Comments 27
Большая и очень полезная работа была проделана.
Огромное вам спасибо!
большое вам спасибо за работу, но на мой взгляд NC в лицензии было сделано зря, есть множество компаний, которые бы хотели использовать этот датасет, но теперь не имеют возможности
Про коммерческое использование.
Смотрели этот датасет. Он, конечно же, прекрасен и автор большой молодец (помню он как-то писал мне год назад, я шерил на канале их сбор народа на крауд), но вот одна беда — даже имея иерархию предметной области, использовать это в своем домене — ну почти нереально.
Разве что только датасет с эмоциями для каких-то «ручных» алгоритмов (без обучения).
Почему? Поясню на примере.
Вот есть слово ноготь. Это физический объект. Но вот в бизнесе это будет некий атом некой услуги. И как использовать это напрямую — непонятно =(
Смотрели этот датасет. Он, конечно же, прекрасен и автор большой молодец (помню он как-то писал мне год назад, я шерил на канале их сбор народа на крауд), но вот одна беда — даже имея иерархию предметной области, использовать это в своем домене — ну почти нереально.
Разве что только датасет с эмоциями для каких-то «ручных» алгоритмов (без обучения).
Почему? Поясню на примере.
Вот есть слово ноготь. Это физический объект. Но вот в бизнесе это будет некий атом некой услуги. И как использовать это напрямую — непонятно =(
Здравствуйте, помню вас. Спасибо, что помогали шером и распространением информации!
Что касается применимости. Познание внутренней структуры языка — это путь. И он не обещает быть ни простым, ни коротким. Сейчас мы пытаемся переложить тот пласт лингвистических исследований (в первую очередь когнитивистов), которые были сделаны в последние 50 лет, на современные технологические рельсы.
Опять же, какими бы ни были коммерческие процессы — это всегда взаимодействие субъектов, объектов (assets) и процессов. Возможность их эффективно вычленять из потока текстовой информации, отделять общеязыковые, каркасные единицы от тематических, специализированных и строить модели поверх более высокоуровневых, чем слова или символы объектов — чем не задача.
Это на перспективу. Программа минимум сейчас — обогатить предельно грубую частеречную разметку инвариантной семантикой и посмотреть, насколько это поможет существующим алгоритмам. Только так, маленькими шажочками и кропотливой работой, придём к качественному результату. Волшебной пилюли здесь нет.
Что касается применимости. Познание внутренней структуры языка — это путь. И он не обещает быть ни простым, ни коротким. Сейчас мы пытаемся переложить тот пласт лингвистических исследований (в первую очередь когнитивистов), которые были сделаны в последние 50 лет, на современные технологические рельсы.
Опять же, какими бы ни были коммерческие процессы — это всегда взаимодействие субъектов, объектов (assets) и процессов. Возможность их эффективно вычленять из потока текстовой информации, отделять общеязыковые, каркасные единицы от тематических, специализированных и строить модели поверх более высокоуровневых, чем слова или символы объектов — чем не задача.
Это на перспективу. Программа минимум сейчас — обогатить предельно грубую частеречную разметку инвариантной семантикой и посмотреть, насколько это поможет существующим алгоритмам. Только так, маленькими шажочками и кропотливой работой, придём к качественному результату. Волшебной пилюли здесь нет.
Ну что тут сказать.
В плане есть работа с чатами на разметки по типу SQUAD.
Если дойдем до этого, подадим разметку из PyMorphy и ваши теги отдельным каналом, заценим точность) Может тот факт, что холодильник это контейнер в квартире поможет. Но наверное, придется разметить и оставить только нужные теги.
Но это все, конечно же, все неточно и subject to популяции кроликов в Австралии =)
В плане есть работа с чатами на разметки по типу SQUAD.
Если дойдем до этого, подадим разметку из PyMorphy и ваши теги отдельным каналом, заценим точность) Может тот факт, что холодильник это контейнер в квартире поможет. Но наверное, придется разметить и оставить только нужные теги.
Но это все, конечно же, все неточно и subject to популяции кроликов в Австралии =)
Мы всецело заинтересованы в том, чтобы данные использовались максимально широко, а не пылились на ГХ. Но когда мы запускали проект были не вполне ясны его перспективы и потенциал для научных и коммерческих применений, поэтому выбрали наиболее строгий вариант лицензии — взять время на подумать, посмотреть что к чему и решить, решить куда хотим развиваться дальше.
Сейчас пришли к пониманию того, что лицензию через какое-то время можно будет сделать более свободной. При этом данные для коммерческих организаций можно получить уже сейчас: достаточно написать на kartaslov@mail.ru с описанием кейса или примерных целей использования и мы отправим своё согласие на использование.
Сейчас пришли к пониманию того, что лицензию через какое-то время можно будет сделать более свободной. При этом данные для коммерческих организаций можно получить уже сейчас: достаточно написать на kartaslov@mail.ru с описанием кейса или примерных целей использования и мы отправим своё согласие на использование.
Хабр ТОРТ! Статья — огонь!
Вопрос по поводу
Не понятно почему эти ошибки по-вашему неустранимы.
Можно же изначально считать каждый семантический атом неоднозначно связанным с набором его лексических представлений. Тогда употребление омонимов в тексте будет вызывать смысловое ветвление, но у каждой такой веточки будет свой кумулятивный вес. Если среди взвешенных семантических веток есть ярко выраженный лидер, то его можно брать как основную гипотезу, иначе у нас просто несколько разновероятных смыслов. И с этим нужно работать.
Дополню. Вообще вся это онтологическая и семантическая кухня в натуральных языках, как мне кажется, здорово ложится на язык Пролог. Такое ощущение, что уже сейчас вашу БД можно сконвертировать в большую базу предикатов и атомов, а потом играться с ней выявляя интересные закономрености.
Вопрос по поводу
- Омонимия и полисемия: слова, имеющие одинаковое начертание, могут иметь разное значение (мука и мука, остановка как процесс и остановка как локация). Сюда же можно отнести метафорическое употребление слов и метонимию (например дверь будет классифицирована как замкнутое пространство — это ожидаемая особенность языка).
- Несбалансированность контекстов употребления слова. Некоторые органичные употребления могут отсутствовать в исходном корпусе, приводя к ошибкам при классификации.
[..]
Ошибки первых двух типов в заданной конфигурации системы неустранимы
Не понятно почему эти ошибки по-вашему неустранимы.
Можно же изначально считать каждый семантический атом неоднозначно связанным с набором его лексических представлений. Тогда употребление омонимов в тексте будет вызывать смысловое ветвление, но у каждой такой веточки будет свой кумулятивный вес. Если среди взвешенных семантических веток есть ярко выраженный лидер, то его можно брать как основную гипотезу, иначе у нас просто несколько разновероятных смыслов. И с этим нужно работать.
Дополню. Вообще вся это онтологическая и семантическая кухня в натуральных языках, как мне кажется, здорово ложится на язык Пролог. Такое ощущение, что уже сейчас вашу БД можно сконвертировать в большую базу предикатов и атомов, а потом играться с ней выявляя интересные закономрености.
Они устранимы и мы будем с ними работать, просто сейчас стоит другая задача. Нет никакого смысла размечать отдельные слова или даже отдельные значения — как потом такую разметку увязать с конкретным контекстом? Наша задача разметить понятия, концепты словами, примерами, чтобы потом в каждом конкретном случае употребления сказать — оно подходит под этот концепт, маркируем таким-то тегом.
Согласно когнитивным теориям языка оно примерно так и устроено в нашей голове. Т.е. мы примерно понимаем границы явлений и можем с разной степенью уверенности говорить, что та или иная языковая единица подходит под конкретное из них. Но при этом попробуйте сформулировать, что такое «игра» или даже тот же «смысл» — это очень непросто, если вообще возможно. А главное, полученное описание будет совершенно непригодно в качестве инструмента классификации: всё равно проще на примерах показать.
Суть качественного скачка, которое сделало машинное обучение, именно в этом — не объяснять компьютеру в чём отличие кошек от собак, а показать 100 картинок тех и тех, а дальше он сам разберётся. Здесь та же идея, но с языковыми единицами.
Согласно когнитивным теориям языка оно примерно так и устроено в нашей голове. Т.е. мы примерно понимаем границы явлений и можем с разной степенью уверенности говорить, что та или иная языковая единица подходит под конкретное из них. Но при этом попробуйте сформулировать, что такое «игра» или даже тот же «смысл» — это очень непросто, если вообще возможно. А главное, полученное описание будет совершенно непригодно в качестве инструмента классификации: всё равно проще на примерах показать.
Суть качественного скачка, которое сделало машинное обучение, именно в этом — не объяснять компьютеру в чём отличие кошек от собак, а показать 100 картинок тех и тех, а дальше он сам разберётся. Здесь та же идея, но с языковыми единицами.
А никто и не предлагал маркировать изолированные слова. Суть та же, что с картинками. Вы показываете компьютеру размеченый корпус, а он находит в нём закономерности, по некотороым абстрактным шаблонам. Так вы дополнительно можете промаркировать корпус признаками Объекта, Предмета, Контейнера и более сложными. В случае с омонимами как раз вполне разрешимая задача предположить какое из понятий лучше подходит для этого места. И здесь речь не только о словах, но и о выражениях вроде «гореть на работе» или "[глоток] [свежего воздуха]".
Всё верно: можно разметить корпус и дальше использовать подходы, работающие сейчас для предсказания частеречной и морфологической разметки. Другое дело, что синтаксис и морфология хорошо изучены и более-менее понятно, какими классами размечать. Но даже там есть масса сложных случаев, требующих вдумчивости и специальных знаний (можно попробовать сложные задания на opencorpora.org).
Чтобы провернуть такой трюк для семантики нужно найти достоверные классы — это мы и делаем. Другое соображение, что разметив достаточно большое количество слов можно будет попробовать обойтись без необходимости разметки корпуса. Вот, например, контраст физических ёмкостей против предметов:
Вполне себе рабочий семантический TF-IDF.
Чтобы провернуть такой трюк для семантики нужно найти достоверные классы — это мы и делаем. Другое соображение, что разметив достаточно большое количество слов можно будет попробовать обойтись без необходимости разметки корпуса. Вот, например, контраст физических ёмкостей против предметов:
микроконтекст | тип | значение |
| | |
отхлёбывать из | VBP_РОД | 0.9990 |
отпивать из | VBP_РОД | 0.9989 |
окунуть в | VBP_ВИН_НЕОД | 0.9986 |
разлить в | VBP_РОД | 0.9984 |
мадеры | XG_NG | 0.9981 |
лака | XG_NG | 0.9978 |
порционный | ADJ | 0.9978 |
плюхнуться в | VBP_ВИН_НЕОД | 0.9978 |
вариться в | VBP_ПРЕД | 0.9978 |
плескаться в | VBP_ПРЕД | 0.9978 |
плова | XG_NG | 0.9977 |
налитой | ADJ | 0.9976 |
макать в | VBP_ВИН_НЕОД | 0.9976 |
политься в | VBP_ВИН_НЕОД | 0.9975 |
долить в | VBP_ВИН_НЕОД | 0.9975 |
кальвадоса | XG_NG | 0.9974 |
выложить в | VBP_РОД | 0.9974 |
умыться из | VBP_РОД | 0.9973 |
чачи | XG_NG | 0.9973 |
плевать в | VBP_ВИН_НЕОД | 0.9971 |
термоса | XG_NG | 0.9971 |
отлить в | VBP_ВИН_НЕОД | 0.9969 |
чернил | XG_NG | 0.9969 |
разложить в | VBP_РОД | 0.9968 |
процедить в | VBP_ВИН_НЕОД | 0.9968 |Вполне себе рабочий семантический TF-IDF.
С Прологом всё не так просто. Язык, да и мышление в целом, подчиняются нечёткой логике и в словоупотреблении встречается много ситуаций семантического блендинга — смешения в слове нескольких смыслов в неизвестных заранее пропорциях. Причём разные контексты «подсвечивают» разные смыслы в одном слове.
Например: «убрать книгу в рюкзак» — это про свойство быть контейнером, «купить рюкзак» — про свойство быть товаром, «взвалить рюкзак на плечи» — одновременно про свойство быть надеваемым и быть достаточно громоздким, «усесться на рюкзак» — про свойство быть предметом, достаточно твёрдым, чтобы служить сидением. В общем пока такое разнообразие компьютеру скорее не зубам.
Например: «убрать книгу в рюкзак» — это про свойство быть контейнером, «купить рюкзак» — про свойство быть товаром, «взвалить рюкзак на плечи» — одновременно про свойство быть надеваемым и быть достаточно громоздким, «усесться на рюкзак» — про свойство быть предметом, достаточно твёрдым, чтобы служить сидением. В общем пока такое разнообразие компьютеру скорее не зубам.
Ну почему, как раз то, что вы перечислили вполне описывается отдельными правилами и не противоречит друг другу. В статье это, мне показалось, называется не свойствами, а «семантическими ролями», но не суть важно.
Все эти роли могут быть отдельными предикатами или атомами. В качестве атомов они могут быть аргументами предикатов-отношений — это ещё более высокий мета-уровень.
Но я вас кажется понял. В текстах часто встречается не просто смысловая неоднозначность, а двойные и тройные смыслы. Намёки, сарказм, каламбур, ирония… Но и это всё можно разметить. И даже с нечеткой логикой Пролог отлично справляется, если весовые коэффициенты добавить в качестве аргументов.
Хотя согласен, наверно для таких задач пора бы придумать что-то покруче пролога, что-то более заточенное на нечеткую логику, на многозначность и мультиконтекстность.
Да, эзопов язык машины понимать научатся не скоро, но, я надеюсь, они хотя бы научатся в ближайшем будущем сочинять двусмысленные тексты… Надо же что-то новенькое для капчи придумывать.
Все эти роли могут быть отдельными предикатами или атомами. В качестве атомов они могут быть аргументами предикатов-отношений — это ещё более высокий мета-уровень.
Но я вас кажется понял. В текстах часто встречается не просто смысловая неоднозначность, а двойные и тройные смыслы. Намёки, сарказм, каламбур, ирония… Но и это всё можно разметить. И даже с нечеткой логикой Пролог отлично справляется, если весовые коэффициенты добавить в качестве аргументов.
Хотя согласен, наверно для таких задач пора бы придумать что-то покруче пролога, что-то более заточенное на нечеткую логику, на многозначность и мультиконтекстность.
Да, эзопов язык машины понимать научатся не скоро, но, я надеюсь, они хотя бы научатся в ближайшем будущем сочинять двусмысленные тексты… Надо же что-то новенькое для капчи придумывать.
Намёки, сарказм, каламбур, ирония, юмор в целом и метафора — это даже не следующий этап, а где-то очень-очень нескоро. Впрочем у Шелодона Купера тоже с пониманием сарказма не очень, но при этом он вполне себе обладает интеллектом.
Первостепенная задача научить машину понимать прямые, характерные контексты и строить поверх них несложные логические цепочки. А там уже видно будет.
Первостепенная задача научить машину понимать прямые, характерные контексты и строить поверх них несложные логические цепочки. А там уже видно будет.
Вообще в контексте стремительно развивающегося направления всяких голосовых помощников и чат-ботов ваши разработки кажутся чутовищно актуальными. Потребность в них как никогда высока.
Теперь мне уже не кажутся недостижимо далёкими перспективы работы с языковой семантикой на полностью автоматическом уровне, как это, к примеру, красочно описал Юдковскй в своём "Тройном Контакте".
Теперь мне уже не кажутся недостижимо далёкими перспективы работы с языковой семантикой на полностью автоматическом уровне, как это, к примеру, красочно описал Юдковскй в своём "Тройном Контакте".
Хорошо, что кто-то этим занимается, правильно. Пока мы очень отстаем в сентимент анализе, его по сути нет для русского языка. Нельзя даже бота-модератора написать, даже на платном софте, для русского языка.
1) Я не очень понимаю, почему вы называете это лишь «семантикой», так как, если я правильно понял, в основном у вас ловятся синтактико-семантические отношения, но слово «синтаксис» у вас ни разу за статью даже не упоминается. Да и вообще, именно «семантика» — это про энциклопедические знания, которые вы признаёте трудными для автоматического сбора, а вот «синтаксис» — он про сочетание слов друг с другом в рамках предложения, и это как раз то, что вы ловите! Далее, часть из этих классов уже даже помечена в морфо-синтаксических словарях, скажем, взятая вами для примера одушевлённость, нужная, чтобы отличать «бегуна» от «бега» — а одушевлённость нужно отмечать в морфологических словарях, потому что винительный падеж множественного числа образуется для них по-разному: вижу бегунов/атлетов vs нет бегунов/атлетов, вижу бега/черчения vs нет бегов/черчений.
2) Вы, наверное, удивитесь, но word2vec имеет встроенную кластеризацию, которая даже из коробки неплохо ловит подобные синтаксическо-семантические классы. Можно и дальше развивать данную идею.
Подскажу, как сделать, чтобы word2vec ещё лучше выделял подобные классы: нужно его тренировать на нелемматизированном корпусе, тогда синтаксические падежные отношения подберут большую часть ваших классов для существительных, но заодно выделят ещё и классы на глаголах, прилагательных, числительных, наречиях. Поэтому мне очень не нравится ваше объяснение вида «word2vec такого не может, поэтому нам пришлось долго и мучительно изобретать своё решение» — увы, боюсь, он про «мы не смогли сделать». Пройдите теперь чуть дальше: нелемматизированный word2vec внутри делает ровно то же самое, что делает ваш самописный алгоритм сравнения гистограмм распределений, и сработает даже на неразмеченном корпусе, может, будет лишь чуть-чуть более шумным.
3) Для решения более глобальных планов ваша идея с семантическим корпусом тоже кажется не лучшим способом движения вперёд. Я в 2012м году был наивным и тоже начал делать подобный словарь, и даже забытый ныне brown clustering и его бинарное дерево группировки слов легко позволяло подобный словарь расширять. Но потом при построении своего синтактико-семантического парсера я увидел, что в языке основные плохо решённые моменты связаны преимущественно с неоднозначностями разного вида: омонимами разного вида, различными смыслами слов (и отсутствием приличного словаря смыслов слов и многословных понятий), фразеологизмами, проблемой кореференции, и многословными сущностями (задачи NER и EMD). А потом пришли нейросети. Так вот: подобные найденных вами синтактико-семантические зависимости нейросетикушают на завтрак легко сами изучат и будут использовать при парсинге, здесь можно даже взять пример «положить в карман (чего?) куртки» vs «положить в сундук (что?) куртки» — представляете, нейросеть на большом датасете в режиме без учителя способна выучить даже весьма условное понимание наличия карманов у предмета, чтобы потом правильно строить синтаксическо-семантические связи между словами в данных предложениях. А у вас, наверное, и «карман» и «сундук» в один класс «ёмкостей» попадут, а в какой класс попадёт «болгарка» я даже боюсь предположить… ;)
Справедливости ради, вы про всё это пишете, однако вы считаете подобные проблемы принципиально неустранимыми (и в вашем словаре — так и есть, но есть нюанс...). Поэтому я просто призываю вас сразу же пробовать применять ваши идеи для решения практических задач, и в результате начать смотреть на языковые проблемы шире.
2) Вы, наверное, удивитесь, но word2vec имеет встроенную кластеризацию, которая даже из коробки неплохо ловит подобные синтаксическо-семантические классы. Можно и дальше развивать данную идею.
Подскажу, как сделать, чтобы word2vec ещё лучше выделял подобные классы: нужно его тренировать на нелемматизированном корпусе, тогда синтаксические падежные отношения подберут большую часть ваших классов для существительных, но заодно выделят ещё и классы на глаголах, прилагательных, числительных, наречиях. Поэтому мне очень не нравится ваше объяснение вида «word2vec такого не может, поэтому нам пришлось долго и мучительно изобретать своё решение» — увы, боюсь, он про «мы не смогли сделать». Пройдите теперь чуть дальше: нелемматизированный word2vec внутри делает ровно то же самое, что делает ваш самописный алгоритм сравнения гистограмм распределений, и сработает даже на неразмеченном корпусе, может, будет лишь чуть-чуть более шумным.
3) Для решения более глобальных планов ваша идея с семантическим корпусом тоже кажется не лучшим способом движения вперёд. Я в 2012м году был наивным и тоже начал делать подобный словарь, и даже забытый ныне brown clustering и его бинарное дерево группировки слов легко позволяло подобный словарь расширять. Но потом при построении своего синтактико-семантического парсера я увидел, что в языке основные плохо решённые моменты связаны преимущественно с неоднозначностями разного вида: омонимами разного вида, различными смыслами слов (и отсутствием приличного словаря смыслов слов и многословных понятий), фразеологизмами, проблемой кореференции, и многословными сущностями (задачи NER и EMD). А потом пришли нейросети. Так вот: подобные найденных вами синтактико-семантические зависимости нейросети
Справедливости ради, вы про всё это пишете, однако вы считаете подобные проблемы принципиально неустранимыми (и в вашем словаре — так и есть, но есть нюанс...). Поэтому я просто призываю вас сразу же пробовать применять ваши идеи для решения практических задач, и в результате начать смотреть на языковые проблемы шире.
Очень крутой комментарий, спасибо!
1) Вы правы, семантик существует как минимум две — нативно-лингвистическая и энциклопедическая (те самые знания о мире). Вторую вычислять из текстов бессмысленно: на то они и знания о мире, что в общетематических текстах о них не написано, это и так всем известно.
Что касается синтаксиса — здесь он служит как вспомогательный инструмент, не более того. Хочется, чтобы компьютер понимал примерно такую цепочку: конструкция «убрать в рюкзак» возможна потому, что аргументом функции «убрать в X» частотно служат контейнеры, а рюкзак является таковым. Синтаксис позволяет понять только то, что на месте икса частотно стоит существительное в неодушевлённом винительном. Это слишком грубое знание, оставляющее массу неоднозначностей.
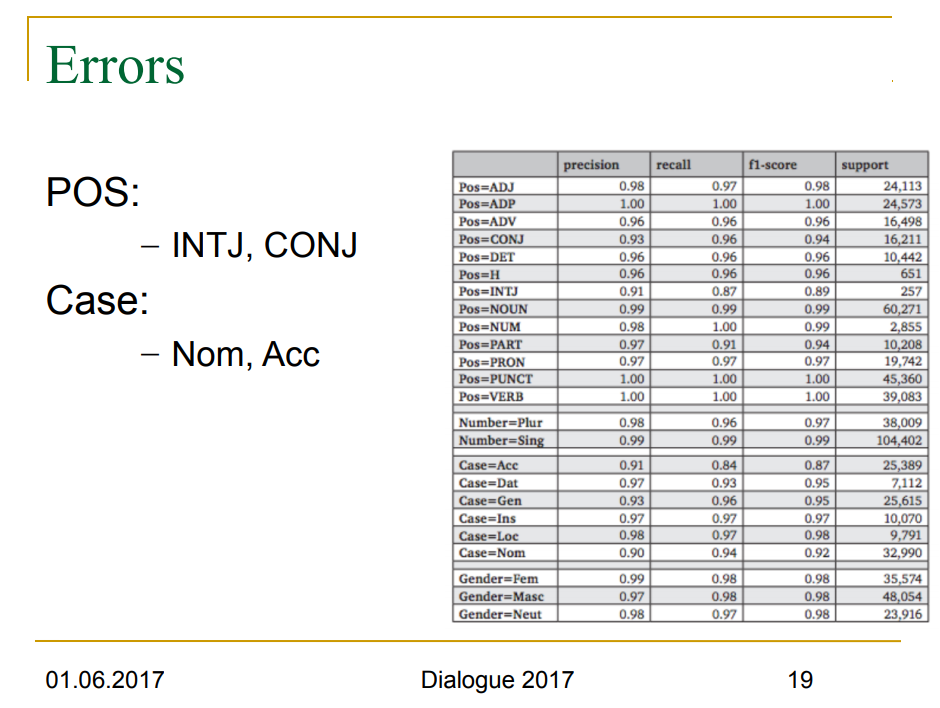
Касательно категории неодушевлённости — здесь речь идёт о настолько важной и частотной семантике, что язык «решил» её аж в синтаксис зашить. Но других таких случаев я не знаю. И опять же, в задачах синтаксической разметки один из самых сложных случаев — развести именительный неодушевлённый с совпадающим винительным неодушевлённым (пруфы: morphoRuEval-2017, Morphobabushka (M), стр. 19). Что говорит только об одном — эта задача решается человеком на уровень выше — на уровне семантики.
2) Да, действительно удивлюсь. Я очень много работал с word2vec в задаче кластеризации синонимов, крутил его и так и так, разговаривал на эту тему с создателями Watset. Не получается из него вытащить нужную информацию о семантических классах. Собственно данная работа не просто из вакуума появилась, а именно из fail'а при работе с дистрибутивными моделями. Поэтому я всегда сравниваю в статьях с word2vec'ом и делаю акцент на разнице в получаемой информации.
Если вы не согласны и считаете, что можно справиться дистрибутивными моделями — сделайте ответную статью с демонстрацией по фактам. Я без шуток. Это будет тот уровень дискуссии, который позволит получить новое знание для всех. И я буду среди благодарных ваших читателей.
3) Нейросети — огонь-технология, прорыв, никто здесь и не спорит. Но им нужны размеченные данные и каждый раз при переходе в новую предметную область или к новому целевому показателю в той же области — сиди размечай заново. Не говоря уже о тех же фундаментальных проблемах в виде отсутствия внеязыковых данных. И абсолютно непонятно, как их в сетку поставлять. А учёт дискурса, когда в одном отзыве клиент и доволен, и недоволен, и в затылке почесал, и пошутил, и собаку с вами обсудил. Тут вообще пиши-пропало.
Причём даже в задачах компьютерного зрения машине объясняют: тут собака, тут кошка, здесь машина, а это — пешеход. Хотя визуальная информация уже априори более богатая, чем текстовая. Так откуда берётся эта непонятная надежда, что тексты, являющиеся жатым-пережатым источником, компьютер вдруг автомагически научится сам понимать!? Для меня это загадка.
P.S. Ещё раз моя вам благодарность за комментарий — он заставляет думать и задумываться. Все эмоции относятся только к сложности решаемой проблемы и никак не к участником этого обсуждения.
1) Вы правы, семантик существует как минимум две — нативно-лингвистическая и энциклопедическая (те самые знания о мире). Вторую вычислять из текстов бессмысленно: на то они и знания о мире, что в общетематических текстах о них не написано, это и так всем известно.
Что касается синтаксиса — здесь он служит как вспомогательный инструмент, не более того. Хочется, чтобы компьютер понимал примерно такую цепочку: конструкция «убрать в рюкзак» возможна потому, что аргументом функции «убрать в X» частотно служат контейнеры, а рюкзак является таковым. Синтаксис позволяет понять только то, что на месте икса частотно стоит существительное в неодушевлённом винительном. Это слишком грубое знание, оставляющее массу неоднозначностей.
Касательно категории неодушевлённости — здесь речь идёт о настолько важной и частотной семантике, что язык «решил» её аж в синтаксис зашить. Но других таких случаев я не знаю. И опять же, в задачах синтаксической разметки один из самых сложных случаев — развести именительный неодушевлённый с совпадающим винительным неодушевлённым (пруфы: morphoRuEval-2017, Morphobabushka (M), стр. 19). Что говорит только об одном — эта задача решается человеком на уровень выше — на уровне семантики.

2) Да, действительно удивлюсь. Я очень много работал с word2vec в задаче кластеризации синонимов, крутил его и так и так, разговаривал на эту тему с создателями Watset. Не получается из него вытащить нужную информацию о семантических классах. Собственно данная работа не просто из вакуума появилась, а именно из fail'а при работе с дистрибутивными моделями. Поэтому я всегда сравниваю в статьях с word2vec'ом и делаю акцент на разнице в получаемой информации.
Если вы не согласны и считаете, что можно справиться дистрибутивными моделями — сделайте ответную статью с демонстрацией по фактам. Я без шуток. Это будет тот уровень дискуссии, который позволит получить новое знание для всех. И я буду среди благодарных ваших читателей.
3) Нейросети — огонь-технология, прорыв, никто здесь и не спорит. Но им нужны размеченные данные и каждый раз при переходе в новую предметную область или к новому целевому показателю в той же области — сиди размечай заново. Не говоря уже о тех же фундаментальных проблемах в виде отсутствия внеязыковых данных. И абсолютно непонятно, как их в сетку поставлять. А учёт дискурса, когда в одном отзыве клиент и доволен, и недоволен, и в затылке почесал, и пошутил, и собаку с вами обсудил. Тут вообще пиши-пропало.
Причём даже в задачах компьютерного зрения машине объясняют: тут собака, тут кошка, здесь машина, а это — пешеход. Хотя визуальная информация уже априори более богатая, чем текстовая. Так откуда берётся эта непонятная надежда, что тексты, являющиеся жатым-пережатым источником, компьютер вдруг автомагически научится сам понимать!? Для меня это загадка.
P.S. Ещё раз моя вам благодарность за комментарий — он заставляет думать и задумываться. Все эмоции относятся только к сложности решаемой проблемы и никак не к участником этого обсуждения.
К вопросу про сетки и тренировку Word2Vec.
Вы не упоминаете FastText. А надо. Он ловит все эти ваши суффиксы и приставки и падежи.
Откровенно говоря просто пробовал разные готовые вектора на downstream задачах. И FastText для русского языка всегда был лучше.
С сетками, вопрос конечно всегда сводится к поиску халявной разметки, но есть еще небольшой лайфхак — скрестить FastText внутри сетки собственно с сеткой — и сразу уйдут проблемы со словарем, нормализацией форм, итд итп
Еще бы придумать как это скрестить с языковым моделированием и NMT — и считай новая сота в «сложных» языках будет.
По сути получится как бы ансамбль внутри ансамбля. Инициализируем его фаст-текстом и профит. Только докинуть разметки.
> Так откуда берётся эта непонятная надежда, что тексты, являющиеся жатым-пережатым источником, компьютер вдруг автомагически научится сам понимать!?
Не научится. Будет оверфититься на какие-то гипер-окрестности в многомерном пространстве. Но мы все равно этого не поймем кроме как отсмотрев attention или просто увидев что сетка оверфитится на словарь или какие-то особенные косяки языка (редкие слова или имена например).
Вы не упоминаете FastText. А надо. Он ловит все эти ваши суффиксы и приставки и падежи.
Откровенно говоря просто пробовал разные готовые вектора на downstream задачах. И FastText для русского языка всегда был лучше.
С сетками, вопрос конечно всегда сводится к поиску халявной разметки, но есть еще небольшой лайфхак — скрестить FastText внутри сетки собственно с сеткой — и сразу уйдут проблемы со словарем, нормализацией форм, итд итп
Еще бы придумать как это скрестить с языковым моделированием и NMT — и считай новая сота в «сложных» языках будет.
По сути получится как бы ансамбль внутри ансамбля. Инициализируем его фаст-текстом и профит. Только докинуть разметки.
> Так откуда берётся эта непонятная надежда, что тексты, являющиеся жатым-пережатым источником, компьютер вдруг автомагически научится сам понимать!?
Не научится. Будет оверфититься на какие-то гипер-окрестности в многомерном пространстве. Но мы все равно этого не поймем кроме как отсмотрев attention или просто увидев что сетка оверфитится на словарь или какие-то особенные косяки языка (редкие слова или имена например).
Спасибо за статью! Мое скромное мнение: покуда производительность компьютеров не уподобится хотя бы хоть сколь-нибудь производительности человеческого мозга (кол-во нервных связей и быстродействие), сделать искусственную модель развитого естественного языка — провальная затея. Размерности данных и факторы, необходимые для «разметки», в мозгу человека прото огромны. Как научить компьютер «понимать» все смыслы и скрытый подтекст, скажем, романов Достоевского или стихотворений Пушкина? Человек может это делать благодаря миллиардам нейронов, связанных между собой самым причудливым образом — это те пресловутые внеязыковые знания о мире. Язык — это всего лишь система знаков (Ф. де Соссюр). И человек понимает человека, преобразуя набор знаков в невербальные концепты, которые накладываются на его картину мира.
Чем больше я занимаюсь естественным языком, тем больше он открывается как вполне логичная и стройная система, поддающаяся анализу и моделированию. Другой вопрос, что для сугубо практических применений гораздо дешевле и эффективнее использовать нейросетевые подходы, строящие свою внутреннюю модель, заточенную под конкретную задачу. В противовес построению generic-системы, воспроизводящей мышление в целом. Аналогичная картина наблюдается и в научных работах.
Процитирую замечательную книгу Т. Г. Скребцовой «Когнитивная лингвистика: классические теории, новые подходы»:
Процитирую замечательную книгу Т. Г. Скребцовой «Когнитивная лингвистика: классические теории, новые подходы»:
Подчеркивается центральная роль физического опыта взаимодействия человека с окружающим миром в организации его понятийной системы. Рационализму формальных теорий, основанных на дуалистической концепции Декарта (ср. картезианская лингвистика Хомского), противопоставляется эмпиризм как метод познания. В связи с этим выдвигается тезис о том, что мышление «воплощено» (embodied) [Johnson 1987; 1992; Lakoff 1987; Lakoff, Johnson 1999], т. е. неразрывно связано с телом человека, его анатомическими и физиологическими особенностями, перцептивным и моторным опытом. Подтверждение тому когнитивисты находят в языке, в частности при исследовании механизмов образности. Именно «воплощенностью» мышления, по их мнению, объясняются неудачи, связанные с моделированием искусственного интеллекта и автоматической обработкой языка.
Есть много подходов, кот. пытаются преодолеть ограниченности рационализма и эмпиризма в познании — воплощенное познание, воплощенный разум, энактивизм, экологический подход, и тд. Все это интересно и полезно для изучения самого процесса познания)), но как применить это на практике? Как найти ту самую generic-систему или подход, кот. вы упомянули, который будет направлять поиск в русло полезных и практически реализуемых решений? Кажется перспективным подход связанный с когнитивным ядром (Core Cognition), как воплощения нативиского подхода к примирению крайностей эмпиризма и рационализма вообще, и проблемы обучения с «чистого листа» (tabula rasa) для ИНС. Включая разработку ИИ, сравнимого с человеческим, в перспективе. Почему? Этот путь уже проделала эволюция используя доступные ей возможности метода проб и ошибок, и добилась успеха. Почему не повторить его? Но уже на новой основе. Однако многие разработчики считают, особенно после успеха AlphaGo, что ИНС могут обучаться с «чистого листа». Хотя анализ показывает, что это не соответствует действительности, см. эту публикацию, для примера. В этом направлении интересны исследования, кот. проводит известный спец. по когнитивной психологии из MIT Д. Таненбаум, см. последнюю работу, носящую обзорный характер. Это целое направление связанное с построением внутренней модели мира младенцами исходя из возможностей когнитивного ядра, и ее адаптации в процессе обучения и получения новой информации. Исследования по составу ядра (или основного знания, как называют это некоторые авторы) бурно развивающаяся область когнитивных исследований. Лингвистический аспект один из составляющих этого ядра, наряду с физическим, математическим и психологическим.
Когда мы сможем создавать роботов, чей мозг вмещается в мозг (или хотя бы все тело), скажем, пчелы, но с такими же способностями, как у пчелы (на весь период онтогенеза), — тогда можно будет уже говорить о моделировании более сложных сущностей. И если язык и речь у человека (читай вербальное мышление) как-то ассоциированы хотя бы с 25% сознательного мышления и 5% бессознательного, то нам еще очень далеко до сколь-нибудь правдоподобной симуляции человеческой речи — не в узком применении (как чат-боты сегодня), а в разговоре на любые темы.
Sign up to leave a comment.
Новогодний датасет 2018: открытая семантика русского языка