Инфа будет полезна JS-разработчикам, которые хотят глубоко понимать суть работы с Node.js и Event Loop. Вы сможете осознанно и более гибко управлять потоком выполнения программы (web-сервера).
Эту статью я составил по материалам своего недавнего доклада для коллег.
В конце статьи есть полезные материалы для самостоятельного изучения.
Как устроена Node.js. Возможности асинхрона
Давайте посмотрим на этот код: он отлично демонстрирует синхронность выполнения кода в Node.js. Делается запрос на GitHub, затем записываем данные в файл и выводим результат в консоли. Что понятно из этого синхронного кода?
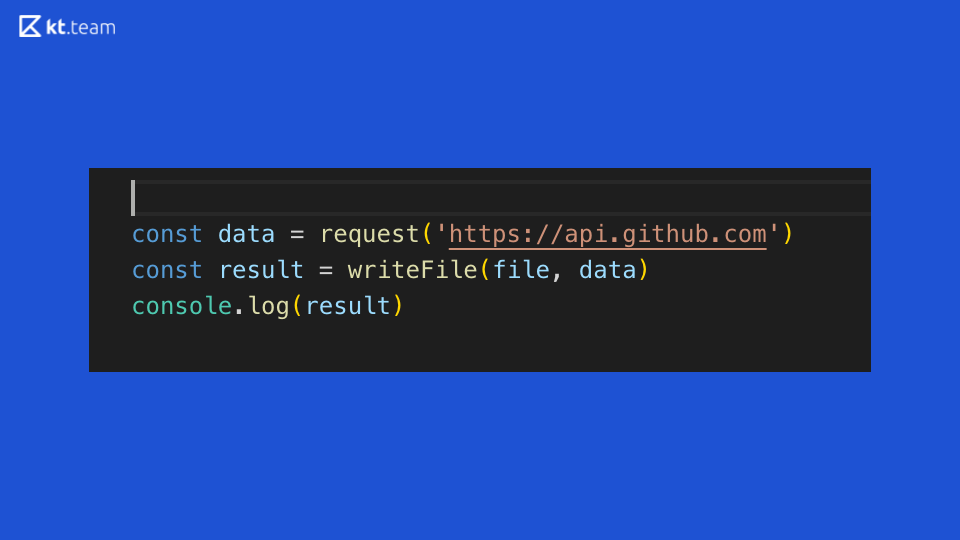
Предположим, что это абстрактный web-сервер, который по какому-то роутеру делает операции. Если по данному роутеру приходит входящий запрос, мы делаем дальше запрос, читаем файл, выводим в консоль. Соответственно, то время, которое тратится на запрос и чтение файла, сервер будет заблокирован, никакие другие входящие запросы он обрабатывать не сможет, выполнять другие операции — тоже.
Какие есть варианты решения данной проблемы?
- Многопоточность
- Неблокирующий ввод/вывод
Для первого варианта (многопоточность) есть хороший пример с web-сервером Apache vs Nginx.
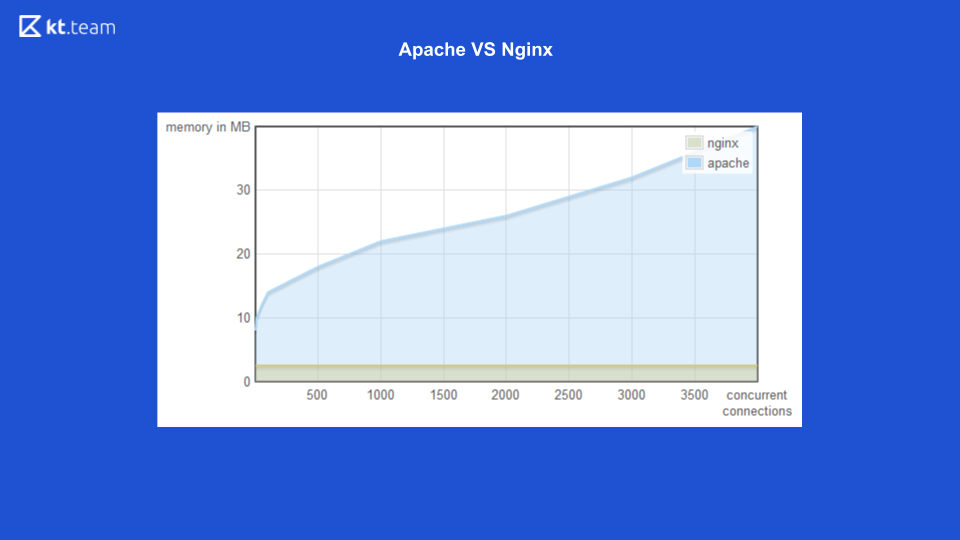
Раньше Apache под каждый входящий запрос поднимал поток: сколько было запросов, столько же было и потоков. В это время Nginx имел преимущество, т. к. использовал неблокирующий ввод/вывод. Здесь вы можете видеть, что с увеличением количества входящих запросов увеличивается объём потребляемой памяти именно у Apache, а на следующем слайде количество обрабатываемых запросов в секунду с количеством подключений у Nginx выше.

Наглядно показано, что неблокирующий ввод/вывод эффективнее.
Неблокирующий ввод/вывод стал возможным благодаря современным операционным системам, которые предоставляют данный механизм — демультиплексор событий.
Демультиплексор — это механизм, который принимает от приложения запрос, регистрирует его и выполняет.

В верхней части схемы видно, что у нас есть приложение и в нём выполняются операции (пусть это будет чтение файла). Для этого делается запрос в демультиплексор событий, сюда отправляется ресурс (ссылка на файл), нужная операция и callback. Демультиплексор событий регистрирует этот запрос и возвращает управление непосредственно приложению — таким образом, оно не блокируется. Затем он выполняет операции над файлом, и после этого, когда файл будет прочитан, callback регистрируется в очереди на выполнение. Затем Event Loop постепенно синхронно обрабатывает каждый callback из этой очереди. И, соответственно, возвращает результат приложению. Дальше (если необходимо) всё делается снова.
Таким образом, благодаря данному неблокирующему вводу/выводу Node.js может быть асинхронным.
Уточню, что в данном случае неблокирующий ввод/вывод предоставляет нам именно операционная система. К неблокирующему вводу/выводу (вообще в принципе к операциям ввода/вывода) мы относим сетевые запросы и работу с файлами.
Это общая концепция неблокирующего ввода/вывода. Когда такая возможность появилась, Райан Дал (Ryan Dahl) — разработчик Node.js — был вдохновлён опытом Nginx, которая использовала неблокирующий ввод/вывод, и решил создать платформу именно для разработчиков. Первое, что ему нужно было сделать, — «подружить» свою платформу с демультиплексором событий. Проблема была в том, что в каждой операционной системе демультиплексор реализован по-разному, и ему пришлось написать обёртку, которая впоследствии стала называться libuv. Это библиотека, написанная на C. Она предоставляет единый интерфейс работы с этими демультиплексорами событий.
Особенности libuv-библиотеки
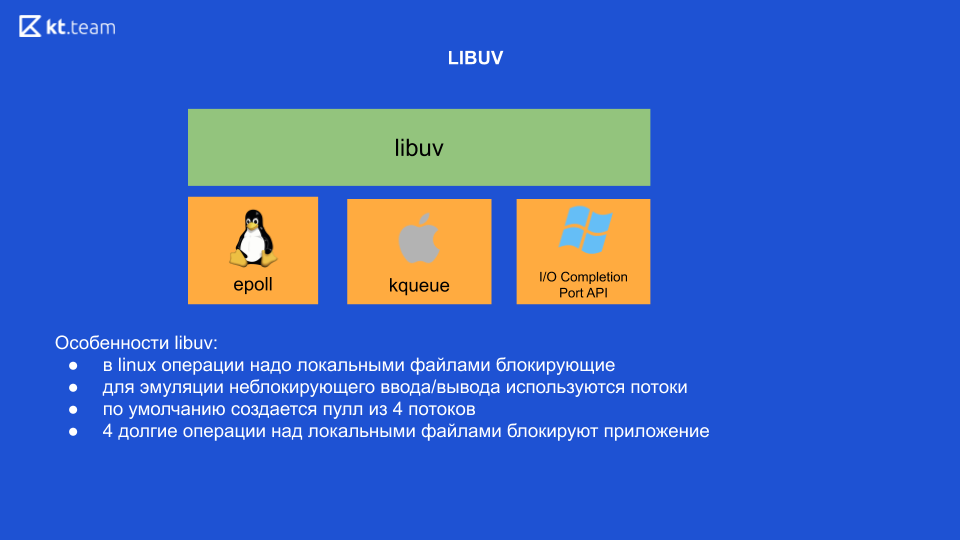
В Linux, в принципе, на текущий момент все операции с локальными файлами — блокирующие. Т. е. вроде бы как есть неблокирующий ввод/вывод, но именно при работе с локальными файлами операция всё равно блокирующая. Именно поэтому для эмуляции неблокирующего ввода/вывода libuv использует внутри потоки. Из коробки поднимается 4 потока, и здесь нужно сделать самый важный вывод: если мы выполняем какие-то 4 тяжёлые операции над локальными файлами, соответственно, мы заблокируем всё наше приложение (именно в ОС Linux, в других ОС такого нет).
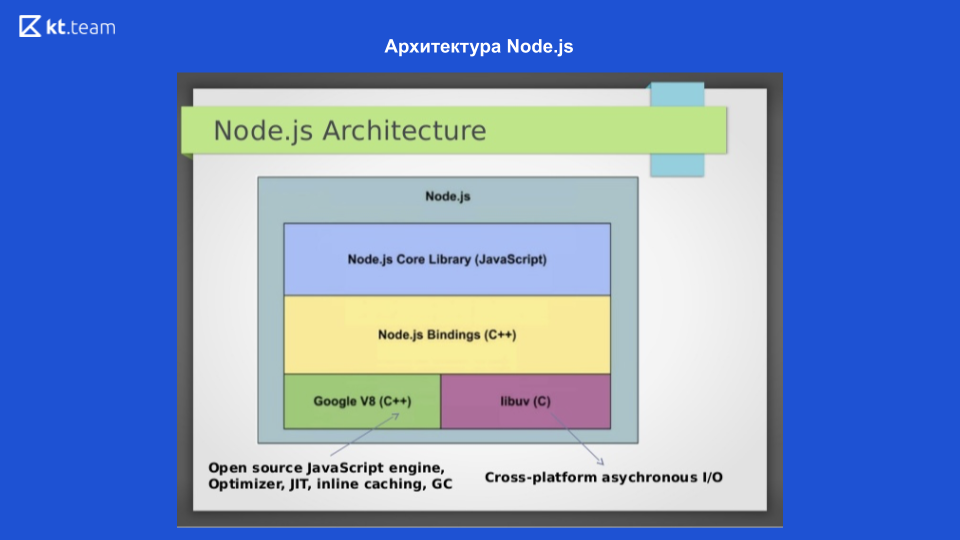
На этом слайде мы видим архитектуру Node.js. Для взаимодействия с операционной системой используется библиотека libuv, написанная на C; для компиляции кода JavaScript'a в машинный код используется движок Google V8, также есть Node.js Core library, где собраны модули для работы с сетевыми запросами, файловой системой и модуль для логирования. Чтобы всё это друг с другом взаимодействовало, написаны Node.js Bindings. Эти 4 компонента составляют саму структуру Node.js. Сам механизм Event Loop'a находится в libuv.
Event Loop
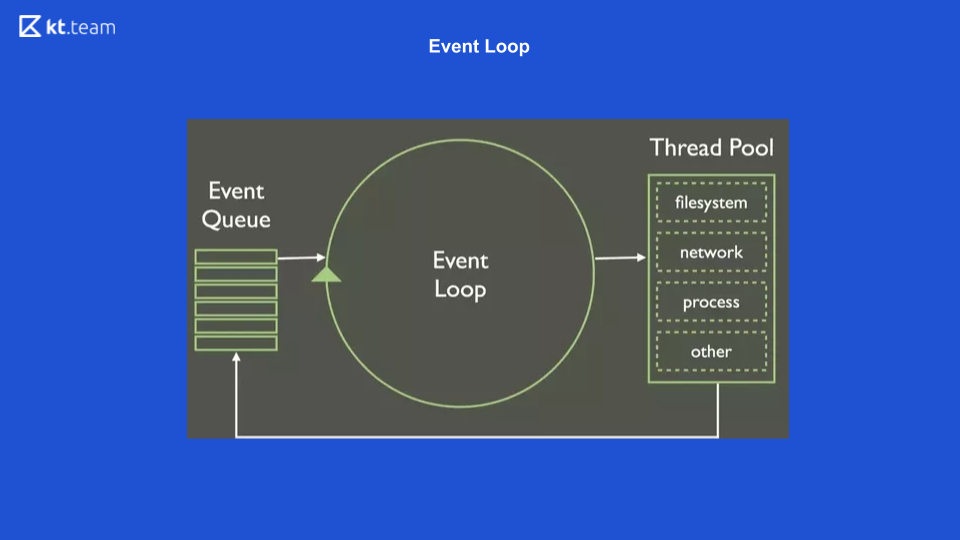
Это простейшее представление, как выглядит Event Loop. Есть определённая очередь событий, есть бесконечный цикл событий, который синхронно выполняет операции из очереди, и он распределяет их дальше.
На этом слайде показано, как выглядит Event Loop непосредственно в самой Node.js.

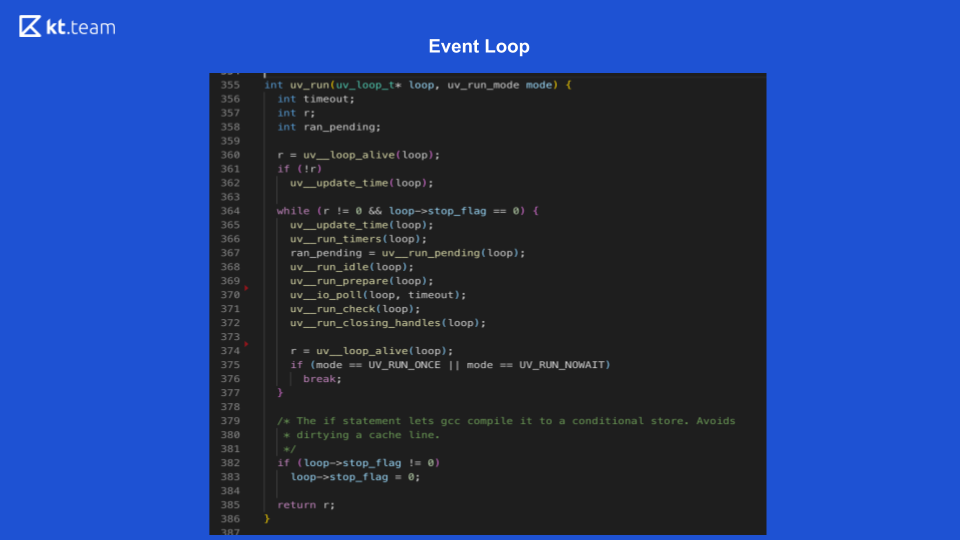
Там реализация поинтереснее и посложнее. По сути, Event Loop — это цикл событий, и он бесконечен до тех пор, пока есть что выполнять. Event Loop в Node.js делится на несколько фаз. (Фазы со слайда 8 надо сопоставлять с исходным кодом на слайде 9.)
1 фаза — таймеры
Данная фаза выполняется непосредственно Event Loop'ом. (Фрагмент кода с uv_update_time) — здесь просто обновляется время, когда начал работать Event Loop.
uv_run_timers — в этом методе выполняется следующее действие с таймером. Есть определённый стек, точнее, куча таймеров, это, по сути, то же самое, что очередь, где находятся таймеры. Берётся таймер с самым маленьким временем, сравнивается с текущим времени Event Loop'а, и, если настало время для исполнения данного таймера, выполняется его callback. Здесь стоит отметить что в Node.js есть реализация setTimeout и есть setInterval. Для libuv это, по сути, одно и то же, только в setInterval ещё есть флаг repeat.
Соответственно, если у данного таймера стоит флаг repeat, то он снова помещается в очередь событий и потом точно так же обрабатывается.
2 фаза — I/O-callback'и
Здесь надо вернуться к диаграмме про неблокирующий ввод/вывод.
Когда демультиплексор событий выполняет чтение какого-либо файла и ставит выполнение callback'а в очередь, это как раз соответствует этапу I/O-callback. Здесь выполняются callback'и для неблокирующего ввода/вывода, т. е. это именно те функции, которые используются после запроса в базу данных или другой ресурс или на чтение/запись файла. Они выполняются именно на данной фазе.
На слайде 9 выполнение функции I/O-callback'и запускает строка 367: ran_pending = uv_run_pending(loop).
3 фаза — ожидание, подготовка
Это внутренние операции для callback'ов, по сути, мы не можем влиять на фазу, только косвенно. Есть process.nextTick, его callback может ненамеренно быть исполнен на фазе «ожидание, подготовка». process.nextTick выполняется на текущей фазе, т. е., по сути, process.nextTick может сработать абсолютно на любой фазе. Какого-то готового инструмента, чтобы запустить код на фазе «ожидание, подготовка», в Node.js нет.
На слайде 9 этой фазе соответствуют строки 368, 369:
uv_run_idle(loop) — ожидание;
uv_run_prepare(loop) — подготовка.
4 фаза — опрос
Здесь выполняется весь наш код, который мы пишем на JS. Первоначально все запросы, которые мы делаем, попадают именно сюда, и именно здесь Node.js может быть заблокирована. Если сюда попадёт какая-либо тяжёлая операция по вычислению, то на этом этапе наше приложение может просто зависнуть и ожидать, пока не выполнится данная операция.
На слайде 9 функция опроса содержится в строке 370: uv_io_poll(loop, timeout).
5 фаза — проверка
В Node.js есть таймер setImmediate, его callback'и выполняются на этой фазе.
В исходном коде это строка 371: uv_run_check(loop).
6 фаза (последняя) — callback'и событий close
Например, web-сокету нужно закрыть соединение, на этой фазе будет вызван callback этого события.
В исходном коде это строка 372: uv_run_closing_handless(loop).
И в итоге Event Loop Node.js выглядит следующим образом
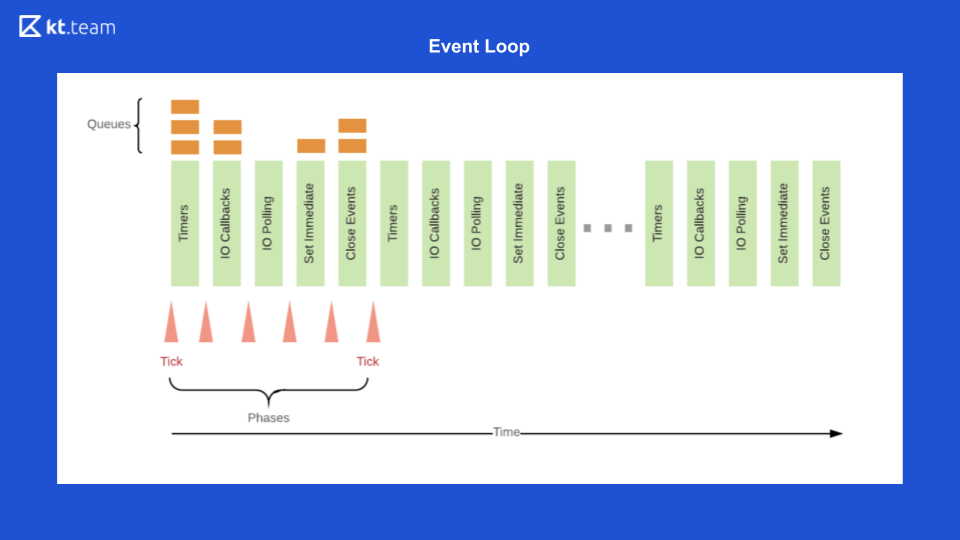
Сначала в очереди таймеров выполняется тот таймер, срок которого подошёл.
Дальше выполняются I/O-callback'и.
Затем — основой код, дальше — setImmediate и события close.
После этого всё повторяется по кругу. Чтобы продемонстрировать это, открою код. Как он будет выполняться?
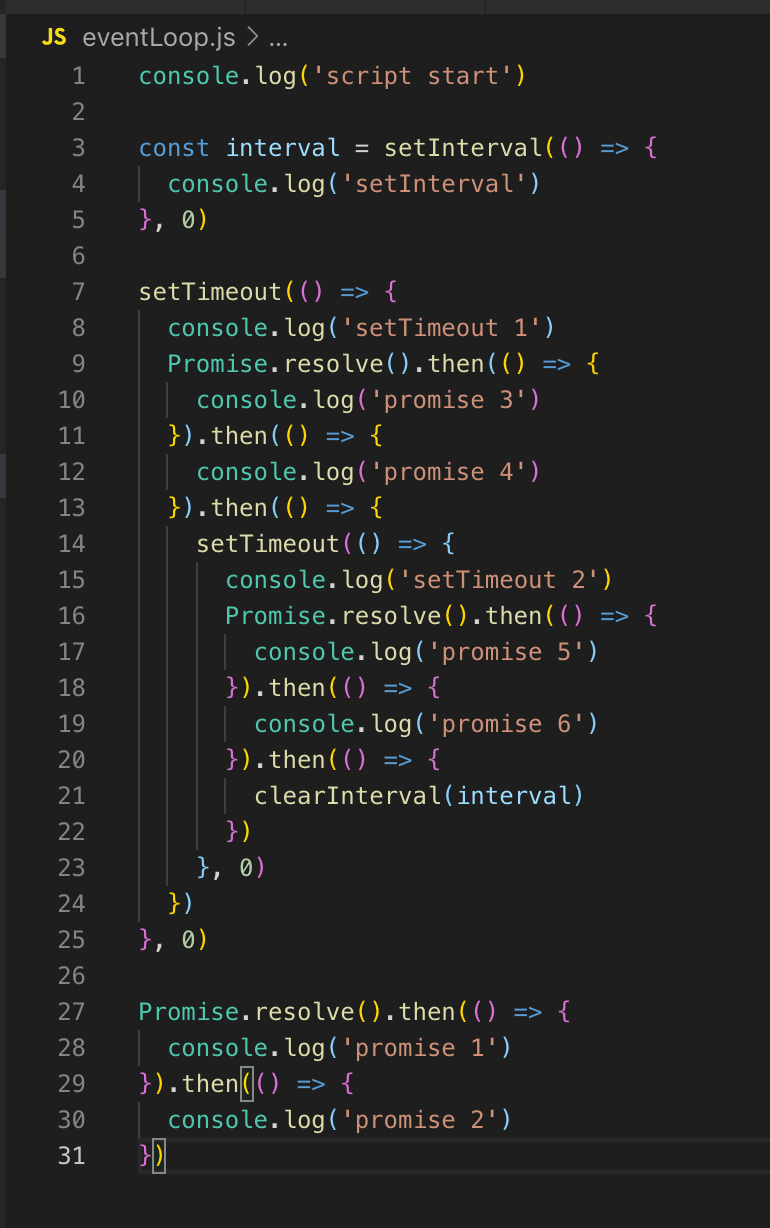
У нас нет таймеров в очереди, поэтому Event Loop двигается дальше. I/O-callback'ов тоже нет, поэтому идём сразу на фазу опроса. Весь код, который здесь есть, изначально выполняется на фазе опроса. Поэтому сначала печатаем script_start, setInterval у нас помещается в очередь таймеров (не выполняется, просто помещается). setTimeout также помещается в очередь таймеров, и затем выполняются промисы: сначала promise 1 и затем promise 2.
В следующий тик (цикл событий) мы возвращаемся на этап таймеров, здесь в очереди уже есть 2 таймера: setInterval и setTimeout. Они оба с задержкой 0, соответственно, они готовы к выполнению.
Выполняются (выводятся в консоль) setInterval, затем setTimeout 1. Callback'ов неблокирующего ввода/вывода нет, дальше будет фаза опроса, в консоль выводятся promise 3 и promise 4.
Дальше регистрируется таймер setTimeout. На этом тик заканчивается, идём в следующий тик. Там — снова таймеры, выполняется вывод в консоль setInterval и setTimeout 2, затем выводятся promise 5 и promise 6.
Event Loop мы рассмотрели и теперь можем более подробно поговорить о многопоточности.
Многопоточность — модуль worker_threads
Многопоточность появилась в Node.js благодаря модулю worker_threads в версии 10.5. И в 10-й версии она запускалась исключительно с ключом --experimental-worker, а с 11-й версии стал возможным запуск без него.
Ещё в Node.js есть модуль cluster, но он не поднимает потоки — он поднимает ещё несколько процессов. Масштабируемость приложения — его основная цель.

Как вообще выглядит 1 процесс:
1 процесс Node.js, 1 поток, 1 Event Loop, 1 движок V8 и libuv.
Если мы запускаем X потоков, то у нас это выглядит так:
1 процесс Node.js, X потоков, Х Event Loop'ов, X движков V8 и X libuv.
Схематично это выглядит следующим образом

Давайте разберём пример.
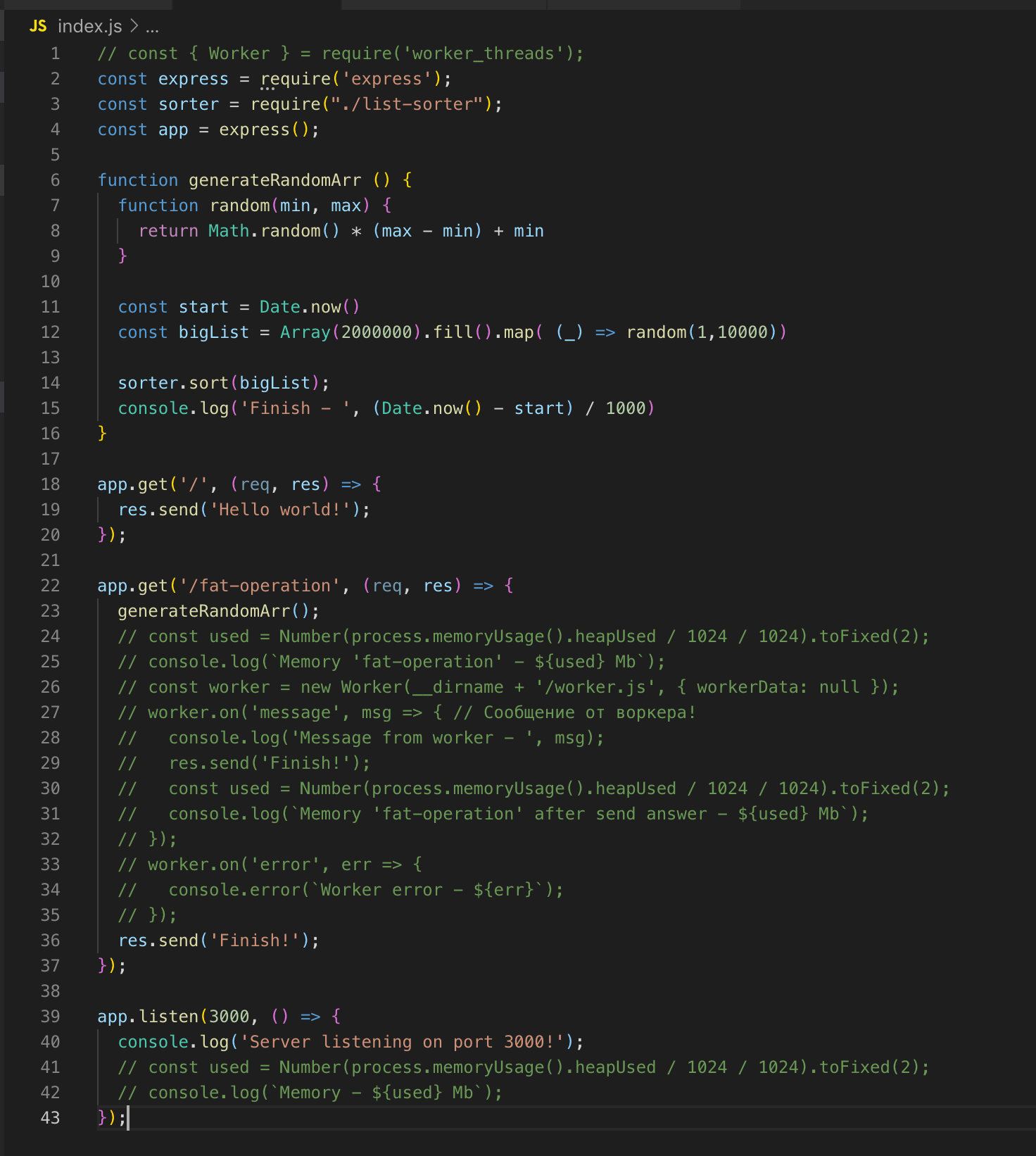
Простейший web-сервер на Express'е. Есть 2 route'а — / и /fat-operation.
Также есть функция generateRandomArr(). Она наполняет массив двумя миллионами записей и сортирует его. Запустим сервер.
Делаем запрос на /fat-operation. И в тот момент, когда выполняется операция сортировки массива, отправляем ещё один запрос на route /, но для получения ответа нам приходится ждать до тех пор, пока не выполнится сортировка массива. Это классическая реализация через один поток. Теперь подключаем модуль worker_threads.
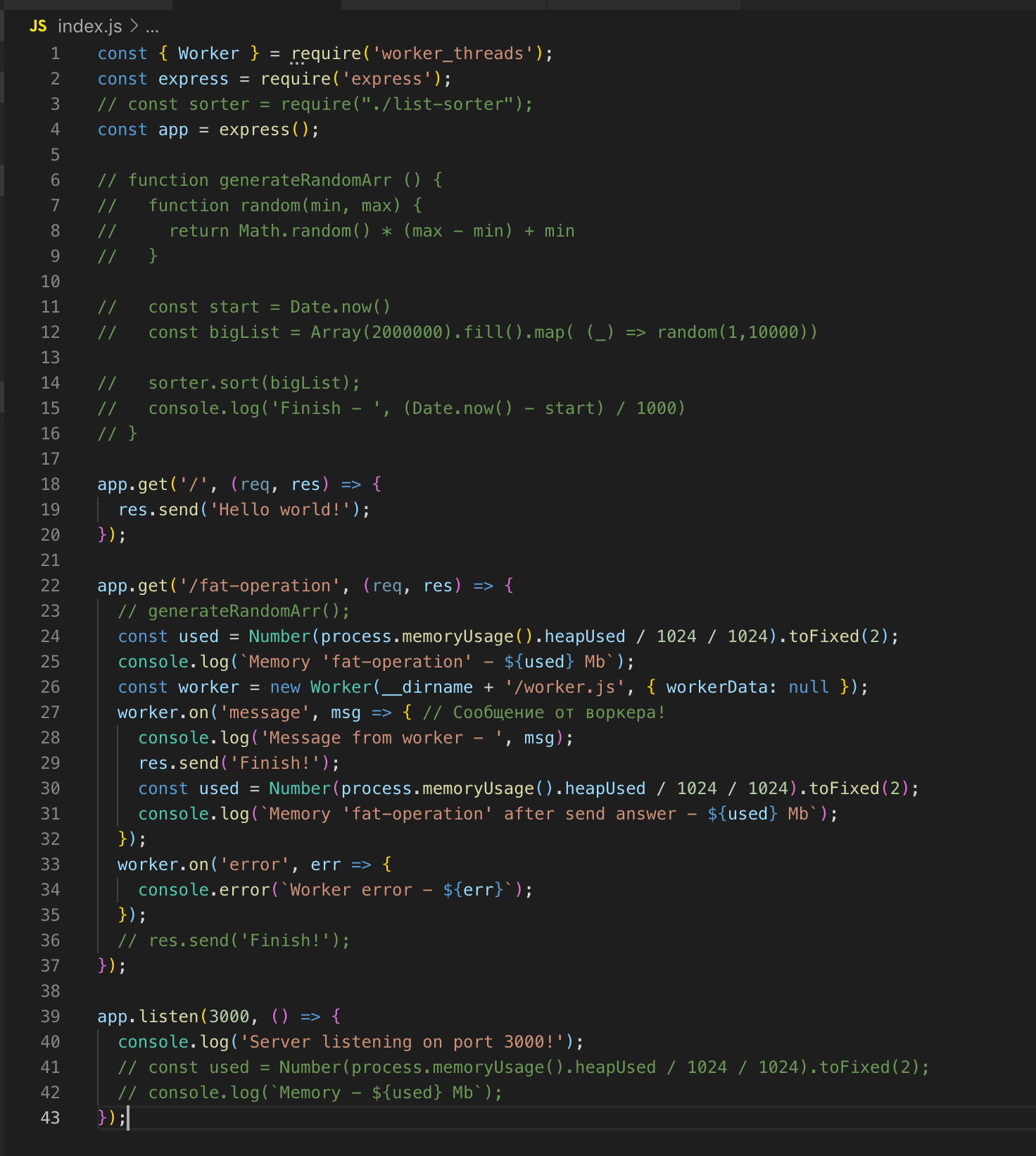
Делаем запрос на /fat-operation и следом — на /, от которого тут же получаем ответ — Hello world!
Для операции сортировки массива мы подняли отдельный поток, у которого есть свой экземпляр Event Loop, и он никак не влияет на выполнение кода в основном потоке.
Поток будет «уничтожен», когда у него не будет операций для выполнения.
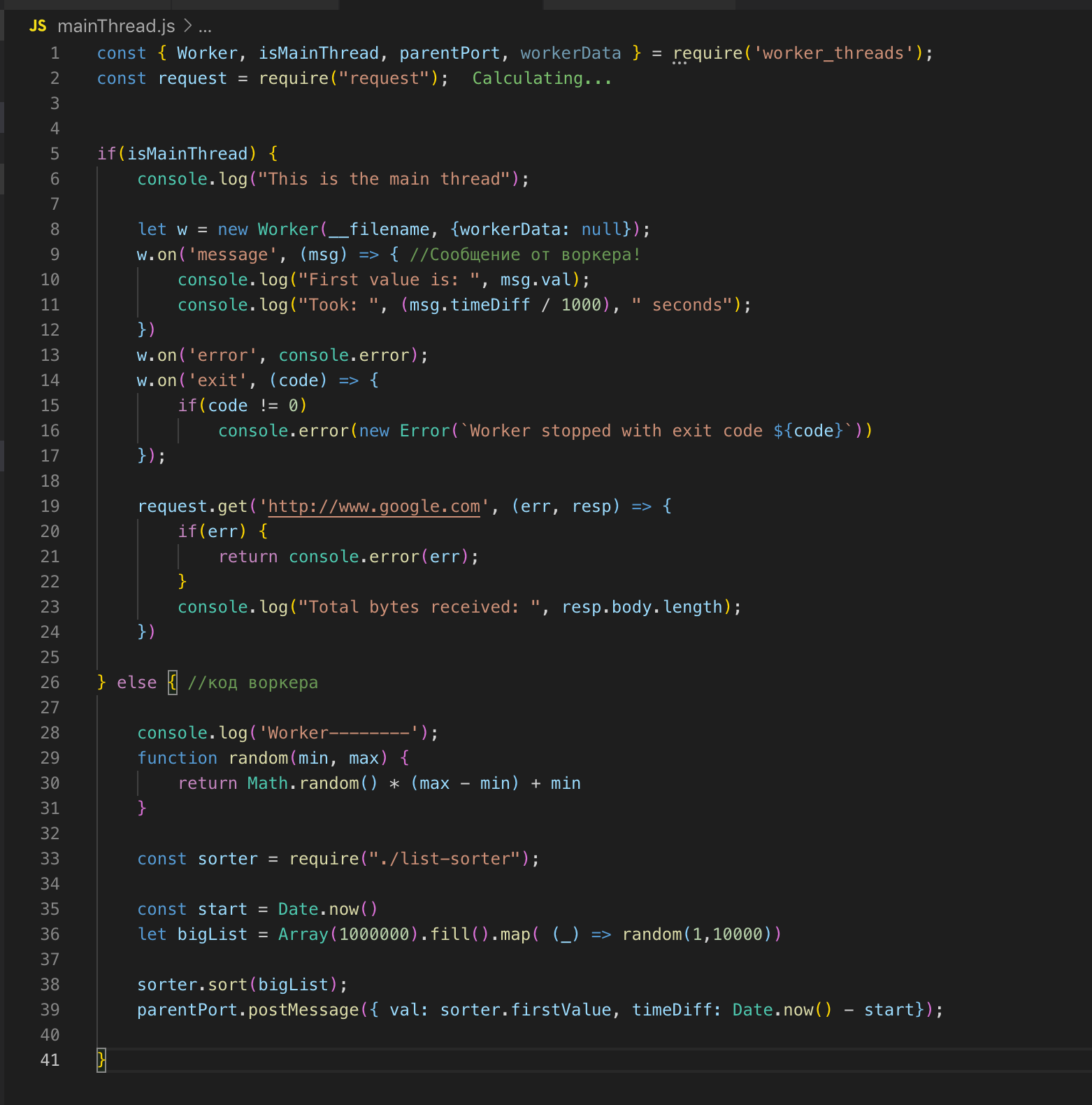
Смотрим исходный код. Регистрируем worker в строке 26 и, если нужно, передаём ему данные. В данном случае я ничего не передаю. И затем подписываемся на события: на ошибку и на месседж. В самом worker'е происходит вызов функции, массив из двух миллионов записей сортируется. Как только он отсортировался, мы через post_message отправляем результат в основной поток ok.

В основном потоке мы ловим это сообщение и отправляем результат finish. У worker'а и основного потока общая память, поэтому мы имеем доступ к глобальным переменным всего процесса. Когда мы передаём данные из основного потока в worker, worker получает только копию.
Основной поток и поток worker'а мы можем описать в одном файле. Модуль worker_threads предоставляет API, благодаря которому мы можем определить, в каком потоке сейчас выполняется код.
Дополнительная информация
Делюсь ссылками на полезные ресурсы и ссылкой на презентацию Райана Дала, когда он презентовал Event Loop (интересно посмотреть).
Event Loop
- Перевод статьи из документации Node.js
- https://blog.risingstack.com/node-js-at-scale-understanding-node-js-event-loop/
- https://habr.com/ru/post/336498/
Worker_threads
