
Вступление
В рамках программы кредитования банк сотрудничает со многими розничными магазинами.
Одним из ключевых элементов заявки на кредит является фотография заемщика – агент магазина-партнера фотографирует покупателя; такая фотография попадает в «личное дело» клиента и используется в дальнейшем как один из способов подтверждения его присутствия на точке в момент подачи заявки на кредит.
К сожалению, всегда существует риск недобросовестного поведения агента, который может передавать в банк недостоверные фотографии – например, снимки клиентов из социальных сетей или паспорта.
Обычно банки решают эту задачу с помощью верификации фотографии – сотрудники офиса просматривают фотографии и пытаются выявить недостоверные изображения.
Мы захотели попробовать автоматизировать процесс и решить задачу с помощью нейросетей.
Формализация задачи
Мы исследовали только фотографии, на которых есть люди. Отсечь посторонние снимки без лиц можно с помощью открытой библиотеки Dlib.
Для наглядности приведем примеры фотографий (на снимках сотрудники банка):

Рис 1. Фото с точки продажи

Рис 2. Фото с соцсетей

Рис 3. Фото паспорта
Итак, нам нужно было написать анализирующую фон фотографии модель. Результатом ее работы должно было стать определение вероятности того, что фото сделано в одной из точек продаж наших партнеров. Мы определили три способа решения этой задачи: сегментация, сравнение с другими фото в той же точке продажи, классификация. Рассмотрим каждый из них подробнее.
А) Сегментация
Первое, что пришло в голову – решать эту задачу сегментацией изображения, определяя области с фоном магазинов-партнеров.
Минусы:
- Подготовка обучающей выборки занимает слишком много времени.
- Построенный на такой модели сервис не будет быстро работать.
Было решено вернуться к этому методу только в случае отказа от альтернативных вариантов. Спойлер: не вернулись.
Б) Сравнение с другими фото в той же точке продажи
Вместе с фотографией к нам поступает информация о том, в каком именно розничном магазине она была сделана. То есть мы имеем группы снимков, сделанных в одинаковых точках продаж. Общее количество фотографий в каждой группе варьируется от нескольких единиц до нескольких тысяч.
Появилась еще одна идея: построить модель, которая будет сравнивать две фотографии и предсказывать вероятность того, что они были сделаны в одной точке продажи. Тогда новую полученную фотографию мы сможем сравнить с имеющимися фотографиями в том же магазине. Если она окажется похожа на них, значит снимок точно достоверный. Если же снимок выбивается из общей картины, мы дополнительно отправляем его на ручную проверку.
Минусы:
- Несбалансированная выборка.
- Сервис будет долго работать, если в точке продажи много фотографий.
- При появлении новой точки продажи нужно переобучать модель.
Несмотря на минусы, мы реализовали модель из статьи, использовав блоки нейросетей VGG-16 и ResNet-50. И… получили процент правильных ответов не сильно выше 50% в обоих случаях :(
В) Классификация!
Самой заманчивой была идея сделать простой классификатор, который будет делить фотографии на 3 группы: фото с точек продаж, с паспортов и из соцсетей. Осталось только проверить, сработает ли этот подход. Ну и еще потратить немного времени на подготовку данных для обучения.
Подготовка данных
В датасете изображений из соцсетей с помощью библиотеки Dlib выбрали только те фото, на которых есть люди.
Снимки паспортов необходимо было по-разному обрезать, оставив только лицо. Тут на помощь снова пришла Dlib. Принцип работы получился таким: нашли с помощью этой библиотеки координаты лица -> обрезали фото паспорта, оставляя лицо.
В каждом из 3 классов оставили по 40 000 фото. Не забыли и про аугментацию данных
Модель
Использовали ResNet-50. Решали проблему как задачу многоклассовой классификации с непересекающимися классами. То есть считали, что фото может принадлежать только одному классу.
model = keras.applications.resnet50.ResNet50()
model.layers.pop()
for layer in model.layers:
layer.trainable=True
last = model.layers[-1].output
x = Dense(3, activation="softmax")(last)
resnet50_1 = Model(model.input, x)
resnet50_1.compile(optimizer=Adam(lr=0.00001), loss='categorical_crossentropy', metrics=[ 'accuracy'])
Результаты
В тестовой выборке оставили 24 000 картинок, то есть 20%. Матрица ошибок выглядела следующим образом:
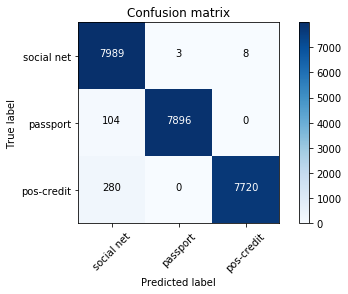
social net — соцсети;
passport — паспорта;
pos-credit – точки продаж-партнеры, которые осуществляют кредитование.
Общий процент ошибок – 1,6 %, для фотографий с точек продаж – 1,2 %. Большая часть ошибочно определенных снимков – похожие на два класса одновременно изображения. Например, почти все неверно определенные фотографии из класса pos-credit были сделаны в неудачных ракурсах (на фоне белой стены, видно только лицо). Поэтому они были похожи еще и на фото из класса social net. Такие фотографии имели низкую максимальную вероятность.
Мы добавили порог для максимальной вероятности. Если итоговое значение оказывается выше – мы доверяем классификатору, ниже – отправляем картинку на ручную проверку.
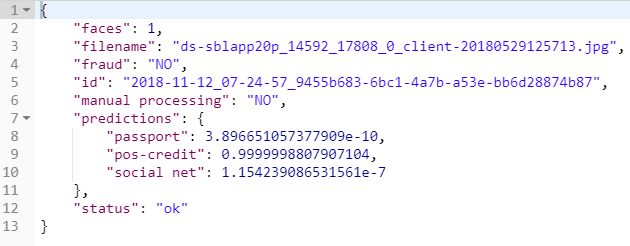
В итоге, результат работы сервиса для фотографии

выглядит следующим образом:
Итоги
Так, с помощью простой модели мы научились автоматически определять, что фотография сделана в одной из точек продаж наших партнеров. Это позволило автоматизировать часть большого процесса по одобрению заявки на кредит.
