Пролог
В настоящее время я занимаюсь разработкой редактора схем на Javascript, и в процессе этой работы столкнулся с проблемой, которой будет посвящена данная статья, а именно: сериализация и десериализация сложных объектов данных.
Не вдаваясь в детали проекта, отмечу, что по моей задумке схема представляет из себя массив элементов (вершин), унаследованных от базового класса. Соответственно, каждый дочерний класс реализует свою логику. Кроме того, вершины содержат ссылки друг на друга (стрелочки), которые также необходимо сохранять. Теоретически, вершины могут ссылаться сами на себя напрямую или через другие вершины. Стандартный JSON.stringify не способен сериализовать такой массив, поэтому мной было принято решение сделать собственный сериализатор, решающий две описанные проблемы:
- Возможность сохранять информацию о классе в процессе сериализации и восстанавливать ее при десериализации.
- Возможность сохранять и восстанавливать ссылки на объекты, в т.ч. циклические.
Подробнее о постановке задачи и ее решении под катом.
Проект сериализатора на github
Ссылка на проект github: ссылка.
Комплексные примеры там же в папке test-src.
Рекурсивный сериализатор: ссылка.
Плоский сериализатор: ссылка.
Постановка задачи
Как я уже отметил, исходная задача – сериализация произвольных схем для редактора. Чтобы не тратить время на описание редактора, поставим задачу попроще. Предположим, что мы хотим сделать формальное описание схемы простого алгоритма с использованием ES6 классов Javascript, а затем сериализовать и десериализовать эту схему.
В интернете я нашел подходящую картинку простейшего алгоритма определения максимума из двух значений:
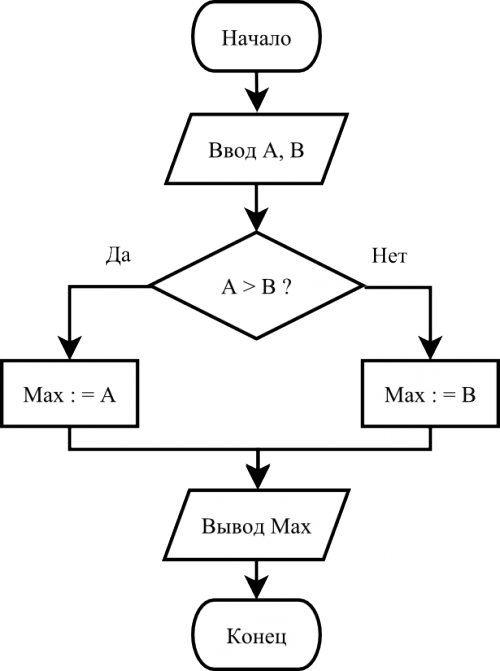
Тут надо сказать, что я не являюсь Javascript-разработчиком, и мой "родной" язык – это C#, поэтому подход к решению задачи продиктован опытом объектно-ориентированной разработки на C#. Глядя на эту схему, я вижу вершины следующих типов (названия условные и особой роли не играют):
- Начальная вершина (Start)
- Конечная вершина (Finish)
- Вершина команды (Command)
- Вершина присваивания (Let)
- Вершина проверки условия (If)
Эти вершины имеют некие отличия друг от друга в наборе своих данных или семантике, но все они унаследованы от базовой вершины (Node). Там же, в классе Node, описано поле links, содержащее ссылки на другие вершины, и метод addLink, позволяющий эти ссылки добавлять. Полный код всех классов можно посмотреть здесь.
Давайте напишем код, собирающий схему с картинки, и попробуем сериализовать результат.
// создаем схему
let start = new Schema.Start();
let input = new Schema.Command('Ввод A, B');
let check = new Schema.If('A > B');
let maxIsA = new Schema.Let('Max', 'A');
let maxIsB = new Schema.Let('Max', 'B');
let output = new Schema.Command('Вывод Max');
let finish = new Schema.Finish();
// настраиваем связи
start.addLink(input);
input.addLink(check);
check.addLink(maxIsA, { condition: 'true' });
check.addLink(maxIsB, { condition: 'false' });
maxIsA.addLink(output);
maxIsB.addLink(output);
output.addLink(finish);
// собираем объект схемы (массив вершин)
let schema = [
start,
input,
check,
maxIsA,
maxIsB,
output,
finish
];Если мы сериализуем эту схему с помощью JSON.stringify, то получим нечто ужасное. Приведу первые несколько строчек результата, в которые я добавил свои комментарии:
[
/* начало первой вершины */
{
"id": "d9c8ab69-e4fa-4433-80bb-1cc7173024d6",
"name": "Start",
"links": {
"2e3d482b-187f-4c96-95cd-b3cde9e55a43": {
"id": "2e3d482b-187f-4c96-95cd-b3cde9e55a43",
"target": /* это уже вторая вершина*/ {
"id": "f87a3913-84b0-4b70-8927-6111c6628a1f",
"name": "Command",
"links": {
"4f623116-1b70-42bf-8a47-da1e9be5e4b2": {
"id": "4f623116-1b70-42bf-8a47-da1e9be5e4b2",
"target": /* а вот и третья вершина*/ {
"id": "94a47403-13ab-4c83-98fe-3b201744c8f2",
"name": "If",
"links": { ...Т.к. первая вершина содержала ссылку на вторую, а та на последующие, то в результате ее сериализации была сериализована все схема. Затем была сериализована вторая вершина и все от нее зависящие, ну и так далее. Восстановить исходные связи из этой мешанины можно только по идентификаторам, но и они не помогут, если какая-то из вершин будет ссылаться сама на себя напрямую или через другие вершины. В этом случае, сериализатор выдаст ошибку Uncaught TypeError: Converting circular structure to JSON. Если непонятно, то вот простейший пример, порождающий эту ошибку: https://jsfiddle.net/L4guo86w/.
Кроме того, JSON не содержит никакой информации об исходных классах, поэтому нет возможности понять, какого типа была каждая из вершин до сериализации.
Осознав эти проблемы, я полез в интернет и стал искать готовые решения. Их было много, но большинство были очень громоздкими или требовали специального описания сериализуемых классов, поэтому было принято решение сделать свой велосипед. И да, я люблю велосипеды.
Концепция сериализатора
Этот раздел для тех, кто хочет поучаствовать в создании алгоритма сериализации вместе со мной, пусть и виртуально.
Сохранение информации о типах данных
Одна из проблем Javascript – отсутствие метаданных, которые позволяют творить чудеса в таких языках, как C# или Java (атрибуты и рефлексия). С другой стороны, мне не требуется супер сложная сериализация с возможностью определения списка сериализуемых полей, валидацией и другими фишками. Поэтому основная идея – добавить в объект информацию о его типе и сериализовать обычным JSON.stringify.
В ходе поиска решений я наткнулся на интересную статью, заголовок которой переводится как "6 неверных способов добавить информацию о типе в JSON". На самом деле способы очень даже неплохие, и я выбрал для себя тот, что под номером 5. Если вам лень читать статью, а я настоятельно рекомендую это сделать, то вкратце опишу этот способ: при сериализации объекта мы оборачиваем его в другой объект с единственным полем, имя которого имеет формат "@<type>", а значение – данные объекта. При десериализации мы извлекаем имя типа, воссоздаем объект из конструктора и читаем данные его полей.
Если из нашего примера выше убрать ссылки, то стандартный JSON.stringify сериализует данные так:
[
{
"id": "d04d6a58-7215-4102-aed0-32122e331cf4",
"name": "Start",
"links": {}
},
{
"id": "5c58c3fc-8ce1-45a5-9e44-90d5cebe11d3",
"name": "Command",
"links": {},
"command": "Ввод A, B"
},
...
}А наш сериализатор обернет так:
[
{
"@Schema.Start": {
"id": "d04d6a58-7215-4102-aed0-32122e331cf4",
"name": "Start",
"links": {}
}
},
{
"@Schema.Command": {
"id": "5c58c3fc-8ce1-45a5-9e44-90d5cebe11d3",
"name": "Command",
"links": {},
"command": "Ввод A, B"
}
},
...
}Конечно, здесь есть недостаток: сериализатор должен знать о типах, которые он может сериализовать, а сами объекты не должны содержать полей, имя которых начинается с собачки. Впрочем, вторая проблема решается соглашением с разработчиками или заменой символа собачки на что-то другое, а первая проблема решается в одну строчку кода (ниже будет пример). Мы ведь знаем, что именно будем сериализовать, правда?
Решение проблемы со ссылками
Здесь все еще проще с точки зрения алгоритма, но сложнее с реализацией.
При сериализации экземпляров классов, зарегистрированных в сериализаторе, мы будем запоминать их в кэше и присваивать им порядковый номер. Если в дальнейшем мы снова встретим этот экземпляр, то в первое его определение мы добавим этот номер (имя поля примет вид "@<type>|<index>"), а в месте сериализации вставим ссылку в виде объекта
{
"@<type>": <index>
}Таким образом, при десериализации мы смотрим, чем именно является значение поля. Если это число, то извлекаем объект из кэша по этому номеру. Иначе это его первое определение.
Вернем ссылку с первой вершины схемы на вторую и посмотрим на результат:
[
{
"@Schema.Start": {
"id": "a26a3a29-9462-4c92-8d24-6a93dd5c819a",
"name": "Start",
"links": {
"25fa2c44-0446-4471-a013-8b24ffb33bac": {
"@Schema.Link": {
"id": "25fa2c44-0446-4471-a013-8b24ffb33bac",
"target": {
"@Schema.Command|1": {
"id": "4f4f5521-a2ee-4576-8aec-f61a08ed38dc",
"name": "Command",
"links": {},
"command": "Ввод A, B"
}
}
}
}
}
}
},
{
"@Schema.Command": 1
},
...
}Выглядит не очень понятно с первого взгляда, т.к. вторая вершина впервые определяется внутри первой в объекте связи Link, но важно, что этот подход работает. Кроме того, я создал второй вариант сериализатора, который обходит дерево не в глубину, а в ширину, что позволяет избежать подобных "лесенок".
Создание сериализатора
Этот раздел предназначен для тех, кому интересна реализация идей, описанных выше.
Заготовка сериализатора
Как и любой другой, наш сериализатор будет иметь два основных метода – serialize и deserialize. Кроме того, нам понадобится метод, сообщающий сериализатору о классах, которые он должен сериализовать (register) и классах, которые не должен (ignore). Последнее нужно, чтобы не сериализовать DOM-элементы, объекты JQuery или какие-либо другие типы данных, которые сериализовать невозможно или сериализация которых не нужна. Например, в моем редакторе я храню визуальный элемент, соответствующей вершине или связи. Он создается при инициализации и, разумеется, не должен попадать в БД.
/**
* сериализатор
*/
export default class Serializer {
/**
* конструктор
*/
constructor() {
this._nameToCtor = []; // словарь сопоставлений типов
this._ctorToName = []; // словарь сопоставлений типов
this._ignore = [Element]; // список игнорируемых типов
}
/**
* зарегистрировать сопоставление
* @param {string} alias псевдоним
* @param {Function} ctor конструктор
*/
register(alias, ctor) {
if (typeof ctor === 'undefined' && typeof alias === 'function') {
// передан один аргумент - конструктор
ctor = alias;
alias = ctor.name;
}
this._nameToCtor[alias] = ctor;
this._ctorToName[ctor] = alias;
}
/**
* зарегистрировать тип для игнорирования
* @param {Function} ctor конструктор
*/
ignore(ctor) {
if (this._ignore.indexOf(ctor) < 0) {
this._ignore.push(ctor);
}
}
/**
* сериализовать объект
* @param {any} val объект
* @param {Function} [replacer] функция преобразования или массив свойств сериализации
* @param {string} [space] для отступов
* @returns {string} строка
*/
serialize(val, replacer, space) {
return JSON.stringify(new SerializationContext(this).serialize(val), replacer, space);
}
/**
* десериализовать строку или объект json
* @param {any} val строка или объект json
* @returns {any} объект
*/
deserialize(val) {
// преобразуем строку в объект
if (isString(val)) val = JSON.parse(val);
return new DeserializationContext(this).deserialize(val);
}
}Пояснения.
Для регистрации класса необходимо передать его конструктор в метод register одним из двух способов:
- register(MyClass)
- register('MyNamespace.MyClass', MyClass)
В первом случае имя класса будет извлечено из имени функции конструктора (не поддерживается в IE), во втором имя вы указываете сами. Второй способ предпочтительней, т.к. позволяет использовать пространства имен, а первый, по задумке, предназначен для регистрации встроенных типов Javascript с переопределенной логикой сериализации.
Для нашего примера инициализация сериализатора выглядит следующим образом:
import Schema from './schema';
...
// создаем сериализатор
let serializer = new Serializer();
// регистрируем классы
Object.keys(Schema).forEach(key => serializer.register(`Schema.${key}`, Schema[key]));Объект Schema содержит в себе описания всех классов вершин, так что код регистрации классов укладывается в одну строчку.
Контекст сериализации и десериализации
Вы могли обратить внимание на загадочные классы SerializationContext и DeserializationContext. Именно они и выполняют все работу, а нужны прежде всего для того, чтобы отделить данные разных процессов сериализации/десериализации, т.к. для каждого их вызова необходимо хранить промежуточную информацию – кэш сериализованных объектов и порядковый номер для ссылки.
SerializationContext
Я разберу детально только рекурсивный сериализатор, т.к. их "плоский" аналог несколько сложнее, и отличается лишь подходом к обработке дерева объектов.
Начнем с конструктора:
/**
* конструктор
* @param {Serializer} ser сериализатор
*/
constructor(ser) {
this.__proto__.__proto__ = ser;
this.cache = []; // кэш сериализованных объектов
this.index = 0; // идентификатор объекта для ссылки
}Постараюсь объяснить загадочную строчку this.__proto__.__proto__ = ser;
На вход конструктора мы принимаем объект самого сериализатора, а эта строчка наследует наш класс от него. Это позволяет получить доступ к данным сериализатора через this.
Например, this._ignore ссылается на список игнорируемых классов самого сериализатора ("черный список"), что очень полезно. В противном случае нам бы пришлось писать что-то типа this._serializer._ignore.
Главный метод сериализации:
/**
* сериализовать объект
* @param {any} val объект
* @returns {string} строка
*/
serialize(val) {
if (Array.isArray(val)) {
// массив
return this.serializeArray(val);
} else if (isObject(val)) {
// объект
if (this._ignore.some(e => val instanceof e)) {
// игнорируемый тип
return undefined;
} else {
return this.serializeObject(val);
}
} else {
// прочие значения
return val;
}
}Тут надо отметить, что существует три базовых типа данных, которые мы обрабатываем: массивы, объекты и простые значения. Если конструктор объекта находится в "черном списке", то этот объект не сериализуется.
Сериализация массивов:
/**
* сериализовать массив
* @param {Array} val массив
* @returns {Array} результат
*/
serializeArray(val) {
let res = [];
for (let item of val) {
let e = this.serialize(item);
if (typeof e !== 'undefined') res.push(e);
}
return res;
}Можно написать короче через map, но это не критично. Важен только один момент – проверка значения на undefined. Если в массиве будет несериализуемый класс, то это без этой проверки он попадет в массив в виде undefined, что не очень хорошо. Также в моей реализации массивы сериализуются без ключей. Теоретически, можно доработать алгоритм для сериализации ассоциативных массивов, но для этих целей я предпочитаю использовать объекты. Кроме того, JSON.stringify также не любит ассоциативные массивы.
Сериализация объектов:
/**
* сериализовать объект
* @param {Object} val объект
* @returns {Object} результат
*/
serializeObject(val) {
let name = this._ctorToName[val.constructor];
if (name) {
// зарегистрированный для сериализации тип
if (!val.__uuid) val.__uuid = ++uuid;
let cached = this.cache[val.__uuid];
if (cached) {
// объект есть в кэше
if (!cached.index) {
// индекс еще не назначен
cached.index = ++this.index;
let key = Object.keys(cached.ref)[0];
let old = cached.ref[key];
cached.ref[`@${name}|${cached.index}`] = old;
delete cached.ref[key];
}
// возвращаем ссылку на объект
return { [`@${name}`]: cached.index };
} else {
let res;
let cached = { ref: { [`@${name}`]: {} } };
this.cache[val.__uuid] = cached;
if (typeof val.serialize === 'function') {
// класс реализует интерфейс сериализации
res = val.serialize();
} else {
// обычная сериализация
res = this.serializeObjectInner(val);
}
cached.ref[Object.keys(cached.ref)[0]] = res;
return cached.ref;
}
} else {
// простой объект
return this.serializeObjectInner(val);
}
}Очевидно, это самая сложная часть сериализатора, его сердце. Давайте разберем его по полочкам.
Для начала, мы проверяем, зарегистрирован ли конструктор класса в сериализаторе. Если нет, то это простой объект, для которого вызывается служебный метод serializeObjectInner.
В противном случае, мы проверяем, назначен ли объекту уникальный идентификатор __uuid. Это простая переменная-счетчик, общая для всех сериализаторов, а используется она для того, чтобы сохранить ссылку на экземпляр класса в кэше. Можно было бы обойтись без нее, и хранить в кэше сам экземпляр без ключа, но тогда для проверки, сохранен ли объект в кэше, приходилось бы пробегать по всему кэшу, а тут достаточно проверить ключ. Думаю, это быстрее с точки зрения внутренней реализации объектов в браузерах. Кроме того, я намеренно не сериализую поля, начинающиеся с двух символов подчеркивания, поэтому поле __uuid не попадет в итоговый json, как и другие приватные поля классов. Если для вашей задачи это недопустимо, можете изменить данную логику.
Далее по значению __uuid мы ищем объект, описывающий экземпляр класса в кэше (cached).
Если такой объект есть, значит значение уже было сериализовано ранее. В этом случае мы назначаем объекту порядковый номер, если этого не было сделано ранее:
if (!cached.index) {
// индекс еще не назначен
cached.index = ++this.index;
let key = Object.keys(cached.ref)[0];
let old = cached.ref[key];
cached.ref[`@${name}|${cached.index}`] = old;
delete cached.ref[key];
}Код выглядит запутанно, и его можно упростить, если назначать номер всем классам, которые мы сериализуем. Но для отладки и восприятия результата лучше, когда номер назначается только тем классам, на которые в дальнейшем есть ссылки.
Когда номер назначен, мы возвращаем ссылку согласно алгоритму:
// возвращаем ссылку на объект
return { [`@${name}`]: cached.index };Если же объект сериализуется впервые, мы создаем экземпляр его кэша:
let res;
let cached = { ref: { [`@${name}`]: {} } };
this.cache[val.__uuid] = cached;А затем сериализуем его:
if (typeof val.serialize === 'function') {
// класс реализует интерфейс сериализации
res = val.serialize();
} else {
// обычная сериализация
res = this.serializeObjectInner(val);
}
cached.ref[Object.keys(cached.ref)[0]] = res;Тут есть проверка на реализацию классом интерфейса сериализации (о котором речь пойдет ниже), а также конструкция Object.keys(cached.ref)[0]. Дело в том, что cached.ref хранит ссылку на объект-обертку { "@<type>[|<index>]": <данные> }, но имя поля объекта нам неизвестно, т.к. на данном этапе мы еще не знаем, будет ли в имени присутствовать номер объекта (index). Эта конструкция просто извлекает первое и единственное поле объекта.
Наконец, служебный метод сериализации внутренностей объекта:
/**
* сериализовать объект
* @param {Object} val объект
* @returns {Object} результат
*/
serializeObjectInner(val) {
let res = {};
for (let key of Object.getOwnPropertyNames(val)) {
if (!(isString(key) && key.startsWith('__'))) {
// игнорируем поля, начинающиеся на два символа подчеркивания
res[key] = this.serialize(val[key]);
}
}
return res;
}Мы создаем новый объект и копируем в него поля из старого.
DeserializationContext
Процесс десериализации работает в обратном порядке и в особых комментариях не нуждается.
/**
* контекст десериализации
*/
class DeserializationContext {
/**
* конструктор
* @param {Serializer} ser сериализатор
*/
constructor(ser) {
this.__proto__.__proto__ = ser;
this.cache = []; // кэш сериализованных объектов
}
/**
* десериализовать объект json
* @param {any} val объект json
* @returns {any} объект
*/
deserialize(val) {
if (Array.isArray(val)) {
// массив
return this.deserializeArray(val);
} else if (isObject(val)) {
// объект
return this.deserializeObject(val);
} else {
// прочие значения
return val;
}
}
/**
* десериализовать объект
* @param {Object} val объект
* @returns {Object} результат
*/
deserializeArray(val) {
return val.map(item => this.deserialize(item));
}
/**
* десериализовать массив
* @param {Array} val массив
* @returns {Array} результат
*/
deserializeObject(val) {
let res = {};
for (let key of Object.getOwnPropertyNames(val)) {
let data = val[key];
if (isString(key) && key.startsWith('@')) {
// указание типа
if (isInteger(data)) {
// ссылка
res = this.cache[data];
if (res) {
return res;
} else {
console.error(`Не найден объект с идентификатором ${data}`);
return data;
}
}
else {
// описание объекта
let [name, id] = key.substr(1).split('|');
let ctor = this._nameToCtor[name];
if (ctor) {
// конструктор есть в описании
res = new ctor();
// сохраняем в кэше, если указан айдишник
if (id) this.cache[id] = res;
if (typeof res.deserialize === 'function') {
// класс реализует интерфейс сериализации
res.deserialize(data);
} else {
// десериализуем свойства объекта
for (let key of Object.getOwnPropertyNames(data)) {
res[key] = this.deserialize(data[key]);
}
}
return res;
} else {
// конструктор не найден
console.error(`Конструктор типа "${name}" не найден.`);
return val[key];
}
}
} else {
// простое поле
res[key] = this.deserialize(val[key]);
}
}
return res;
}
}Дополнительные возможности
Интерфейс сериализации
В Javascript нет поддержки интерфейсов, но мы можем договориться, что если класс реализует метод serialize и deserialize, то именно эти методы будут использоваться для сериализации/десериализации соответственно.
Кроме того, Javascript позволяет реализовать эти методы для встроенных типов, например, для Date:
Date.prototype.serialize = function () {
return this.toISOString();
};
Date.prototype.deserialize = function (val) {
let date = new Date(val);
this.setDate(date.getDate());
this.setTime(date.getTime());
};Главное не забудьте зарегистрировать тип Date: serializer.register(Date);.
Результат:
{
"@Date": "2018-06-02T20:41:06.861Z"
}Единственное ограничение: результат сериализации не должен быть целым числом, т.к. в этом случае это будет интерпретировано как ссылка на объект.
Аналогично можно сериализовать простые классы в строки. Пример с сериализацией класса Color, описывающего цвет, в строку #rrggbb есть на github.
Плоский сериализатор
Специально для вас, дорогие читатели, я написал второй вариант сериализатора, который обходит дерево объектов не рекурсивно в глубину, а итеративно в ширину с помощью очереди.
Для сравнения приведу пример сериализации двух первых вершин нашей схемы в обоих вариантах.
[
{
"@Schema.Start": {
"id": "5ec74f26-9515-4789-b852-12feeb258949",
"name": "Start",
"links": {
"102c3dca-8e08-4389-bc7f-68862f2061ef": {
"@Schema.Link": {
"id": "102c3dca-8e08-4389-bc7f-68862f2061ef",
"target": {
"@Schema.Command|1": {
"id": "447f6299-4bd4-48e4-b271-016a0d47fc0e",
"name": "Command",
"links": {},
"command": "Ввод A, B"
}
}
}
}
}
}
},
{
"@Schema.Command": 1
}
][
{
"@Schema.Start": {
"id": "1412603f-24c2-4513-836e-f2b0c0392483",
"name": "Start",
"links": {
"b94ac7e5-d75f-44c1-960f-a02f52c994da": {
"@Schema.Link": {
"id": "b94ac7e5-d75f-44c1-960f-a02f52c994da",
"target": {
"@Schema.Command": 1
}
}
}
}
}
},
{
"@Schema.Command|1": {
"id": "a93e452e-4276-4d6a-86a1-0681226d79f0",
"name": "Command",
"links": {},
"command": "Ввод A, B"
}
}
]Лично мне второй вариант нравится даже больше, чем первый, но следует помнить, что выбрав один из вариантов, вы не сможете использовать другой. Все дело в ссылках. Обратите внимание, что в плоском сериализаторе ссылка на вторую вершину идет до ее описания.
Плюсы и минусы сериализатора
Плюсы:
- Код сериализатора достаточно прост и компактен (примерно 300 строк, половина из которых комментарии).
- Сериализатор прост в использовании и не требует сторонних библиотек.
- Есть встроенная поддержка интерфейса сериализации для произвольной сериализации классов.
- Результат приятно радует глаз (имхо).
- Разработка аналогичного сериализатора/десериализатора на других языках не представляет проблемы. Это может потребоваться, если результат сериализации будет обрабатываться на бэке.
Минусы:
- Для работы сериализатора требуется регистрация классов, которые он может сериализовать.
- Существуют небольшие ограничения на имена полей объектов.
- Сериализатор написан нубом в Javascript, поэтому может содержать баги и ошибки.
- Может страдать производительность на больших объемах данных.
Также минусом является то, что код написан на ES6. Конечно, возможно преобразование в более ранние версии Javascript, но я не проверял совместимость полученного кода с разными браузерами.
