Очень коротко покажу, как настроить PG для логирования планов выполнения запросов и как потом, не искать по логам всё, что медленно исполнялось
Для автоматического логирования планов выполнения существует модуль auto_explain
Сделать это можно двумя путями:
Ну всё, можно тестить
А вот запрос, которым будем отлаживать логи:
Го в логи, там план:

Собственно хорошо, только нюанс — залогировался запрос 4 раза, а план — трижды, почему так — Parallel Seq Scan, а именно — запрос начал обрабатываться в 2 потока (Workers Planned: 2) и после собрался в общий результат (новый шаг в плане выполнения PG10 — Gather). Так и получается ровно 3 плана, на каждый запрос )
Итак, собственно вот, видим «на лету», что у нас есть что-то нехорошее — Sec Scan тысяч строк
Уверен поможет индекс:
Всё, модуль автоэксплейна ничего в логи не пишет:
Просматривать логи глазками неудобно, потому для поиска подобных запросов по логам есть утилита — pgbadger. Она группирует и агрегирует запросы в простенький html-отчёт. И будет он настолько подробным, насколько подробны ваши логи
Установка:
Генерация отчёта на основании логов:
И подобная красота получается:
В общем не буду рассказывать обо всех возможностях pgbadger, ибо и сам их не знаю, а документация у него очень хорошая, тем более есть "живой отчёт", который нагляднее покажет всё.
И коротко, как у нас:
У меня нет postgres на локальной тачке, потому сначала установлю
Ubuntu 18
> sudo apt install postgresql-10
Success. You can now start the database server using:
/usr/lib/postgresql/10/bin/pg_ctl -D /var/lib/postgresql/10/main -l logfile start
Ver Cluster Port Status Owner Data directory Log file
10 main 5432 down postgres /var/lib/postgresql/10/main /var/log/postgresql/postgresql-10-main.log
update-alternatives: using /usr/share/postgresql/10/man/man1/postmaster.1.gz to provide /usr/share/man/man1/postmaster.1.gz (postmaster.1.gz) in auto mode
Processing triggers for ureadahead (0.100.0-20) ...
Processing triggers for systemd (237-3ubuntu10) ...
> sudo -u postgres psql postgres
psql (10.3 (Ubuntu 10.3-1))
Type "help" for help.
postgres=# \password postgres
Enter new password: 1
Enter it again: 1
postgres=# create DATABASE test;
> sudo -u postgres psql test
test=# show config_file;
config_file
-----------------------------------------
/etc/postgresql/10/main/postgresql.conf
(1 row)auto_explain
Для автоматического логирования планов выполнения существует модуль auto_explain
Модуль auto_explain предоставляет возможность автоматического протоколирования планов выполнения медленных операторов, что позволяет обойтись без выполнения EXPLAIN вручную. Это особенно полезно для выявления неоптимизированных запросов в больших приложениях.Т.е. в Postgres возможно узнать план запроса на момент его исполнения
Сделать это можно двумя путями:
- Включив модуль для запроса:
Это полезно, если попрофилировать нужно конкретный запросload 'auto_explain'; SET auto_explain.log_min_duration = 10; SET auto_explain.log_analyze = true; select count(*) from somet where number < 1000 - Включить модуль на все запросы на сервере

попутно подправлю логирование
Не забудь применить конфиги
test=# SELECT pg_reload_conf(); pg_reload_conf ---------------- t (1 row)


Ну всё, можно тестить
Генерация тестовых данных
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
create table somet(
id uuid PRIMARY key,
number INTEGER,
text text
);
insert into somet
select uuid_generate_v1(), round(random() * 1000000), round(random() * 1000000)::text from generate_series(1,10000000)А вот запрос, которым будем отлаживать логи:
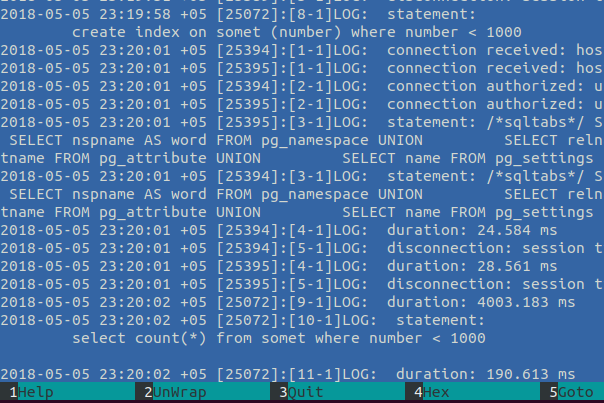
select count(*) from somet where number < 1000Го в логи, там план:
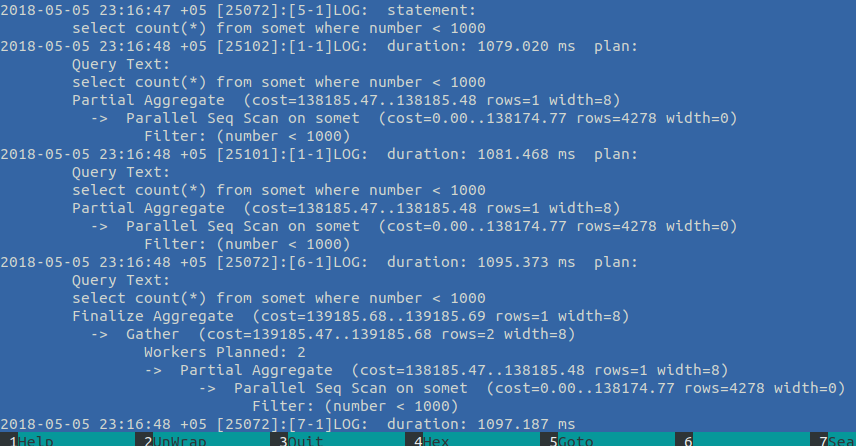
Собственно хорошо, только нюанс — залогировался запрос 4 раза, а план — трижды, почему так — Parallel Seq Scan, а именно — запрос начал обрабатываться в 2 потока (Workers Planned: 2) и после собрался в общий результат (новый шаг в плане выполнения PG10 — Gather). Так и получается ровно 3 плана, на каждый запрос )
Итак, собственно вот, видим «на лету», что у нас есть что-то нехорошее — Sec Scan тысяч строк
Уверен поможет индекс:
create index on somet (number) where number < 1000Всё, модуль автоэксплейна ничего в логи не пишет:

pgBadger
Просматривать логи глазками неудобно, потому для поиска подобных запросов по логам есть утилита — pgbadger. Она группирует и агрегирует запросы в простенький html-отчёт. И будет он настолько подробным, насколько подробны ваши логи
Показывать буду на пг 9.6, т.к. лог 10-ки не так демонстративен

Установка:
> sudo apt install pgbadgerГенерация отчёта на основании логов:
> pgbadger -j 4 -p '%t [%p]:[%l-1]' /var/log/postgresql/postgresql-9.6-main.log -o bad.html
[========================>] Parsed 43578 bytes of 43578 (100.00%), queries: 115, events: 1
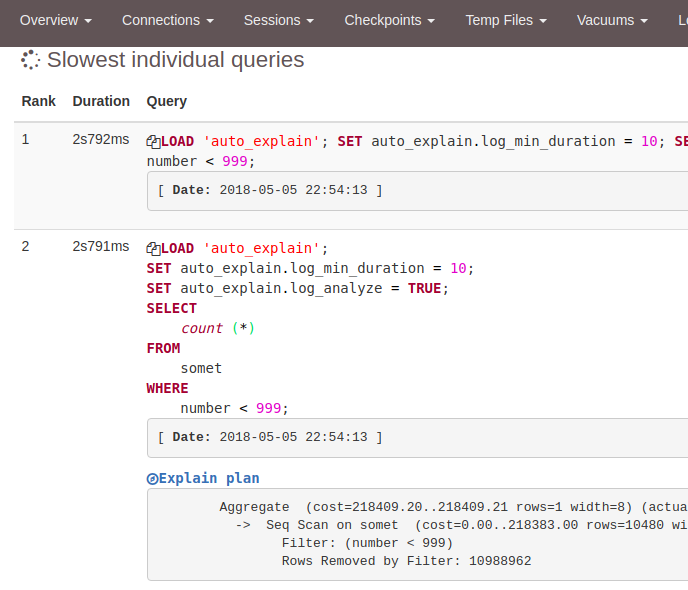
LOG: Ok, generating html report...И подобная красота получается:

В общем не буду рассказывать обо всех возможностях pgbadger, ибо и сам их не знаю, а документация у него очень хорошая, тем более есть "живой отчёт", который нагляднее покажет всё.
И коротко, как у нас:
- auto_explain в проде отключен
- К логам постгрес обращаемся очень редко, но pgBadger использовали
- Для real time мониторинга используем вовсе okmeter, отлично себя показал, но лучше логов, порой, ничего нет )
