друга.
4. В правилах, помимо остальных частей речи, не хватает знаков пунктуации. Можно ввести константные литералы «NOUN '-' NOUN», а можно, как выше в примере с учительницей, проверять знак в правиле.
5. Pymorphy2 умеет предполагать принадлежность слов к частям речи, поэтому возможны даже такие варианты:
>>> parseText(patterns, 'бятые пуськи')
+ бятые пуськи ['ADJF', 'NOUN'] ['бятые', 'пуськи']
+ бятые пуськи ['NOUN', 'Name'] ['бятые', 'пуськи']
Однако здесь пришлось оригинальные слова Петрушевской поменять местами, т.к. нет шаблона с обратным порядком слов. Не то, чтобы это проблема, шаблон ввести недолго, но перестановки слов в русском языке случаются часто и всех их шаблонами не покрыть. Поэтому имеет смысл ввести в описания шаблонов какие-то модификаторы, допускающие перестановку.
Код лежит на GitHub.
