Решили мы попробовать на деле новую тенденцию в IT сообществе, а именно software defined storage.

Попросили у наших замечательных поставщиков полигон для тестов.
Конфигурация стенда:
Вообще сейчас Virtual SAN решений великое множество, Starwind VSAN отпала из-за значительных ограничений бесплатной версии, которые убивали все интересные фишки, VMWARE VSAN отпало из за требований к железу и высокой стоимости владения, не оптимальной для небольших региональных бюджетов, а так же из-за того, что сами тех. спецы VMWARE в кулуарах очень не советуют применять их VSAN для business-critical приложений. В результате выбрали решение от Nutanix и EMC ScaleIO.
ScaleIO это software defined virtial SAN от EMC, может работать в бесплатном режиме почти без ограничений (написано в лицензии for non-production use!) — единственный серьезный минус — это то, что в данной системе нет встроенных механизмов авто-тиринга данных или кеширования, использую SSD диски.(в отличии от конкурентов, которым SSD дает серьезное преимущество в скорости работы виртуалок). Архитектурно очень сильно напоминает hi-end enterprise систему хранения IBM XIV — даже размер блока тот же — 1МБ.
Читал в разных источниках противоречивые минимальные требования:
Однако на практике для версии 1.32 таких ограничений не встретили.
В связи с тем, что в production мы используем рассово правильный VMWARE и не любим неправославный Hyper-V, в качестве гипервизора мы выбрали для развертывания триальную версию VMWARE ESXi 6.0. Ради справедливости нужно заметить, что ScaleIO прекрасно работает на следующих гипервизорах XEN, ESXi, Hyper-V, на последнем, с помощью Windows 2012 r2 умельцы обошли отсутствие SSD кеширования массива с помощью встроенных в 2012 R2 средств, что конечно положительно сказалось на производительности системы. (в интернете есть методика)
Для начала требуется установить на все хосты гипервизор ESXi и установить appliance VCENTER для управления кластером VMWARE. Тут же нас поджидал первый казус — ESXi ни в какую не хотел видеть контроллер Adaptec 6405E, хотя он и присутствует в VMWARE HCL.
Скачиваем с сайта Adaptec драйвера (Offline-Bundles and VIB) ддя VMWARE и через VMWARE powercli с помощью вот этой тулзы готовим кастомный образ гипервизора с интегрированными драйверами — после этого всё встало отлично.
Далее развертывается виртуалка VCENTER appliance и опять же через vmware powercli регистрируются плагины ScaleIO и копируются на datastore шаблоны виртуальной машины ScaleIO в формате .ova (согласно инструкции по установке ScaleIO).
После перезагрузки всех хостов система готова к работе по установке ScaleIO.
Крайне рекомендую прочитать инструкцию по развертыванию иначе многие моменты будут непонятны:
— например нужно осознать такие вещи как protection domain и как он связан со storage pool'ами,
— какие рекомендации по созданию storage pool'ов (то, что не стоит мешать HDD и SSD, хотя это и возможно)
— понять, что такое FaultSets, хотя мы его и не использовали. Понять, что такое ZeroPadding Policy, RAM Cache policy и ее опции, Spare policy. Нюансов много
ScaleIO не поддерживает возможность использования SSD накопителей как кеша для массива данных! Это неприятная такая особенность. Пулы из SSD можно собирать, но это будет всего лишь flash-only pool — ничего более!
В качестве кешируюшего элемента рекомендуют использовать read\write cache RAID адаптера, если он оснащен батарейкой, а так же есть функция RAM CACHE, при создании protection domain, которая использует часть оперативной памяти хоста виртуализации как кеш для массива! (на 16GB RAM у нас получилось выделить 1.3GB как кеш в настройках, читайте документацию)
Также вам потребуется 2 виртуальных VLAN: management и data, потребуется выдать каждой из 4-х (в минимальной конфигурации) SVM (SVM — ScaleIO Virtual Machine) management IP и DATA IP с указанием шлюза и масок. (очень желательно подготовить план адресации заранее, чтобы не заполнять все нужные поля по 10 раз).
Всего в минимальном режиме установка создает 4 SVM на наших 3-х хостах (SVM — ScaleIO Virtual Machine), занимает 8cpu на всех (по 2 на хост: на первом хосте 2 виртуальных машины следовательно 4 vcpu), занимает 12Gb памяти на всех.
SVM на node1 — primary mdm, sds, sdc
SVM на node2 — secondary mdm, sds, sdc
SVM на node3 — tie breaker, sdc
SVM на любом узле — gateway — (централизованное обновление, мониторинг, maintenance)
mdm — Meta Data Manager — управляет таблицами размещения блоков данных по устройствам
sds — ScaleIO data server — управляет выдачей физических накопителей посредством RDM дисков в VMWARE (raw disk mapping)
sdc — ScaleIO data client — в случае VMWARE это доп. модули ядра, которые интегрируются на этапе развертывания ScaleIO и позволяют достичь бОльшей производительности, нежели когда они работают на самой виртуальной машине SVM.
Так же, очень большое преимущество иметь SDC в ядре это то, что созданные на ScaleIO тома данных презентуются в VMWARE напрямую в качестве LUNов для создания datastore, без использования дополнительного слоя виртуализации и презентования томов через механизм iSCSI.

Процесс развертывания не прошел гладко, так как у нас небыли готовы необходимые VLANы и IP адреса для SVM. После подготовки данных и повторного запуска на последнем шаге мастера установки у нас начали вылетать вот такие ошибки:
Failed: Add SDS device ScaleIO-4c1885e7 to Storage Pool hdds (ScaleIO — Timeout)
С чем это было связано сказать не могу. Посидели, подумали — нажали retry. Предыдущие ошибки пропали, однако на одном из SVM на хосте2 появились другие ошибки:
Failed: Add SDS device ScaleIO-4c1885eb to Storage Pool hdds (ScaleIO — The SDS is already attached to this MDM)
Посидели подумали… выяснили, что на одной из SVM, где находился secondary mdm, по какой-то причине при установке не создались маппинги RDM на физические диски, и соответственно не поднялась служба SDS. Таким образом один из узлов у нас не завелся.
Нажали кнопку «deploy scaleio environment» еще раз и, о чудо, хост и пустая виртуалка нашлись, как неиспользуемые, внесли еще раз данные по поводу VLANов и IP адресов, и хост завелся нормально без ошибок.
После этого интересный момент поджидал на этапе создания volume на котором будем размещать данные. Я не смог найти этот пункт в GUI: ни в GUI dashboard который ставится на windows, ни в GUI VMWARE, ни в веб-интерфейсе Gateway. много инструкций по созданию из cli — нашлось случайно на каком то блоге.
Привожу скриншот — где находится заветная кнопочка создания volume в GUI VMWARE.

Ура, нашли! Но «ура» было не долгое. Согласно скриншоту на storage pool с названием HDDs (куда я объединил все 6 дисков SAS со всех 3-х узлов) у нас total capacity limit 1.6ТB (что в общем то соответствует 6х300GB), но volume c таким объемом не создается… и непонятно какой доступен объем для пользователя. Прочитал инструкции из интернетов, как с помощью CLI посмотреть доступный объем. Зашли по SSH на один из MDM SVM — даю команду:
Что?
Пробую на втором MDM: ошибка что-то типа can't connect localhost:6611
На gateway вообще сказало что нет таких команд. Всё — ступор! Непонятно как пользоваться CLI.
Внимательно изучаем userguide по ScaleIO особенно про CLI Basics, а там в самом низу написано, что необходимо дополнительно залогироваться в CLI и дата ссылочка, как это делать, а делать это нужно вот так:
И после этого замечательно все CLI команды стали работать.
Подождите, ЧТО? доступный объем в нашем случае 544GB?! Как? Почему? Тут требуется объяснение об архитектуре хранения (см. скриншот):
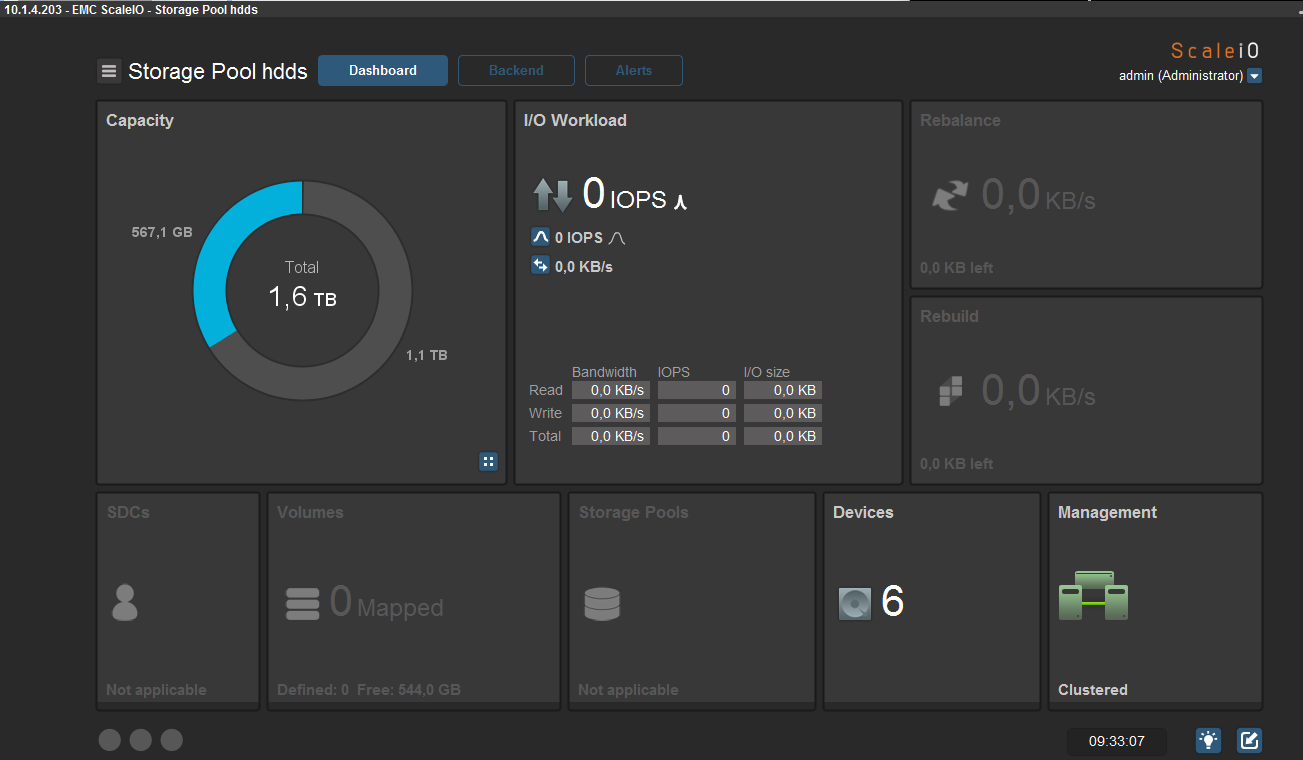
Т.е. общий raw объем storage pool'а с именем HDDs: 1.6ТБ минус 567.1 GB spare capacity = 1.1TB unused capacity. Spare Capacity определяется параметром Spare Policy в настройках. По рекомендациям из документации, для полной защиты от выхода из строя одного узла необходимо, чтобы Storage Capacity был не менее 1\N от общего объема всех физических дисков всех узлов, входящих в storage pool, где N количество узлов которые входят в пул (т.е если у нас 3 узла с дисками в этом storage pool'e, то spare capacity в нашем случае 1\3 от 1.6TB (от общего объема) соответственно 567.1 GB (580708 MB).
Итак, получаем 1.1TB неиспользуемого места в storage pool для создания volume. Однако для целей высокой доступности и надежности ScaleIO на всех физических накопителях хранит по 2 копии каждого блока данных, соответственно объем 1.1TB делим еще в 2 раза, в результате и получаем доступный объем для создания volume 544.0 GB.
При тестовой эксплуатации системы нам удалось достичь следующих показателей (скорость была 85-130МБ\сек, но нужно понимать, что это всего лишь нагрузка одной виртуалки, при расширении массива добавлением узлов с дисками думаю это всё будет пропорционально рости вверх вместе с IOPSами):

Nutanix Comminity Edition 4.5 — бесплатно для non-commercial использования
Вообще документации по Nutanix, как ни странно, довольно мало… Некоторые моменты выяснялись уже в процессе установки. Nutanix объединяет в себе и hypervisor и систему управления кластером виртуализации (аля VMWARE Vcenter) в одном «лице», а так же распределенную систему хранения данных отдаваемую по NFS с функциями high-availability.
К сожалению, версию с гипервизором ESXi мы не смогли достать. Поэтому стали тестировать версию Community Edition, а у нее много ограничений:
— максимум 4 узла
— максимум 4 диска на узел (включая SSD, поэтому максимальный объем на хост 18 TB (3 x 6 TB HDDs))
— процессор Intel c поддержкой VT-x 4 ядра минимум
— встроенные Advanced Host Controller Interface (AHCI) SATA контроллеры
— LSI контроллеры в режиме IT mode (Nutanix testing shows better performance than IR)
— минимум 16 GB памяти на хост (очень рекомендуется 32 GB или больше для дедубликации — на 16 она не включается)
— минимальный объем SSD на каждый хост 200 GB
— минимальный объем SSD на каждый хост для поддержки дедубликации 300GB (желательно больше 400,480)
Контроллер ADAPTEC 6405E SAS не определился Nutanix, соответственно использовать диски SAS мы не смогли (использовали диски SATA и SSD которые подключены к разъемам на мат. плате).
Для установки требуется носитель на каждый хост: мы не стали ставить готовый образ на локальные диски сервера — поставили на флешку по 8GB на каждый хост (минимальные требования флешка 8GB, лучше 16, туда ставится сам hypervisor KVM (Acropolis) и CVM — control virtual machine — и так на каждый хост!), всего количество виртуальных машин CVM по количеству хостов.
В нашем случае получилась такая конфигурация:
— 16 гигабайт памяти на хост
— на каждый хост 2 жестких диска HDD SATA 500GB
— на каждый хост 1 жесткий диск SSD 500GB
— для дедубликации нужно минимум 24GB памяти на хост + минимум 300GB SSD на хост, поэтому у нас она не включилась.
В случае несоблюдения минимальных требований система не устанавливается…
В Community Edition нельзя поменять гипервизор — по умолчанию ставится только KVM — это огромный минус, потому что мы привыкли к использованию VMWARE ESXi.
После установки на каждом хосте появляется служебная виртуальная машина (CVM — control virtual machine), которая занимает 2 ядра процессора и резервирует для себя 12ГБ оперативной памяти на каждом хосте — учитывыйте это при планировании.
Аосле установки на все узлы кластера создаем тома для хранения данных: при создании StorageContainer если Replication Factor 2, то свободное место дискового хранилища на 50% меньше (все блоки данных дублируются на других дисках, например у нас 3 хоста, на каждом 2 диска SATA по 500 гб, всего 6 дисков + SSD диски на каждом из хостов всего 2.88 TB общий объем из них 1.44 TB доступных пользователю для хранения).
Дисковый массив после создания доступен и отдается по NFS: например, в кластер VMWARE 5.5 он в качестве datastore подключился замечательно, соответственно storage vmotion работает тоже, правда скорость по сравнению с FC 4Gb\sec сильно проигрывает (оно и понятно при гигабитном подключении — интересно было бы погонять на 10G или infiniband).
Живая машинка на 60GB с кластера VMWARE переезжала примерно 24 минуты на хранилище Nutanix. Обратно на FC хранилище enterprise уровня она же переезжала 13 минут.
Запись iso файла c сервера windows на виртуалку vmware которая находится на хранилище нутаникс через nfs (1Gb/s) — 34MB/sec.
Нет интерактивного инструмента управления портгруппами и vswitch — всё делается из cli.
Неочевидный момент по поводу сетей для работы виртуальных машин: советую внимательно прочитать документацию. Для виртуальных машин внутри Nutanix мы использовали VLANы, который используют все наши остальные системы виртуализации для выхода в сеть. На этапе настройки виртуальных сетей просто указывается номер VLANа виртуальной сети — больше настроек нет, а в свойствах виртуальной машины настраивается соответствие виртуального сетевого адаптера номеру сети — и все, других настроек в GUI нет! Но всё работает.
Для установки Windows guests виртуальных машин необходимо подключать второй виртуальный CDROM с VirtIO драйверами (например можно взять отсюда (предварительно положить iso файл на хранилище): fedoraproject.org/wiki/Windows_Virtio_Drivers#Direct_download)
Время установки guest vm на windows 2012 R2 составило всего 7 минут от начала до полной загрузки рабочей системы, работает виртуальная машина визуально тоже быстро — очевидно, помогает SSD.
Можно ставить виртуальные машину и на тип кортроллера виртуального диска IDE (без подключения VirtIO драйверов), но это не рекомендуемая конфигурация — производительность будет значительно меньше.
При тестовом отключении по питанию одного из хостов кластера HA отработал, система не повисла, дисковые ресурсы доступны и по сети и локально, виртуальные машины, которые были на отключенном хосте перезапустились на других хостах (если памяти достаточно),
однако неприятным фактом после включения питания 3-го хоста обратно явилось то, что статус системы очень долгое время держится в Critial — не знаю, что это за собой тянет, но хорошего мало. (от 1 часа до 2-х). Например тот же кластер VMWARE после подключения хоста достаточно быстро определяет его статус и подключает обратно в кластер.
Вообще нужно заметить, что у интерфейса Prism для управления кластером Nutanix CE довольно бедный (хотя и приятный) интерфейс. Доступны только базовые настройки, но в общем случае их на первый взгляд достаточно, есть некая настраиваемая графическая аналитика, хотя конечно значительно слабее, чем в VCENTER.
Непонятным остается то, как осуществлять резервное копирование: ведь ни Symantec ни продукты Veeam не поддерживают KVM виртуализацию… очевидно, через снэпшоты, но как быть с гранулярным восстановлением данных в этом случае (пофайлово).
Визуально Nutanix был намного быстрее, что на этапе копирования образов на его систему хранения, что на этапе установки операционной системы на новую виртуалку из образа, что на этапе загрузок-перезагрузок: почти мгновенно всё). Есть желание попробовать Nutanix на более мощной конфиурации и обязательно при использовании VMWARE EXSi.
Особых данных производительности обеих систем конечно привести не могу, но зато можно почерпнуть некую информацию о «граблях» на этапе установки настройки. Если что прошу прощения — первая заметка на Хабре.
Попросили у наших замечательных поставщиков полигон для тестов.
Конфигурация стенда:
- 3 сервера SuperMicro X9SCL/X9SCM следующей конфиругации:
- процессор Intel E3-1220V2: 4 cores x 3.1 GHz
- RAM — 16 Gb
- RAID адаптер Adaptec 6405E: 2х300GB SAS 10K, 1x180GB SSD — все диски необходимо настроить в режим JBOD
- 2x500GB SATA 7.4K подключенные к разъемам на мат. плате
- 2x1GB NIC
Вообще сейчас Virtual SAN решений великое множество, Starwind VSAN отпала из-за значительных ограничений бесплатной версии, которые убивали все интересные фишки, VMWARE VSAN отпало из за требований к железу и высокой стоимости владения, не оптимальной для небольших региональных бюджетов, а так же из-за того, что сами тех. спецы VMWARE в кулуарах очень не советуют применять их VSAN для business-critical приложений. В результате выбрали решение от Nutanix и EMC ScaleIO.
ScaleIO это software defined virtial SAN от EMC, может работать в бесплатном режиме почти без ограничений (написано в лицензии for non-production use!) — единственный серьезный минус — это то, что в данной системе нет встроенных механизмов авто-тиринга данных или кеширования, использую SSD диски.(в отличии от конкурентов, которым SSD дает серьезное преимущество в скорости работы виртуалок). Архитектурно очень сильно напоминает hi-end enterprise систему хранения IBM XIV — даже размер блока тот же — 1МБ.
Читал в разных источниках противоречивые минимальные требования:
- These are the minimum system requirements for a ScaleIO 1.31 and 1.32 implementation:
- ScaleIO 1.31 and 1.32 solution is only supported on ESXi 5.5 GA.
- Three ESXi servers with 100 GB of free capacity per server
- 1 Gbps network
- Four 7,200 rpm SATA disks per node
Однако на практике для версии 1.32 таких ограничений не встретили.
В связи с тем, что в production мы используем рассово правильный VMWARE и не любим неправославный Hyper-V, в качестве гипервизора мы выбрали для развертывания триальную версию VMWARE ESXi 6.0. Ради справедливости нужно заметить, что ScaleIO прекрасно работает на следующих гипервизорах XEN, ESXi, Hyper-V, на последнем, с помощью Windows 2012 r2 умельцы обошли отсутствие SSD кеширования массива с помощью встроенных в 2012 R2 средств, что конечно положительно сказалось на производительности системы. (в интернете есть методика)
Для начала требуется установить на все хосты гипервизор ESXi и установить appliance VCENTER для управления кластером VMWARE. Тут же нас поджидал первый казус — ESXi ни в какую не хотел видеть контроллер Adaptec 6405E, хотя он и присутствует в VMWARE HCL.
Скачиваем с сайта Adaptec драйвера (Offline-Bundles and VIB) ддя VMWARE и через VMWARE powercli с помощью вот этой тулзы готовим кастомный образ гипервизора с интегрированными драйверами — после этого всё встало отлично.
Далее развертывается виртуалка VCENTER appliance и опять же через vmware powercli регистрируются плагины ScaleIO и копируются на datastore шаблоны виртуальной машины ScaleIO в формате .ova (согласно инструкции по установке ScaleIO).
После перезагрузки всех хостов система готова к работе по установке ScaleIO.
Крайне рекомендую прочитать инструкцию по развертыванию иначе многие моменты будут непонятны:
— например нужно осознать такие вещи как protection domain и как он связан со storage pool'ами,
— какие рекомендации по созданию storage pool'ов (то, что не стоит мешать HDD и SSD, хотя это и возможно)
— понять, что такое FaultSets, хотя мы его и не использовали. Понять, что такое ZeroPadding Policy, RAM Cache policy и ее опции, Spare policy. Нюансов много
ScaleIO не поддерживает возможность использования SSD накопителей как кеша для массива данных! Это неприятная такая особенность. Пулы из SSD можно собирать, но это будет всего лишь flash-only pool — ничего более!
В качестве кешируюшего элемента рекомендуют использовать read\write cache RAID адаптера, если он оснащен батарейкой, а так же есть функция RAM CACHE, при создании protection domain, которая использует часть оперативной памяти хоста виртуализации как кеш для массива! (на 16GB RAM у нас получилось выделить 1.3GB как кеш в настройках, читайте документацию)
Также вам потребуется 2 виртуальных VLAN: management и data, потребуется выдать каждой из 4-х (в минимальной конфигурации) SVM (SVM — ScaleIO Virtual Machine) management IP и DATA IP с указанием шлюза и масок. (очень желательно подготовить план адресации заранее, чтобы не заполнять все нужные поля по 10 раз).
Всего в минимальном режиме установка создает 4 SVM на наших 3-х хостах (SVM — ScaleIO Virtual Machine), занимает 8cpu на всех (по 2 на хост: на первом хосте 2 виртуальных машины следовательно 4 vcpu), занимает 12Gb памяти на всех.
SVM на node1 — primary mdm, sds, sdc
SVM на node2 — secondary mdm, sds, sdc
SVM на node3 — tie breaker, sdc
SVM на любом узле — gateway — (централизованное обновление, мониторинг, maintenance)
mdm — Meta Data Manager — управляет таблицами размещения блоков данных по устройствам
sds — ScaleIO data server — управляет выдачей физических накопителей посредством RDM дисков в VMWARE (raw disk mapping)
sdc — ScaleIO data client — в случае VMWARE это доп. модули ядра, которые интегрируются на этапе развертывания ScaleIO и позволяют достичь бОльшей производительности, нежели когда они работают на самой виртуальной машине SVM.
Так же, очень большое преимущество иметь SDC в ядре это то, что созданные на ScaleIO тома данных презентуются в VMWARE напрямую в качестве LUNов для создания datastore, без использования дополнительного слоя виртуализации и презентования томов через механизм iSCSI.

Процесс развертывания не прошел гладко, так как у нас небыли готовы необходимые VLANы и IP адреса для SVM. После подготовки данных и повторного запуска на последнем шаге мастера установки у нас начали вылетать вот такие ошибки:
Failed: Add SDS device ScaleIO-4c1885e7 to Storage Pool hdds (ScaleIO — Timeout)
С чем это было связано сказать не могу. Посидели, подумали — нажали retry. Предыдущие ошибки пропали, однако на одном из SVM на хосте2 появились другие ошибки:
Failed: Add SDS device ScaleIO-4c1885eb to Storage Pool hdds (ScaleIO — The SDS is already attached to this MDM)
Посидели подумали… выяснили, что на одной из SVM, где находился secondary mdm, по какой-то причине при установке не создались маппинги RDM на физические диски, и соответственно не поднялась служба SDS. Таким образом один из узлов у нас не завелся.
Нажали кнопку «deploy scaleio environment» еще раз и, о чудо, хост и пустая виртуалка нашлись, как неиспользуемые, внесли еще раз данные по поводу VLANов и IP адресов, и хост завелся нормально без ошибок.
После этого интересный момент поджидал на этапе создания volume на котором будем размещать данные. Я не смог найти этот пункт в GUI: ни в GUI dashboard который ставится на windows, ни в GUI VMWARE, ни в веб-интерфейсе Gateway. много инструкций по созданию из cli — нашлось случайно на каком то блоге.
Привожу скриншот — где находится заветная кнопочка создания volume в GUI VMWARE.

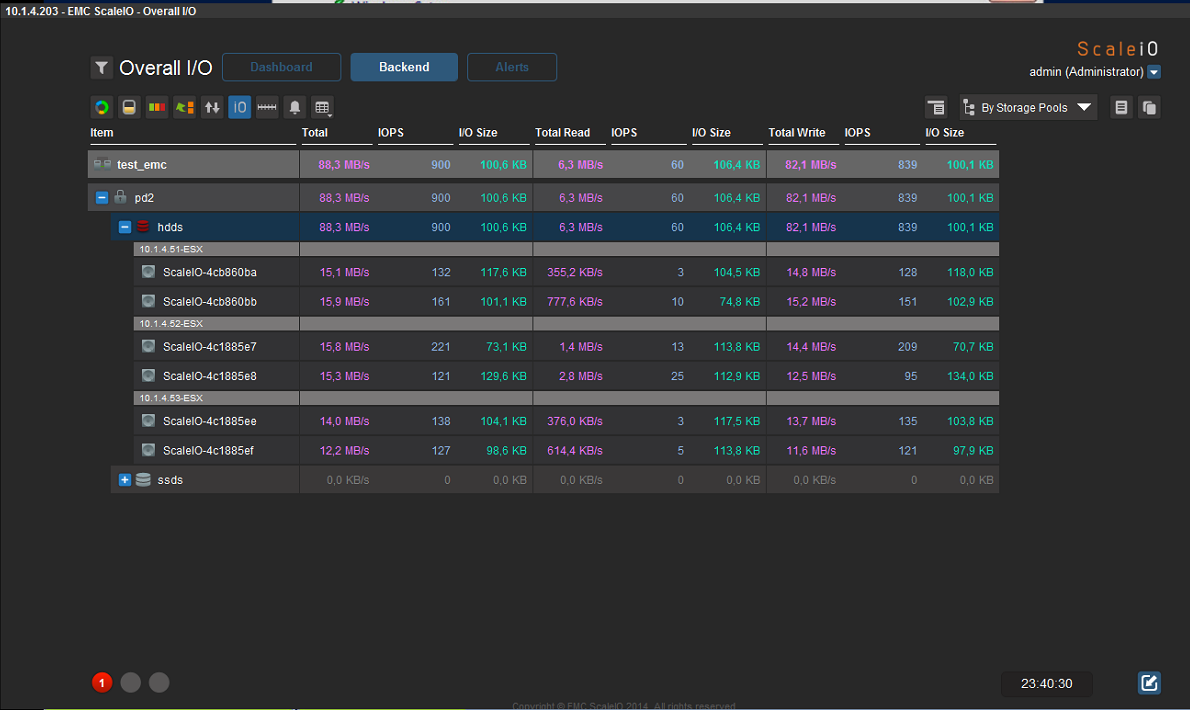
Ура, нашли! Но «ура» было не долгое. Согласно скриншоту на storage pool с названием HDDs (куда я объединил все 6 дисков SAS со всех 3-х узлов) у нас total capacity limit 1.6ТB (что в общем то соответствует 6х300GB), но volume c таким объемом не создается… и непонятно какой доступен объем для пользователя. Прочитал инструкции из интернетов, как с помощью CLI посмотреть доступный объем. Зашли по SSH на один из MDM SVM — даю команду:
ScaleIO-10-1-4-203:~ # scli --query_storage_pool --protection_domain_name pd2 --storage_pool_name hdds
Error: MDM failed command. Status: Invalid session. Please login and try again.
Что?
Пробую на втором MDM: ошибка что-то типа can't connect localhost:6611
На gateway вообще сказало что нет таких команд. Всё — ступор! Непонятно как пользоваться CLI.
Внимательно изучаем userguide по ScaleIO особенно про CLI Basics, а там в самом низу написано, что необходимо дополнительно залогироваться в CLI и дата ссылочка, как это делать, а делать это нужно вот так:
ScaleIO-10-1-4-203:~ # scli --login --username admin
Enter password:
И после этого замечательно все CLI команды стали работать.
scli --query_storage_pool --protection_domain_name pd2 --storage_pool_name hdds
Storage Pool hdds (Id: 574711eb00000000) has 0 volumes and
544.0 GB (557056 MB) available for volume allocation
Background device scanner: Disabled
Zero padding is disabled
Spare policy: 34% out of total
Uses RAM Read Cache
RAM Read Cache write handling mode is 'cached'
1.6 TB (1667 GB) total capacity
1.1 TB (1100 GB) unused capacity
567.1 GB (580708 MB) spare capacity
Подождите, ЧТО? доступный объем в нашем случае 544GB?! Как? Почему? Тут требуется объяснение об архитектуре хранения (см. скриншот):

Т.е. общий raw объем storage pool'а с именем HDDs: 1.6ТБ минус 567.1 GB spare capacity = 1.1TB unused capacity. Spare Capacity определяется параметром Spare Policy в настройках. По рекомендациям из документации, для полной защиты от выхода из строя одного узла необходимо, чтобы Storage Capacity был не менее 1\N от общего объема всех физических дисков всех узлов, входящих в storage pool, где N количество узлов которые входят в пул (т.е если у нас 3 узла с дисками в этом storage pool'e, то spare capacity в нашем случае 1\3 от 1.6TB (от общего объема) соответственно 567.1 GB (580708 MB).
Итак, получаем 1.1TB неиспользуемого места в storage pool для создания volume. Однако для целей высокой доступности и надежности ScaleIO на всех физических накопителях хранит по 2 копии каждого блока данных, соответственно объем 1.1TB делим еще в 2 раза, в результате и получаем доступный объем для создания volume 544.0 GB.
При тестовой эксплуатации системы нам удалось достичь следующих показателей (скорость была 85-130МБ\сек, но нужно понимать, что это всего лишь нагрузка одной виртуалки, при расширении массива добавлением узлов с дисками думаю это всё будет пропорционально рости вверх вместе с IOPSами):
Nutanix Comminity Edition 4.5 — бесплатно для non-commercial использования
Вообще документации по Nutanix, как ни странно, довольно мало… Некоторые моменты выяснялись уже в процессе установки. Nutanix объединяет в себе и hypervisor и систему управления кластером виртуализации (аля VMWARE Vcenter) в одном «лице», а так же распределенную систему хранения данных отдаваемую по NFS с функциями high-availability.
К сожалению, версию с гипервизором ESXi мы не смогли достать. Поэтому стали тестировать версию Community Edition, а у нее много ограничений:
— максимум 4 узла
— максимум 4 диска на узел (включая SSD, поэтому максимальный объем на хост 18 TB (3 x 6 TB HDDs))
— процессор Intel c поддержкой VT-x 4 ядра минимум
— встроенные Advanced Host Controller Interface (AHCI) SATA контроллеры
— LSI контроллеры в режиме IT mode (Nutanix testing shows better performance than IR)
— минимум 16 GB памяти на хост (очень рекомендуется 32 GB или больше для дедубликации — на 16 она не включается)
— минимальный объем SSD на каждый хост 200 GB
— минимальный объем SSD на каждый хост для поддержки дедубликации 300GB (желательно больше 400,480)
Контроллер ADAPTEC 6405E SAS не определился Nutanix, соответственно использовать диски SAS мы не смогли (использовали диски SATA и SSD которые подключены к разъемам на мат. плате).
Для установки требуется носитель на каждый хост: мы не стали ставить готовый образ на локальные диски сервера — поставили на флешку по 8GB на каждый хост (минимальные требования флешка 8GB, лучше 16, туда ставится сам hypervisor KVM (Acropolis) и CVM — control virtual machine — и так на каждый хост!), всего количество виртуальных машин CVM по количеству хостов.
В нашем случае получилась такая конфигурация:
— 16 гигабайт памяти на хост
— на каждый хост 2 жестких диска HDD SATA 500GB
— на каждый хост 1 жесткий диск SSD 500GB
— для дедубликации нужно минимум 24GB памяти на хост + минимум 300GB SSD на хост, поэтому у нас она не включилась.
В случае несоблюдения минимальных требований система не устанавливается…
В Community Edition нельзя поменять гипервизор — по умолчанию ставится только KVM — это огромный минус, потому что мы привыкли к использованию VMWARE ESXi.
После установки на каждом хосте появляется служебная виртуальная машина (CVM — control virtual machine), которая занимает 2 ядра процессора и резервирует для себя 12ГБ оперативной памяти на каждом хосте — учитывыйте это при планировании.
Аосле установки на все узлы кластера создаем тома для хранения данных: при создании StorageContainer если Replication Factor 2, то свободное место дискового хранилища на 50% меньше (все блоки данных дублируются на других дисках, например у нас 3 хоста, на каждом 2 диска SATA по 500 гб, всего 6 дисков + SSD диски на каждом из хостов всего 2.88 TB общий объем из них 1.44 TB доступных пользователю для хранения).
Дисковый массив после создания доступен и отдается по NFS: например, в кластер VMWARE 5.5 он в качестве datastore подключился замечательно, соответственно storage vmotion работает тоже, правда скорость по сравнению с FC 4Gb\sec сильно проигрывает (оно и понятно при гигабитном подключении — интересно было бы погонять на 10G или infiniband).
Живая машинка на 60GB с кластера VMWARE переезжала примерно 24 минуты на хранилище Nutanix. Обратно на FC хранилище enterprise уровня она же переезжала 13 минут.
Запись iso файла c сервера windows на виртуалку vmware которая находится на хранилище нутаникс через nfs (1Gb/s) — 34MB/sec.
Нет интерактивного инструмента управления портгруппами и vswitch — всё делается из cli.
Неочевидный момент по поводу сетей для работы виртуальных машин: советую внимательно прочитать документацию. Для виртуальных машин внутри Nutanix мы использовали VLANы, который используют все наши остальные системы виртуализации для выхода в сеть. На этапе настройки виртуальных сетей просто указывается номер VLANа виртуальной сети — больше настроек нет, а в свойствах виртуальной машины настраивается соответствие виртуального сетевого адаптера номеру сети — и все, других настроек в GUI нет! Но всё работает.
Для установки Windows guests виртуальных машин необходимо подключать второй виртуальный CDROM с VirtIO драйверами (например можно взять отсюда (предварительно положить iso файл на хранилище): fedoraproject.org/wiki/Windows_Virtio_Drivers#Direct_download)
Время установки guest vm на windows 2012 R2 составило всего 7 минут от начала до полной загрузки рабочей системы, работает виртуальная машина визуально тоже быстро — очевидно, помогает SSD.
Можно ставить виртуальные машину и на тип кортроллера виртуального диска IDE (без подключения VirtIO драйверов), но это не рекомендуемая конфигурация — производительность будет значительно меньше.
При тестовом отключении по питанию одного из хостов кластера HA отработал, система не повисла, дисковые ресурсы доступны и по сети и локально, виртуальные машины, которые были на отключенном хосте перезапустились на других хостах (если памяти достаточно),
однако неприятным фактом после включения питания 3-го хоста обратно явилось то, что статус системы очень долгое время держится в Critial — не знаю, что это за собой тянет, но хорошего мало. (от 1 часа до 2-х). Например тот же кластер VMWARE после подключения хоста достаточно быстро определяет его статус и подключает обратно в кластер.
Вообще нужно заметить, что у интерфейса Prism для управления кластером Nutanix CE довольно бедный (хотя и приятный) интерфейс. Доступны только базовые настройки, но в общем случае их на первый взгляд достаточно, есть некая настраиваемая графическая аналитика, хотя конечно значительно слабее, чем в VCENTER.
Непонятным остается то, как осуществлять резервное копирование: ведь ни Symantec ни продукты Veeam не поддерживают KVM виртуализацию… очевидно, через снэпшоты, но как быть с гранулярным восстановлением данных в этом случае (пофайлово).
Визуально Nutanix был намного быстрее, что на этапе копирования образов на его систему хранения, что на этапе установки операционной системы на новую виртуалку из образа, что на этапе загрузок-перезагрузок: почти мгновенно всё). Есть желание попробовать Nutanix на более мощной конфиурации и обязательно при использовании VMWARE EXSi.
Особых данных производительности обеих систем конечно привести не могу, но зато можно почерпнуть некую информацию о «граблях» на этапе установки настройки. Если что прошу прощения — первая заметка на Хабре.
