Comments 48
Не могу разместить ссылку на PDF документ со сводной таблицей, я еще маленький для этого?
Юзаю ZFS дома в самопальном NAS довольно давно.
На RAID-Z1 из 4 низкооборотных дисков при даже не сильно активной работе торрент-клиента пользоваться NAS практически нереально — I/O Wait 100% одного ядра, куча IOPS на диски.
Особых бенчмарков не проводил, но когда аналогичный NAS был на RAID-5/XFS подобных проблем не возникало.
На RAID-Z1 из 4 низкооборотных дисков при даже не сильно активной работе торрент-клиента пользоваться NAS практически нереально — I/O Wait 100% одного ядра, куча IOPS на диски.
Особых бенчмарков не проводил, но когда аналогичный NAS был на RAID-5/XFS подобных проблем не возникало.
Это из за ARC кэша, он очень любит ОЗУ. Тюнить при отсутствии хотя-бы 8ГБ ОЗУ на системе, неблагодарное занятие. Всё-таки ФС расчитана на суровый энтерпрайз. У меня дома ZFS RAID-10 на 6 дисках (3 зеркала), и ОЗУ на компе 64ГБ, вобщем тюнить даже не тянет.
ОЗУ 8Гб на текущем NAS, кеши не тюнил. Кроме ZFS там память никто не жрет особо.
Текущий объем ARC 1.8Gb, может стоит разрешить ему кушать побольше чем 25%.
До этого имел долгий опыт жизни с «NAS» из 10 7.2k SATA дисков в RAID-Z2 при 256Gb RAM (такой вот франкенштейн), по дурости думал что такой объем памяти мне позволит сделать дедупликацию без снижения производительности… угу, щас. Удаление большого файла вызывало дикие локапы всей системы. Когда ее убрал — стало по-божески, но это 256Гб все таки.
Текущий объем ARC 1.8Gb, может стоит разрешить ему кушать побольше чем 25%.
До этого имел долгий опыт жизни с «NAS» из 10 7.2k SATA дисков в RAID-Z2 при 256Gb RAM (такой вот франкенштейн), по дурости думал что такой объем памяти мне позволит сделать дедупликацию без снижения производительности… угу, щас. Удаление большого файла вызывало дикие локапы всей системы. Когда ее убрал — стало по-божески, но это 256Гб все таки.
А зачем на файлопомойке урезать ARC? Мне для общего развития… На Linux я его подрезал до 75% исключительно из-за того, что он (linux) иногда начинает драться с ZFS за память. Если их растащить таким способом, всё становится нормально (debian 7, давно дело было). Но до 25% это террор, особенно если учесть, что ARC сильно продвинутее чем кеш ОС.
А я не ограничивал, все по дефолту.
Он, насколько я помню, лимитируется в 50% RAM если zfs_arc_max=0.
Почему он у меня меньше 50% — хз, возможно сдувается под давлением обстоятельств :) На глаз 25% как раз.
Он, насколько я помню, лимитируется в 50% RAM если zfs_arc_max=0.
Почему он у меня меньше 50% — хз, возможно сдувается под давлением обстоятельств :) На глаз 25% как раз.
Просто ему нечего кешировать, всё нормально =)))
Возможно. Запустил торренты, посмотрим раздует ли и до каких пределов.
так не бывает ) после первый же отгруженного в Torrent фильма ARC должен занять явно больше 2 ГБ… Главный профит ARC — хранение метаданных файловой системы. Ну и чтение, разумеется. Если объём памяти ограничен — атрибут primarycache=metadata для ФС должен помочь. Содержимое самих файлов не будет вымывать из кэша структуру, соотв, ZFS всегда знает, где лежит тот или иной блок и куда положить новый.
Это у вас дома такие франкенштейны обитают?
Живу на 4 Гигах на машине с второй корой дуба (Core2 Duo) диски на родном контроллере чипсета. Всё в норме, память оно жрёт, но если нужно отпускает. Правда есть некоторый чит, живу я на FreeBSD. ZFS может работать и с 2-я гигами памяти, весь вопрос в том, что при меньшем количестве памяти, будут больше работать диски. 8 Гигов — это для файлопомойки достаточно много, если при этом диски не в raidz и их не много, смысла в этом большого нет ИМХО.
Что-то пошло не так, ZFS использует deadline в качестве планировщика и никогда не кладёт диски в полку на 100%. Может подтормаживать ввод-вывод, но совсем капец наступить не должен. Отзывчивость чтения должна быть на уровне. Можно попробовать recordsize увеличить, если включён large_blocks `zfs get feature@large_blocks $dataset_name` то можно поставить 1 Мбайт. Это уменьшит количество запросов блоков (в среднем один блок в торрентах где-то 1-4 Мбайта) и разгрузит очередь. Но у меня ZFS диски не ложил. XFS легко, EXT4 — это его нормальное состояние, ZFS никогда.
У меня отдельный ZFS датасет под торренты с блоком в 16к по рекомендации лучших собаководов отсюда: www.open-zfs.org/wiki/Performance_tuning#Bit_Torrent
И когда работают торренты у меня стандартно 20-30% I/O wait (из 4 ядер), вот скрин из заббикса:
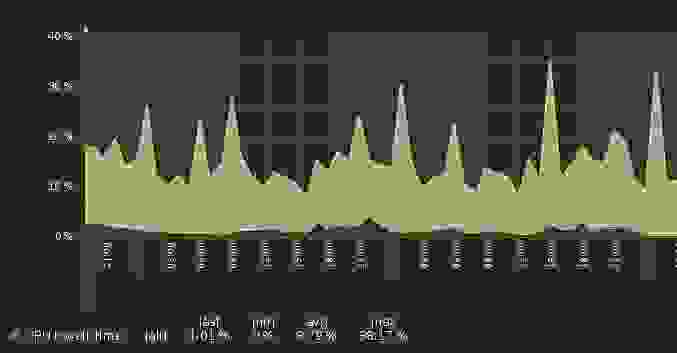
OS Ubuntu 16, ZoL последний, диски HGST какие-то около 5-6к оборотов.
И когда работают торренты у меня стандартно 20-30% I/O wait (из 4 ядер), вот скрин из заббикса:
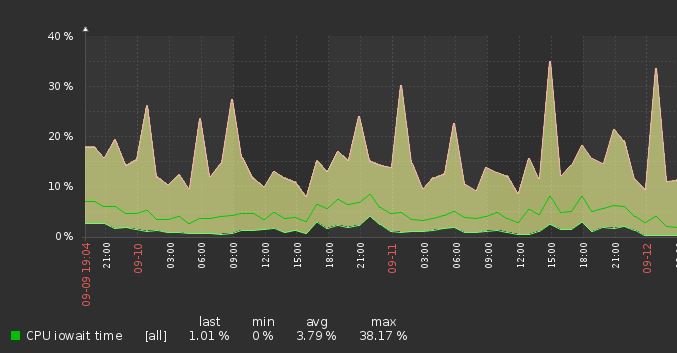
OS Ubuntu 16, ZoL последний, диски HGST какие-то около 5-6к оборотов.
1 блок торрента в среднем 1 мегабайт, для отдачи одного блока в очередь попадает 1024/16 команд на загрузку данных. И получается советская очередь за молоком. Лучше увеличить по среднему размеру блока в торрентах.
Возможно, я не вдумывался, сделал как в доках сказано. Погляжу статистику I/O — какие размеры операций идут. Спасибо.
Помониторил:
Судя по этим данным средний размер I/O 46400/2385=19.4 килобайта, что примерно соответствует моему размеру блока в 16k.
Так что, по крайней мере мой transmission, не читает блоками по 1М.
# zpool iostat 10
capacity operations bandwidth
pool alloc free read write read write
---------- ----- ----- ----- ----- ----- -----
bkp 799G 1.94T 0 0 0 0
zfs 5.95T 4.61T 799 0 14.0M 0
---------- ----- ----- ----- ----- ----- -----
bkp 799G 1.94T 0 0 0 0
zfs 5.95T 4.61T 773 0 15.3M 0
---------- ----- ----- ----- ----- ----- -----
bkp 799G 1.94T 0 0 0 0
zfs 5.95T 4.61T 813 0 17.1M 0
---------- ----- ----- ----- ----- ----- -----
Судя по этим данным средний размер I/O 46400/2385=19.4 килобайта, что примерно соответствует моему размеру блока в 16k.
Так что, по крайней мере мой transmission, не читает блоками по 1М.
Он читает блоками, если блок 16, он читает 16. При изменении размера блока, все новые файлы будут писаться на новый размер, тогда может быть выигрыш. Я размер блока посмотрел в статистике своего клиента глазами, может более суровое исследование даст лучший результат. Но кажется что мегабайт будет нормально, тем более, что больше вроде пока нельзя, да и мегабайт можно только с соответствующей опцией.
Я смотрел видео, где человек рассказывал о использовании ZFS на серверах раздачи видеоконтента, и он сильно агитировал за больший размер блока.
Я смотрел видео, где человек рассказывал о использовании ZFS на серверах раздачи видеоконтента, и он сильно агитировал за больший размер блока.
Проблема в том, что если блок ФС 1М, а блок торрента 16к, то запись блоков по 16к будет вызывать read-modify-write всего 1М блока (для пересчета контрольной суммы, разливания по RAID-Z и т.п.). Поэтому я не уверен что это не ухудшит дела, хотя стоит проверить.
zpool все таки показывает что чтение идет блоками в районе 20к, а не 1М. Попробую посмотреть при записи что происходит.
zpool все таки показывает что чтение идет блоками в районе 20к, а не 1М. Попробую посмотреть при записи что происходит.
Очень странно видеть сравнение не со схожей конфигурацией под управлением mdraid, а одним диском под XFS.
Непонятно также почему выбран Virtio-Block, хотя прокс рекомендует Virtio-Scsi. Ну и цифры эти они о погоде на луне, я раньше тоже так тестил. Имхо если ставим гипервизор, то наверное будет несколько виртуалок, иначе какой смысл в прослойке, если будет несколько виртуалок, то картинка может сильно поменяться, поэтому таких тестов и нету, желательно тестить c помощью fio непосредственно на хосте гипервизора.
Непонятно также почему выбран Virtio-Block, хотя прокс рекомендует Virtio-Scsi
Мне в данный момент тоже непонятно почему я такой выбор сделал )
то наверное будет несколько виртуалок, иначе какой смысл в прослойке
ну зная скорость на одной можно сделать некоторые выводы, мне хотелось понять именно разницу в скорости между этими реализациями
желательно тестить c помощью fio непосредственно на хосте
ну меня в этих тестах интересовало что именно дойдет до виртуалки.
Вот для сравнения, да простят меня все линуксоиды, сравнительный тест в среде MS
Гипервизор (не Hyper-V) на Server 2016 (это уже на другой железке тесты)
SOFT RAID 5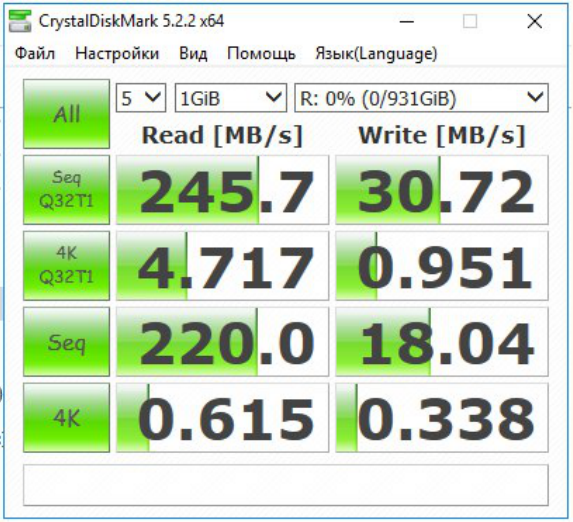
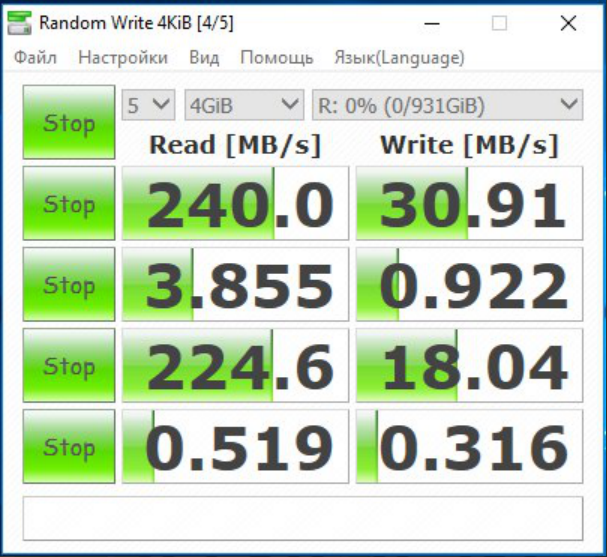

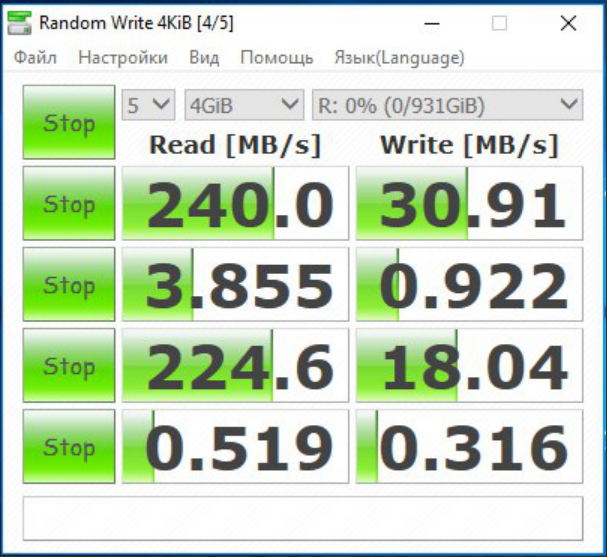
И то что доходит до виртуальной машины на WS 2008 R2
VirtualBox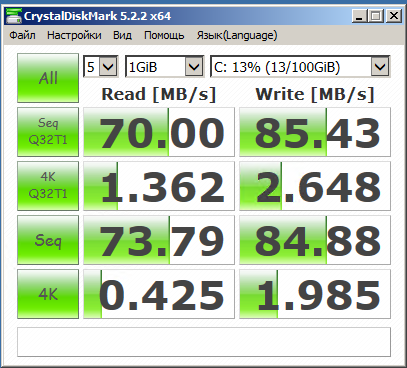
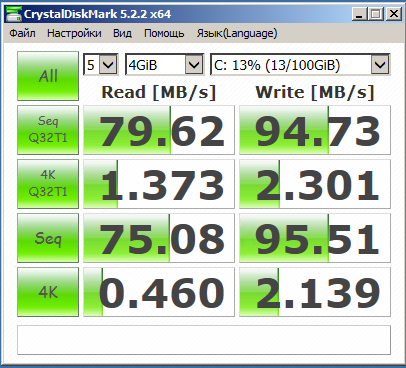


Непонятно также почему выбран Virtio-Block, хотя прокс рекомендует Virtio-Scsi.Именно в вопросе производительности это не сильно важно. Proxmox рекомендует virtio-scsi скорее из-за большего количества функций (полноценное scsi устройство, поддержка blkdiscard, масштабируемость и т.д.) при примерно той же производительности (при некоторых паттернах нагрузки она хуже из-за большего количества прослоек).
ну меня в этих тестах интересовало что именно дойдет до виртуалки.
100% практически и дойдет, именно в этом цель virtio драйверов.
Вот для сравнения, да простят меня все линуксоиды, сравнительный тест в среде MS
Гипервизор (не Hyper-V) на Server 2016 (это уже на другой железке тесты)
Вы же понимаете что так не бывает и где-то в тестах косяк? Если на физ. машине действительно запись всего 30 МБ/с, то на виртуалке ну никак 85 не будет. Имхо вы просто не пробили тут кеш 1 гиговым файлом.
Также хотелось бы подробностей, вы написали что для кеша использовали SSD, как L2Arc? А то там можно еще SSD подключить как Zil, тогда еще и запись ускорится.
В большей степени были бы полезнее iops'ы а не скорость чтения/записи
А IOPS-ы от шпинделей. Выше производительности дисков не прыгнешь.
Не всё так однозначно, если учесть сколько всего ФС пихает в память и ARC/ZIL. Тестировал при помощи утилиты ioping на VM-ках и цифры на ZFS всегда были на порядок выше. Например если на ufs/ext3/ext4 ~2k, то на ZFS ~70-80k. Шпинделя были одни и те же.
C методикой тестирования действительно надо бы определиться что бы не сравнивать разрозненные величины. Для меня это так и осталось открытым вопросом.
C методикой тестирования действительно надо бы определиться что бы не сравнивать разрозненные величины. Для меня это так и осталось открытым вопросом.
Если читающим это действительно интересно, напишите какие тесты провести, что замерять. Сейчас на некоторое время есть свободная железка, правда с более слабым конфигом (C2D, 6GB RAM и тот же набор дисков).
Из статьи и из моего опыта можно сделать грустный вывод. Сколько дисков zfs не дай, а скорость записи будет просто смешной. Да и xfs в вашей виртуалке в 100мб/сек — тоже отстой. В ntfs win эти диски могут показывать более 180мб/сек, верно?
Сейчас под рукой нет результатов тестов на одиночных дисках, а результаты RAID5 приводил чуть выше,
Сколько дисков zfs не дай, а скорость записи будет просто смешной.
Вот тут я думаю ваш вывод абсолютно верный! И исходя из целей и задач виртуализированных ОС для кого-то ZFS не будет иметь никакого смысла. В ближайшей перспективе хочу провести сравнение с mdadm.
XFS для Proxmox вроде не самая дефолтная ФС, там же Debian в основе, и дефолтом шла и имет ext3/ext4. Вы их не меряли?
И вот каком момент: когда речь заходит о ext4 (или xfs, как вы взяли), обычно говорят о томе RAID (ставить гипервизор не на резервированное хранилище довольно смело, и так делают только под очень узкие задачи), так вот RAID с батарейкой, а особенно с SSD-кешем, может существенно повлиять на результаты — в таком варианте не замеряли?
И ZFS — какие настройки по памяти делали? ОС хоста, гипервизор и сами ОЗУ потребляют, да еще ZFS умеет любит ОЗУ использовать — так вот какими настроками/мануалами пользовались для тюнинга?
И вот каком момент: когда речь заходит о ext4 (или xfs, как вы взяли), обычно говорят о томе RAID (ставить гипервизор не на резервированное хранилище довольно смело, и так делают только под очень узкие задачи), так вот RAID с батарейкой, а особенно с SSD-кешем, может существенно повлиять на результаты — в таком варианте не замеряли?
И ZFS — какие настройки по памяти делали? ОС хоста, гипервизор и сами ОЗУ потребляют, да еще ZFS умеет любит ОЗУ использовать — так вот какими настроками/мануалами пользовались для тюнинга?
Ну как так-то?
Почему в случае с включенным кэшем мы получаем производительность сильно ниже, даже на мелких 4 и 1 гб файлах. Сравните ZFS Raid1 и Raid1 + кеш.
Почему в случае с включенным кэшем мы получаем производительность сильно ниже, даже на мелких 4 и 1 гб файлах. Сравните ZFS Raid1 и Raid1 + кеш.
По теме рекомендую почитать также труды вот этого чела:
jrs-s.net/2013/05/17/kvm-io-benchmarking
jrs-s.net/2018/03/13/zvol-vs-qcow2-with-kvm
Очень познавательно.
jrs-s.net/2013/05/17/kvm-io-benchmarking
jrs-s.net/2018/03/13/zvol-vs-qcow2-with-kvm
Очень познавательно.
Десятикратный прирост производительности на ZFS vs XFS? Можно, я просто не поверю? Это либо прогретые кеши, либо writeback.
Каждый раз, когда мне пытаются продать увеличение производительности диска в 10 раз, я обнаруживаю внутри writeback. Иногда с игнором flush'ей.
Каждый раз, когда мне пытаются продать увеличение производительности диска в 10 раз, я обнаруживаю внутри writeback. Иногда с игнором flush'ей.
Sign up to leave a comment.
ZFS и скорость доступа к диску в гипервизорах