Comments 51
Ну то есть, для заказчика диаграммы выглядят красиво, он все равно их не понимает.
А программистам зачем этот «привет из 70-х»?
Чтобы хранить диаграммы рядом с кодом. Чтобы версионировать их вместе с кодом. Чтобы по git diff видеть изменения, а по git blame видеть их причину. Чтобы не засорять репозиторий кучей устаревающих PNG.
Когда есть код?
Не все знания можно извлечь из кода. Если кратко, в нём есть знание «как» он написан, но часто нет знания «почему» и «зачем».
Ну и статья-то о работе аналитика. Если бы аналитик писал сразу код, то 1) разработчики были бы не нужны и 2) стейкхолдеры со стороны бизнеса ничего не поняли бы, они же разговаривают не на языке программирования.
Но текст первичен/универсален.
Когда рисуются «диаграммы», то они «объясняют» «как» писать программу/ы.
А вот «зачем»/«почему» не очень.
Простое перечисление входных и выходных данных гораздо информативнее, чем нарисованная диаграмма. Как минимум на ед. площади :-)
А насчет стетхолдеров. Диаграммы дают им опасную иллюзию, что они понимают, как работает (будет работать) программа.
В действительности это не совсем так.
И опять же, текст и интерфейс (скриншоты, а лучше прототип) гораздо понятнее, чем диаграммы.
Как минимум, когда приходишь к заказчику с со скриншотами (не о говоря о прототипе), то разговор становиться более предметным.
Интересно, тот же RUP говорит: при желании описывайте процесс текстом. И мы этим часто пользуемся. Но в сложных случаях очень часто именно диаграммы позволяют пояснять особенности проектируемой системы стейкхолдерам от пользователей. Об этом также говорится в RUP и это подтверждает опыт.
Опасную иллюзию понимания работы системы может дать и текст и прототипы интерфейсов. Многие пользователи могут вообще не понимать, как будет работать система до того, как ее запустят. На самом деле даже через много лет, после того, как ее запустят.
Прототипы интерфейсов «врут» по минимуму.
Т.к. для стейтхолдеров программа это интерфейс.
Грубо говоря (аналогия не доказательство)
Стейтхолдерам все равно, как выглядит движок автомобиля и из каких материалов он будет сделан.
Для них главное внешний вид, удобство управления, гарантия, того что у нее будут определенные характеристики.
И что для стейтхолдера интереснее — подробный чертеж карданного вала, или деревянный/пластиковый прототип будущего автомобиля?
Требование Model Visually есть в RUP. Требование итеративной разработки (против которой, насколько я понимаю, направлена Ваша аналогия с движком автомобиля) есть вообще много где. Программисты замечательных продуктов (того же junit5) используют диаграммы в документации.
Ставить все эти очень распространенные паттерны под вопрос можно и полезно, но в рамках значительно более широкого и серьезного обсуждения.
Но даже в данной статье, указывается, что текст удобнее чем диаграмма!
Т.е. пишем текст, чтобы получить диаграмму!
Тогда зачем диаграмма?
Может быть из текста удобнее получать информацию, чем из текста.
Если информацию удобнее изложить в виде текста.
Я уже не говорю, о трансляции.
Т.к. то что получается на выходе после трансляции это не всегда один в один, то что пишется в исходном тексте. :-)
Еще svg в pug тоже норм.
Тогда зачем диаграммы нужны?
Если их не удобно создавать, хранить, передавать.
И мой опыт говорит, что их и читать не удобно.
Зачем они нужны?
Я уверен (это мой опыт), что диаграммы очень помогают в программной документации (как и текст, и прототипы интерфейсов). Но это тема другой статьи))
Заказчику проще оперировать конкретными образами (прототип приложения/интерфейса), чем абстрактными диаграммами.
На презентациях они делают конечно умное лицо. Но когда доходит до реализация начинают вылезать нюансы, которых в диаграммах не было, но они должны были быть отражены.
Мне как программисту удобнее читать текст, чем «ползать» по развесистой диаграмме. Так проще сфокусироваться.
Да и по опыту других программистов, я вижу, что для них диаграммы ненужны, т.к. они привет из 70-х и процедурного программирования. На ООП плохо «ложатся».
Сущности удобнее воспринимать в виде списка.
А игры с со схемой БД, даже на этапе проектирования никто не заморачивается.
Т.к. если делать подробную схему это что-то невнятное в виде огромного полотна.
Если делать не такую подробную, то постоянное перескакивание с одной части схемы на другую.
Поэтому и мой вопрос «Зачем?»
Какую задачу выполняет диаграмма.
Ну кроме развлекательной.
Читать текст с картинками интереснее, чем без них :-)
По опыту sequence диаграммы в нём хорошо описывать. А вот для диаграмм классов, ER диаграмм и т.п. он, на мой взгляд, скорее плох, чем хорош, т.к. блоки обозначающие классы или таблицы на итоговом листе размещаются на листе неким «оптимальным» образом. Оптимальным с точки зрения пакета vizgraph, а не с точки зрения автора документации.
Сегодня у нас 5 таблиц, и мы имеем одно их расположение на диаграмме, завтра добавим одну, и те таблицы с высокой вероятностью будут размещены совершенно подругому. В результате, если нужно работать с диаграммой, проще взять графический инструмент (лично меня пока ни один инструмент не устроил), или нарисовать от руки на бумаге.
Я пишу этот комментарий, в надежде, вдруг эта проблема на самом деле не проблема, и автор, либо кто-нибудь из комментаторов подскажет, как можно управлять размещением блоков на экране. Вдруг я не первый, кто такого странного пожелал.
В plantuml можно немного управлять расположением классов, указывая направление стрелочек и отношеним классов в тексте:
1 FirstClass —* SecondClass (FirstClass будет сверху на графике)
2 SecondClass *— FirstClass (FirstClass будет распологаться снизу)
3 FirstClass -right-* SecondClass (собственно расположение будет лево-право)
Я рассматриваю PlantUML в первую очередь как инструмент бизнес-аналитика. Уверен, что этот инструмент не получится нормально использовать для проектирования классов или структуры базы данных, для этого есть другие прекрасные продукты. Но его очень удобно использовать для генерации программной документации.
Например, для визуального проектирования структуры базы данных мы используем инструмент DbSchema (который, собственно, и дает на выходе описание структуры в 2bass). Однако помещать ER-диаграммы в документацию — та еще головная боль. Поэтому для генерации документации мы используем именно PlantUML (фактически, создается несколько диаграмм, каждая на подмножество таблиц базы данных). При проектировании структуры базы данных я даже не задумываюсь о том, как визуально она разложится в диаграмме в документации, я всегда уверен, что это будет красиво и заказчик будет доволен.
Другой вопрос, что при проектировании логической структуры данных для понимания и согласования с заказчиком общих требований к системе я обычно использую именно PlantUML. Т.е. сначала структура сущностей рождается в диаграмме классов PlantUML, далее на основе нее разрабатывается структура базы данных в DbSchema, этот же инструмент используется для поддержания структуры в актуальном состоянии, далее документация по этой структуре генерируется автоматически опять же при помощи PlantUML.
Касательно комментария DmitriyDev. Да, все верно, PlantUML позволяет указывать желаемое направление стрелки (например, -r- или -right-), на самом деле, еще и увеличивать ее длину (например --- будет длиннее, чем --). Но, как я писал в статье, у меня не получилось использовать эту функциональность удобно. Пусть уж PlantUML распределяет элементы, как хочет. Я стараюсь влиять на расположение элементов через их группировку, иногда через порядок их указания в спецификации.
Если такое руление стало занимать много времени — надо простой перейти на другой инструмент.
Также есть проблемы с кавычками и многострочностью в define, что ограничивает включение общих файлов в диаграммы разного типа. Тем не менее, вполне можно делать довольно сложные сборки со многими include файлами, без дублирования кода, используя общие блоки с условной сборкой.
Есть одна микросервисная архитектура. Я её нарисовал в graphviz и по честному отобразил все потоки данных к которым я приложил руки за 1.5 года работы; получилось много и страшно. Прежде всего из за циклов и многократного использования одного компонента в разных бизнес-процессах, из за чего он покрывается стрелочками как ёжик иголками.
Хочется следующего: Отразить реально существующие потоки данных на граф, выделить подграфы для каждого бизнес-процесса и иметь возможность смотреть как на отдельный процесс, так и на всю простыню при необходимости.
Т.е. поулчается мультиграф с петлями, где ребра имеют дополнительный признак принадлежности бизнес-процессу. Есть готовоые средства, или придется самому изобретать?
Добавлю к комментарию habradante. Картинки PlantUML можно также объединять при помощи Asciidoctor, тогда у Вас будет прекрасная, хорошо читаемая документация без ежей, которую можно представить и в html, и в pdf.
Я после прочтения этой статьи установил "на попробовать" расширение PlantUML в Visual Studio Code — завелось сразу.
Я нарыл установку сервера на своем железе, такое решение меня больше устраивает.
На сколько я понимаю, конкретно это расширение может рендерить как на сервере, так и локально. Для локальной работы нужны установленные java и graphviz. Для рендера на сервере нужно указать адрес сервера, можно своего. Я пробовал локальную обработку.
Речь о расширении https://marketplace.visualstudio.com/items?itemName=jebbs.plantuml
Сам сейчас, подготавливаю материалы для презентации в нашей группе разработке, о ведении технической документации для проекта. (asciidoc + plantuml)
Да, этот инструмент, простоват. И на нем не опишешь всю систему, все аспекты моделей, и динамическое обновление всех и вся. Но ведь он и не для этого.
Собственно, вот на текущем проекте, не хватает, каких-то таких простых вещей, общей картины не видно. Что и зачем куда там переходит. Нужны наброски, черновики. Да просто общий смысл нужен.
Вот для этого, это всё подходит хорошо.
Сам подумываю над использованием Eclipse Papyrus. Это мощная… (штука) для ведения моделей, чуть ли не с синхронизацией с кодом. И если есть опыт использования, или как начать, я бы почитал. Но это штука не для описания тех.документации, т.е. наверное ее картинки можно использовать, но она более мощный инструмент. Но однако тоже интересный.
Да, этот инструмент, простоват. И на нем не опишешь всю систему, все аспекты моделей, и динамическое обновление всех и вся. Но ведь он и не для этого.
Можно описать всю систему. Можно настроить автоматическую генерацию документации по моделям и ее выгрузку в нужное место.
Сам сейчас, подготавливаю материалы для презентации в нашей группе разработке, о ведении технической документации для проекта. (asciidoc + plantuml)
Перевел всю тех документацию по актуальным проектам на эту схему года 3 — 4 назад. Если не ударяться в дизайн схем (хотя он вроде бы настраиваемый), то инструмента вполне достаточно для работы.
Несомненно, отдельное веселье собирать для документации прилично выглядящий pdf, но это тема большой и очень нецензурной статьи.
На всякий случай добавлю, что с использованием плагина для asciidoc код plantuml можно писать прямо в тексте документации (а не генерить картинки отдельно и вставлять ссылками, как делает автор поста)
А подготавливаю материалы, для мотивации сотрудников использовать вот такой подход, для документирования, своих «брильянтовых» идей.
Потому, что, проект тут огромен, использует нецензурное_слово всякого. И соответственно, почему это было так сделано, кто-то помнит, а кто-то уволился давно.
Вариант искать в Jira или в коммитах, как-то, сильно неудобно, а да, а еще есть просто .doc файлы, с ТЗ.
Очень неудобно…
Вот и хочу показать ребятам: «смотрите как здорово!? вам этого не хватало! давайте так же делать!!!»
Как только встает вопрос «а давайте сделаем Руководство Пользователя/ТЗ по ГОСТ/любой многостраничный документ с требованием к оформлению и печати» придется идти к оригинальному asciidoc и бекэнду в виде docbook+pdf. А там еще ряд веселья по настройке. pdf, повторюсь, отдельная боль, избегайте ее по возможности в начале:)
На момент годичной давности asciidoctor имел зачатки pdf рендера в виде отдельного модуля, но на что — то большее, чем простой набор страниц, он не был способен.
Если вдруг будут нужны какие — то детали по системе или, может быть, примеры документаций — стучитесь в личку, помогу чем смогу :)
Моё воображение рисует что-то среднее между механизмом обсуждения pull request'ов на гитхабе и комментариями в гуглодоках.
В моем представлении это все — таки функционал контроля версий, а не системы сборки документации.
Что мешает пользоваться // комментариями AsciiDoc прямо в тексте, если речь идёт о ремарках, которые должны быть видимы авторам текста, но не читателям текста?
Действительно, включение PlantUML-диаграмм в текст asciidoc — это удобно. Тут больше говорят мои издательские привычки держать спецификации картинок отдельно от документа.
Code first approach более жизненный — документация никогда не устареет, если автогенерируется. Но с другой стороны накладывает дополнительные ограничения на код и добавляет работы разработчикам. На прошлом проекте генерировал диаграммы последовательности из кода.
:choise one; в один блок, чтобы было красиво? start
if (condition one) then (yes)
:choise one;
else (no)
if (condition two) then (no)
:choise one;
elseif (condition three) then (blank)
:choise one;
else (filled)
:choise two;
endif
endif
stop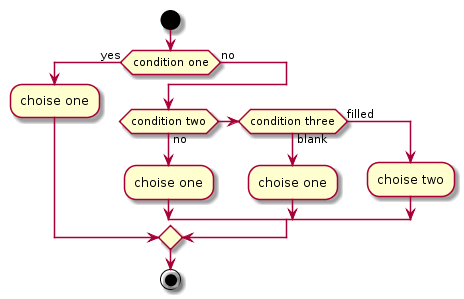
Диаграммы деятельности, мне кажется, надо стараться делать попроще, избегая больших ветвлений, и, в любом случае, подписи на этой диаграмме не совсем ей соответствуют. Но разные есть случаи, предположим надо так
Мой подход был бы следующем
skinparam defaultTextAlignment center
start
if (condition one) then (no)
if (condition two) then (yes)
if (condition three) then (filled)
:choice two;
(A)
detach
else (blank)
endif
else (no)
endif
else (yes )
endif
label l1
:choice one;
(B)
detach
if () then
(A)
else ()
(B)
endif
stopВместо detach можно сразу поставить stop. Именно в этом примере нижний аппендицит, конечно, не нужен. Но в общем случае можно действовать именно так.

Опять же, в данном конкретном случае можно нарушить все нотации и сделать вот так:
skinparam rectangle {
roundCorner 0
roundCorner<<outcome>> 25
}
!define ICONURL https://raw.githubusercontent.com/tupadr3/plantuml-icon-font-sprites/v2.0.0
!includeurl ICONURL/common.puml
!includeurl ICONURL/font-awesome-5/question_circle.puml
!includeurl ICONURL/font-awesome-5/check_circle.puml
!define _CS scale=0.4
!define _qc <$question_circle{_CS}>
!define _cc <$check_circle{_CS}>
rectangle "_qc condition one" as cond1
rectangle "_cc choice one" <<outcome>> as ch1
cond1 --> ch1 : yes
rectangle "_qc condition two" as cond2
cond1 --> cond2 : no
cond2 --> ch1 : no
rectangle "_qc condition three" as cond3
cond2 --> cond3 : yes
cond3 --> ch1 : blank
rectangle "_cc choice two" <<outcome>> as ch2
cond3 --> ch2 : filled

В нашем полку любителей plantUML прибывает, это очень приятные новости! Для себя я отмечаю одну непревзойденную особенность этой нотации — можно делать код-ревью сиквенсов и даже более-мене сложных схем в виде простого текста. Представьте себе насколько это просто в виде:
@startuml
[Readable name 1] as RN1
[Readable name 2] as RN2
RN1 -> RN2
RN2 -> RN1
@endumlпротив визуального сравнения тех же схем, нарисованных в Визио. Хотя визиоподобные продукты позволяют делать красивости, это да.
Но и тут можно заморочиться и получить такую, например, картинку:
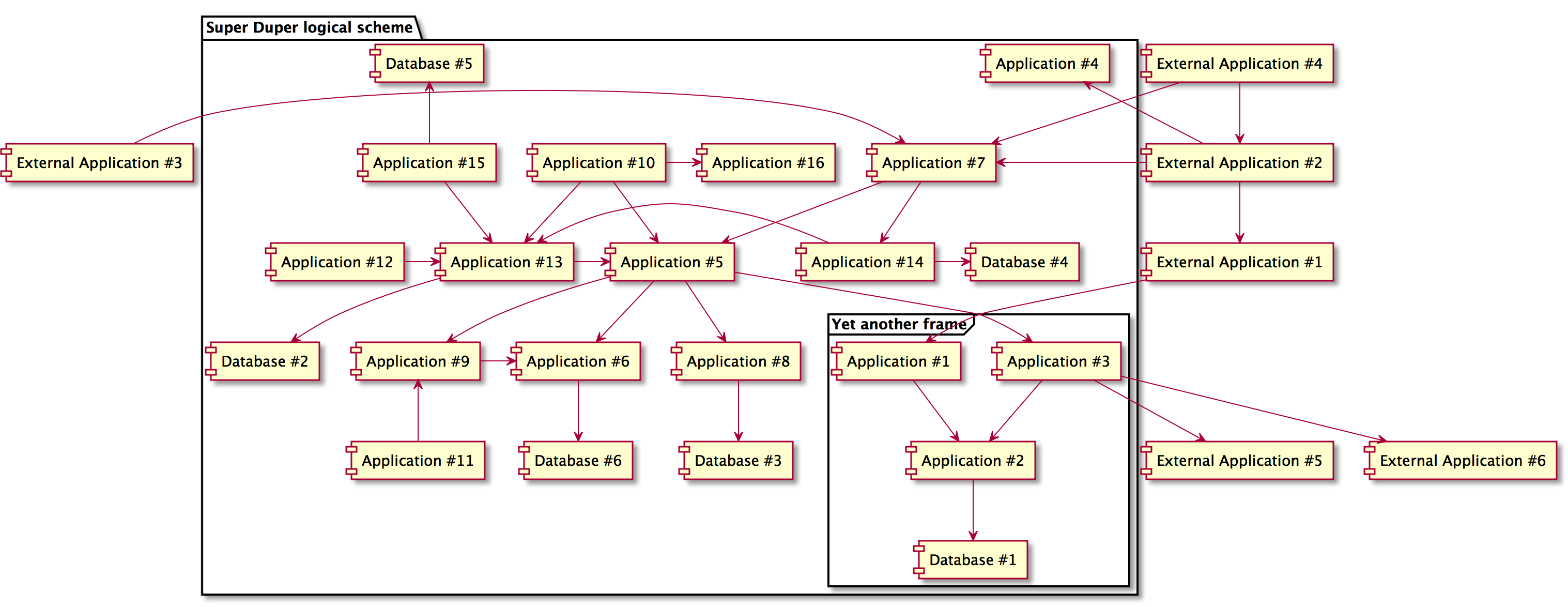
Посмотрите как эта схема выглядит исходном виде: https://github.com/antonlva/platinum-toolset/blob/master/docs/wsd/super-duper.wsd
Кстати, возможно кому-то будет полезен тулсет, который в любой линуксовой среде позволит быстро и удобно генерировать подобные картинки. Она доступна для свободного использования в https://github.com/rbkmoney/plantuml-toolset.
Помогает прям из ИДЕИ редактировать и смотреть результат. А ещё есть бесплатный плагин к confluence.
Ну и весьма удобно хранить рядом с кодом диаграммы, особенно когда описываешь state-machine.
Спасибо, PlantUML очень понравился! До этого рисовал sequence диаграммы в draw.io, в PlantUML создавать их на порядок быстрее!
Вот кстати хороий ресурс с реальными примерами использования PlantUML Вроде не видел этой ссылки здесь.
real-world-plantuml.com
PlantUML — все, что нужно бизнес-аналитику для создания диаграмм в программной документации