
Я хотела бы представить концепцию Функционального Программирования новичкам самым простейшим образом, выделив некоторые его преимущества из множества остальных, которые реально позволят сделать код более читаемым и выразительным. Я подобрала для вас интересные демонстрационные примеры, которые находятся на
Playground в Github.Функциональное Программирование: Определение
Прежде всего, Функциональное Программирование — это не язык или синтаксис, а скорее всего — способ решения проблем путем разбиения сложных процессов на более простые и последующей их композиции. Как следует из названия "Функциональное программирование", единицей композиции для данного подхода является функция; и цель такой функции — избежать изменения состояния или значений за пределами своей области действия (
scope).В Мире
Swift для этого есть все условия, ибо функции здесь являются такими же полноправными участниками процесса программирования, как и объекты, а проблема изменяемости (mutation) решается на уровне концепции value ТИПОВ (структур struct и перечислений enum), которые помогают управлять изменяемостью (mutation) и четко сообщают о том, как и когда это может произойти.Однако
Swift не является в полном смысле языком Функционального программирования, он не принуждает вас к Функциональному программированию, хотя и признает преимущества Функциональных подходов и находит способы встраивания их. В этой статье мы сфокусируемся на использовании встроенных в
Swift (то есть «из коробки») элементов Функционального программирования и понимании того, как можно их комфортно использовать в вашем приложении.Императивный и Функциональный подходы: Сравнение
Чтобы оценить Функциональный подход, давайте сравним решения некоторой простой задачи двумя различными способами. Первый способ решения — "Императивный", при котором код изменяет состояния внутри программы.
//Imperative Approach
var numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
for i in 0..<numbers.count {
let timesTen = numbers[i] * 10
numbers[i] = timesTen
}
print(numbers) //[10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
Заметьте, что мы манипулируем значениями внутри изменяемого массива с именем
numbers, а затем распечатываем его на консоли. Смотря на этот код, попробуйте ответить на следующие вопросы, которые мы обсудим в ближайшее время:- Чего вы пытаетесь достичь с помощью вашего кода?
- Что произойдет, если другой поток (
thread) попытается получить доступ к массивуnumbersво время выполнения вашего кода? - Что произойдет, если вы захотите иметь доступ к первоначальным значениям, находящимся в массиве
numbers? - Насколько надежно можно протестировать этот код?
Теперь давайте рассмотрим альтернативный "Функциональный" подход:
//Functional Approach
let numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
extension Array where Element == Int {
func timesTen() -> [Int] {
var output = [Int]()
for num in self {
output.append(num * 10)
}
return output
}
}
let result = numbers.timesTen()
print(numbers) //[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(result) //[10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
В этом кусочке кода мы получаем на консоли тот же самый результат, подходя к решению задачи совершенно другим способом. Заметьте, что на этот раз наш массив
numbers является неизменяемым (immutable) благодаря ключевому слову let. Мы переместили процесс умножения чисел из массива numbers в метод timesTen(), который находится в расширении extension массива Array. Мы все еще используем for цикл и изменяем переменную с именем output, но, область действия (scope) этой переменной ограничена только этим методом. Подобным же образом, наш входной аргумент self передается в метод timesTen() по значению (by value), имея ту же самую область действия, что и выходная переменная output. Метод timesTen() вызывается, и мы можем распечатать на консоли как исходный массив numbers, так и результирующий массив result.Давайте вернемся к рассмотрению наших 4-х вопросов.
1. Чего вы пытаетесь достичь с помощью вашего кода?
В нашем примере мы выполняем очень простую задачу, умножая числа, находящиеся в массиве
numbers, на 10.При Императивном подходе для того, чтобы получить выходной результат, вы должны думать как компьютер, следуя инструкциям в
for цикле. В этом случае код показывает, КАК вы достигаете результата. При Функциональном подходе "КАК" «завернуто» в метод timesTen(). При условии, что этот метод был реализован в другом месте, вы реально можете видеть только выражение numbers.timesTen(). Такой код ясно показывает, ЧТО достигается этим кодом, а не КАК решается поставленная задача. Это называется Декларативным Программированием, и нетрудно догадаться, почему такой подход является привлекательным. Императивный подход заставляет разработчика понимать, КАК код работает для того, чтобы определять ЧТО он должен делать. Функциональный подход по сравнению с Императивным является значительно более «выразительным» и предоставляет разработчику роскошную возможность просто предполагать, что метод делает то, о чем он заявляет! (Очевидно, что это предположение относится только к заранее проверенному коду).2. Что произойдет, если другой поток (
thread) попытается получить доступ к массиву numbers во время выполнения вашего кода?Представленные выше примеры существуют в совершенно изолированном пространстве, хотя в сложной многопоточной среде вполне возможна ситуация, когда два потока (
threads) пытаются получить доступ к одним и тем же ресурсам одновременно. В случае Императивного подхода нетрудно увидеть, что, когда другой поток (thread) имеет доступ к массиву numbers в процессе его использования, то результат будет диктоваться тем порядком, в котором потоки (threads) получают доступ к массиву numbers. Эта ситуация называется «состояние гонки» (race condition) и может привести к непредсказуемому поведению и даже к нестабильности и аварийному завершению приложения.По сравнению с этим Функциональный подход не имеет «побочных эффектов» (
side effects). Другими словами, выход output метода не изменяет никакие хранящиеся (stored) значения в нашей системе и определяется исключительно входом. В этом случае любой поток (threads), который имеет доступ к массиву numbers, ВСЕГДА будет получать те же самые значения и его поведение будет стабильно и предсказуемо.3. Что произойдет, если вы захотите иметь доступ к первоначальным значениям, запомненным в массиве
numbers?Это продолжение нашего разговора о «побочных эффектах» (
side effects). Очевидно, что изменения состояния не отслеживаются. Следовательно, при Императивном подходе мы теряем первоначальное состояние нашего массива numbers в процессе преобразования. Наше решение, основанное на Функциональном подходе, сохраняет первоначальный массив numbers и формирует на выходе новый массив result с желаемыми свойствами. Он оставляет первоначальный массив numbers нетронутым и пригодным для будущей обработки.4. Насколько надежно можно протестировать этот код?
Так как Функциональный подход уничтожает все «побочные эффекты» (
side effects), тестируемая функциональность полностью находится внутри метода. Вход этого метода НИКОГДА не будет испытывать изменений, так что вы можете проводить тестирование многократно с помощью цикла сколько угодно раз, и вы ВСЕГДА будете получать один и тот же результат. В этом случае тестирование проводить очень легко. В сравнении с этим, тестирование Императивного решения в цикле будет изменять начение входа и вы будете получать совершенно различные результаты после каждой итерации.Краткое изложение преимуществ
Как мы видели из очень простого примера, Функциональный подход является классной вещью, если вы имеете дело с Моделью данных, потому что:
- Оно декларативно
- Оно устаняет проблемы, связанные с потоками, наподобие «состояний гонки» (
race condition) и «взаимной блокировки» (dead lock) - Оно оставляет состояние в неизменном состоянии, которое может быть использованы для последующих преобразований
- Оно является легко теcтируемым
Давайте продвинемся немного дальше в изучении Функционального программирования в
Swift. Оно предполагает, что основными «действующими лицами» являются функции, и они должны быть прежде всего объектами первого класса.Функции первого класса и Функции высшего порядка
Для того, чтобы функция была первоклассной, у неё должна быть возможность быть объявленной в виде переменной. Это позволяет управлять функцией как обычным ТИПОМ данных и в то же время исполнять её. К счастью, в
Swift функции являются объектами первого класса, то есть поддерживается их передача в качестве аргументов другим функциям, возврат их как результат других функций, присваивание их переменным или сохранение в структурах данных.Благодаря этому мы имеем в
Swift и другие функции - функции высшего порядка, которые определяются как функции, принимающие другую функцию как аргумент или возвращающие функцию. Их много: map , filter , reduce , forEach , flatMap , compactMap ,sorted и т.д. Наиболее распространенными примерами функций высшего порядка являются функции map , filter и reduce. Они — не глобальные, все они «привязаны» к определенным ТИПАМ. Они работают на всех Sequence ТИПАХ, включая коллекцию Collection, представителями которой являются такие структуры данных в Swift, как массив Array, словарь Dictionary и множество Set. В Swift 5 функции высшего порядка работают еще и с совершенно новым ТИПОМ - Result.map(_:)
В
Swift map(_:) принимает функцию в качестве параметра и преобразует значения определенного ТИПА согласно этой функции. Например, применяя map(_:) к массиву значенй Array, мы применяем функцию-параметр к каждому элементу исходного массива и получаем на выходе также массив Array, но уже преобразованных значений.//Functional Approach
let numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
func timesTen(_ x:Int) -> Int {
return x * 10
}
let result = numbers.map (timesTen)
print(numbers) //[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(result) //[10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
В приведенном выше коде мы создали функцию
timesTen (_:Int), которая берет целое Int значение и возвращает умноженное на 10 целое значение Int, и использовали ее в качестве входного параметра нашей функции высшего порядка map(_:), применив ее к нашему массиву numbers. Мы получили нужный нам результат в массиве result.Имя функции-параметра
timesTen для функций высшего порядка наподобие map(_:), не имеет значения, важен ТИП входного параметра и возвращаемого значения, то есть сигнатура (Int) -> Int функции-входного параметра. Поэтому мы можем использовать в map(_:) анонимные функции — замыкания (closure) — в любой форме, в том числе и c сокращенными именами аргументов $0, $1 и т.д.//Functional Approach
let numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
let result = numbers.map { $0 * 10 }
print(numbers) //[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(result) //[10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
Если мы посмотрим на функцию
map(_ :) для массива Array, то она может выглядеть так:func map<T>(_ transform: (Element) -> T) -> [T] {
var returnValue = [T]()
for item in self {
returnValue.append(transform(item))
}
return returnValue
}
Это хорошо знакомый нам императивный код, но он уже не является проблемой разработчика, это проблема
Apple, проблема Swift. Реализация функции высшего порядка map(_:) оптимизируется Apple с точки зрения производительности, а нам, разработчикам, гарантированно предоставляется функциональность map(_:), так что нам остается только правильно выразить с помощью функции-аргумента transform ЧТО мы хотим, не заботясь о том, КАК это будет реализовано. В результате мы получаем прекрасно читаемый код в виде единственной строки, который будет работать лучше и быстрее.//Functional Approach
let possibleNumbers = ["1", "2", "three", "///4///", "5"]
let mapped = possibleNumbers.map {str in Int(str) }
print (mapped) // [Optional(1), Optional(2), nil, nil, Optional(5)]
Возвращаемый функцией-параметром
ТИП может не совпадать с ТИПОМ элементов исходной коллекции.В выше приведенном коде у нас есть возможные целые числа
possibleNumbers, представленные в виде строк, и мы хотим преобразовать их в целые числа ТИПА Int , иcпользуя «падающий» (failable) инициализатор Int(_ :String), представленный замыканием { str in Int(str) }. Мы делаем это с помощью map(_:) и получаем на выходе массив mapped ТИПА Optional:
Нам
НЕ удалось преобразовать в целые числа ВСЕ элементы нашего массива possibleNumbers, в результате одна часть получила значение nil, указывающее на невозможность преобразования строки String в целое число Int, а другая часть превратилась в Optionals, имеющие значения:print (mapped) // [Optional(1), Optional(2), nil, nil, Optional(5)]
compactMap(_ :)
Если функция-параметр, передаваемая в функцию высшего порядка имеет на выходе
Optional значение, то, возможно, полезнее использовать другую схожую по смыслу функцию высшего порядка — compactMap(_ :), которая делает все то же самое, что и map(_:), но дополнительно «разворачивает» полученные на выходе Optional значения и удаляет из коллекции значения равные nil.
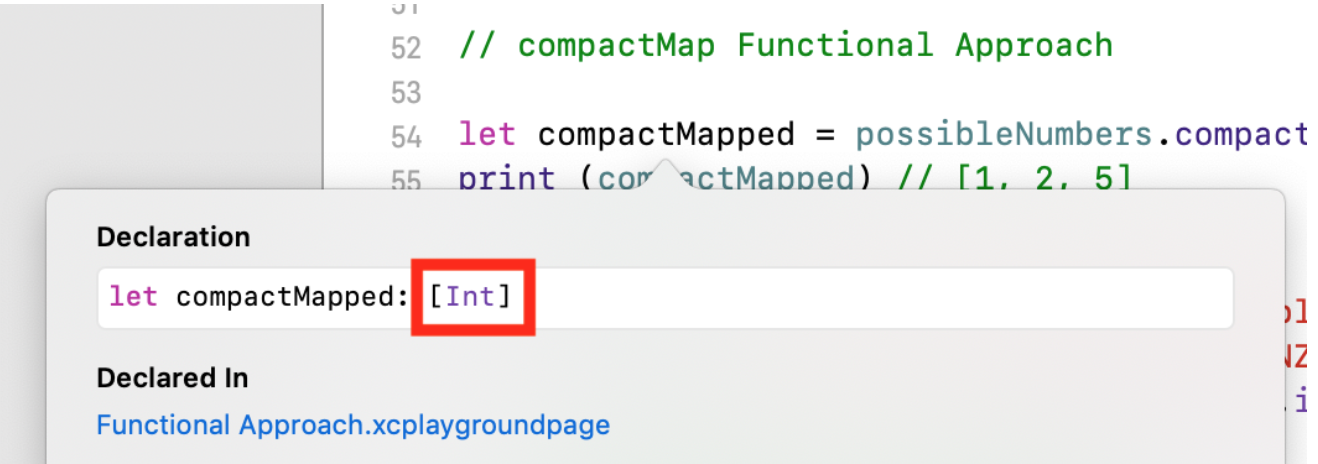
В этом случае мы получаем массив
compactMapped ТИПА [Int], но, возможно, меньшего размера:let possibleNumbers = ["1", "2", "three", "///4///", "5"]
let compactMapped = possibleNumbers.compactMap(Int.init)
print (compactMapped) // [1, 2, 5]
Всегда, когда вы используете в качестве преобразующей функции «падающий» (
failable) инициализатор init?(), вам придется использовать compactMap(_ :):// Validate URLs
let strings = ["https://demo0989623.mockable.io/car/1",
"https://i.imgur.com/Wm1xcNZ.jpg"]
let validateURLs = strings.compactMap(URL.init)
// Separate Numbers and Operations
let mathString: String = "12-37*2/5+44"
let numbers1 = mathString.components(separatedBy: ["-", "*", "+", "/"]).compactMap(Int.init)
print(numbers1) // [12, 37, 2, 5, 44]
Надо сказать, что оснований для использования функции высшего порядка
compactMap(_ :) более, чем достаточно. Swift «любит» Optional значения, их можно получить не только применяя «падающий» (failable) инициализатор init?(), но и с помощью оператора as? «кастинга» ТИПА:let views = [innerView,shadowView,logoView]
let imageViews = views.compactMap{$0 as? UIImageView}
… и оператора
try? при обработке выбрасываемых некоторыми методами ошибок. Надо сказать, что Apple озаботилась тем, что использование try? очень часто приводит к двойному Optional и в Swift 5 теперь оставляет только один уровень Optional после применения try?.Есть еще одна схожая по названию функция высшего порядка
flatMap(_ :), о которой чуть ниже.Иногда, чтобы воспользоваться функцией высшего порядка
map(_:), полезно использовать метод zip (_:, _:) для создания последовательности пар из двух различных последовательностей.Допустим, у нас есть
view, на котором представлено несколько точек points, соединенных между собой и образующих ломаную линию:
Нам необходимо построить другую ломанную линию, соединяющую середины отрезков первоначальной ломанной линии:

Для того, чтобы рассчитать среднюю точку отрезка, мы должны располагать координатами двух точек: текущей и следующей. Для этого мы можем сформировать последовательность, состоящую из пар точек — текущей и последующей — с помощью метода
zip (_:, _:), в котором будем использовать массив исходных точек points и массив следующих точек points.dropFirst():let pairs = zip (points,points.dropFirst())
let averagePoints = pairs.map {
CGPoint(x: ($0.x + $1.x) / 2, y: ($0.y + $1.y) / 2 )}
Имея такую последовательность, мы очень легко рассчитываем средние точки с помощью функции высшего порядка
map(_:) и отображаем их на графике.filter (_:)
В
Swift функция высшего порядка filter (_:) доступна большинству ТИПОВ, которым доступна функция map(_:). Вы можете фильтровать любые последовательности Sequence с помощью filter (_:), это очевидно! Метод filter (_:) принимает другую функцию в качестве параметра, которая представляет собой условие для каждого элемента последовательности, и если условие выполняется, то элемент включается в результат, а если — нет, то не включается. Эта «другая функция» принимает единственное значение — элемент последовательности Sequence - и возвращает Bool, так называемый предикат.Например, для массивов
Array функция высшего порядка filter (_:) применяет функцию-предикат и возвращает другой массив, состоящий исключительно из тех элементов первоначального массива, для которых входная функция-предикат возвращает true.//Functional Approach
let numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
let filted = numbers.filter{$0 % 2 == 0}
//[2, 4, 6, 8, 10]
Здесь функция высшего порядка
filter (_:) берет каждый элемент массива numbers (представленный $0) и проверяет, является ли этот элемент четным числом. Если это четное число, то элемент массива numbers попадает в новый массив filted, в противном случае — нет. Мы в декларативной форме сообщили программе, ЧТО мы хотим получить вместо того, чтобы озаботиться тем, КАК мы должны это делать. Приведу еще пример использования функция высшего порядка
filter (_:) для получения только четных первых 20 чисел Фибоначчи, у которых значения < 4000:let fibonacci = sequence(first: (0, 1), next: { ($1, $0 + $1) })
.prefix(20).map{$0.0}
.filter {$0 % 2 == 0 && $0 < 4000}
print (fibonacci)
// [0, 2, 8, 34, 144, 610, 2584]
Мы получаем последовательность кортежей, состоящих из двух элементов последовательности Фибоначчи: n — го и (n+ 1) — го:
(0, 1), (1, 1), (1, 2), (2, 3), (3, 5) …
Для дальнейшей обработки мы ограничиваем число элементов двадцатью первыми элементами с помощью
prefix (20) и берем 0-ой элемент сформированного кортежа, используя map {$0.0 }, что будет соответствовать последовательности Фибоначчи, начинающейся с 0:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,...
Мы могли бы взять и
1-ый элемент сформированного кортежа, используя map {$0.1 }, что будет соответствовать последовательности Фибоначчи, начинающейся с 1:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,...
Нужные нам элементы мы получаем с помощью функции высшего порядка
filter {$0 % 2 == 0 && $0 < 4000}, которая возвращает массив элементов последовательности, удовлетворяющих заданному предикату. В нашем случае это будет массив целых чисел [Int]:[0, 2, 8, 34, 144, 610, 2584]
Есть еще один полезный пример использования
filter (_:) для коллекции Collection.Я столкнулась с одной реальной задачей, когда у вас есть массив изображений
images, который отображается с помощью CollectionView, и вы можете с помощью технологии Drag & Drop набрать целую «пачку» изображений и перемещать их повсюду, в том числе и «сбрасывать» в «мусорный бак».
В этом случае фиксируется массив индексов
removedIndexes сброшенных в «мусорный бак» изображений, и вам нужно создать новый массив изображений, исключив те, индексы которых попали в массив removedIndexes. Допустим, у нас есть массив целых чисел images, имитирующий изображения, и массив индексов этих целых чисел removedIndexes, которые нужно убрать. Мы будем использовать для решения нашей задачи filter (_:) :var images = [6, 22, 8, 14, 16, 0, 7, 9]
var removedIndexes = [2,5,0,6]
var images1 = images
.enumerated()
.filter { !removedIndexes.contains($0.offset) }
.map { $0.element }
print (images1) // [22, 14, 16, 9]
Метод
enumerated() возвращает последовательность кортежей, состоящих из индексов — offset и значений element массива. Затем мы применяем фильтр filter к полученной последовательности кортежей, оставляя только те, у которых индекс $0.offset не содержится в массиве removedIndexes. Следующим шагом мы выделяем из кортежа значение $0.element и получаем нужный нам массив images1.reduce (_:, _:)
Метод
reduce (_:, _:) также доступен большинству ТИПОВ, которым доступны методы map(_:) и filter (_:). Метод reduce (_:, _:) «сворачивает» последовательность Sequence до единственного аккумулирующего значения и имеет два параметра. Первый параметр — это стартовое аккумулирующее значение, а второй параметр — это функция, которая комбинирует аккумулирующее значение с элементом последовательности Sequence для получения нового аккумулирующего значения.Входная функция-параметр применяется к каждому элементу последовательности
Sequence, один за другим, до тех пор, пока не достигнет конца и не создаст финальное аккумулируюшее значение.let sum = Array (1...100).reduce(0, +)
Это классический тривиальный пример использования функции высшего порядка
reduce (_:, _:) - подсчет суммы элементов массива Array.Итерация начало текущее результат
1 0 1 0 +1 = 1
2 1 2 2 + 1 = 3
3 3 3 3 + 3 = 6
4 6 4 4 + 6 = 10
. . . . . . . . . . . . . . . . . . .
100 4950 100 4950 + 100 = 5050
С помощью функции
reduce (_:, _:) мы можем очень просто посчитать сумму чисел Фибоначчи, удовлетворяющих определенному условию:let fibonacci = sequence(first: (0, 1), next: { ($1, $0 + $1) })
.prefix(20).map{$0.0}
.filter {$0 % 2 == 0 && $0 < 4000}
print (fibonacci)
// [0, 2, 8, 34, 144, 610, 2584]
print(fibonacci.reduce(0,+))
// 3382
Но есть и более интересные применения функции высшего порядка
reduce (_:, _:). Например, мы можем очень просто и лаконично определить очень важный параметр для
UIScrollView — размер «прокручиваемой» области contentSize - на основании размеров его subviews:let scrollView = UIScrollView()
scrollView.addSubview(UIView(frame: CGRect(x: 300.0, y: 0.0, width: 200, height: 300)))
scrollView.addSubview(UIView(frame: CGRect(x: 100.0, y: 0.0, width: 300, height: 600)))
scrollView.contentSize = scrollView.subviews
.reduce(CGRect.zero,{$0.union($1.frame)})
.size
// (500.0, 600.0)
В этом демонстрационном примере аккумулирующее значение имеет
ТИП GCRect, а аккумулирующей операцией является операция объединения union прямоугольников, представляющих собой frame наших subviews.Несмотря на то, что функция высшего порядка
reduce (_:, _:) предполагает аккумулирующий характер, она может использоваться совершенно в другом ракурсе. Например, для разделения кортежа на части в массиве кортежей:// Separate Tuples
let arr = [("one", 1), ("two", 2), ("three", 3), ("four", 4)]
let (arr1, arr2) = arr.reduce(([], [])) {
($0.0 + [$1.0], $0.1 + [$1.1]) }
print(arr1) // ["one", "two", "three", "four"]
print(arr2) // [1, 2, 3, 4]
В Swift
4.2 появилась новая разновидность функции высшего порядка reduce (into:, _:). Метод reduce (into:, _:) является предпочтительным по эффективности в сравнении с методом reduce (:, :), если в качестве результирующей структуры используется COW (copy-on-write) ТИП, например, Array или Dictionary. Его можно эффективно использовать для удаления совпадающих значений в массиве целых чисел:
// Remove duplicates
let arrayInt = [1,1,2,6,6,7,2,9,7].reduce(into: []) {
!$0.contains($1) ? $0.append($1) : () }
// [1, 2, 6, 7, 9]
… или при подсчете числа разных элементов в массиве:
// Count equal elements in array
let arrayIntCount = [1,1,2,2,6,6,7,2,9,7].reduce(into: [:]) {
counts, letter in counts[letter, default: 0] += 1 }
// [6: 2, 9: 1, 1: 2, 2: 3, 7: 2]
flatMap (_:)
Прежде чем переходить к этой функции высшего порядка, давайте рассмотрим очень простой демонстрационный пример.
let maybeNumbers = ["42", "7", "three", "///4///", "5"]
let firstNumber = maybeNumbers.map (Int.init).first
Если мы запустим этот код на выполнение на
Playground, то все выглядит хорошо, и наш firstNumber равно 42:
Но, если вы не знаете, то
Playground часто скрывает истинный ТИП, в частности ТИП константы firstNumber. В действительности, константа firstNumber имеет ТИП двойного Optional:
Это происходит потому, что
map (Int.init) на выходе формирует массив Optional значений ТИПА [Int?], поскольку не каждая строка String способна преобразоваться в Int и инициализатор Int.int является «падающим» (failable). Затем мы берем первый элемент сформированного массива с помощью функции first для массива Array, который также формирует на выходе Optional, так как массив может оказаться пустым и нам не удастся получить первый элемент массива. В результате имеем двойной Optional, то есть Int??.Мы получили вложенную структуру
Optional в Optional, с которой реально сложнее работать и которую нам, естественно, не хочется иметь. Для того, чтобы достать значение из этой вложенной структуры, нам придется «нырнуть» на два уровня. Кроме того, любые дополнительные преобразования могут углублять уровень Optional еще ниже.Достать значение из двойного вложенного
Optional реально обременительно.У нас есть 3 варианта и все они требуют углубленного знания языка
Swift.- Мы можем использовать синтаксическую конструкцию
if let, но нам понадобится запускать ее несколько раз; один раз для «разворачивания» «внешнего»Optional, и еще раз — для «внутреннего»Optional:
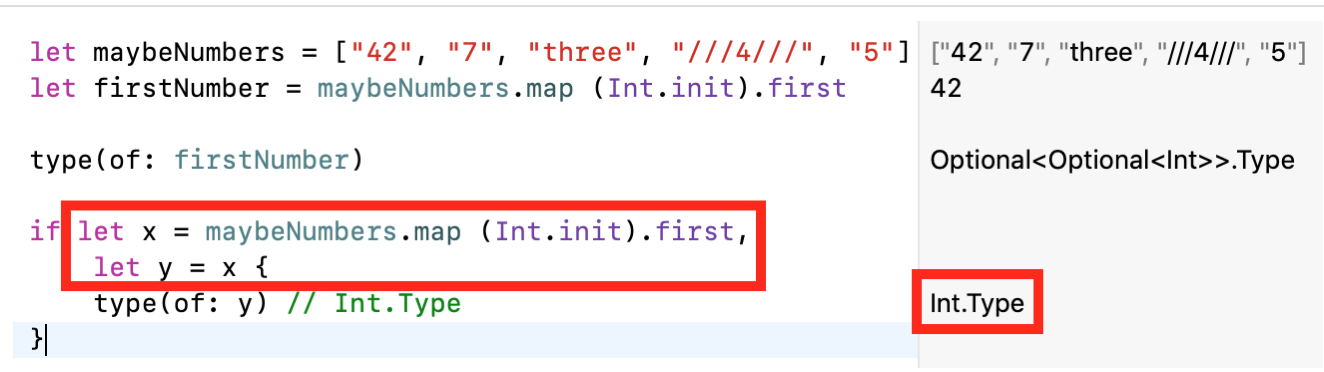
- Мы могли бы также использовать конструкцию
if case letи явное сопоставление с шаблоном (pattern match) внутри вложения:
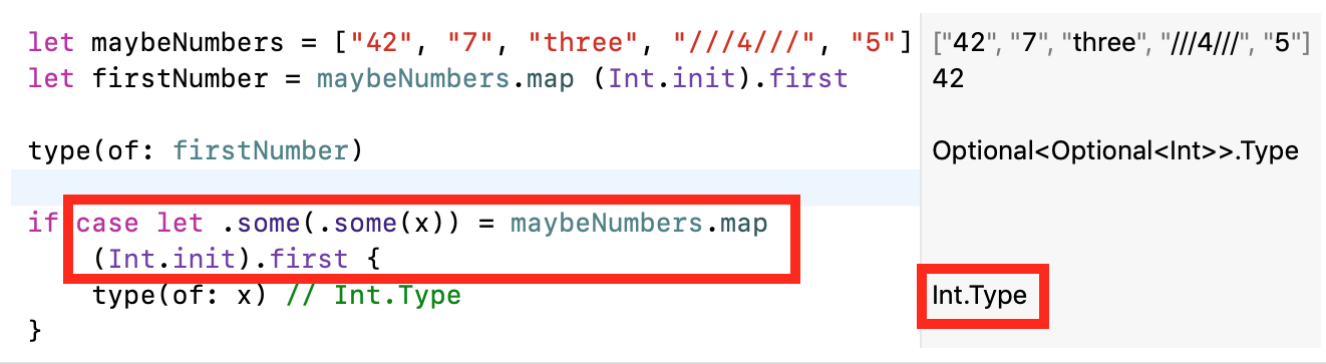
Мы могли бы также использовать оператор??для сокращенного варианта вышеприведенного синтаксиса:

- Наконец, мы могли бы использовать оператор
switchдля реального перечисления всезвозможных ситуаций:
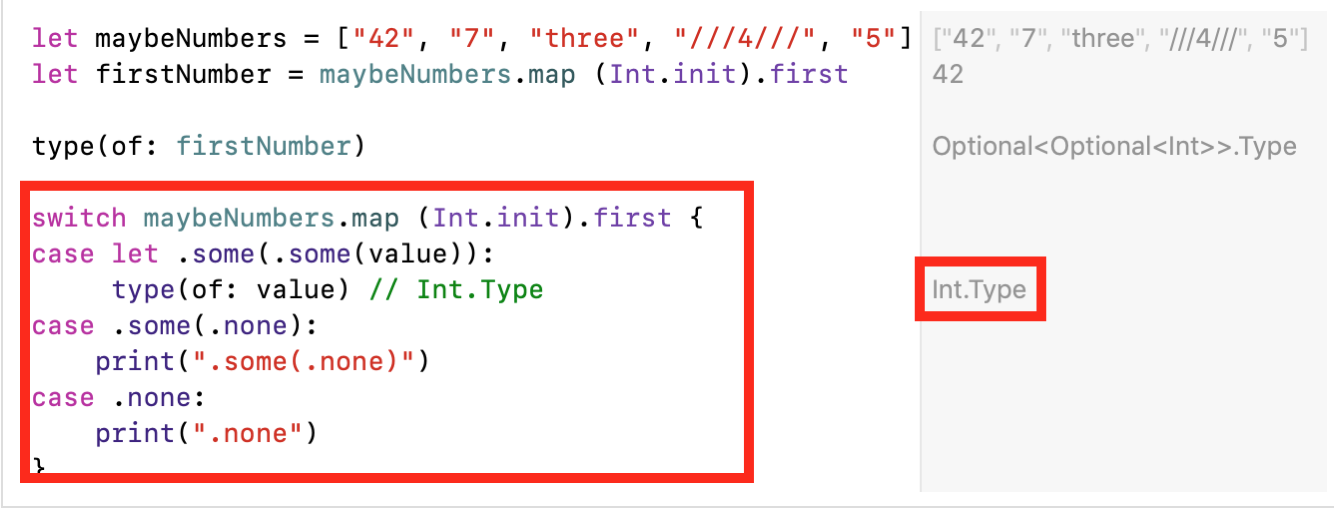



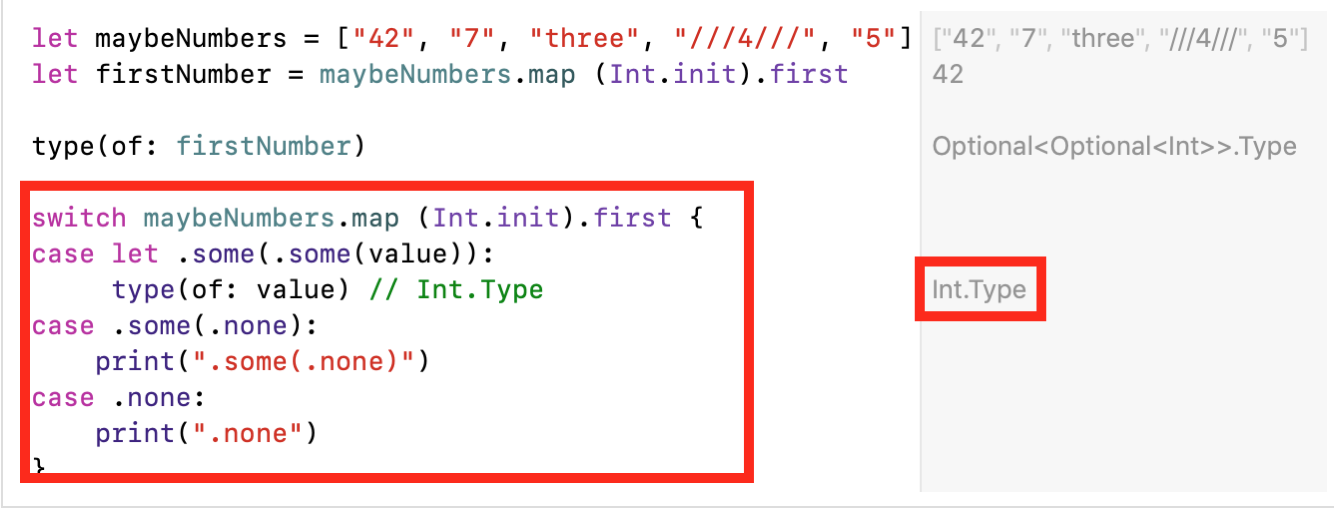
Еще хуже то, что подобные проблемы «вложенности»
ТИПОВ возникают в любых ситуациях, связанных с обобщенными (generic) контейнерами, для которых определена операция map. Например, для массивов Array.Рассмотрим еще один пример кода. Допустим, что у нас есть многострочный текст
multilineString, который мы хотим разделить на слова, написанные строчными (маленькими) буквами:let multilineString = """
Есть свойства, бестелесные явленья,
С двойною жизнью; тип их с давних лет, —
Та двойственность, что поражает зренье:
То — тень и сущность, вещество и свет.
Есть два молчанья, берега и море,
Душа и тело. Властвует одно
В тиши. Спокойно нежное, оно
Воспоминаний и познанья горе
Таит в себе, и «больше никогда»
Зовут его. Телесное молчанье,
Оно бессильно, не страшись вреда!
"""
let words = multilineString.lowercased()
.split(separator: "\n")
.map{$0.split(separator: " ")}
Для того, чтобы получить массив слов
words, мы сначала делаем Прописные ( большие) буквы строчными (маленькими) с помощью метода lowercased(), Затем разделяем текст на cтроки с помощью метода split(separatot: "\n") и получаем массив строк, а затем применяем map {$0.split(separator: " ")} для разделения каждой строки на отдельные слова.В результате мы получаем вложенные массивы:
[["есть", "свойства,", "бестелесные", "явленья,"],
["с", "двойною", "жизнью;", "тип", "их", "с", "давних", "лет,", "—"],
["та", "двойственность,", "что", "поражает", "зренье:"],
["то", "—", "тень", "и", "сущность,", "вещество", "и", "свет."],
["есть", "два", "молчанья,", "берега", "и", "море,"],
["душа", "и", "тело.", "властвует", "одно"],
["в", "тиши.", "спокойно", "нежное,", "оно"],
["воспоминаний", "и", "познанья", "горе"],
["таит", "в", "себе,", "и", "«больше", "никогда»"],
["зовут", "его.", "телесное", "молчанье,"],
["оно", "бессильно,", "не", "страшись", "вреда!"]]
… и
words имеет ТИП двойного Array:
Мы опять получили «вложенную» структуру данных, но на этот раз у нас не
Optional, а Array. Если мы хотим продолжать обработку полученных слов words, например, для нахождения буквенного спектра этого многострокового текста, то нам придется сначала каким-то образом «выпрямить» массив двойного Array и превратить его в массив одинарного Array. Это похоже на то, что мы делали с двойным Optional для демонстрационного примера в начале этого раздела, посвященного flatMap:let maybeNumbers = ["42", "7", "three", "///4///", "5"]
let firstNumber = maybeNumbers.map (Int.init).first
К счастью в
Swift нам не придется прибегать к сложным синтаксическим конструкциям. Swift поставляет нам уже готовое решение для массивов Array и Optional. Это функция высшего порядка flatMap! Она очень похожа на map, но у нее есть дополнительная функциональность, связанная с последующем «выпрямлением» «вложений», которые появляются при выполнении map. И именно поэтому она называется flatMap, она «выпрямляет» (flattens) результат map.Давайте попробуем применить
flatMap к firstNumber :
Мы действительно получили на выходе значение c одинарным уровнем
Optional.Еще интереснее
flatMap работает для массива Array. В нашем выражении для words мы просто заменяем map на flatMap:
… и получаем просто массив слов
words без какой-либо «вложенности»:["есть", "свойства,", "бестелесные", "явленья,", "с", "двойною", "жизнью;", "тип", "их", "с", "давних", "лет,", "—", "та", "двойственность,", "что", "поражает", "зренье:", "то", "—", "тень", "и", "сущность,", "вещество", "и", "свет.", "есть", "два", "молчанья,", "берега", "и", "море,", "душа", "и", "тело.", "властвует", "одно", "в", "тиши.", "спокойно", "нежное,", "оно", "воспоминаний", "и", "познанья", "горе", "таит", "в", "себе,", "и", "«больше", "никогда»", "зовут", "его.", "телесное", "молчанье,", "оно", "бессильно,", "не", "страшись", "вреда!"]
Теперь мы можем продолжить нужную нам обработку полученного массива слов
words, но будьте осторожны. Если мы еще раз применим flatMap к каждому элементу массива words, то получим, возможно, неожиданный, но вполне объяснимый результат.
Мы получим единый не «вложенный» массив букв и символов
[Character], содержащихся в нашей многострочной фразе:["е", "с", "т", "ь", "с", "в", "о", "й", "с", "т", "в", "а", ",", "б", "е", "с", "т", "е", "л", "е", "с", "н", "ы", "е", "я", "в", "л", "е", "н", "ь", "я", ",", "с", "д", "в", "о", "й", "н", "о", "ю", "ж", "и", "з", "н", "ь", "ю", ";", "т", "и", "п", "и", "х", "с", "д", "а", "в", "н", "и", "х", "л", "е", "т", ...]
Дело в том, что строка
String представляет собой коллекцию Collection символов [Character] и, применяя flatMap к каждому отдельному слову, мы еще раз понижаем уровень «вложенности» и приходим к массиву символов flattenCharacters.Может быть это именно то, что вы хотите, а может быть и — нет. Обратите на это внимание.
Собираем все вместе: решение некоторых задач
ЗАДАЧА 1
Мы можем продолжить нужную нам обработку полученного в предыдущем разделе массива слов
words, и рассчитать частоту появления букв в нашей многострочной фразе. Для начала давайте «склеим» все слова из массива words, в одну большую строку и исключим из нее все знаки препинания, то есть оставим только буквы:let wordsString = words.reduce ("",+).filter { "абвгдеёжзийклмнопрстуфхцчшщьыъэюя"
.contains($0)}
// естьсвойствабестелесныеявленьясдвойноюжизньютипихсдавнихлеттадвойственностьчтопоражаетзреньетотеньисущностьвеществоисветестьдвамолчаньяберегаиморедушаителовластвуетодновтишиспокойнонежноеоновоспоминанийипознаньягоретаитвсебеибольшеникогдазовутеготелесноемолчаньеонобессильнонестрашисьвреда
Итак, мы получили все нужные нам буквы. Теперь давайте составим из них словарь, где ключом
key является буква, а значением value — частота её появления в тексте.Мы можем это сделать двумя способами.
1-ый способ связан с использованием новой, появившейся в
Swift 4.2, разновидности функции высшего порядка reduce (into:, _:). Этот метод вполне нам подойдет для организации словаря letterCount с частотой появления букв в нашей многострочной фразе:let letterCount = wordsString.reduce(into: [:]) { counts, letter in
counts[letter, default: 0] += 1}
print (letterCount)
// ["ы": 1, "и": 18, "щ": 2, "х": 2, "й": 5, "р": 7, "а": 17, "м": 4, "с": 23, ...]
В результате мы получим словарь
letterCount ТИПА [Character : Int], в котором ключами key являются символы, встретившиеся в исследуемой фразе, а в качестве значения value — количество этих символов.2-ой способ связан с инициализацией словаря с помощью группировки, которая дает тот же самый результат:
let letterCountDictionary = Dictionary(grouping: wordsString ){ $0}.mapValues {$0.count}
letterCount == letterCountDictionary // true
Нам бы хотелось отсортировать словарь
letterCount по алфавиту:let lettersStat = letterCountDictionary
.sorted(by: <)
.map{"\($0.0):\($0.1)"}
print (lettersStat)
// ["а:17", "б:5", "в:18", "г:4", "д:8", "е:35", "ж:3", "з:4", "и:18", "й:5", "к:2", "л:10", "м:4", "н:26", "о:34", "п:5", "р:7", "с:23", "т:25", "у:4", "х:2", "ч:3", "ш:4", "щ:2", "ы:1", "ь:14", "ю:2", "я:4"]
Но мы не можем напрямую отсортировать словарь
Dictionary, так как он принципиально не является упорядоченной структурой данных. Если мы применим функцию sorted (by:) к словарю Dictionary, то она вернет нам отсортированные с заданным предикатом, элементы последовательности в виде массива именованных кортежей, который с помощью map мы превращаем в массив строк ["а:17", "б:5", "в:18", ...], отражающих частоту появления соответсвующей буквы. Мы видим, что на этот раз в качестве предиката в функцию
sorted (by:) высшего порядка передается просто оператор "<". Функция sorted (by:) ожидает на входе «функцию сравнения» в качестве единственного аргумента. Она используется для сравнения двух смежных значений и принятия решения, являются ли они корректно упорядоченными (в этом случае возвращается true) или нет (возвращается false). Мы можем вручить эту «функцию сравнения» функции sorted (by:) в виде анонимного замыкания:sorted(by: {$0.key < $1.key}
А можем передать ей просто оператор "
<", имеющий нужную нам сигнатуру, как это было сделано выше. Это тоже функция, и идет сортировка по ключам key.Если мы хотим выполнить сортировку словаря по значениям
value и выяснить, какие буквы чаще всего встречаются в этой фразе, то нам придется использовать замыкание для функции sorted (by:):let countsStat = letterCountDictionary
.sorted(by: {$0.value > $1.value})
.map{"\($0.0):\($0.1)"}
print (countsStat )
//["е:35", "о:34", "н:26", "т:25", "с:23", "и:18", "в:18", "а:17", "ь:14", "л:10", "д:8", "р:7", "п:5", "б:5", "й:5", "у:4", "я:4", "ш:4", "г:4", "м:4", "з:4", "ж:3", "ч:3", "щ:2", "х:2", "к:2", "ю:2", "ы:1"]
Если мы взглянем на решение задачи определения буквенного спектра какой-то многострочной фразы целиком…
let multilineString = """
Есть свойства, бестелесные явленья,
С двойною жизнью; тип их с давних лет, —
Та двойственность, что поражает зренье:
То — тень и сущность, вещество и свет.
Есть два молчанья, берега и море,
Душа и тело. Властвует одно
В тиши. Спокойно нежное, оно
Воспоминаний и познанья горе
Таит в себе, и «больше никогда»
Зовут его. Телесное молчанье,
Оно бессильно, не страшись вреда!
"""
let words = multilineString.lowercased()
.split(separator: "\n")
.flatMap{$0.split(separator: " ")}
let wordsString = words.reduce ("",+).filter { "абвгдеёжзийклмнопрстуфхцчшщьыъэюя"
.contains($0)}
let letterCount = wordsString.reduce(into: [:]) { counts, letter in
counts[letter, default: 0] += 1}
let lettersStat = letterCountDictionary
.sorted(by: <)
.map{"\($0.0):\($0.1)"}
print (lettersStat)
// ["а:17", "б:5", "в:18", "г:4", "д:8", "е:35", "ж:3", "з:4", "и:18", "й:5", "к:2", "л:10", "м:4", "н:26", "о:34", "п:5", "р:7", "с:23", "т:25", "у:4", "х:2", "ч:3", "ш:4", "щ:2", "ы:1", "ь:14", "ю:2", "я:4"]
let countsStat = letterCountDictionary
.sorted(by: {$0.value > $1.value})
.map{"\($0.0):\($0.1)"}
print (countsStat )
//["е:35", "о:34", "н:26", "т:25", "с:23", "и:18", "в:18", "а:17", "ь:14", "л:10", "д:8", "р:7", "п:5", "б:5", "й:5", "у:4", "я:4", "ш:4", "г:4", "м:4", "з:4", "ж:3", "ч:3", "щ:2", "х:2", "к:2", "ю:2", "ы:1"]
… то мы заметим, что в этом фрагменте кода принципиальное отсутствуют переменные (нет
var, только let) и все имена используемых функций отражают ДЕЙСТВИЯ (функции) над определенной информацией, вовсе не заботясь о том, КАК эти действия реализуются:split - разделить,map — преобразоватьflatMap - преобразовать с выравниванием (удалением одного уровня вложенности),filter - отфильтровать,sorted - сортировать,reduce - свернуть данные в некоторую структуру с помощью определенной операцииВ этом фрагменте каждую строку кода делает понятным название функции, которую мы используем. Если мы выполняем «чистое» преобразование, то используется
map, если мы выполняем преобразование с понижением уровня вложенности, то используется flatMap, если мы хотим выбрать только определенные данные, то мы используем filter и т.д, Все эти функции «высшего порядка» разработаны и оттестированы Apple с учетом оптимизации производительности. Так что этот фрагмент кода является весьма надежным и лаконичным — нам понадобилось не более 5 предложений для решения нашей задачи. Это и есть пример функционального программироваия.Единственным недостатком применения функционального подхода в этом демонстрационном примере является то, что в угоду неизменяемости, тестируемости и читаемости, мы многократно гоняем наш текст через различные функции высшего порядка. В случае большого количества элементов коллекции
Collection производительность может резко упасть. Например, если мы сначала используем filter(_:) и, а затем - first.В
Swift 4 появились некоторые новые варианты функций, позволяющие увеличить быстродействие, и вот некоторые советы по написанию более быстродействующего кода.1. Используйте contains, а НЕ first( where: ) != nil
Проверка того, что объект находится в коллекции
Collection может быть выполнена многими способами. Наилучшее быстродействие обеспечивает функция contains.ПРАВИЛЬНЫЙ КОД
let numbers = [0, 1, 2, 3]
numbers.contains(1)
НЕПРАВИЛЬНЫЙ КОД
let numbers = [0, 1, 2, 3]
numbers.filter { number in number == 1 }.isEmpty == false
numbers.first(where: { number in number == 1 }) != nil
2. Используйте проверку isEmpty, а НЕ сравнение count с нулем
Так как для некоторых коллекций доступ к свойству
count выполняется путем итерации по всем элементам коллекции.ПРАВИЛЬНЫЙ КОД
let numbers = []
numbers.isEmpty
НЕПРАВИЛЬНЫЙ КОД
let numbers = []
numbers.count == 0
3. Проверяйте пустую строку String с помощью isEmpty
Строка
String в Swift представляет собой коллекцию символов [Character]. Это означает, что для строк String также лучше использовать isEmpty.ПРАВИЛЬНЫЙ КОД
myString.isEmpty
НЕПРАВИЛЬНЫЙ КОД
myString == ""
myString.count == 0
4. Получение первого элемента, который удовлетворяет определенным условиям
Итерация по всей коллекции с целью получения первого объекта, который удовлетворяет определенным условиям, может быть выполнена с помощью метода
filter, за которым следует метод first, но наилучшим с точки зрения быстродействия является метод first (where:). Этот метод останавливает итерацию по коллекции, как только встретит выполнение нужного условия. Метод filter будет продолжать итерацию по всей коллекции независимо от того, встретил он нужные элементы или нет.Очевидно, то же самое справедливо для метода
last (where:).ПРАВИЛЬНЫЙ КОД
let numbers = [3, 7, 4, -2, 9, -6, 10, 1]
let firstNegative = numbers.first(where: { $0 < 0 })
НЕПРАВИЛЬНЫЙ КОД
let numbers = [0, 2, 4, 6]
let allEven = numbers.filter { $0 % 2 != 0 }.isEmpty
Иногда, когда коллекция
Collection имеет очень большой размер и производительность для вас критична, то стоит вернуться к сравнению императивного и функционального подходов и выбрать приемлемый для вас. ЗАДАЧА 2
Есть еще один замечательный пример очень лаконичного использования функции высшего порядка
reduce (_:, _:), с которым мне пришлось столкнуться. Это игра SET.Вот ее основные правила. Название игры
SET происходит от английского слова «set» — «набор». В игре SET участвует 81 карта, каждая с уникальной картинкой:
Каждая карта имеет 4 признака, перечисленных ниже:
Количество: на каждой карте есть один, два или три символа.
Тип символов: овалы, ромбы или волны.
Цвет: символы могут быть красными, зелеными или фиолетовыми.
Заполнение: символы могут быть пустыми, зашрихованными или закрашенными.
Цель игры
SET: Среди 12 карт, разложенных на столе, нужно найти SET (набор), состоящий из 3-х карт, у которых каждый из признаков либо полностью совпадает, либо полностью различается на всех 3-х картах. Все признаки должны полностью подчиняться этому правилу.Например, количество символов на всех 3-х картах должно быть или одинаковым, или различным, цвет на всех 3-х картах должно быть или одинаковым, или различным, и так далее…
В этом примере нас будет интересовать только Модель карты
SET struct SetCard и алгоритм определения SET по 3-м картам isSet( cards:[SetCard]):struct SetCard: Equatable {
let number: Variant // number - 1, 2, 3
let color: Variant // color - 1, 2, 3 (например, красный, зеленый, фиолетовый)
let shape: Variant // symbol - 1, 2, 3 (например, ромб, волна, овал)
let fill: Variant // fill - 1, 2, 3 (например, закрашен, заштрихован, пустой)
enum Variant: Int, CaseIterable {
case v1 = 1
case v2
case v3
}
static func isSet(cards: [SetCard]) -> Bool {
guard cards.count == 3 else {return false}
let sums = [
cards.reduce(0, { $0 + $1.number.rawValue }),
cards.reduce(0, { $0 + $1.color.rawValue }),
cards.reduce(0, { $0 + $1.shape.rawValue }),
cards.reduce(0, { $0 + $1.fill.rawValue })
]
return sums.reduce(true, { $0 && ($1 % 3 == 0) })
}
}
В Модели каждый признак — Количество
number, Тип символа shape, Цвет color и Заполнение fill — представлены перечислением Variant, имеющим 3 возможных значения: var1, var2 и var3, что соответствует 3-м целым числам rawValue — 1,2,3. В таком виде с rawValue легко оперировать. Если мы возьмем какой-нибудь признак, например, color, то сложив все rawValue для colors 3-х карт, мы обнаружим, что если colors для всех 3-х карт равны, то сумма будет равняться 3, 6 или 9, а если они все будут разные, то сумма будет равняться 6. В любом из этих случаев у нас имеет место кратность 3-м суммы rawValue для colors всех 3-х карт. Мы знаем, что это и является необходимым условием того, что 3 карты составляют SET. Для того, чтобы 3 карты действительно стали SET необходимо, чтобы для всех признаков SetCard - Количество number, Тип символа shape, Цвет color и Заполнение fill — сумма их rawValue была кратна 3-м.Поэтому в
static методе isSet( cards:[SetCard]) мы сначала вычисляем массив sums сумм rawValue для всех 3-х карт и для всех 4-х характеристик карты с помощью функций высшего порядка reduce с начальным значением, равным 0, и аккумулирующими функциями {$0 + $1.number.rawValue}, {$0 + $1.color.rawValue}, {$0 + $1.shape.rawValue}, { {$0 + $1.fill.rawValue}. Каждый элемент массива sums должен быть кратен 3-м, и мы опять используем функцию reduce, но на этот раз с начальным значением, равным true и аккумулирующей логической функцией "AND" {$0 && ($1 % 3) == 0}. В Swift 5 для проверки кратности одного числа другому введена функция isMultiply(of:) вместо оператора % остатка от деления. Это еще улучшит читаемость кода : { $0 && ($1.isMultiply(of:3) }.Этот фантастически короткий код для выяснения того, являются ли 3
SetCard карты SET-ом, получен благодаря "функциональному" подходу, и мы можем удостовериться в его работоспособности на Playground:
Как на этой Модели игры
SET построить пользовательский интерфейс (UI) можно посмотреть здесь, здесь и здесь.Чистые функции и побочные эффекты
Чистая функция выполняет два условия. Она всегда возвращает один и тот же результат при одних и тех же входных параметрах. И вычисление результата не вызывает побочных эффектов, связанных с выводом данных во вне (например, на диск) или с заимствованием исходных данных извне (например, времени). Это позволяет существенно оптимизировать код.
Эта тема для
Swift прекрасно изложена на сайте point.free в самых первых эпизодах "Functions" и "Side Effects", которые переведены на русский язык и представлены как "Функции" и «Побочные эффекты».Композиция функций
В математическом смысле это означает применение одной функции к результату другой функции. В
Swift функции могут возвращать значение, которое вы можете использовать как вход для другой функции. Это общая практика программирования.Представим, что у нас есть массив целых чисел и мы хотим на выходе получить массив квадратов уникальных четных чисел. Обычно мы реазизуем это следующем образом:
var integerArray = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 5]
func unique(_ array: [Int]) -> [Int] {
return array.reduce(into: [], { (results, element) in
if !results.contains(element) { results.append(element) }
})
}
func even(_ array: [Int]) -> [Int] {
return array.filter{ $0%2 == 0}
}
func square(_ array: [Int]) -> [Int] {
return array.map{ $0*$0 }
}
var array = square(even(unique(integerArray))) // it returns [4, 16, 36, 64]
Этот код дает нам правильный реультат, но вы видите, что читаемость последней строки кода не такая уж легкая. Последовательность функций (справа налево) противоположна той, к которой мы привыкли (слева направо) и хотели бы здесь видеть. Нам нужно направить нашу логику сначала в самую внутреннюю часть многократного вложения — на массив
integerArray, затем на внешнюю по отношению к этому массиву функцию unique, затем поднимаемся еще на один уровень вверх — функция even, и, наконец в заключении функция square.И здесь нам на помощь приходят операторы «композиции» функций
>>> и |>, которые позволяют нам записать код в очень удобном виде, представляющем обработку исходного массива integerArray в виде «конвейера» функций:var array1 = integerArray |> unique >>> even >>> square
Почти во всех специализированных языках функционального программирования типа
F#, Elixir и Elm используются эти операторы для «композиции» функций. В
Swift нет встроенных операторов «композиции» функций >>> и |>, но мы можем их очень легко получить с помощью Generics, замыканий (closure) и infix оператора:precedencegroup ForwardComposition{
associativity: left
higherThan: ForwardApplication
}
infix operator >>> : ForwardComposition
func >>> <A, B, C>(left: @escaping (A) -> B, right: @escaping (B) -> C) -> (A) -> C {
return { right(left($0)) }
}
precedencegroup ForwardApplication {
associativity: left
}
infix operator |> : ForwardApplication
func |> <A, B>(a: A, f: (A) -> B) -> B {
return f(a)
}
Несмотря на дополнительные затраты, это в некоторых случаях может существенно повысить производительность, читаемость и тестируемость вашего кода. Например, когда внутри
map вы размещаете целую цепочку функций с помощью оператора «композиции» >>> вместо того, чтобы гонять массив через многочисленные map:var integerArray1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 5]
let b = integerArray1.map( { $0 + 1 } >>> { $0 * 3 } >>> String.init)
print (b)
// ["6", "9", "12", "15", "18", "21", "24", "27", "30", "6", "15", "18"]
Но не всегда функциональный подход дает положительный эффект.
Поначалу, когда появился
Swift в 2014 году, все бросились писать библиотеки с операторами для «композиции» функций и решать сложную для того времени задачу типа парсинга JSON с помощью операторов функционального программирования вместо того, чтобы использовать бесконечно вложенные конструкции if let. Я сама переводила восхитившую меня своим элегантным решением статью о функциональном парсинге JSON и была поклонницей библиотеки Argo.Но разработчики
Swift пошли совершенно другим путем и предложили на основе протоколо-ориентированной технологии значительно более лаконичный способ написание кода. Для того, чтобы «доставить» JSON-данные прямо в Модель, достаточно сделать эту Модель Codable, что автоматически реализует этот протокол, если ваша Модель состоит из известных Swift структур данных: String, Int, URL, Array, Dictionary и т.д.struct Blog: Codable {
let id: Int
let name: String
let url: URL
}
Имея
JSON данные из той знаменитой статьи …[
{
"id" : 73,
"name" : "Bloxus test",
"url" : "http://remote.bloxus.com/"
},
{
"id" : 74,
"name" : "Manila Test",
"url" : "http://flickrtest1.userland.com/"
}
]
… в настоящий момент вам достаточно одной строки кода для получения массива блогов
blogs:let blogs = Bundle.main.path(forResource: "blogs", ofType: "json")
.map(URL.init(fileURLWithPath:))
.flatMap { try? Data.init(contentsOf: $0) }
.flatMap { try? JSONDecoder().decode([Blog].self, from: $0) }
print ("\(blogs!)")
// [id: 73 name: Bloxus test url: http://remote.bloxus.com/,
// id: 74 name: Manila Test url: http://flickrtest1.userland.com/]
Все благополучно забыли об использовании операторов «композиции» функций для парсинга
JSON, если есть другой, более понятный и легкий способ это сделать с использованием протоколов. Если все так легко, то мы можем «закачивать»
JSON данные и в более сложные Модели. Допустим, что у нас есть файл c JSON данными, который имеет имя user.json и находится в нашей директории Resources. В нем находятся данные о некотором пользователе:{
"email": "blob@pointfree.co",
"id": 42,
"name": "Blob"
}
И у нас есть
Codable Модель пользователя User с инициализатором из данных json:struct User: Codable {
let email: String
let id: Int
let name: String
init?(json: Data) {
if let newValue = try? JSONDecoder().decode(User.self, from: json) {
self = newValue
} else {
return nil
}
}
}
Мы очень просто можем получить нового пользователя
newUser с помощью еще более простого функционального кода:let newUser = Bundle.main.path(forResource: "user", ofType: "json")
.map(URL.init(fileURLWithPath:))
.flatMap { try? Data.init(contentsOf: $0) }
.flatMap { User.init(json: $0) }
Очевидно, что ТИП
newUser будет Optional, то есть User?:
Допустим, что у нас в директории
Resources есть еще один файл с именем invoices.json и в нем находятся данные об инвойсах этого пользователя.[
{
"amountPaid": 1000,
"amountDue": 0,
"closed": true,
"id": 1
},
{
"amountPaid": 500,
"amountDue": 500,
"closed": false,
"id": 2
}
]
Мы можем загрузить эти данные точно также, как делали это с
User. Давайте определим в качестве Модели инвойса структуру struct Invoice …struct Invoice: Codable {
let amountDue: Int
let amountPaid: Int
let closed: Bool
let id: Int
}
… и декодировать представленный выше
JSON в массив инвойсов invoices, изменив только путь к файлу и логику декодирования decode:let invoices = Bundle.main.path(forResource: "invoices", ofType: "json")
.map( URL.init(fileURLWithPath:) )
.flatMap { try? Data.init(contentsOf: $0) }
.flatMap { try? JSONDecoder().decode([Invoice].self, from: $0) }
ТИП invoices будет [Invoice]?:
Теперь нам бы хотелось соединить пользователя
user вместе с его инвойсами invoices, если они оба не равны nil, и сохранить, например, в структуре конверта UserEnvelope, который посылается пользователю вместе с его инвойсами:struct UserEnvelope {
let user: User
let invoices: [Invoice]
}
Вместо того, чтобы выполнять двукратно
if let …if let newUser = newUser, let invoices = invoices {
}
… давайте напишем функциональный аналог двойного
if let как вспомогательную Generic функцию zip, преобразующую два Optional значения в Optional кортеж :func zip<A, B>(_ a: A?, _ b: B?) -> (A, B)? {
if let a = a, let b = b { return (a, b) }
return nil
}
Теперь у нас нет причин что-то присваивать переменным
newUser и invoices, мы просто встроим все в нашу новую функцию zip, используем инициализатор UserEnvelope.init и все будет работать!let userEnv = zip(
Bundle.main.path(forResource: "user", ofType: "json")
.map(URL.init(fileURLWithPath:))
.flatMap { try? Data.init(contentsOf: $0) }
.flatMap { User.init(json: $0) },
Bundle.main.path(forResource: "invoices", ofType: "json")
.map(URL.init(fileURLWithPath:))
.flatMap { try? Data.init(contentsOf: $0) }
.flatMap { try? JSONDecoder().decode([Invoice].self, from: $0) }
).flatMap (UserEnvelope.init)
print ("\(userEnv!)")
// UserEnvelope(user: id: 42 name: Blob ,
// invoices: [id: 1 amountDue: 0 amountPaid: 1000 closed: true,
// id: 2 amountDue: 500 amountPaid: 500 closed: false])
В одном единственном выражении упакован целый алгоритм доставки
JSON данных в сложную Модель в виде структуры struct UserEnvelope.- Когда мы видим
zip, мы знаем, что комбинируем множество контекстуально независимых значений в одно целое. В нашем случае пользователяuser,JSONзагруженного с диска, и массива инвойсовinvoices, также загруженных с диска вJSONформате. Ни одно из этих значений не зависит от другого. - Когда мы видим
map, мы знаем, что выполняем «чистое» безошибочное преобразование над определенным значением внутри контекста. - Когда мы видим
flatMap, мы знаем, что выполняем преобразование над определенным значением внутри контекста, которое может приводить к ошибке.
Операции
zip, map и flatMap представляют собой своебразный предметно-ориентированный язык (domain-specific language, DSL) для преобразования данных.Мы можем и дальше развивать этот демонстрационный пример на предмет представления асинхронного считывания содержимого файла в виде специальной функции, которую вы можете посмотреть на сайте pointfree.co.
Я не являюсь фанатичной поклонницей Функционального Программирования везде и во всем, однако умеренное его использование мне представляется целесообразным.
Заключение
Я привела примеры различных возможностей функционального программирования
Swft «из коробки», основанные на применении функций высшего порядка map, flatMap, reduce, filter и других для последовательностей Sequence, Optional и Result. Именно они могут быть «рабочими лошадками» создания кода в Модели, особенно если там задействованы value ТИПЫ — структуры struct и перечисления enum. Разработчик iOS приложений должен владеть этим инструментом.Все демонстрационные примеры, собранные на
Playground, можно найти на Github. Если у вас будут проблемы с запуском Playground, можно посмотреть эту статью:Как избавиться от ошибок «зависания» Xcode Playground с сообщениями «Launching Simulator» и «Running Playground».
Ссылки:
Functional Programming in Swift: An Introduction.
An Introduction to Functional Programming in Swift.
The Many Faces of Flat-Map: Part 3
Inside the Standard Library: Sequence.map()
Practical functional programming in Swift
