Мой коллега Рафаэль Григорян eegdude недавно написал статью о том, зачем человечеству потребовалась ЭЭГ и какие значимые явления могут быть зарегистрированы в ней. Сегодня в продолжение темы нейроинтерфейсов мы используем один из открытых датасетов, записанных на игре, использующей механику P300, чтобы визуализировать сигнал ЭЭГ, посмотреть структуру вызванных потеницалов, построить основные классификаторы, оценить качество, с которым мы можем предсказать наличие такого вызыванного потенциала.
Напомню, что P300 — это вызванный потенциал (ВП), специфический отклик мозга связанный с принятием решений и и различением стимулов (что он из себя представляет мы увидим ниже). Обычно он используется для построения современных BCI.
Для того, чтобы заняться классификацией ЭЭГ, можно позвать друзей, написать игру про Енотов и Демонов в VR, записать собственные реакции и написать научную статью (об этом я расскажу как-нибудь в другой раз), но по счастью, учёные со всего мира уже провели некоторые эксперименты за нас и осталось только скачать данные.
Разбор способа построения нейроинтерфейса на P300 с пошаговым кодом и визуализациями, а также ссылку на репозиторий можно найти под катом.
В статье приведены только основные моменты из кода, полную воспроизводимую версию в jupyter notebook искать тут
С точки зрения ЭЭГ P300 это всего лишь всплеск в определённое время в определённых каналах. Способов вызвать его известно множество, например, если концентрироваться на одном предмете, а он в случайный момент активируется (изменит форму, цвет, яркость или отпрыгнет куда-то). Вот как это было реализовано в стародавние времена
В общем виде схема следующая: в поле зрения человека есть несколько (обычно от 3 до 7) стимулов. Человек выбирает один из них и сосредотачивается на нём (хороший способ — считать количество активаций), далее каждый объект мигает в случайном порядке. Зная время активации каждого стимула мы теперь можем посмотреть на следующую за этим ЭЭГ и установить, был ли в ней характерый пик (мы увидим его на визуализациях ниже). Поскольку человек концентрировался только на одном стимуле, то и пик должен быть один. Таким образом в этих ваших нейроинтерфейсах происходит выбор одного из нескольких вариантов (букв для написания, действий в игре и Бог знает чего ещё). Если вариантов больше семи, можно положить их на сетку и свести задачу к выбору строки+столбца. Так получился классический матричный P300 speller, показанный выше.
В случае датасета, рассматриваемого сегодня, визуальная часть (как и название) была позаимствованы у известной игры space inviders. Выглядело это примерно так

По-сути, это тот же спеллер, только буквы заменены на игровых инопланетян.
Также сохранилось видео процесса игры и технические отчёты
Так или иначе, в интернете появились данные, собранные с помощью этой игры и мы можем получить к ним доступ. Данные состоят из 16 каналов ЭЭГ и одного канала событий, показывающего в какие моменты были активированы целевой (загаданный игроком), и нецелевые стимулы, с ними мы и будем работать.
Большинство датасетов для BCI было записано нейрофизиологами, а это ребята, которые не очень заботятся о совместимости, поэтому форматы данных отличаются большим разнообразием: от разных версий .mat файлов до "стандартных" форматов .edf и .gdf.
Самое главное, что нужно знать про эти форматы — вы не хотите их парсить или работать с ними напрямую.
По счастью группа энтузиастов из NeuroTechX написала загрузчики для некоторых датасетов напрямую в numpy.
Эти загрузчики являются частью проекта moabb претендующего на универсализацию решений для BCI.
Загрузка сырого датасета
import moabb.datasets
sampling_rate = 512
m_dataset = moabb.datasets.bi2013a(
NonAdaptive=True,
Adaptive=True,
Training=True,
Online=True,
)
m_dataset.download()
m_data = m_dataset.get_data()На данном этапе мы получили структуру RawEDF, содержащую записи ЭЭГ. Это структура из пакета mne, им обычно пользуются биологи для взаимодействия с сигналами: в этой структуре есть встроенные методы для фильтрации, визуализации, хранения меток и мало ли чего ещё. Но мы не будем идти этим путём т.к. интерфейс пакета имеет свойство быть нестабильным (текущая версия 0.19, но мы будем использовать 0.17 т.к. датасет уже не читается новой версией) и слабо документированным, через это наши результаты могут стать невоспроизводимыми.
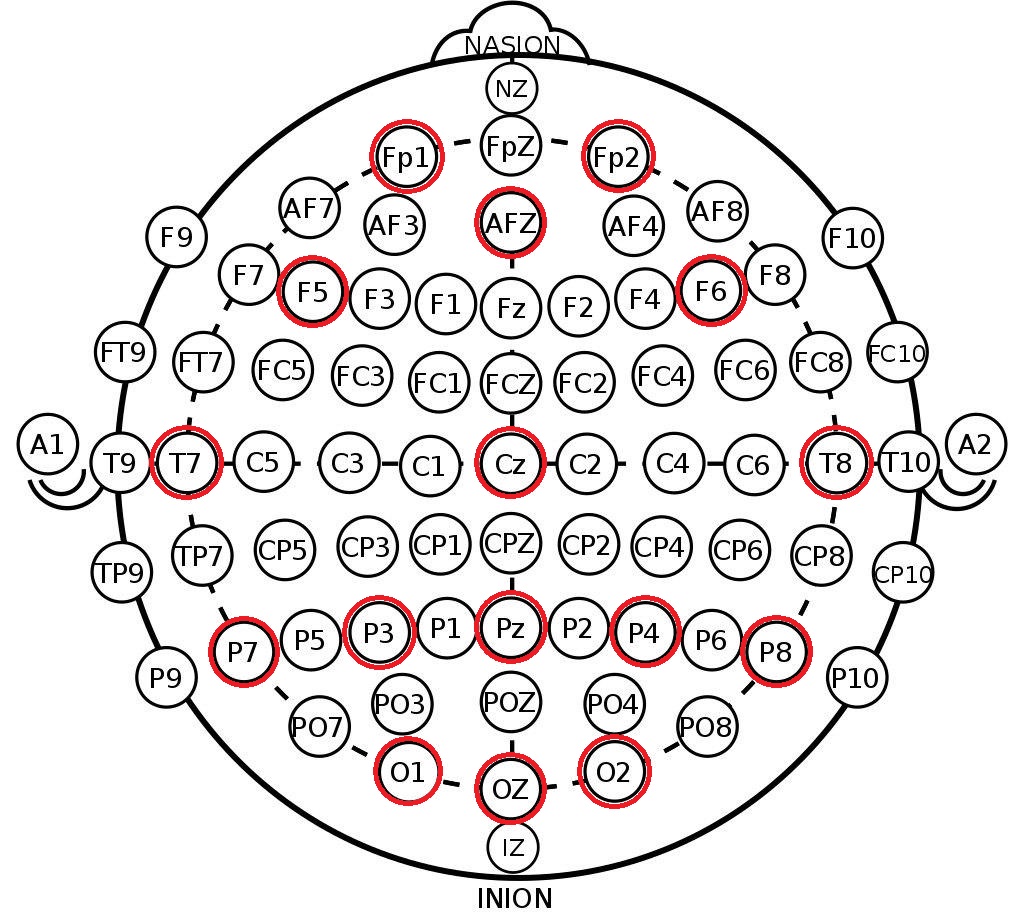
Что мы возьмём из полученной структуры — это метки каналов в системе 10-20. Это международная схема расположения электродов на голове человека, созданная для того, чтобы учёные могли соотносить зоны мозга и расположения каналов ЭЭГ. Ниже приведено расположение электродов в системе 10-10 (отличается от 10-20 вдвое большей плотностью разметки) и красным отмечены те каналы, которые были записаны в этом датасете.
print(m_data[1]['session_1']['run_1'])
# <RawEDF | 1.gdf, n_channels x n_times : 17 x 159232 (311.0 sec), ~20.7 MB, data loaded>
channels = m_data[1]['session_1']['run_1'].ch_names[:-1]
channels
# ['FP1', 'FP2', 'F5', 'AFz', 'F6', 'T7', 'Cz', 'T8', 'P7', 'P3', 'Pz', 'P4', 'P8', 'O1', 'Oz', 'O2']
Сначала мы из загруженных данных для каждого испытуемого выделяем массивы непрерывного ЭЭГ по 16 секунд и все метки для этого промежутка (в данных это просто ещё один канал, в котором отмечены начала интересующих нас событий).
На данном этапе мы сохраняем максимальную длину непрерывного ЭЭГ для того, чтобы при дальнейшей фильтрации не встречаться с краевыми эффектами.
raw_dataset = []
for _, sessions in sorted(m_data.items()):
eegs, markers = [], []
for item, run in sorted(sessions['session_1'].items()):
data = run.get_data()
eegs.append(data[:-1])
markers.append(data[-1])
raw_dataset.append((eegs, markers))Фильтрация и разделение на эпохи
В целом для обзора методов предобработки и классификации ЭЭГ могу порекомендовать отличный обзор от мэтров нейрокомпьютерных интерфейсов. Также не очень давно вышел более свежий обзор нейросетевых метедов.
Минимальная предобработка сигнала ЭЭГ для классификации включает 3 шага:
- децимация
- фильтрация
- масштабирование
Для реализации этих шагов мы воспользуемся старым добрым sklearn-ом и его парадигмой трансформеров и пайплайнов для того, чтобы наш препроцессинг мог быть легко расширяемым.
Код трансформеров вынесен в отдельный файл, ниже опишем некоторые детали.
Децимация
Почему-то в некоторых статьях и примерах обаработки я встречал понижение частоты сигнала простым выкидыванием отсчётов в стиле eeg = eeg[:, ::10]. Это совершенно некорректно (почему — см. любую книжку по обработке сигналов). Мы используем стандартную реализацию из scipy.
Фильтрация
Здесь мы также опираемся на фильтры из scipy, выбрав bandpass фильтр Баттерворта 4 порядка и применив его в прямом и обратном направлении (filtfilt) для сохранения фазы. Частоты отсечки — от 0.5 до 20 Гц, это стандартный диапазон для нашей задачи.
Масштабирование
Мы использовали поканальный StandardScaler (вычитает среднее, делит на стандартное отклонение), который видит все сигналы из выборки. На самом деле в этом месте вводеится небольшая утечка данных т.к. формально, скейлер видит данные и из тестовой выборки, но при достаточно больших объёмах данных среднее и отклонение оказываются одинаковыми.
Мастабирование производится поканально для того, чтобы можно было в рамках одного датасета агрегировать данные с разных датчиков, имеющих разные порядки величин и природу (например, кожно-гальваническую реакцию (КГР))
Кроме приведённых операций можно было также выделить артифакты в ЭЭГ (моргания, жевательные движения, движения головы), но этот датасет уже очень чистый, так что оставим это до следующего раза.
reload(transformers)
decimation_factor = 10
final_rate = sampling_rate // decimation_factor
epoch_duration = 0.9 # seconds
epoch_count = int(epoch_duration * final_rate)
eeg_pipe = make_pipeline(
transformers.Decimator(decimation_factor),
transformers.ButterFilter(sampling_rate // decimation_factor, 4, 0.5, 20),
transformers.ChannellwiseScaler(StandardScaler()),
)
markers_pipe = transformers.MarkersTransformer(labels_mapping, decimation_factor)Далее мы применим пайплайн препроцессинга к нашим данным и порежем непрерывный сигнал ЭЭГ на эпохи. Будем называть эпохой промежуток времени сразу после активации стимула с характерной продолжительностью 0.5-1 секунды, в нашем случае продолжительность составляет 900 мс, хотя её можно и сократить.
В нашем датасете 16 каналов ЭЭГ, после применения децимации частота понизится до 50 Гц, таким образом одна эпоха будет описываться матрицей (16, 45) — 900 мс на 50 Гц это 45 временных отсчётов.
Метки в данном датасете только бинарыне — они маркируют целевой (загаданный игроком, активный, 1) и не целевой (пустой, 0) сигнал.
for eegs, _ in raw_dataset:
eeg_pipe.fit(eegs)
dataset = []
for eegs, markers in raw_dataset:
epochs = []
labels = []
filtered = eeg_pipe.transform(eegs)
markups = markers_pipe.transform(markers)
for signal, markup in zip(filtered, markups):
epochs.extend([signal[:, start:(start + epoch_count)] for start in markup[:, 0]])
labels.extend(markup[:, 1])
dataset.append((np.array(epochs), np.array(labels)))dataset[0][0].shape, dataset[0][1].shape
# ((1308, 16, 45), (1308,))Таким образом у нас получился датасет в стиле Pytorch в котором первый индекс отсчитывает различных людей. С такой структурой мы можем как провести кросс-валидацию внутри данных одного человека, так и протестировать переносимость классификатора между разными людьми (т.н. transfer learning, calibration-less prediction). Данные одного человека состоят из массива эпох и меток классов. Количество эпох у каждого человека немного разнится в силу особенностей записи.
Исследование и визуализация данных
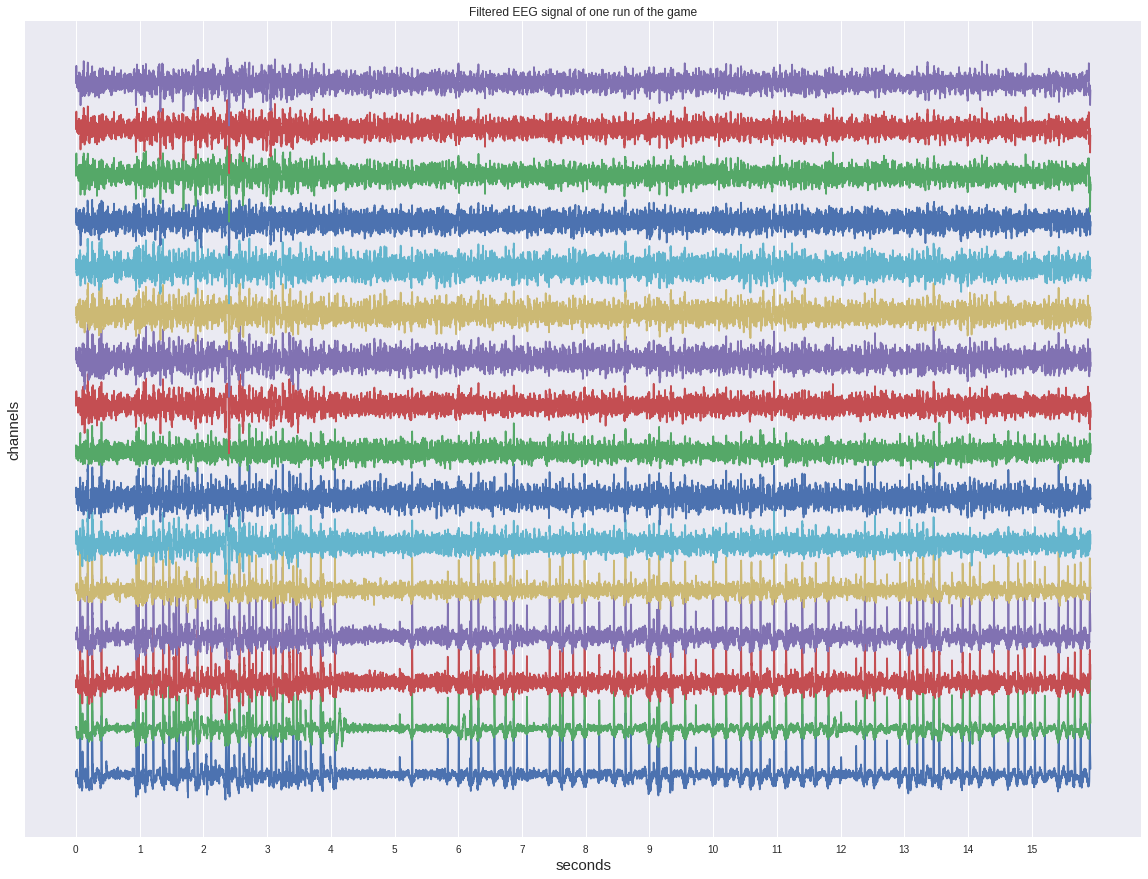
Для начала взглянем на один из непрерывных сигналов до нарезки на эпохи.
Не смотря на то, что он уже отфильтрован, на нём не видно глазом каких-либо активаций и больше походит на какой-то шум.
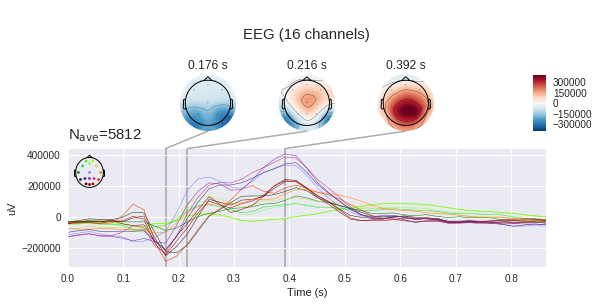
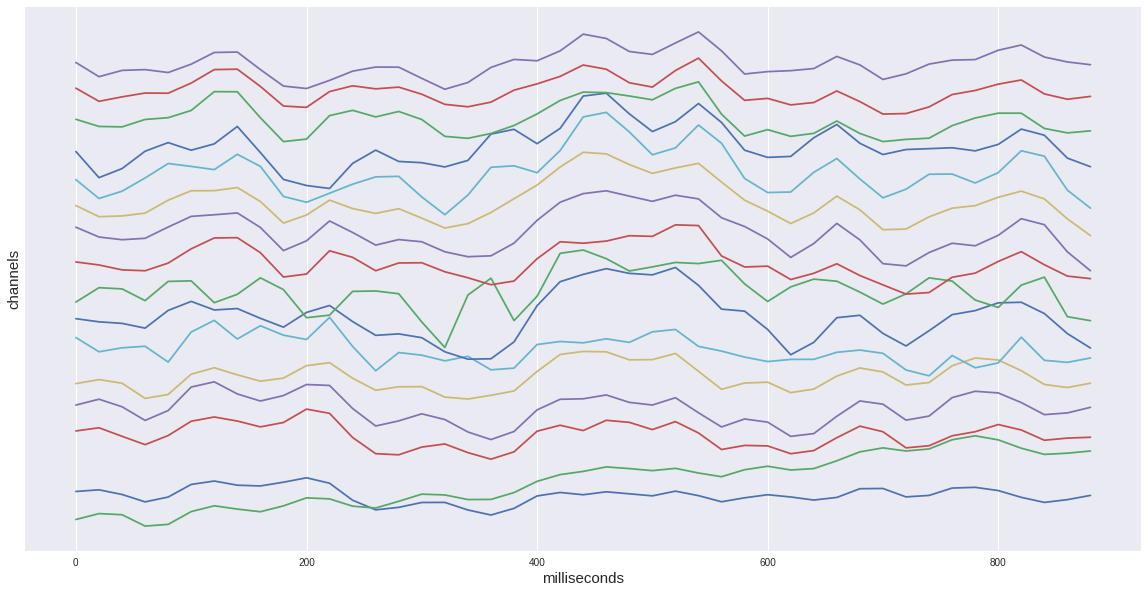
Если же мы рассмотрим только одну целевую эпоху из нашего датасета, то увидим характерный подъём на промежутке 400-600 мс. Это и есть наш искомый вызванный потенциал P300.
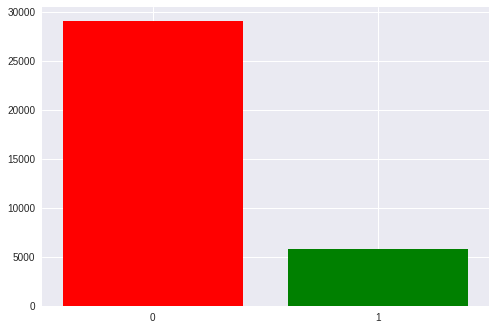
Всего в нашем датасете около 35 тысяч эпох, то есть активаций стимулов. У каждого человека примерно от 1300 до 1750 (это связано с тем, что кто-то сбивал пришельцев быстрее, а кто-то медленнее).
Также в классах есть ощутимый дисбаланс: 1 к 5 в пользу пустых стимулов т.к. у нас в матрице 6 строчек и столбцов и только по одному из них — целевые. Позже мы вернёмся к этому при обсуждении полученных метрик.
Теперь настало время взглянуть на отличие целевого сигнала от нецелевого
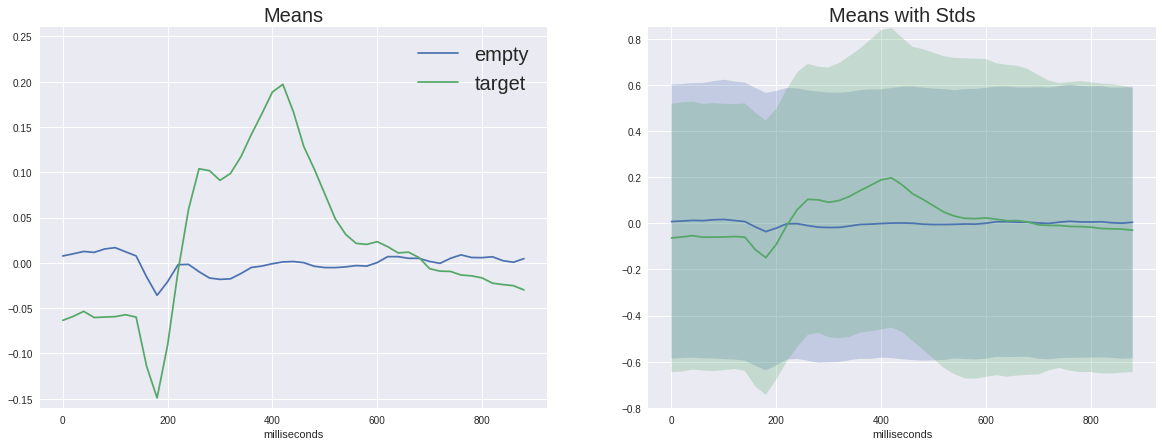
На левом графике можно увидеть, что средние сигналы разнятся очень сильно, причём у обоих есть неспецифический отклик в районе 180мс, но у целевого он гораздо амплитуднее, также у целевого есть характерный горб от 250 до 500 мс — это и есть пресловутый P300.
С таким отличием в сигнале наша задача может показаться плёвой, но если мы добавим на график стандартное отклонение в каждой точке, то увидим, что картина не так уж радужна — сигнал довольно сильно зашумлён. И это не смотря на то, что соотношение сигнал-шум для P300 считается одним из самых высоких в нейрофизиологии.
(На самом деле эти графики построены не вполне честно т.к. пустой сигнал усредняется по впятеро большему числу разных семплов, таким образом случайные отклонения давятся больше, но как мы видим по дисперсии одного порядка, это не слишком помогает)

Также полезно взглянуть на средние сигналы одного человека.
Тут находит подтвержедние предыдущая ремарка про "нечестное" усреднение — пустой сигнал заметно амплитуднее, чем при усреднении по всем. Также пик P300 у одного человека более высокий из-за меньшего усреднения.
Важно отметить ещё одну особенность сигнала одного человека — он имеет несколько другую форму, чем обобщённый. Межличностная вариативность нейрофизиологических реакций довольно высока, мы ещё увидим влияние этого фактора в работе классификаторов. Впрочем, внутриличностные различия (один человек в разном настроении, уровне стресса, усталости) также достаточно велика.

Далее мы видим поканальную развёртку сигналов. Точка зрения тут совпадает с картинкой выше, на которой изображены положения электродов — нос сверху и т.д.
Отклик каждой части головы разный. На Fp1,2 ярко выражены два отрицательных пика, предшествующих положительному пику. Также в некоторых каналах положительных пика два, а в некоторых — один или что-то переходное между.
Разные каналы имеют разную важность для определения наличия P300, её можно оценить разными методами — вычислением взаимной информации (mutual information) или методом добавления-удаления (aka stepwise regression). Примененнием этих методов мы займёмся в другой раз.
Стоит помнить, что электродами мы измеряем разность потенциалов между электродами, а значит мы можем по измененрям напряжения в отдельных точках построить карту напряжений для всей головы в определённые моменты времени. Понятно, что при наличии 16 электродов точность такой карты оставляет желать лучшего, но какое-то понимание сформировать. (mne по умолчанию ожидает увидеть микровольты, но мы уже применили масштабирование, так что абсолютные величины указаны не верно)

Классификация
Наконец пришло время применить методы машинного обучения к нашей выборке.
В качестве классификаторов были выбраны несколько базовых — лог. регрессия, метод опорных векторов (SVM) и несколько методов, использующих корреляционный анализ из пакета pyriemann (детали работы каждого метода можно найти в документации), стоит отметить, что эти методы специально разрабатывались для применения к ЭЭГ и с их помощью было выиграно несколько соревнований на kaggle.
clfs = {
'LR': (
make_pipeline(Vectorizer(), LogisticRegression()),
{'logisticregression__C': np.exp(np.linspace(-4, 4, 9))},
),
'LDA': (
make_pipeline(Vectorizer(), LDA(shrinkage='auto', solver='eigen')),
{},
),
'SVM': (
make_pipeline(Vectorizer(), SVC()),
{'svc__C': np.exp(np.linspace(-4, 4, 9))},
),
'CSP LDA': (
make_pipeline(CSP(), LDA(shrinkage='auto', solver='eigen')),
{'csp__n_components': (6, 9, 13), 'csp__cov_est': ('concat', 'epoch')},
),
'Xdawn LDA': (
make_pipeline(Xdawn(2, classes=[1]), Vectorizer(), LDA(shrinkage='auto', solver='eigen')),
{},
),
'ERPCov TS LR': (
make_pipeline(ERPCovariances(estimator='oas'), TangentSpace(), LogisticRegression()),
{'erpcovariances__estimator': ('lwf', 'oas')},
),
'ERPCov MDM': (
make_pipeline(ERPCovariances(), MDM()),
{'erpcovariances__estimator': ('lwf', 'oas')},
),
}
Наиболее часто встречающаяся схема нейроинтерфейсов это "калибровка+работа" т.е. сначала нужно, чтобы человек какое-то время концентрировался на заранее указанных стимулах и только после этого мы предсказываем его выбор. Этот подход обладает очевидным минусом занудого начального этапа.
Для оценки работоспособности наших методов в этом режиме проведём кроссвалидацию внутри эпох одного человека.
Метрика accuracy в данном случае не релевантна в силу разбалансированности датасета (бейзлайн тут 5/6 ~ 83%), так что я предпочитаю смотреть на тройку precision-recall-f1.
Чтобы обозреть весь датасет, усредним результаты такой кроссвалидации по всем людям. В целом, перфоманс лучших моделей достаточно высок по сравнению с тем, что мы в Neiry имеем в "полевых" условиях парка развлечений (напомню, что этот датасет записывался в лаборатории).
В этом датасете присутствуют только бинарные метки для данных. В целом же нам нужно решить мультиклассовую задачу выбора одного из стимулов (она, кстати, сбалансирована т.к. каждый стимул активируется одиаковое количество раз). Для её решения обычно фиксируют число активаций каждого стимула (например, 6 стимулов по 5 активаций) и все стимулы в случайном порядке активируются (30 раз), получается 30 эпох и для каждого стимула складываются вероятности его активаций быть целевыми, после этого стимул, набравший максимальную сумму признаётся целевым. Релизацию этого подхода мы продемонстрируем в одном из будущих постов на подходящем датасете.

Вторая схема проведения называется transfer learning — то есть перенос классификатора между людьми. Дело в том, что когда мы делаем калибровку, то мы фактически переобучаемся на форму пика одного человека, поэтому можем неплохо предсказывать её же в последующих тестах. В случае отсутствия калибровки, предобученный классификатор должен уметь выделять концепцию P300 не зная наперёд форму сигнала конкретного человека.
Мы проведём два эксперимента — обучим классификатор на одном человеке, и предскажем пятерых, а потом увеличим тренировочную выборку до 10 человек и сравним результаты чтобы убедиться, что модели смогли повысить свою обобщающую способность
Тренировка на 1 человеке

Тренировка на 10 людях
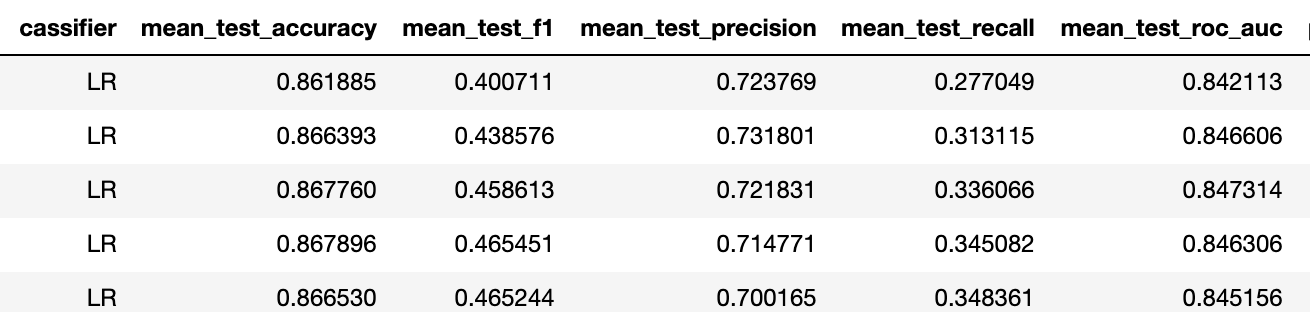
Итак f1 поднялся с 0.23 до 0.4 для лучшего классификатора (в обоих случаях это логрегрессия с одинаковой регуляризацией).
Это означает, что предсказательная способность повысилась от "никакой" до "приемлемой". Исходя из нашего опыта при таких метриках бинарной задачи достаточно 5 активаций каждого стимула, для достижения accuracy мультиклассовой задачи около 75%.
В конце хочется отметить, что приведённый метод достаточно примитивен, что видно, например, по высокой степени регуляризации логрегрессии — каналы в данных довольно сильно скореллированы и существует несколько подходов к разрешению этого обстоятельства.
Заключение
Сегодня мы ближе познакомились с вызванным потенциалом P300 и построили простой пайплайн для нейроинтерфейса. Рекомендую заинтересовавшимся самостоятельно открыть ноутбук (находится в репозитории) и поэкспериментировать с вариантами визуализаций и классификаторов.
Имея базовое представление о методах работы с сигналом ЭЭГ мы в дальнейшем сможем более глубоко рассмотреть эту тему — применить продвинутые методы предобработки, а также нейросети для решения задач построения нейроинтерфейсов. Продолжение следует...
