Иногда возникает необходимость в организации отказоустойчивого хранилища СХД маленького объема до 20Тб, но с функционалом Enterprise — All-Flash, SSD кэш, MPIO,HA(Activ-Activ) и всё это с бюджетной ценой. Готовые аппаратные решения с данными функциями начинаются от сотен терабайт и цены из 8 и более знаков в рублях. Имея маленький бюджет 6-7 знаков в р. и необходимость в маленьком и быстром (но надежном) хранилище, с 2009 года были опробованы и переведены в промышленную эксплуатацию два варианта СХД (Общее у этих систем это, высоконадёжные системы без единой точки отказа +можно потрогать руками до покупки или «обойтись без неё»(FREE)).
Кому интересен данный опыт, далее будет описано следующее:
StarWind Virtual SAN (VSAN) – в решении Activ- Activ (синхронная репликация на 3-х серверах), в эксплуатации с 2009 -2016 год в разных редакциях(Starwind ISCSI SAN HA-3) на основании серверов с аппаратными RAID массивами.
Плюсы:
Минусы:
Возможно уже вылеченные проблемы(ранее случившиеся при эксплуатации в нашем ЦОД):
Полезные новости(ещё не опробованные):
StarWind Virtual SAN for vSphere (гиперконвергентное решение), позволяет встраивать в кластер виртуализации Vmware без привязки к Windows серверам(на базе линукс виртуальных машин).
Резюме: Отказоустойчивое решение, при наличии нормальной программы замены аппаратных серверов по окончании гарантии и наличии технической поддержки StarWindSoftWare.
Постановка задачи:
Создать отказоустойчивую сеть хранения данных небольшого объема итого 4 TB-20TB, с гарантированным функционированием в среднесрочной перспективе без значительных дополнительных финансовых затрат.
Исходные данные:
Расчет характеристик
Чтобы избежать узкие мест в части производительности при использовании SSD дисков, которая будет срезаться, чем то из цепочки оборудования: сетевые карты ,RAID (HBA) контроллер, экспандер (корзина), диски.
Необходимо на момент создания предусмотреть исходя их требуемых характеристик определенную конфигурацию оборудования.
Можно конечно запустить на 1Gb/s сетях и 3G контроллерах конфигурация с SSD кешированием SAS HDD, но результат будет в 3-7 раз хуже, чем на 6Gb RAID и 10Gb/s сетях (проверено тестами).
В инструкции по тюнингу VxFlexOS описана простая инструкция по расчету необходимой пропускной способности, исходя из оценки SSD -450 МБ/C и HDD -100 МБ/C, при последовательной записи (на пример при ребалансе и ребильде серверов хранения).

Например:
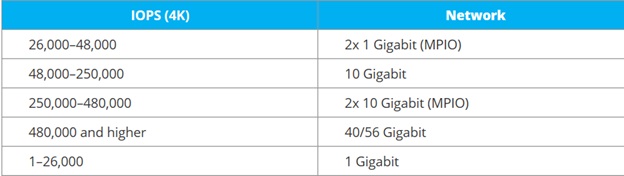
Для определения пропускной способности сети по IOPS (штатная нагрузка на серверах баз данных и нагруженных виртуальных серверах), есть ориентировочная таблица от StariWindSoftware
Итоговая конфигурация:
Способ решения
На данный момент не найдено бюджетных вариантов «Аппаратных Enterprise СХД» маленького объема, с указанными выше требованиями.
Остановились на программных решениях, позволяющих пользоваться преимуществами Enterprise СХД, при варианте использования существующих серверов, которые при этом варианте имеют право умереть от старости без ущерба СХД.
Для ускорение операций чтения, записи в систем хранения применялись SSD устройства:
3.1. Контролеры с функциями SSD кэширования.
В 2010 году появились RAID контролеры с функциями SSD кэширования Adaptec 5445 с MaxIQ диском(для ощутимого результата нужно было иметь хотя бы 10% MaxIQ диска от объема кэшируемого тома), результат есть но незначительный *проверено на себе;
Позже появились контролеры которые могут использовать произвольный SSD диск для кэширования, как у Adaptec серия Q, так и LSI CacheCade ( но там лицензирование отдельно);
3.2. Программное кэширование с использование дисков, типа Intel DC S3700, которые видит контроллер и экспандер брендовых серверов HP, IBM, FUJI ( большинство серверов их удачно опознает, для All-Flash дороговато, а вот для 10% на SSD cache — терпимо не выпуски их под партномерами IBM, HP, FUJI, а просто Intel). *Но сейчас есть более дешевые совместимые варианты(см.п. 3.5.);
3.3. Программное кэширование с использование адаптера PCIe- M.2, SSD Synology M.2 M2D18 , проверено, работает и в обычных серверах( не только в Synology), полезно когда RAID контроллер и корзина отказывается видеть SSD, которые не указал производитель в совместимых (н.п. HP D2700)? *;
3.4. Гибридные диски Seagate EXOS, н.п. 600Gb Seagate Exos 10E2400 (ST600MM0099) {SAS 12Gb/s, 10000rpm, 256Mb, 2.5"}, * проверено опознается серверами HP,IBM, FUJI (альтернатива вариантам 3.1.-3.3.);
3.5. Диски SSD c большим ресурсом и сопоставимой ценой с SAS корпоративного класса,
Crucial Micron 5200 MAX MTFDDAK480TDN-1AT1ZABYY, *проверено опознается серверами HP,IBM, FUJI
(альтернатива вариантам замены HDD дисков на совместимые по п.3.4 и совместимые со старыми серверами SAS диски: Жесткий диск SAS2.5" 600GB AL14SEB060N TOSHIBA*,
C10K1800 0B31229 HGST, ST600MM0099 SEAGATE ). Позволяет бюджетно перейти от HDD+SSD, к All-Flash томам.;
СХД EMC ScaleIO (VxFlexOS)
После тестирования решения до покупки, пришел к выводу, что для нормального функционирования системы необходимо более 3-х нод (при 3 нестабильно отработка отказа), для примера возьмет конфигурацию из 8 серверов (переживет без потери томов последовательный отказ 4 серверов).
Аппаратная часть:
FUJI CX2550M1 (E5-2xxx)– 3 шт. (основной кластер виртуализации серверов VmWare VSphere + ScaleIO клиент SDC и сервер SDS);
+5 серверов поколения HP G6(G7) или IBM M3 (e55xx-x56xx) — сервера ScaleIO SDS;
+ 2 коммутатора NetGear XS712T-100NES
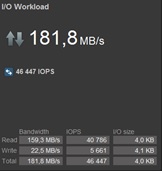
На работающем СХД в режиме RFCache, удалось при помощи Iometer разогнать до 44KIops
Конфигурация СХД:
12TB сырой емкости(минимальная лицензия на момент когда еще продавалась как софт)

8 серверов SDS 28 дисков

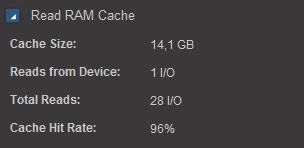
Read RAM cache 14 Gb
Read Flash cashe 1,27 TB (RFCashe)

В промежуточном варианте, где только 3 серверах 2х10Gb имеют сетевые карты, в остальных 2 х1Gb.

Наглядно видно, что даже при SSD кэшировании при 1Gb вместо 10Gb, идет потеря пропускной способности SDS в три раза и более, при идентичных носителях.
Без кеширования, если считать по данным «нормативам» то при 28 дисках HDD,
получим 28Х140=3920 IOPS, т.е. чтобы получить результат в 44000 IOPS нужно было бы в 11 раз больше дисков. Экономически выгодней при малых потребностях в объемах, не увеличивать количество дисков а, SSD кэш.
На вопрос, зачем такие скорости при маленьком объеме, отвечу сразу!
Есть такие маленькие организации(как наша), в которых есть большое количество электронных документов, которые в программном комплексе обрабатываются долго (контроли каждого реестр на отправку ПП до 1 часа, даже на этом разогнанном СХД). Все остальные варианты уже применены ранее (увеличение на РМ -ОЗУ, CPU i5, SSD, 1Gb- NET). Даже применение на СХД только связки SSD+SAS (пока без ALL-Flash) позволило использовать большую часть ресурсов серверов виртуализации, перенос нагруженных ВМ на ScaleIO — увеличил загрузку процессоров FUJI CX400M1 в два раза (ранее сдерживало хранилище).
Кому интересен данный опыт, далее будет описано следующее:
- Опыт эксплуатации ПО StarWind Virtual SAN (VSAN).
- Как сделать маленькое Enterprise СХД.
- История разгона IOPS(практика).
- Шпаргалка по развертыванию и эксплуатации СХД EMC ScaleIO (VxFlexOS) (при отсутствии технической поддержки силами специалистов «НЕ Linux-guru») 1 часть.
1. Опыт эксплуатации ПО StarWind Virtual SAN (VSAN)
StarWind Virtual SAN (VSAN) – в решении Activ- Activ (синхронная репликация на 3-х серверах), в эксплуатации с 2009 -2016 год в разных редакциях(Starwind ISCSI SAN HA-3) на основании серверов с аппаратными RAID массивами.
Плюсы:
- Легко и быстро, устанавливается даже не профессионалом;
- MPIO по ISCSI Ethernet;
- HA (Activ-Activ);
- На новых (гарантийных) серверах (с новыми дисками) можно на несколько лет забыть об обслуживании СХД (пользователи не заметят даже выход из строя двух серверов из трех);
- RAM и SSD кэш томов;
- Быстрая Fast-синхронизация при мелких сбоях в сети.
Минусы:
- Ранее существовала только версия под Windows платформу;
- При длительной эксплуатации (более 3 лет) – трудно найти диск взамен вышедшего из строя (сняты с производства) для ремонта RAID массива (при разнородных дисках возможны сбои в массиве);
- Увеличение количества сетевых интерфейсов и занимаемых под них слотов PCI(дополнительно для синхронизации -сетевые карты, коммутаторы) ;
- При использовании LSFS- «журналируемой файловой системы», длительное выключение системы, которое может быть пагубно при срабатывании UPS при отключении питания;
- Очень длительное время полной синхронизации при большом томе.
Возможно уже вылеченные проблемы(ранее случившиеся при эксплуатации в нашем ЦОД):
- При развале RAID массива – сервер остается виден по каналу синхронизации и данных, но диск в Windows сервере вне сети, раздувается лог Starwind и пожирается память сервера, как следствие зависание сервера. Возможное лечение назначение контрольного файла и убирание из настроек логов не критичных сообщений.
- При выходе из строя коммутатора или сетевых интерфейсов – неоднозначный выбор ведущего сервера (иногда случалось- система не могла понять с кого синхронизировать).
Полезные новости(ещё не опробованные):
StarWind Virtual SAN for vSphere (гиперконвергентное решение), позволяет встраивать в кластер виртуализации Vmware без привязки к Windows серверам(на базе линукс виртуальных машин).
Резюме: Отказоустойчивое решение, при наличии нормальной программы замены аппаратных серверов по окончании гарантии и наличии технической поддержки StarWindSoftWare.
2. Как сделать маленькое Enterprise СХД
Постановка задачи:
Создать отказоустойчивую сеть хранения данных небольшого объема итого 4 TB-20TB, с гарантированным функционированием в среднесрочной перспективе без значительных дополнительных финансовых затрат.
- Cистема должна быть отказоустойчивой (спокойно переносить выход из строя, как минимум одного коммутатора, одного сервера, дисков и сетевых карт в сервере).
- По максимуму использовать все ресурсы имеющегося аппаратного парка серверов (3-10 летних серверов и коммутаторов).
- Обеспечивать функционирование томов разных уровней: All-Flash и HDD +SSD cache.
Исходные данные:
- ограниченный бюджет;
- оборудование поколения 3-10 летней давности;
- специалисты — «Не Linux- Guru».
Расчет характеристик
Чтобы избежать узкие мест в части производительности при использовании SSD дисков, которая будет срезаться, чем то из цепочки оборудования: сетевые карты ,RAID (HBA) контроллер, экспандер (корзина), диски.
Необходимо на момент создания предусмотреть исходя их требуемых характеристик определенную конфигурацию оборудования.
Можно конечно запустить на 1Gb/s сетях и 3G контроллерах конфигурация с SSD кешированием SAS HDD, но результат будет в 3-7 раз хуже, чем на 6Gb RAID и 10Gb/s сетях (проверено тестами).
В инструкции по тюнингу VxFlexOS описана простая инструкция по расчету необходимой пропускной способности, исходя из оценки SSD -450 МБ/C и HDD -100 МБ/C, при последовательной записи (на пример при ребалансе и ребильде серверов хранения).
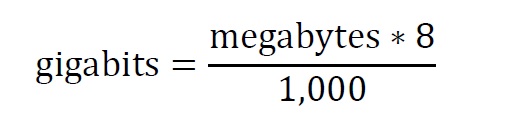
Например:
- (SSD кэш + 3 HDD), получаем ((450*1)+(3*100))*8/1000= 6Гб
- (ALL FLASH SSD) + (SSD кэш + 3 HDD) ((450*2)+(3*100))*8/1000= 9,6Гб
Для определения пропускной способности сети по IOPS (штатная нагрузка на серверах баз данных и нагруженных виртуальных серверах), есть ориентировочная таблица от StariWindSoftware
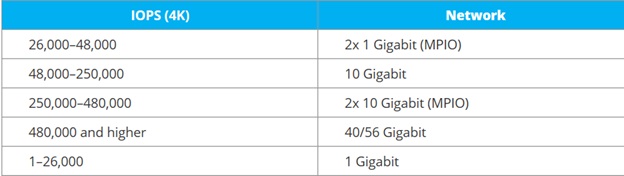
Итоговая конфигурация:
- ПО СХД, которое может не объединять диски в RAID-массивы, а передавать их СХД в виде отдельных дисков (чтоб не было проблем с заменой через определенный период дисков при выходе их из строя, а просто подбирать их по емкости);
- Сервера Поколения процессоров e55xx- x56xx и выше, шинами pci-express v 2.0 и выше, Raid (HBA) контроллерами 6G -12Gс памятью, корзинами экспандерами на 6-16 дисков;
- Коммутаторы SMB 10G Layer 2 (JUMBO FRAME, LACP).
Способ решения
На данный момент не найдено бюджетных вариантов «Аппаратных Enterprise СХД» маленького объема, с указанными выше требованиями.
Остановились на программных решениях, позволяющих пользоваться преимуществами Enterprise СХД, при варианте использования существующих серверов, которые при этом варианте имеют право умереть от старости без ущерба СХД.
- Сeph — не хватает Linux специалистов;
- EMC ScaleIO — за пару лет технической поддержки — можно обойтись существующими кадрами.
- (как оказалось, познания в Linux можно иметь минимальные, об это дальше в шпаргалке).
3. История разгона IOPS (бюджетная практика)
Для ускорение операций чтения, записи в систем хранения применялись SSD устройства:
3.1. Контролеры с функциями SSD кэширования.
В 2010 году появились RAID контролеры с функциями SSD кэширования Adaptec 5445 с MaxIQ диском(для ощутимого результата нужно было иметь хотя бы 10% MaxIQ диска от объема кэшируемого тома), результат есть но незначительный *проверено на себе;
Позже появились контролеры которые могут использовать произвольный SSD диск для кэширования, как у Adaptec серия Q, так и LSI CacheCade ( но там лицензирование отдельно);
3.2. Программное кэширование с использование дисков, типа Intel DC S3700, которые видит контроллер и экспандер брендовых серверов HP, IBM, FUJI ( большинство серверов их удачно опознает, для All-Flash дороговато, а вот для 10% на SSD cache — терпимо не выпуски их под партномерами IBM, HP, FUJI, а просто Intel). *Но сейчас есть более дешевые совместимые варианты(см.п. 3.5.);
3.3. Программное кэширование с использование адаптера PCIe- M.2, SSD Synology M.2 M2D18 , проверено, работает и в обычных серверах( не только в Synology), полезно когда RAID контроллер и корзина отказывается видеть SSD, которые не указал производитель в совместимых (н.п. HP D2700)? *;
3.4. Гибридные диски Seagate EXOS, н.п. 600Gb Seagate Exos 10E2400 (ST600MM0099) {SAS 12Gb/s, 10000rpm, 256Mb, 2.5"}, * проверено опознается серверами HP,IBM, FUJI (альтернатива вариантам 3.1.-3.3.);
3.5. Диски SSD c большим ресурсом и сопоставимой ценой с SAS корпоративного класса,
Crucial Micron 5200 MAX MTFDDAK480TDN-1AT1ZABYY, *проверено опознается серверами HP,IBM, FUJI
(альтернатива вариантам замены HDD дисков на совместимые по п.3.4 и совместимые со старыми серверами SAS диски: Жесткий диск SAS2.5" 600GB AL14SEB060N TOSHIBA*,
C10K1800 0B31229 HGST, ST600MM0099 SEAGATE ). Позволяет бюджетно перейти от HDD+SSD, к All-Flash томам.;
4. Шпаргалка по развертыванию и эксплуатации СХД EMC ScaleIO (VxFlexOS) 1часть
СХД EMC ScaleIO (VxFlexOS)
После тестирования решения до покупки, пришел к выводу, что для нормального функционирования системы необходимо более 3-х нод (при 3 нестабильно отработка отказа), для примера возьмет конфигурацию из 8 серверов (переживет без потери томов последовательный отказ 4 серверов).
Аппаратная часть:
FUJI CX2550M1 (E5-2xxx)– 3 шт. (основной кластер виртуализации серверов VmWare VSphere + ScaleIO клиент SDC и сервер SDS);
+5 серверов поколения HP G6(G7) или IBM M3 (e55xx-x56xx) — сервера ScaleIO SDS;
+ 2 коммутатора NetGear XS712T-100NES
На работающем СХД в режиме RFCache, удалось при помощи Iometer разогнать до 44KIops

Конфигурация СХД:
12TB сырой емкости(минимальная лицензия на момент когда еще продавалась как софт)
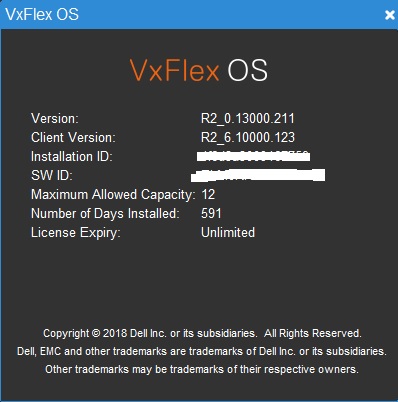
8 серверов SDS 28 дисков
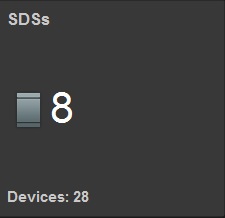
Read RAM cache 14 Gb
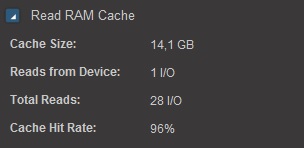
Read Flash cashe 1,27 TB (RFCashe)

В промежуточном варианте, где только 3 серверах 2х10Gb имеют сетевые карты, в остальных 2 х1Gb.

Наглядно видно, что даже при SSD кэшировании при 1Gb вместо 10Gb, идет потеря пропускной способности SDS в три раза и более, при идентичных носителях.
Без кеширования, если считать по данным «нормативам» то при 28 дисках HDD,
получим 28Х140=3920 IOPS, т.е. чтобы получить результат в 44000 IOPS нужно было бы в 11 раз больше дисков. Экономически выгодней при малых потребностях в объемах, не увеличивать количество дисков а, SSD кэш.
На вопрос, зачем такие скорости при маленьком объеме, отвечу сразу!
Есть такие маленькие организации(как наша), в которых есть большое количество электронных документов, которые в программном комплексе обрабатываются долго (контроли каждого реестр на отправку ПП до 1 часа, даже на этом разогнанном СХД). Все остальные варианты уже применены ранее (увеличение на РМ -ОЗУ, CPU i5, SSD, 1Gb- NET). Даже применение на СХД только связки SSD+SAS (пока без ALL-Flash) позволило использовать большую часть ресурсов серверов виртуализации, перенос нагруженных ВМ на ScaleIO — увеличил загрузку процессоров FUJI CX400M1 в два раза (ранее сдерживало хранилище).
