Comments 29
1. В опросе не хватает пункта «SDL Trados»: SDL ведь купил их несколько лет назад.
2. Если говорить о сопоставлении сегментов оригинального текста и перевода, можно вспомнить еще WinAlign (входит в состав старого Традоса).
3. По моим ощущениям, главный недостаток при переводе с помощью CAT-программ — необходимость строго соблюдать структуру оригинала. Для работы с техническими текстами, документами и т. п. это подходит прекрасно, но вот с чем-то более художественным работать уже не очень удобно. Наверное, так и должно быть, все-таки перевод «художки» — это отдельная область.
4. Глоссарии и проверку текста по ним жутко удобно использовать для языков с бедной (англ.) или отсутствующей (кит.) морфологией. Тот же русский язык уже вызывает трудности: термины опознаются не всегда и не везде, потому что могут стоять в косвенном падеже или какой-нибудь особой форме.
Резюмируя: CATом можно зарабатывать неплохие деньги при переводе инструкций и всякого такого. Особенно если заказчик не прислал готовую «память перевода» (translation memory) и не знает, сколько в тексте новых сегментов (за них платят 100%), а сколько повторений (за них дают 20%).
Вопрос автору: насколько стабильна OmegaT? Можно использовать «в продакшене» или она годится только для фриланса? (Что касается перевода на КДПВ: пропущено тире в последнем предложении.)
1. В опросе не хватает пункта «SDL Trados»: SDL ведь купил их несколько лет назад.
Упс, так и сделал опрос изначально, но что-то пошло не так :(
насколько стабильна OmegaT? Можно использовать «в продакшене»
Если под стабильностью понимать «не крашится ли с эксепшном» — то стабильна уже пару лет, во всяком случае stable-ветка. Впрочем, я сижу на latest и там не видел никаких проблем.
Но нужно принимать во внимание особенности работы, такие как костыль для разделения/сращивания сегментов, и поведение спецсимволов в памяти перевода. С последним я до конца не разобрался, то ли баг, то ли я что-то не так делаю.
Кроме того, я намеренно не покрыл в туториале командную работу: правильная настройка SVN и выстраивание рабочего процесса через него заслуживает отдельной статьи, потому что geek way и совершенно не дружелюбно к пользователю. Что, в общем-то, не мешало использовать OmegaT на моём предыдущем рабочем месте для команды из нескольких человек.
Встроенный машинный перевод разве проблема омеги? Сервисы сами по себе платные (кроме яндекса), ничего тут не поделаешь.
Я живу за великим китайским файерволом, поэтому у меня уже определённая деформация сознания: везде, где можно, пользоваться standalone или self-deployed решениями. Потому что сегодня облако работает, а завтра оно закрыто навсегда. Независимо от масштаба. (ваша блокировка яндекса — это так, пустяки ещё).
Да и по скорости отклика интерфейса облачным решениям всё ж таки далеко до обычных программ.
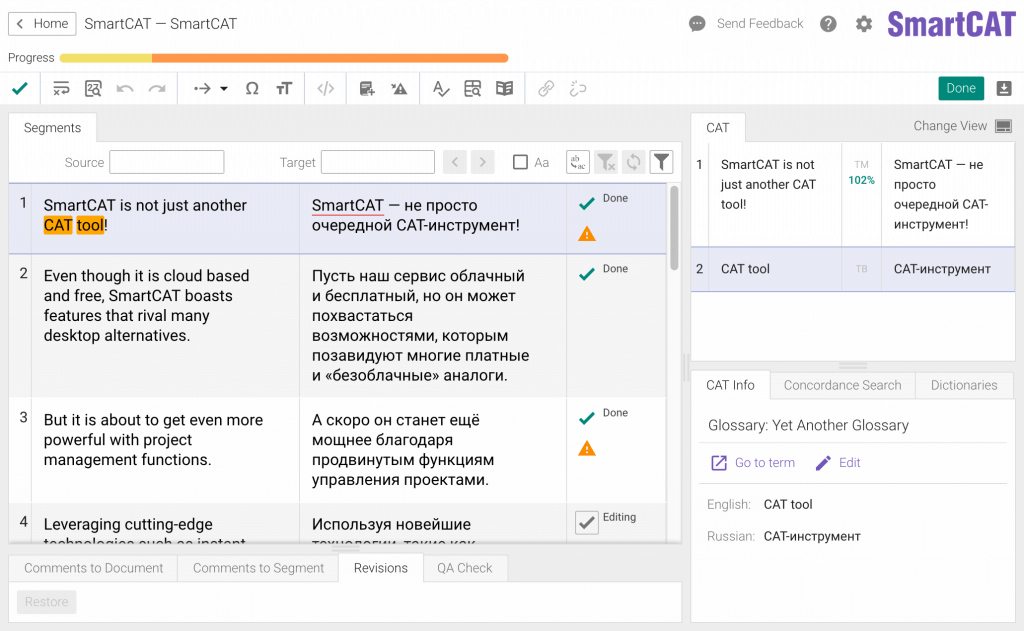
Вверху прогрессбар, справа совпадения с цветовым выделением процента, подтвержденные сегменты отмечены выделяющейся зеленой галочкой, ошибки обозначены оранжевым треугольником. Теги выделены желтым (на скриншоте нет). Информации минимум, важное выделено.
Вот скриншот OmegaT

Процент выполнения показан внизу мелкими малопонятными цифрами, причем тут смешана и статистика по текущему документу, и по проекту в целом. Окно Fuzzy Matches: за процент совпадения тем же шрифтом, что и собственно текст, нужно бить по рукам. Окно Editor: теги сливаются с основным текстом, в самих тегах слишком много текста. Можно было бы делать, как в Poedit: просто циферка в скобках.
В целом, я положительно оцениваю OmegaT: проведена гигантская работа и это достойный инструмент переводчика, но к нему очень сильно нужно привыкать. Про скорость отклика с Вами согласен.
Связку Яндекса с Омегой попробую, open source нужно поддерживать. MS переводчик вроде тоже можно получить бесплатно, только нужно бумажной почтой отправить подписанный договор в Редмонд :)
Ну и еще раз поблагодарю Вас за руководство, вышло очень толково. Представляю, сколько времени ушло на написание. Если будет желание, сделайте что-то похожее об Okapi — там все еще запутаннее…
Работа действительно идёт. В последнем релизе наконец-то вынесли все настройки в одно удобное окно конфигурации, на порядок лучше стало. И добавили LanguageTools к простому сверятелю тегов.
С Okapi я не так плотно работаю, пользуюсь время от времени для каких-то совсем простых операций. Гайд по омеге же писал по своему многолетнему опыту, в основном чтобы не объяснять кому-нибудь в н-цатый раз одно и тоже, а просто кидать ссылку (:
Что ж, если разработка идет, то и мотивации использовать гораздо больше :) можно даже попровать feature request, вдруг прокатит.
Если первое, то Project -> Current translated document, и будет сгенерирован текущий финальный файл в том формате, в котором был оригинал.
Если второе, то Tools -> Scripting -> Write Excel table, и будет сгенерирован эксель со всем контетом из проекта.
Спасибо за статью.
Использовал OmegaT лет 8-9 назад.
Как раз юридические документы.
А вот программы переводил просто в текстовом редакторе Vim.
Там обычно .po или .xml и омега как то не прижилась.
Но это так по мелочам.
Про настройку репозитория для Ворд/Эксель было бы интересно.
Особенно прикрутили ли diff и если да то как?
Репозиторий это тот самый SVN или git.
Настройки тоже интересны, но на самом деле workflow — это самое вкусное.
Переводчики обычно не технари, организовать совместную работу такой команды это плюс 100500 очков к знанию подводных камней.
Вот ими делитесь, если желание останется.
По ответу понятно что никакими diff-tool не пользовались.
Обычно такой инструмент нужен когда сводишь вместе работу двух разных людей в одном файле — merge.
Для языков программирования это достаточно тривиально, простой текст он и в Африке текст, большинство инструментов с ним прекрасно справляются.
Для Ворд/Эксель нормальных diff не находил, когда искал.
Часто можно вывернуться поделив большой файл на части и распределив их в команде.
Кроме Майкрософтовских е немало форматов для которых контроль изменений — боль.
Если над доком работает несколько человек по SVN, то синхронизация идёт достаточно быстро. Плюс омега может оставлять пометки о том, кто именно перевёл тот или иной фрагмент. Т.е. память перевода постоянно синхронизируется между переводчиками, и любой из них в любой момент может сгенерировать конечный файл.
Когда мы работали командой, то просто обуславливались, с какого по какой сегмент переводим. Либо делили на разные файлы, да. (со всякими key=value документами это не проблема).
Командная работа идёт по SVN, но версионность как таковая в омеге не задействована.
У меня около года назад стояла задача создать и поддерживать репозиторий для файлов Simulink, так разработчикам пришлось перейти к разработке без мерджей, только версии.
Инструменты для дифф/мердж существуют но стоили невменяемых денег.
Для вас может подойти использование инструментов, которые конвертируют Word/Exel на лету в текстовый формат (Markdown?), происходит слияние (merge), а затем, так-же на лету происходит конвертация обратно.
В идеальном случае, в репозиторий попадет только текст, а реальный документ будет использоваться в работе и как конечный результат.
Более менее представляю как это сделать на Git, с SVN придется курить мануалы.
Я бы попробовал в Git использовать в качестве хуков скрипты на основе pandoc.
Правда это может поломать разметку некоторых файлов.
Есть ещё word_diff на первый взгляд немного заморочно.
За то не придется ставить на машины ничего кроме Git клиента, конвертация в собственном облаке.
OmegaT: переводим с помощью компьютера