Comments 92
А можете такими же словами объяснить backpropagation? :)
UFO just landed and posted this here
Градиентный спуск классически рассказывают на аналогии шарика, скатывающегося с горы к точке минимума. В рамках этой аналогии можно и learning rate раскрыть, и momentum.
В начале мне казалось, что объяснить НС тоже — нетривиально. Но нашлись аналогии. Как видите я остановился подойдя вплотную к backpropagation. Толи вдохновение кончилось, толи это действительно неочевидно.
UFO just landed and posted this here
Интересная статья, простые и понятные аналогии. Хочу дополнить, что очень сильно упрощает понимание компьютерных нейронные сетей, как это ни банально, понимание работы человеческого нейрона. Даже не углубляясь в тонкости физиологии.
Вдогонку пару своих вопросов, которые всегда хотелось задать программистам нейронных сетей:
Есть ли в компьютерных нейронных сетях аналог «Аксонного холмика»? Это небольшая область, при получении сигнала на которую, нейрон сразу же переходит в стадию возбуждения, при том, что этого сигнала пришедшего на любой другой участок мембраны – заведомо недостаточно для возбуждения.
Есть ли в КНС аналоги такой физиологии: аксон или раздваивается, или просто заворачивается на нейрон обратно и дополнительно возбуждает нейрон, или наоборот – тормозит его?
Вдогонку пару своих вопросов, которые всегда хотелось задать программистам нейронных сетей:
Есть ли в компьютерных нейронных сетях аналог «Аксонного холмика»? Это небольшая область, при получении сигнала на которую, нейрон сразу же переходит в стадию возбуждения, при том, что этого сигнала пришедшего на любой другой участок мембраны – заведомо недостаточно для возбуждения.
Есть ли в КНС аналоги такой физиологии: аксон или раздваивается, или просто заворачивается на нейрон обратно и дополнительно возбуждает нейрон, или наоборот – тормозит его?
Есть ли в компьютерных нейронных сетях аналог «Аксонного холмика»?Если один из весов значительно больше остальных, так и будет происходить. Но такая ситуация вообще нежелательна, так что в процессе генерализации такие коэффициенты давят.
аксон или раздваивается, или просто заворачивается на нейрон обратно и дополнительно возбуждает нейрон, или наоборот – тормозит егоЕсть различного вида рекуррентные сети, где сигнал с выхода действительно подаётся на вход (в рамках нейрона, слоя или целой сети). Они не столь удобны по очевидной причине: выход сети зависит не только от текущих входных данных, но и от предыдущих состояний, т.е. оценить качество работы такой сети не всегда просто.
Интересно! Жаль, что даже такие простые механизмы реальных нейронов вызывают сложности и от них стараются избавляться. Я думал, что все намного лучше…
Это как алфавит. В компьютерах могли использоваться троичные и другие н-ричные системы, но выбрали бинарную — ибо проще в реализации, а следовательно лучше масштабируется. Аналогичную мы видим сейчас на рынке процессоров, где Интелы, считающие за один такт очень много всего, хорошенько теснятся АРМ процессорами, такт которых — это некоторая элементарная операция. Тут тоже самое — легче влепить 10 или более примитивных нейронов, для описания одного нейрона мозга.
Мммм… Исходя из этого описания машинных нейронов, я не вижу простой возможности реализовать свойства, которые я перечислил, может быть потому, что я совсем не силен в компьютерных нейросетях
Прошу прощения, я не сразу понял задачу с «аксонным хомяком». Sadler прав. Это решается большим весом на входе от необходимого нейрона. Проблема лишь в том, что простые алгоритмы обучения не очень любят такую ситуацию. Если же использовать что-то более серьёзное — то без проблем.
Спасибо за отличную статью! Теперь я думаю, что понимаю основы искусственных нейросетей (наверняка на самом деле все гораздо глубже :) ).
Я правильно понимаю, что компьютерные нейроны строятся на фундаменте «транзисторной» логики? То есть, грубо говоря, алгоритм работы нейрона запрограммирован с помощью стандартных «если-то-иначе» на каком-нибудь С++?
Почти так, но, т.к. нейронов достаточно много, удобнее оперировать не отдельными их характеристикам, а матрицами коэффициентов. Кроме прочего, это позволяет легко переложить задачу на GPU. Стандартом в отрасли является Python, я сам предпочитаю matlab. Для C++ тоже есть фреймворки, и иногда достаточно быстрые, но лично мне хватает проблем с самим алгоритмом, не хочу устраивать себе дополнительные.
На таком фундаменте строятся любые нейроны.
гайд по поиску «своей второй половинки» с помощью нейронных сетей)
P.S.
спасибо за статью)
P.S.
спасибо за статью)
Было бы здорово иметь онлайн-конструктор нейронных сетей для начинающих. Чтобы как ваши картинки, но их можно было бы перетаскивать и соединять связями. Давая веса, выбирая типы нейронов, и так далее. Всегда было легче учиться на интерактивных примерах. Такое уже есть, или, может кто-то, кто в теме, может написать?
P.S. Спасибо за отличную статью! Подписываюсь на все следующие.
P.S. Спасибо за отличную статью! Подписываюсь на все следующие.
UFO just landed and posted this here
Есть современная браузерная демка от гугла — playground.tensorflow.org
Не совсем понятно, а почему на geektimes? Почему не хабр?
Науч-поп без формул. В процессе написания я понял, что многим интересна эта тематика так же как и астрономия, но её незаслуженно побаиваются, так как не могут увидеть своими глазами, пощупать.
А можете ли объяснить мат.решение след.задачи именнуемой «банерокрутилкой»?
Задача: Имеется N графических PNG-файлов(банеров). Системе нужно прокрутить их в псевдо-рандомном порядке. За одну прокрутку N банеров система показывает каждый банер не более одного раза. Вторая часть звучит так: Сделайте настройку процесса прокрутки так, чтоб при следующем показе банеров порядок их отображения был уже другой.
Пока есть решение в виде куска кода в песочнице: https://habrahabr.ru/sandbox/61205/. Но мне кажется такое должно решаться с помощью модификации LFSR. Может ошибаюсь
З.Ы.: Теги ссылки можно использовать только тем у кого кармы достаточно, так что прошу прощения за небрежное оформление
Задача: Имеется N графических PNG-файлов(банеров). Системе нужно прокрутить их в псевдо-рандомном порядке. За одну прокрутку N банеров система показывает каждый банер не более одного раза. Вторая часть звучит так: Сделайте настройку процесса прокрутки так, чтоб при следующем показе банеров порядок их отображения был уже другой.
Пока есть решение в виде куска кода в песочнице: https://habrahabr.ru/sandbox/61205/. Но мне кажется такое должно решаться с помощью модификации LFSR. Может ошибаюсь
З.Ы.: Теги ссылки можно использовать только тем у кого кармы достаточно, так что прошу прощения за небрежное оформление
Отличная статья, спасибо!
Радует увеличение статей про нейронные сети в последнее время. Всегда была интересна эта тема.
Радует увеличение статей про нейронные сети в последнее время. Всегда была интересна эта тема.
Большое спасибо за статью! Восторг от неё напоминает таковой от изучения производных и численных методов.
У меня такой вопрос: предположим, нейросеть управляет машиной. Машина подъезжает к повороту и заключает: впереди поворот налево. Соответствующий нейрон будет крутить руль влево. Но так же справа — какой-нибудь другой возбудитель, я не знаю, бонус к нитро :) И другой нейрон будет крутить руль вправо. В итоге, машина поедет прямо, что совсем не подходит — лучше уже или туда, или сюда. Как заставить один нейрон быть «главнее» в спорных вопросах?
Интуиция подсказывает сделать нейрон, который бы принимал аксоны этих двух нейронов, и выбрасывал бы меньшее по модулю значение. Есть ли более корректное решение? Возможно, вы посоветуете мне литературу?
У меня такой вопрос: предположим, нейросеть управляет машиной. Машина подъезжает к повороту и заключает: впереди поворот налево. Соответствующий нейрон будет крутить руль влево. Но так же справа — какой-нибудь другой возбудитель, я не знаю, бонус к нитро :) И другой нейрон будет крутить руль вправо. В итоге, машина поедет прямо, что совсем не подходит — лучше уже или туда, или сюда. Как заставить один нейрон быть «главнее» в спорных вопросах?
Интуиция подсказывает сделать нейрон, который бы принимал аксоны этих двух нейронов, и выбрасывал бы меньшее по модулю значение. Есть ли более корректное решение? Возможно, вы посоветуете мне литературу?
По факту — это уже архитектура сети и зависит она только от вашего воображения.
— Можно сделать нейрон который будет давать 0.5 если прямо, 0 налево до упора и 1 до упора направо
— Можно сделать два нейрона — каждый будет тянуть в свою сторону, а машина поедет куда-то прямо (среднее).
В обоих вариантах нужно учить сеть, и вы затратите на это условно одинаковое количество времени, но во втором вы бонусом получаете меру «сомнения» сети относительно принятого решения.
Литературы не посоветую — НС, это развивающаяся в данный момент наука, следовательно самое вкусное — находится где-то в гугле.
— Можно сделать нейрон который будет давать 0.5 если прямо, 0 налево до упора и 1 до упора направо
— Можно сделать два нейрона — каждый будет тянуть в свою сторону, а машина поедет куда-то прямо (среднее).
В обоих вариантах нужно учить сеть, и вы затратите на это условно одинаковое количество времени, но во втором вы бонусом получаете меру «сомнения» сети относительно принятого решения.
Литературы не посоветую — НС, это развивающаяся в данный момент наука, следовательно самое вкусное — находится где-то в гугле.
Есть ли более корректное решение?Дискриминирующий слой вида «победитель получает всё». Также для такой задачи смотрите в сторону свёрточных сетей, для графики они куда эффективнее классических.
Хорошая статья! Написано легко и интересно! За бутылкой пива теперь будет гораздо интереснее))
PS теперь я понял как выбиратю дам :P
PS теперь я понял как выбиратю дам :P
Отличная статья!
Очень показателен (в плане «нейрон как простейший классификатор») рисунок с 2D координатами и «зоной влюблённости» и «обычной зоной», ну и градиентом (нелинейный сумматор в нейроне).
А можно как-то показать на декартовых координатах принятие решения многонейронной/многослойной сетью?
Я понимаю, что пространство получится большой размерности, но… может как-то на проекциях?
Это бы сильно облегчило понимание и «демистифицировало» нейронную сеть :)
Хорошо бы ещё написать про обратное распространение ошибки (backpropagation). Мне понравилась аналогия в комментариях с иерархией когда начальник говорит подчинённому, а тот своему подчинённому и т.д.
Очень показателен (в плане «нейрон как простейший классификатор») рисунок с 2D координатами и «зоной влюблённости» и «обычной зоной», ну и градиентом (нелинейный сумматор в нейроне).
А можно как-то показать на декартовых координатах принятие решения многонейронной/многослойной сетью?
Я понимаю, что пространство получится большой размерности, но… может как-то на проекциях?
Это бы сильно облегчило понимание и «демистифицировало» нейронную сеть :)
Хорошо бы ещё написать про обратное распространение ошибки (backpropagation). Мне понравилась аналогия в комментариях с иерархией когда начальник говорит подчинённому, а тот своему подчинённому и т.д.
Спасибо!
Я как раз думаю об этом. Можно остаться и в двухмерной плоскости — если входных суждений 2.
Если же на скрытом слое их много, то на этой плоскости можно рисовать двухмерные фигурки при классификации. И красить их в разные цвета, в зависимости от показаний выходных нейронов.
Я как раз думаю об этом. Можно остаться и в двухмерной плоскости — если входных суждений 2.
Если же на скрытом слое их много, то на этой плоскости можно рисовать двухмерные фигурки при классификации. И красить их в разные цвета, в зависимости от показаний выходных нейронов.
А можно картинку с двумерными фигурками на плоскости и их связью с входными и (особенно) скрытыми слоями?
Нигде такой картинки не нашёл — везде попадаются максимум примеры с 1 нейроном, который линейно делит плоскость и всё.
Если я правильно понял, то если у N входных нейронов по 2 входа (X и Y) у каждого, то они рассекают плоскость N прямыми и таким образом классифицируют?
Или дополнительные слои могут дать и нелинейную классификацию?
В общем очень-очень жду картинку! :)
P.S. Как Вам можно написать сообщение? я новичёк на GT и не нашёл тут как писать личные сообщения (не в комментариях).
Нигде такой картинки не нашёл — везде попадаются максимум примеры с 1 нейроном, который линейно делит плоскость и всё.
Если я правильно понял, то если у N входных нейронов по 2 входа (X и Y) у каждого, то они рассекают плоскость N прямыми и таким образом классифицируют?
Или дополнительные слои могут дать и нелинейную классификацию?
В общем очень-очень жду картинку! :)
P.S. Как Вам можно написать сообщение? я новичёк на GT и не нашёл тут как писать личные сообщения (не в комментариях).
Берём сеть 2-2-1, (2 входа, 2 скрытых, 1 выход). Скрытые нейроны и выход — делаем «максималистами». Тоесть — дискретными. Если выходной нейрон будет реализовывать логическое «И» — тогда распознаваемая им область будет пересечением областей нейронов скрытого слоя. От сюда можно сделать свой Paint.exe с блекджеком итд :)
П.С. Заходите в мой профиль и нажимаете на конвертик сверху-справа, сразу после рейтинга.
П.С. Заходите в мой профиль и нажимаете на конвертик сверху-справа, сразу после рейтинга.
Лучше представлять это графически.
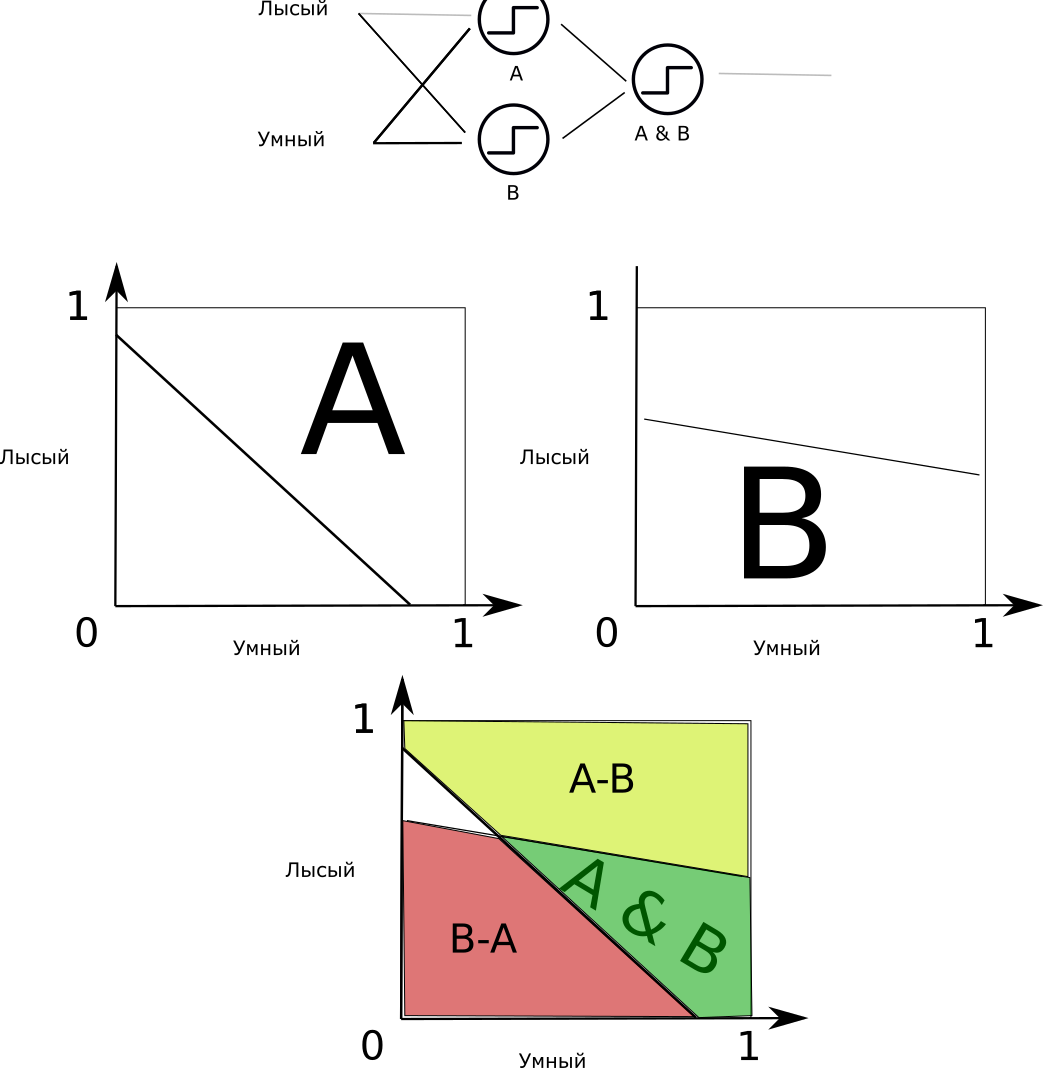
Два нейрона на скрытом слое — каждый рисует сою линию на входной плоскости.
Мы же видим их взаимодействие. Добавление ещё одного нейрона на скрытом слое добавит ещё одну линию

Два нейрона на скрытом слое — каждый рисует сою линию на входной плоскости.
Мы же видим их взаимодействие. Добавление ещё одного нейрона на скрытом слое добавит ещё одну линию
Снимаю шляпу — вы мастер доносить информацию! Это лучший рассказ о нейронных сетях, который я читал. Спасибо.
Здорово! Давайте также про адаптивно-резонансную теорию!
Статья просто супер! Очень хотелось бы увидеть еще продолжение!
Благодарю.
Тут встаёт вопрос — верно ли я понял ЦА. Разделение на хабр и ГТ, смущает и не понятно куда писать и с каким уровнем сложности. Стоит ли писать продолжение в ГТ или перейти в Хабр?
Тут встаёт вопрос — верно ли я понял ЦА. Разделение на хабр и ГТ, смущает и не понятно куда писать и с каким уровнем сложности. Стоит ли писать продолжение в ГТ или перейти в Хабр?
Насколько я понял — основные понятия, база еще не вся описана. Поэтому уровень сложности для следующих статьей пока что можно оставить на этом же уровне.
Главное добавьте ссылку на следующие статьи сюда. Буду заходить проверять периодически.
А вообще, такие статьи мотивируют на дальнейшее изучение. Но все-таки основу хотелось бы прочитать от Вас.
Главное добавьте ссылку на следующие статьи сюда. Буду заходить проверять периодически.
А вообще, такие статьи мотивируют на дальнейшее изучение. Но все-таки основу хотелось бы прочитать от Вас.
UFO just landed and posted this here
1) Если нужен просто порог — то вполне вероятно можно обойтись обычной линейной регрессией (исходных данных недостаточно чтобы понять актуальность этого).
Ежели вы хотите делать через НС — то обучать её относительно не долго. (опять таки неизвестен масштаб проблемы). Это может быть час или день, но не год.
2) Да, именно так. Мы обучили её разок — а потом используем просто как функцию с n входов, m выходов. Даже без GPU сетки разумных масштабов работают быстро.
Ежели вы хотите делать через НС — то обучать её относительно не долго. (опять таки неизвестен масштаб проблемы). Это может быть час или день, но не год.
2) Да, именно так. Мы обучили её разок — а потом используем просто как функцию с n входов, m выходов. Даже без GPU сетки разумных масштабов работают быстро.
Ай да Юрий, ай да нейро-сын))
Спасибо, очень наглядно, я до этого не въезжал в тренировку. А как выставлять первичные значения порогов и весом?
PS Книжка-раскаска «ТФКП для самых маленьких» стала будто на шаг ближе :)
PS Книжка-раскаска «ТФКП для самых маленьких» стала будто на шаг ближе :)
вот тут неплохо описано как лучше всего инициализировать стартовые значения для обучения методом обратного распространения ошибки. Если вкратце, то веса и пороги берутся случайным образом из интервала (-0.5, 0.5), при этом желательно избегать близких к нулю значений.
В большинстве других методов обучения — примерно так же.
П.С. Как было бы круто если кто-то сделал бы это (*подмигивает). ТФКП так и остался мраком для меня с институтских времён…
В большинстве других методов обучения — примерно так же.
П.С. Как было бы круто если кто-то сделал бы это (*подмигивает). ТФКП так и остался мраком для меня с институтских времён…
Спасибо. Ещё такой вопрос: а как выбрать, какими днными кормить нейросеть, сырыми или препроцессироваными?
Какое-то время назад я решал вопрос, расположены ли митохондрии в В-лимфоцитах в норме и при Б-ХЛЛ одинаково, или паттерн всё-таки разный. Я получил трехмерные фотки (XYZ) для клеток, сегментировал их и посчитал сет инвариантов к шкалированию/повороту/сдвигу по Jan Flusser, в итоге каждый снимок был описан сотней значений. Эти наборы значений я долго крутил методом главных компонент, так ничего и не понял. Вот мне и интересно, как распознаются изображения, чтобы понять, по какому признаку они различны/сходны, и что лучше подавать, исходники, постропроцессированные или выход детерменированного классификатора.
PS Ну, мангу по диффурам и квантмеху уже нарисовали и даже частично перевели. I want to believe :) ТФКП для средней школы описывал Арнольд, но он знатный тролль, и в какой-то момент я логику потерял. Например, я так и не понял, при чём там квартернионы.
Какое-то время назад я решал вопрос, расположены ли митохондрии в В-лимфоцитах в норме и при Б-ХЛЛ одинаково, или паттерн всё-таки разный. Я получил трехмерные фотки (XYZ) для клеток, сегментировал их и посчитал сет инвариантов к шкалированию/повороту/сдвигу по Jan Flusser, в итоге каждый снимок был описан сотней значений. Эти наборы значений я долго крутил методом главных компонент, так ничего и не понял. Вот мне и интересно, как распознаются изображения, чтобы понять, по какому признаку они различны/сходны, и что лучше подавать, исходники, постропроцессированные или выход детерменированного классификатора.
PS Ну, мангу по диффурам и квантмеху уже нарисовали и даже частично перевели. I want to believe :) ТФКП для средней школы описывал Арнольд, но он знатный тролль, и в какой-то момент я логику потерял. Например, я так и не понял, при чём там квартернионы.
О как! А я всегда при этом словосочетании представлял себе такую колбу или чашку петри, в которой выращивают нейронную ткань, подключенную к электродам и уже с этим киборгом химичат. :))))
Статья прекрасна, продолжай в том же духе. Прям восторг вызвал :)
В тему, периодические новости с переднего края этой области публикует Анатолий Левенчук здесь: http://www.livejournal.com/search/?journal=ailev&q=deep+learning
Огромное спасибо за статью, ничего лучше по этой теме я не читал!
Одно осталось не понятно, в рамках приведенных аналогий. Почему факторов всегда два (или больше)? Почему влюбленность не может зависеть только от харизмы? Почему не может быть нейрона с одним синапсом?
Одно осталось не понятно, в рамках приведенных аналогий. Почему факторов всегда два (или больше)? Почему влюбленность не может зависеть только от харизмы? Почему не может быть нейрона с одним синапсом?
Я не автор этой статьи, но занимаюсь нейросетями. Если так уж случилось, что связи лишние, их веса просто занулятся в процессе обучения и не будут влиять на результат. Условно можно считать, что их и нет вовсе. Обычно проводят какую-то предобработку данных, совсем уж лишние входы заранее устраняют, чтобы не тормозить дополнительно процесс обучения. Сети с одним входом тоже бывают, это характерно для рекуррентных сетей, где на входе, скажем, звуковая волна.
//еще немного вспомнил из физиологии нейронов
Нейрон срабатывает тогда, когда площадь распространения деполяризации на мембране, достигнет определенного размера. То есть, если пришло одновременно 4 сигнала на 4 противоположные стороны клетки, то нейрон не среагирует. А если только три сигнала, но с синапсов расположенных близко друг от друга – то нейрон возбудится, потому что вместо 4 небольших площадей локальной деполяризации, будет одна, но большего размера.
Еще фишка, что если нервный импульс прошел несколько раз по одному и тому же маршруту, то с каждым разом прохождение именно этого маршрута становится легче
Есть ли подобные механизмы в компьютерных нейросетях?
Нейрон срабатывает тогда, когда площадь распространения деполяризации на мембране, достигнет определенного размера. То есть, если пришло одновременно 4 сигнала на 4 противоположные стороны клетки, то нейрон не среагирует. А если только три сигнала, но с синапсов расположенных близко друг от друга – то нейрон возбудится, потому что вместо 4 небольших площадей локальной деполяризации, будет одна, но большего размера.
Еще фишка, что если нервный импульс прошел несколько раз по одному и тому же маршруту, то с каждым разом прохождение именно этого маршрута становится легче
Есть ли подобные механизмы в компьютерных нейросетях?
Подобного рода сети с «биологическими» нейронами просчитываются в проектах симуляции мозга. На практике эта слишком усложнённая модель не используется (то есть я практически не видел за последние лет 5 статей на эту тему). Математический нейрон следует усложнять только в том случае, если это даст преимущество при обучении и не слишком снизит производительность. Даже наоборот, идут по пути повышения уровня абстракции: те же свёрточные сети, как видно из названия, используют операцию свёртки, что, насколько я понимаю, напоминает работу зрительной коры, и тут уже даже речи нет об отдельных нейронах, имитируется работа рецептивных полей.
Разве сложность и гибкость человеческого мозга, не является его преимуществом? Компьютерные мощности не позволяют пользоваться такой гибкостью? Все упирается в железо?
Я не очень разбираюсь в нейросетях, но может есть сети, которые усложняют себя сами, повышая сложность нейронов или пользуясь изначально сложными моделями нейронов, но задействуют эти возможности постепенно? Или это пока из области фантастики?
Что касается второго примера, с облегчением прохождения сигнала, то это же часть обучения мозга. Мне кажется в нейросетях этот метод должен использоваться
Я не очень разбираюсь в нейросетях, но может есть сети, которые усложняют себя сами, повышая сложность нейронов или пользуясь изначально сложными моделями нейронов, но задействуют эти возможности постепенно? Или это пока из области фантастики?
Что касается второго примера, с облегчением прохождения сигнала, то это же часть обучения мозга. Мне кажется в нейросетях этот метод должен использоваться
Энергоэффективность и степень параллелизма мозга являются его преимуществом. Наши машины всё ещё в достаточной степени последовательны, даже с переходом на GPU, которые увеличили число вычислительных ядер на несколько порядков. Можно повышать сложность нейронов когда угодно, но всегда надо понимать, зачем мы это делаем. Сложность ради сложности ни к чему не приведёт, разум не самозародится. С тем же успехом можно наращивать число нейронов в процессе обучения, и такие алгоритмы вполне себе есть. Я, кстати, подумаю о реализации нейросети с более сложными нейронами, поэкспериментирую ради интереса.
Процесс обучения мозга — дело тёмное, мы не используем ничего подобного. Учим чисто математическими методами типа разных модификаций градиентного спуска.
Процесс обучения мозга — дело тёмное, мы не используем ничего подобного. Учим чисто математическими методами типа разных модификаций градиентного спуска.
Ясно. Спасибо за развернутые ответы!
А что именно попробуете усложнить в нейронах?
А что именно попробуете усложнить в нейронах?
Пока на ум приходит более интересная функция активации или просто нелинейная функция нескольких коэффициентов вместо весов. Это надо кодить и смотреть, что выйдет.
Для меня началась китайская грамота :)
Посмотрите на графические функции в статье (максималист, прямолинейная и мудрец). Каждая из них, как я старался показать в статье, имеет свои незаменимые плюсы и непреодолимые минусы. Хочется же иметь одну функцию, которая, в зависимости от настроек коэффициентов может принимать вид любой из трёх. Тогда метод обучения сможет подобрать форму этой функции для каждого нейрона по необходимости. Пример: если мне нужна чёткая, буленовая логика — то функция приниммает вид ступеньки. Если нечёткое суждение — то вид «мудреца». Во всех остальных случаях — функция остаётся линейной
что если сделать что-то вроде k1*sign(x) + k2*(kx+b) * k3(exp)? тоесть тупо усреднить и взять влияние. При этом сумма k должна быть строго равна 1
Как раз когда занимался этой статьёй наткнулся на мысль: Есть три функции активации — пороговая, линейная и сигмоид. Для того что бы выродить линейную в пороговую — нужны предельные значения весов. У сигмоида свои косяки — зона насыщения находится в бесконечности и также она не вырождается в пороговую. Соответственно мы имеем перед глазами наглую провокацию для методов обучения завышать веса. Хочется заполучить функцию, которая имеет помимо весов и порогов ещё два параметра — наклон (при нуле — вырождается в пороговую) и нелинейность (при нуле выражается в прямую). Тогда три функции активации будут лишь частным случаем этой функции.
Вы ничего не слышали о подобных функциях?
Вы ничего не слышали о подобных функциях?
Если говорить о статических нейронах ( не рекурентных), то тут вопрос — имеет ли смысл их усложнять или лучше оставить их максимально простыми, а сложности делать их комбинацией?
Мда, если за бутылкой пива Вы начинаете разговаривать о нейронных сетях, то ничего удивительного, что люди под стол прячутся и у них глаза дёргаются</сарказм>
А вообще, статья интересная, спасибо.
P.S. Под пиво лучше мысли Шопенгауэра обсуждать.
А вообще, статья интересная, спасибо.
P.S. Под пиво лучше мысли Шопенгауэра обсуждать.
//Допустим, я знаю о девушке две вещи — симпатична она мне или нет, а также, есть ли о чём мне с ней поговорить. Если есть, то будем считать //
//это единицей, если нет, то — нулём. Аналогичный принцип возьмем и для внешности. Вопрос: “В какую девушку я влюблюсь и почему?”
Всё бы хорошо на словах… Да вот, на деле машина-то НЕ ЗНАЕТ такие вещи, как девушка, симпатия, любовь и так далее. Машина распознаёт только «0» и «1».
Значит, кто-то должен закодировать, что «девушка» — это, например, «00110011», а «симпатия „11001100“ и присваивать этим значениям нули и единицы.
Потом, нужно закодировать индивидуальные характеристики понятий „девушка“, „любовь“ и такое прочее. Исчисляется уже Мегабайтами.В конце концов надо будет добиться, чтобы остановился цикл „одни дефиниции через другие дефиниции“. Это уже пахнет Эксабайтами.
Ситуацию усугубляет и тот фактор, что человек учится ДВУКАНАЛЬНО!!! По одному каналу, например, визуальному или тактильному получает информацию от органов зрения или осязания, а по другому — аудиокуналу — с помощью органов слуха присваивает этой информации маркёр-идентификатор.
Никакая ИНС не может этого делать. Почему? И не только потому, что нейроны мозга этого не делают, а потому, что „нейронщики“, с одной стороны, копируют сами зная что, и, с другой стороны, ИНС импотентны воспроизвести процедуры сознания.
ИНС — контрпродуктивный путь.
//это единицей, если нет, то — нулём. Аналогичный принцип возьмем и для внешности. Вопрос: “В какую девушку я влюблюсь и почему?”
Всё бы хорошо на словах… Да вот, на деле машина-то НЕ ЗНАЕТ такие вещи, как девушка, симпатия, любовь и так далее. Машина распознаёт только «0» и «1».
Значит, кто-то должен закодировать, что «девушка» — это, например, «00110011», а «симпатия „11001100“ и присваивать этим значениям нули и единицы.
Потом, нужно закодировать индивидуальные характеристики понятий „девушка“, „любовь“ и такое прочее. Исчисляется уже Мегабайтами.В конце концов надо будет добиться, чтобы остановился цикл „одни дефиниции через другие дефиниции“. Это уже пахнет Эксабайтами.
Ситуацию усугубляет и тот фактор, что человек учится ДВУКАНАЛЬНО!!! По одному каналу, например, визуальному или тактильному получает информацию от органов зрения или осязания, а по другому — аудиокуналу — с помощью органов слуха присваивает этой информации маркёр-идентификатор.
Никакая ИНС не может этого делать. Почему? И не только потому, что нейроны мозга этого не делают, а потому, что „нейронщики“, с одной стороны, копируют сами зная что, и, с другой стороны, ИНС импотентны воспроизвести процедуры сознания.
ИНС — контрпродуктивный путь.
Я вам представил основы работы примитивной нейронной сети «персептрон» в утрированных условиях «подготовленных данных», разбавленных юмором. Такая сеть свою задачу классификации решает.
Если бы мы с вами строили рекурентные сети, начиная со зрительных и аккустических, то для того чтобы дойти до сети женидьбы потребовалось бы 100 страниц текста. И конечно там очень многое ещё не понятно.
Если бы мы с вами строили рекурентные сети, начиная со зрительных и аккустических, то для того чтобы дойти до сети женидьбы потребовалось бы 100 страниц текста. И конечно там очень многое ещё не понятно.
Не читал, но осуждаю. Вы крайне неудачно выбрали пример, на котором объясняете тему. Тема межполовых отношений слишком эмоционально окрашена и холиварна, чтобы её можно было использовать как пример для объяснения чего-то ещё. Люди вместо того, чтобы думать над предметом объяснения, будут думать наподобие «ну вот, все люди как люди, а меня девочки не любят», или «да как он смеет так обращаться с таким святым чувством, как Любовь!», или «да что он понимает в бабах» и т. п. Хуже в этом смысле была бы разве что война на донбассе. Вот и ребе Юдковский про это же пишет: http://lesswrong.ru/w/Политика_убийца_разума
Мне было очень интересно, хотя я не знаю пожалуй ничего о нейронных сетях. Спасибо, с нетерпением жду продолжения.
Статья и основной пример — отличные! Благодарю :-)
Спасибо за статью! Позвольте неумный вопрос. Со студенческой скамьи все не могу понять простую вещь в части обучения НС. Если грубо, то обучение это настройка весов коэффициентов таким образом, чтобы результат работы сети совпадал с эталоном?
То есть для обучения мы должны дать N эталонов с заранее описанными входными параметрами (богатая, красивая, умная, пр.). То есть получили формулу y = f(x1, x2, x3, ..xN).
При известных y (эталон) и x1-xN задача НС сводится к перебору коэффициентов, чтобы на большой выборке эталонов совпадение было максимальным?
Как в анекдоте: «Ну студенты пошли, три раза объяснил, ничерта не понимают. Сам понял, а они не понимают».
Буду признателен за ответ «в вашем стиле».
То есть для обучения мы должны дать N эталонов с заранее описанными входными параметрами (богатая, красивая, умная, пр.). То есть получили формулу y = f(x1, x2, x3, ..xN).
При известных y (эталон) и x1-xN задача НС сводится к перебору коэффициентов, чтобы на большой выборке эталонов совпадение было максимальным?
Как в анекдоте: «Ну студенты пошли, три раза объяснил, ничерта не понимают. Сам понял, а они не понимают».
Буду признателен за ответ «в вашем стиле».
Sign up to leave a comment.
Искусственные нейронные сети простыми словами