Comments 68
>максимально допустимых стрессов в материале
Напряжений. Просто напряжений, нет?
Напряжений. Просто напряжений, нет?
UFO just landed and posted this here
Тут наверное имеется ввиду в одном линейном направлении, то бишь 32768*32768 ~ 1млрд элементов.
Нет, думаю, что моя оценка верна. Столь большие модели они не пробовали делать, это довольно ясно следует из статьи и сопроводительного файла примеров.
>> И чем мельче сетка, тем более оптимальную конструкцию вроде можно выжать. И тем более «фрактальной»(ажурной) она будет.
Если штрафовать за фрактальность в кост функции — то может и не быть.
Если штрафовать за фрактальность в кост функции — то может и не быть.
Как Вы хотите описать то, что Вы называете «фрактальностью» в целевой функции?
(это не фрактальность, конечно. Более того, фрактальность может быть ценным и полезным качеством — посмотрите на древоподобные решения опор, они и надёжны и красивы. И фрактальны)
(это не фрактальность, конечно. Более того, фрактальность может быть ценным и полезным качеством — посмотрите на древоподобные решения опор, они и надёжны и красивы. И фрактальны)
Ограничение на толщину эелемента вполне себе убивает фрактальность (это не мой мопет — выше так назвали, но мы то знаем о чем мы говорим, да?).
>> фрактальность может быть ценным и полезным качеством
Несомненно, вот только реальный мир подразумевает дефекты изготовления и самой структуры материала. Нужно как-то задавать запас, а-то получится структура из «паутинок», которая по теории супер прочная. А что будет, если одна паутинка сломается? Не повлечет ли это цепной реакции, которая сложит весь домик?
Во всем должен быть баланс.
>> фрактальность может быть ценным и полезным качеством
Несомненно, вот только реальный мир подразумевает дефекты изготовления и самой структуры материала. Нужно как-то задавать запас, а-то получится структура из «паутинок», которая по теории супер прочная. А что будет, если одна паутинка сломается? Не повлечет ли это цепной реакции, которая сложит весь домик?
Во всем должен быть баланс.
UFO just landed and posted this here
Тем более я в другом комменте предлагал сделать еще надежнее — залить смолой пустоты.
Блин, Вы о чём вообще? Какой смолой Вы собрались заливать пустоты в конструкции моста? Вы, похоже, держите в голове одну конретную модель нужного изделия и подгоняете под неё всё, что видите. Работа не об этом. Пожалуйста, не надо зашумлять коменты.
UFO just landed and posted this here
Ограничение на толщину эелемента вполне себе убивает фрактальность (это не мой мопет — выше так назвали, но мы то знаем о чем мы говорим, да?).
Хотел было пораздражаться на отсутствие конкретики реализации этого ограничения, но потом пришла в голову более интересная мысль по теме… На втором шаге после нормирования логитов сигмоидой они там используют некий cone-filter с радиусом 2 (который, скорее всего является известным инструментом, поэтому о нём нет никаких деталей, однако его до сих пор никто из отметившихся не опознал)… Так вот судя по тому, что, скорее всего, это морфологический фильтр, тогда он может в том числе налагать некоторые имплицитные ограничения на вид результирующей структуры, как раз убирая слишком мелкие детали. У них в статье нет сведений, использовался ли он в бейслайновых методах (и если да, с какими параметрами? — впрочем, если это стандартный фильтр, то мог использоваться) и в контрольном Pixel-LBFGS… Если он был только в НС-версии оптимизатора, то вполне возможно, что это он влияет на отсутствие паутины… Попробую связаться с авторами и уточнить. Момент любопытный.
Несомненно, вот только реальный мир подразумевает дефекты изготовления и самой структуры материала. Нужно как-то задавать запас, а-то получится структура из «паутинок», которая по теории супер прочная. А что будет, если одна паутинка сломается? Не повлечет ли это цепной реакции, которая сложит весь домик?
Ну да, думаю, это как раз одна из важных причин, кроме нетехнологичности, почему паутина обычно(!) вредна.
В продолжение прошлого комента.
Уже получил ответ от первого автора, Stephan Hoyer (вот это я понимаю подход к работе!). Сейчас нет времени разбирать всё подробно, в течение пары-тройки дней сделаю. Кратко — да, я правильно нашёл описание cone-filter, это именно он, и да, они использовали его с одинаковыми параметрами в каждом алгоритме, что уже само по себе делает гипотезу о его (существенном) влиянии на паутину, в общем, скорее неверной. Но ещё подумаю, потом напишу апдейт.
зы: ещё Стефан сказал, что они планируют скоро выложить код работы на Гитхаб. Снова могу только сказать «вот это я понимаю подход к работе!» :) Пока это ещё не стало нормой, и очень круто, что они проталкивают и эту тему.
Уже получил ответ от первого автора, Stephan Hoyer (вот это я понимаю подход к работе!). Сейчас нет времени разбирать всё подробно, в течение пары-тройки дней сделаю. Кратко — да, я правильно нашёл описание cone-filter, это именно он, и да, они использовали его с одинаковыми параметрами в каждом алгоритме, что уже само по себе делает гипотезу о его (существенном) влиянии на паутину, в общем, скорее неверной. Но ещё подумаю, потом напишу апдейт.
зы: ещё Стефан сказал, что они планируют скоро выложить код работы на Гитхаб. Снова могу только сказать «вот это я понимаю подход к работе!» :) Пока это ещё не стало нормой, и очень круто, что они проталкивают и эту тему.
Итак, продолжаем тему.
После получения ответа Стефана я внёс в статью необходимые поправки и уточнения.
Главные следствия вкратце:
Теперь, что касается Вашей идеи:
Наверное, мы можем придумать и добавить в целевую функцию слагаемое, которое будет отвечать за «ажурность» конструкции, штрафуя мелкие элементы. Такой себе регуляризатор… Вполне. Однако я здесь вижу две тонкости, которые… скажем так… не делают очевидными мне пользу этого подхода:
зы офф: я так понимаю, теперь можно ожидать появление nickname22 и новой порции отжигов…
После получения ответа Стефана я внёс в статью необходимые поправки и уточнения.
Главные следствия вкратце:
- cone-filter не имеет ни малейшего отношения к фильтрам мат.морфологии, а есть ни что иное, как простейшее взвешенное среднее с ядром, линейно зависящим от расстояния до текущей точки. Принципиальных причин использовать его, а не какой-нибудь Gaussian Blur (отличие просто в том, что в Gaussian Blur ядро фильтра — тот самый колокольчик, а здесь просто конус), насколько я понимаю, нет. Просто он даёт другое сглаживание.
- Соответственно, конечно же, никакой (существенной) регуляризации это не даёт, поэтому та моя гипотеза, что он влияет на паутину, совершенно не валидна (более того, он же используется и во всех бейслайн методах, сильно более активно генерящих паутину).
- Поэтому именно эффект сверточной сети в убирании паутины максимален.
Теперь, что касается Вашей идеи:
Ограничение на толщину эелемента вполне себе убивает фрактальность (это не мой мопет — выше так назвали, но мы то знаем о чем мы говорим, да?).
Наверное, мы можем придумать и добавить в целевую функцию слагаемое, которое будет отвечать за «ажурность» конструкции, штрафуя мелкие элементы. Такой себе регуляризатор… Вполне. Однако я здесь вижу две тонкости, которые… скажем так… не делают очевидными мне пользу этого подхода:
- Мы получаем ещё один набор гиперпараметров, которые надо подбирать — по меньшей мере это один скаляр, характеризующий минимальную нештрафуемую толщину, и ещё один скаляр, составляющий величину штрафа. Лишние гиперпараметры — лишний геморрой.
- А что будем делать, когда нам может быть полезна ажурность? Мелкие элементы ведь могут быть совершенно полноценными, нужными и полезными частями решения в ряде случаев. Нас то волнует именно ненужная паутина, а не мелкость, но убирая таким образом паутину, мы вообще не сможем получить нужного решения. Оно просто будет перештрафовано и никогда не появится.
зы офф: я так понимаю, теперь можно ожидать появление nickname22 и новой порции отжигов…
UFO just landed and posted this here
То же самое, что и всё научно-инженерное сообщество. У слова «фрактал» и образованного от него прилагательного я знаю только одно определение и только один смысл (это про другой Ваш комент, на который отвечать не буду). В Википедии и определение раскрыто, и приблизительные критерии даны, и примеры (с деревьями в том числе).
Паутина — не фрактал и даже не псевдофрактал, т.к. ни одному критерию не соответствует.
Паутина — не фрактал и даже не псевдофрактал, т.к. ни одному критерию не соответствует.
UFO just landed and posted this here
UFO just landed and posted this here
UFO just landed and posted this here
«Можно делать» не значит «нужно делать». 3D печать ещё очень дорогое удовольствие и будет таковым скорее всего ещё долго. Поэтому проста и дешевизна тех.процесса — почти всегда и везде очень важны.
То что точность до микрон, еще не означает, что размер изделия достаточен. По вполне понятным причинам чем больше размер принтера — тем сложнее сделать сам принтер достаточно жестким и точным (это в общем верно для любого станка). Так что да, дорогое удовольствие, если хочется и размеры и точность.
Насчет композита — не уверен, что для таких изделий применяли, но в целом почему нет? Все эти тонкие структуры — они хорошо работают на растяжение, и плохо на сжатие (потеря устойчивости). Это вполне верно даже для точких стенок обычных баков, так что проблема давно известна, как и много лет известны некоторые решения (типа сотовых конструкций).
Насчет композита — не уверен, что для таких изделий применяли, но в целом почему нет? Все эти тонкие структуры — они хорошо работают на растяжение, и плохо на сжатие (потеря устойчивости). Это вполне верно даже для точких стенок обычных баков, так что проблема давно известна, как и много лет известны некоторые решения (типа сотовых конструкций).
Интересно, как справился бы генетический алгоритм.
О том, что их можно использовать пишут практические везде, но реальных примеров успешных использований не видел. Предположу, что как и в почти всех остальных случаях — очень медленно и, вероятно, плохо. Тут эффективный градиентный спуск, а ГА лишь несколько лучше случайного блуждания. И тоже подвержен локальным оптимумам.
Короче, в большинстве мне известных случаев, к ГА приходят совсем от безысходности, когда ничего умнее придумать не удаётся…
Короче, в большинстве мне известных случаев, к ГА приходят совсем от безысходности, когда ничего умнее придумать не удаётся…
матрицы жесткости конструкции К
Матрица жесткости рассчитывается на основе свойств материала (модуль Юнга), длин стержней (если говорить про стрежневые системы типа ферм) и моментов инерции сечений. В простейшем случае (круг, квадрат) можно связать площадь сечения и момент инерции. Возможно, U-Net субоптимально генерирует базовую структуру и «толщины» стержней, что позволяет вычислить и матрицу жесткости. А далее минимизируется truss compliance, т.е. Fu/2 с учетом Ku=F, где F — нагрузки, u — смещения узлов системы, K — матрица жесткости.
Спасибо за ценное уточнение! (первый комент по делу, не зря писал!)
Добавил в текст со ссылкой.
Немного уточню.
U-Net не то, что бы «субоптимально генерирует базовую структуру»… Она сначала вообще генерирует шум, который потом под давлением градиента целевой функции эволюционирует в решение. U-Net всегда генерирует просто монохромную картинку (примеры есть на врезках). На шаге 2 эта картинка с помощью нескольких хитрых трюков нормализуется (с точки зрения картинки — на общее количество нужного чёрного пигмента, с точки зрения физики — на общее количество нужного конструкции материала) и бинаризуется в чёрно-белую (я назвал полученное изображение каркасом, но я не уверен, что это общепринятый термин, — пока другого нет, оставляю). В этих шагах я уверен, и они описаны в статье. Соответственно, далее, учитывая Ваш комментарий, остаётся предположить, что зная свойства материала (допустим, бетона), можно ответить на вопрос, какая была бы матрица жесткости для конструкции из такого материала, описываемой таким каркасом.
Добавил в текст со ссылкой.
Немного уточню.
U-Net не то, что бы «субоптимально генерирует базовую структуру»… Она сначала вообще генерирует шум, который потом под давлением градиента целевой функции эволюционирует в решение. U-Net всегда генерирует просто монохромную картинку (примеры есть на врезках). На шаге 2 эта картинка с помощью нескольких хитрых трюков нормализуется (с точки зрения картинки — на общее количество нужного чёрного пигмента, с точки зрения физики — на общее количество нужного конструкции материала) и бинаризуется в чёрно-белую (я назвал полученное изображение каркасом, но я не уверен, что это общепринятый термин, — пока другого нет, оставляю). В этих шагах я уверен, и они описаны в статье. Соответственно, далее, учитывая Ваш комментарий, остаётся предположить, что зная свойства материала (допустим, бетона), можно ответить на вопрос, какая была бы матрица жесткости для конструкции из такого материала, описываемой таким каркасом.
Еще небольшое дополнение насчет того,
общий объем можно задать как 1, а решением задачи будут соотношения между объемами элементов конструкции (которые суммируются к 1).
как выбирается общий объём конструкции V0
общий объем можно задать как 1, а решением задачи будут соотношения между объемами элементов конструкции (которые суммируются к 1).
Наверное, это работает в обычных методах, но здесь так нельзя. Я не останавливался подробно на этом моменте в описании, думал и так понятно, но поясню.
Сначала цитата из работы (самый конец второй страницы):

Значения выходного слоя использованной НС представляют собой то, что в Машинном Обучении стали называть «логитами», — «сырой» результат (как правило, линейной, = скалярное произведение) комбинации входов нейрона с весами этих входов. Они потенциально могут иметь значения (-inf,+inf). Для дальнейшего использования логиты, надо, очевидно, как-то нормализовать в какой-то ограниченный диапазон, причём так, чтобы выполнялось ограничение на максимально допустимое количество «включённых» значений (другими словами, на максимально допустимое количество чёрного пигмента, который потребуется, чтобы нарисовать полученную картинку).
Второй нюанс. Посмотрите на этот фрагмент картинки этапов метода:
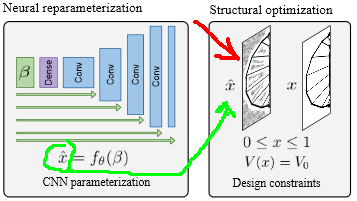
Красной стрелкой я указал вариант графического изображения выдаваемых сетью логитов (очищенная картинка справа — это уже обработанный «каркас»). НС, особенно пока настройка параметров ещё сошлась окончательно, не даст идеальной картинки. Там будет присутствовать некий шум и артефакты. Хотя со временем донастройки он и будет уменьшаться, но он никогда не сойдёт в нуль, а само его присутствие будет «размывать» полезный сигнал, влиять на градиент там, где этого не нужно и т.д. и т.п. Короче, надо бы как-то сделать так, чтобы усилить сильные логиты и ослабить слабые (опять же, выполняя при этом ограничения на объём).
Вот что сделали авторы. Есть логистическая функция (у авторов почему-то отсутствует знак «минус» перед х^, но это скорее всего просто опечатка). Вот для наглядности её график:
(у авторов почему-то отсутствует знак «минус» перед х^, но это скорее всего просто опечатка). Вот для наглядности её график:
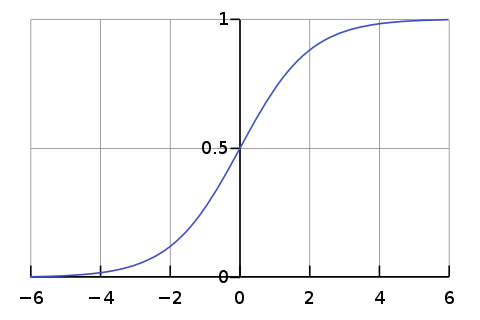
Эта функция хороша тем, что отображает область определения (-inf,+inf) в область значений (0,1) так, что за счёт экспоненты даже небольшое отклонение аргумента от 0 очень быстро начинает отображаться почти в граничные значения (~0 для х<<0 или ~1 для x>>0). Соответственно, применив её к ненормированному изображению за счёт нелинейности мы получим почти-бинарное изображение (но оно всё ещё будет дифференцироваться, в отличие от пороговой функции).
Теперь вспоминая нюанс номер 2, мы можем сразу увидеть, что если применять сигмоиду к логитам «в лоб», то у нас возможна ситуация, когда, например, даже полезный сигнал может оказаться сильно ниже «порога отсечения» (условно, значения, при котором аргумент сигмоиды отображается почти в нуль), или шум окажется сильно выше «порога отсечения». Соответственно, чтобы изменить порог отсечения, надо просто уменьшить или увеличить аргумент сигмоиды на какую-то величину, — ей является в терминах авторов работы величина b(x^,V0). Если её выбирать для исходного изображения (x^) так, чтобы «объём» (сумма значений всех точек-пикселей отнесённая к общей площади?) преобразованного изображения оказалась бы равна V0, то одновременно с улучшением соотношения сигнал/шум и нормализацией картинки в (0,1) мы ещё получим и выполнение требования на общий объём конструкции.
Таким образом, я думаю, что просто так взять и задать общий объём в 1 (или любое другое наперёд выбранное число) нельзя, потому что это одновременно влияет и на «порог» сигмоиды, — можно случайно отсечь полезный сигнал. По этой причине авторы и пробовали несколько значений V0, вместо того, чтобы просто использовать соотношения элементов конструкции
Сначала цитата из работы (самый конец второй страницы):

Значения выходного слоя использованной НС представляют собой то, что в Машинном Обучении стали называть «логитами», — «сырой» результат (как правило, линейной, = скалярное произведение) комбинации входов нейрона с весами этих входов. Они потенциально могут иметь значения (-inf,+inf). Для дальнейшего использования логиты, надо, очевидно, как-то нормализовать в какой-то ограниченный диапазон, причём так, чтобы выполнялось ограничение на максимально допустимое количество «включённых» значений (другими словами, на максимально допустимое количество чёрного пигмента, который потребуется, чтобы нарисовать полученную картинку).
Второй нюанс. Посмотрите на этот фрагмент картинки этапов метода:

Красной стрелкой я указал вариант графического изображения выдаваемых сетью логитов (очищенная картинка справа — это уже обработанный «каркас»). НС, особенно пока настройка параметров ещё сошлась окончательно, не даст идеальной картинки. Там будет присутствовать некий шум и артефакты. Хотя со временем донастройки он и будет уменьшаться, но он никогда не сойдёт в нуль, а само его присутствие будет «размывать» полезный сигнал, влиять на градиент там, где этого не нужно и т.д. и т.п. Короче, надо бы как-то сделать так, чтобы усилить сильные логиты и ослабить слабые (опять же, выполняя при этом ограничения на объём).
Вот что сделали авторы. Есть логистическая функция
(у авторов почему-то отсутствует знак «минус» перед х^, но это скорее всего просто опечатка). Вот для наглядности её график:
Эта функция хороша тем, что отображает область определения (-inf,+inf) в область значений (0,1) так, что за счёт экспоненты даже небольшое отклонение аргумента от 0 очень быстро начинает отображаться почти в граничные значения (~0 для х<<0 или ~1 для x>>0). Соответственно, применив её к ненормированному изображению за счёт нелинейности мы получим почти-бинарное изображение (но оно всё ещё будет дифференцироваться, в отличие от пороговой функции).
Теперь вспоминая нюанс номер 2, мы можем сразу увидеть, что если применять сигмоиду к логитам «в лоб», то у нас возможна ситуация, когда, например, даже полезный сигнал может оказаться сильно ниже «порога отсечения» (условно, значения, при котором аргумент сигмоиды отображается почти в нуль), или шум окажется сильно выше «порога отсечения». Соответственно, чтобы изменить порог отсечения, надо просто уменьшить или увеличить аргумент сигмоиды на какую-то величину, — ей является в терминах авторов работы величина b(x^,V0). Если её выбирать для исходного изображения (x^) так, чтобы «объём» (сумма значений всех точек-пикселей отнесённая к общей площади?) преобразованного изображения оказалась бы равна V0, то одновременно с улучшением соотношения сигнал/шум и нормализацией картинки в (0,1) мы ещё получим и выполнение требования на общий объём конструкции.
Таким образом, я думаю, что просто так взять и задать общий объём в 1 (или любое другое наперёд выбранное число) нельзя, потому что это одновременно влияет и на «порог» сигмоиды, — можно случайно отсечь полезный сигнал. По этой причине авторы и пробовали несколько значений V0, вместо того, чтобы просто использовать соотношения элементов конструкции
UFO just landed and posted this here
UFO just landed and posted this here
Ну так-то в пакетах типа ANSYS для типовых элементов (link, beam, shell и т.д.) матрицы жесткости уже заданы — иначе просчет конечно-элементных моделей длился бы вечность.
А вообще в статье как-то слишком поверхностно описана сама НС.
А вообще в статье как-то слишком поверхностно описана сама НС.
А вообще в статье как-то слишком поверхностно описана сама НС.
Наверное, потому, что для достижения заявленной цели статьи — описания метода, она не важна. Не?
Вы ещё, судя по всему, оригинальную работу не открывали. Там большинство из того, что я развёрнуто на несколько страниц тут описывал, там — полтора абзаца и отдельные фразы по тексту. И в целом — и не нужно иного, для понимания метода достаточно. Кому нужно — для того список ссылок и гугл…
Я как раз про оригинальную статью и говорю — там по каждому вопросу буквально пара фраз. Не совсем понятно, как увязали опоры, нагрузки и точки их приложения с этой «картинкой плотностей», как потом определяли, достаточно ли прочна и устойчива конструкция.
Понятно. Да, есть такое… и это ещё далеко не самая плохая статья, кстати…
Предположу, что положение опоры, приложение нагрузки и прочее просто запрограммировано как частью физ.модели для данной конкретной задачи. Соответственно, прочность, устойчивость и некоторые иные качества будут являться следствиями целевой функции податливости. Большое её значение говорит, что «что-то явно не так», а градиент позволяет двигаться в сторону «более так».
как увязали опоры, нагрузки и точки их приложения с этой «картинкой плотностей», как потом определяли, достаточно ли прочна и устойчива конструкция
Предположу, что положение опоры, приложение нагрузки и прочее просто запрограммировано как частью физ.модели для данной конкретной задачи. Соответственно, прочность, устойчивость и некоторые иные качества будут являться следствиями целевой функции податливости. Большое её значение говорит, что «что-то явно не так», а градиент позволяет двигаться в сторону «более так».
UFO just landed and posted this here

В чём отличие от этого (где-то на Хабре был перевод)?
UFO just landed and posted this here
Ну, если Вы читали то, на что Вы дали ссылку, то не могли не заметить, что там описаны только волнующие пассы руками вроде: «deep learning… уууу...blockchain generative models… уууу...» а потом так «Вжух!!!» и красивая картинка. И ни малейшей конкретики.
Это, конечно, правда. Но они, видать, посчитали это ноу-хау и решили не публиковать. Но, очевидно, вот эта новая статья не первый результат подобного рода.
А я вот очень в этом неуверен. Дьявол в деталях и что и как там было сделано (если было сделано, чего я всё же не исключаю) может чрезвычайно и принципиально отличаться от подхода, изложенного в описанной работе. Без конкретного описания что и как там делалось писать какие-то умозаключения абсолютно бессмысленно; они не стоят электричества потраченного на их передачу.
Ой, я не внимателен.
Они же написали, что основа — генеративные модели. Это совершенно другой инструмент.
Они же написали, что основа — генеративные модели. Это совершенно другой инструмент.
Кстати, вот интересное видео, где в числе прочего показано из каких предпосылок разрабатывался дизайн Sagrada Familia и как Гауди обошёлся без нейронных сетей для решения задачи оптимизации: www.youtube.com/watch?v=JlL6ZHChhQE
Интересная статья!
Несколько комментариев по ходу.
Матрица жесткости — это понятие из метода конечных элементов (МКЭ), нахождение которой там является целевой функцией и которая позволяет по заданным граничным условиям (загрузкам, закреплениям) и свойствам материала найти перемещения конечных элементов и деформацию всей конструкции. (Крылов О.В. «Метод конечных элементов»)
Обычно при решении задач оптимизации топологии используется SIMP-метод (Solid Isotropic Material with Penalization), суть которого — для решенной МКЭ-задачи, на основе матрицы напряжений создается матрица условных «плотностей» (матрица вещественных коэффициентов от 0 до 1), которая множится на матрицу жесткости модели. Те элементы, напряжения в которых были близки к 0, получают, соответственно, плотность (для расчета веса) и жесткость (для расчета деформаций) близкую к 0 и из последующего расчета выпадают. После этого МКЭ-задача заново запускается на расчет и т.д. до достижения заданных ограничений.
Собственно алгоритм построения матрицы «плотностей» и был (как я понял) сутью работы из статьи. Обычно используются различные статичные методы преобразования матриц, но здесь авторы решили каждому элементу МКЭ-модели присвоить отдельный нейрон сети и в качестве матрицы «плотностей» использовать весовые коэффициенты самой нейронки. Довольно оригинально, хотя и лежит на поверхности.
Несколько комментариев по ходу.
Матрица жесткости — это понятие из метода конечных элементов (МКЭ), нахождение которой там является целевой функцией и которая позволяет по заданным граничным условиям (загрузкам, закреплениям) и свойствам материала найти перемещения конечных элементов и деформацию всей конструкции. (Крылов О.В. «Метод конечных элементов»)
Обычно при решении задач оптимизации топологии используется SIMP-метод (Solid Isotropic Material with Penalization), суть которого — для решенной МКЭ-задачи, на основе матрицы напряжений создается матрица условных «плотностей» (матрица вещественных коэффициентов от 0 до 1), которая множится на матрицу жесткости модели. Те элементы, напряжения в которых были близки к 0, получают, соответственно, плотность (для расчета веса) и жесткость (для расчета деформаций) близкую к 0 и из последующего расчета выпадают. После этого МКЭ-задача заново запускается на расчет и т.д. до достижения заданных ограничений.
Собственно алгоритм построения матрицы «плотностей» и был (как я понял) сутью работы из статьи. Обычно используются различные статичные методы преобразования матриц, но здесь авторы решили каждому элементу МКЭ-модели присвоить отдельный нейрон сети и в качестве матрицы «плотностей» использовать весовые коэффициенты самой нейронки. Довольно оригинально, хотя и лежит на поверхности.
Спасибо за ценные дополнения! Добавлю ссылку на комент в статью.
Действительно, авторы использовали «modified SIMP» из Andreassen, E., Clausen, A., Schevenels, M., Lazarov, B. S., and Sigmund, O. Efficient topologyoptimization in MATLAB using 88 lines of code.Structural and Multidisciplinary Optimization,43(1):1–16, 2011.
поправка — выходной нейрон, точнее нейрон последнего слоя.
Нет, веса и вход НС являются лишь параметрами, влияющими на значение выходных нейронов. Если НС представить за чёрный ящик, то его выходом (в данной задаче) являются значения нейронов последнего слоя.
SIMP-метод (Solid Isotropic Material with Penalization)
Действительно, авторы использовали «modified SIMP» из Andreassen, E., Clausen, A., Schevenels, M., Lazarov, B. S., and Sigmund, O. Efficient topologyoptimization in MATLAB using 88 lines of code.Structural and Multidisciplinary Optimization,43(1):1–16, 2011.
здесь авторы решили каждому элементу МКЭ-модели присвоить отдельный нейрон сети
поправка — выходной нейрон, точнее нейрон последнего слоя.
в качестве матрицы «плотностей» использовать весовые коэффициенты самой нейронки
Нет, веса и вход НС являются лишь параметрами, влияющими на значение выходных нейронов. Если НС представить за чёрный ящик, то его выходом (в данной задаче) являются значения нейронов последнего слоя.
Ясно. Спасибо за разъяснения по поводу использования здесь нейронки. Надо будет внимательней перечитать оригинал :)
По поводу V0 — обычно в SIMP-методах задается Design Space (это вся доступная область модели, из которой потом убираются элементы), объем модели, который должен остаться (обычно в процентах от Design Space, я так понял это и есть V0) и допустимый предел деформаций конструкции, чаще всего в виде максимального перемещения какого-то одного элемента модели. Собственно, Design Space и предельные деформации задаются изначально, а величиной V0 играют, чтобы получить приемлемое соотношение веса (объема) и предельных напряжений.
По поводу V0 — обычно в SIMP-методах задается Design Space (это вся доступная область модели, из которой потом убираются элементы), объем модели, который должен остаться (обычно в процентах от Design Space, я так понял это и есть V0) и допустимый предел деформаций конструкции, чаще всего в виде максимального перемещения какого-то одного элемента модели. Собственно, Design Space и предельные деформации задаются изначально, а величиной V0 играют, чтобы получить приемлемое соотношение веса (объема) и предельных напряжений.
Да, это про V0 понятно…
Вот тут в коменте ещё дописал объяснение про V0. Видимо его действительно «в лоб» универсально не задать, надо перебирать и играцца и смотреть как влияет.
Вот тут в коменте ещё дописал объяснение про V0. Видимо его действительно «в лоб» универсально не задать, надо перебирать и играцца и смотреть как влияет.
UFO just landed and posted this here
Есть такой САПР, SolidThinking Inspire. Используется в индустрии, эффективно решает подобные задачи… Не знаю, какой там алгоритм, давно смотрел.
Можно чуть поподробнее про «дифференцируемый физический движок». Он по чему дифференцируемый?
По входам дифференцируемый, очевидно :)
Смотрите, вся эта конструкция (метод) работает, когда существует возможность вычислить градиент целевой функции, т.е. набор значений всех частных производных целевой функции по весам и входу НС. Т.е. иметь возможность для каждого конкретного значения веса/входа вычислить как (на сколько и в какую сторону) изменяется целевая функция в данной точке (пространства весов+входов). Чтобы это сделать, необходимо, чтобы вся цепочка преобразований, ведущая от данного веса до значения целевой функции, была бы дифференцируемой. Конкретно, с точки зрения физической модели это означает, аналогично, что мы должны иметь возможность вычислить, как бы изменялась целевая функция податливости конструкции при изменении любого из элементов, описывающих составные части каркаса. Соответственно, в таком случае физическая модель, позволяющая рассчитать податливость каркаса, будет являться дифференцируемой. Как-то это можно сделать, очевидно, но я не настоящий сварщик в теме вычислительной физики, конкретных деталей далее не скажу, надо разбираться…
Смотрите, вся эта конструкция (метод) работает, когда существует возможность вычислить градиент целевой функции, т.е. набор значений всех частных производных целевой функции по весам и входу НС. Т.е. иметь возможность для каждого конкретного значения веса/входа вычислить как (на сколько и в какую сторону) изменяется целевая функция в данной точке (пространства весов+входов). Чтобы это сделать, необходимо, чтобы вся цепочка преобразований, ведущая от данного веса до значения целевой функции, была бы дифференцируемой. Конкретно, с точки зрения физической модели это означает, аналогично, что мы должны иметь возможность вычислить, как бы изменялась целевая функция податливости конструкции при изменении любого из элементов, описывающих составные части каркаса. Соответственно, в таком случае физическая модель, позволяющая рассчитать податливость каркаса, будет являться дифференцируемой. Как-то это можно сделать, очевидно, но я не настоящий сварщик в теме вычислительной физики, конкретных деталей далее не скажу, надо разбираться…
Вот и я о том. Чем является вход для физического движка? Матрицей/кубом плотностей. Чем является выход движка? Предположим, что скаляром «поддатливости». Стало быть, такой движок кроме скаляра на выходе выдает еще и матрицу/куб производной «поддатливости» по плотности в каждой точке?
На эту тему в тексте даже написано. Физ.движок рассчитывает тензор (скорее всего матрица) смещения элементов каркаса под нагрузкой. Далее из него и матрицы жесткости получается скаляр — целевая функция, описывающая податливость всей конструкции.
Попытаюсь ещё раз объяснить. Вы расписали, что на выходе у любого такого движка. У дифференцируемого на выходе еще должна быть и производная/градиент. Производная чего по чему? Производная выхода по входу, так? Выход, по вашим словам — тензор (скорее всего матрица) смещения элементов под нагрузкой. На входе — матрица/куб плотностей. Так что из себя будет представлять производная? Что она описывает? Изменение всего тензора (скорее всего матрицы) при элементарном изменении плотности одного пикселя? Ведь изменение плотности любого из кубиков конструкции влияет на изменение смещения сразу во всей конструкции!
Изменение всего тензора (скорее всего матрицы) при элементарном изменении плотности одного пикселя? Ведь изменение плотности любого из кубиков конструкции влияет на изменение смещения сразу во всей конструкции!
Да какое «изменение всего тензора»… Как вы это себе представляете?..
Изменение составляющих тензора же…
Вот пусть есть матричная функция Y=F(X), где X={x_ij} — какая-то матрица и Y={y_kl} какая-то матрица произвольной размерности. Градиент DF представляет собой тензор частных производных каждого значения функции по каждому аргумента { d(y_kl)/d(x_ij) }, т.е. иначе — каждому элементу Y в градиенте соответствует матрица производных этого элемента по каждому из входов, т.е. описание как меняется каждый элемент Y при элементарном изменении каждого элемента Х, полагая остальные элементы аргумента неизменными. — Это же самое обычное определение частной производной функции многих переменных, просто расширенное на случай матриц. Если это не понятно, то надо просто разбираться с понятием частных производных и их обобщениями, потом градиентными методами. Либо я, наверное, по прежнему не понимаю, что не понятно…
(ошибка, не туда ответ ушёл)
Sign up to leave a comment.
Параметризация нейросетью физической модели для решения задачи топологической оптимизации