
Недавно у департамента эксплуатации Яндекс.Денег прошло значимое событие. Наша компания быстро растет, и оказалось, что перемен требуют не только наши сердца, но и дата-центр. А точнее, перемен требовала его локация. И вот уже три месяца, как один из дата-центров живет в новом месте.
О том, как Яндекс.Деньги переезжали в новый дата-центр, расскажу я, руководитель департамента эксплуатации, и Иван, начальник отдела ИТ-инфраструктуры и внутренних систем.
Под катом — хронология событий, важные вехи переезда, неожиданные повороты и разбор полетов. Делимся, как мы пережили это.
Предпосылки переезда
Ранее один из дата-центров Яндекс.Денег размещался в пригороде Москвы. Реальность такова, что за пределами города не у всех провайдеров оптических каналов связи есть возможность независимо прокладывать кабельные трассы — это дорого. И первая причина нашего решения о переезде была связана с тем, что в старом дата-центре каналы связи проходили по одним и тем же маршрутам, а это несло дополнительные риски.
Внутри МКАДа много провайдеров, и кабельная система хорошо развита. Можно у разных провайдеров закупить каналы, которые идут разными путями, и не пересекаются. В области же есть повышенные риски — например, приедет экскаватор и перекопает сразу все трассы.
Во-вторых, предыдущий дата-центр имел технологические ограничения, в том числе мы периодически сталкивались с проблемами электропитания.
Но самая главная причина (= боль) — невозможность расширения. Это значило, что в здании закончилось пространство для дополнительных стоек, куда можно было ставить новое оборудование. Это напрямую касалось нашей продуктивной среды, потому что у Яндекс.Денег два дата-центра и они должны быть симметричны по мощностям.
Планирование
Подготовку к переезду поделили на этапы:
- Конкурсы: ДЦ, каналы, сети, стойки, PDU, кабели;
- Перенос приложений и БД во 2-ой ДЦ;
- Учения — отключение ДЦ;
- Новая архитектура опорных сетей, IX;
- Настройка нового ядра сети в ДЦ.
Выбор поставщиков
Первый дата-центр Яндекс.Денег расположен в Москве. И чтобы избежать больших сетевых задержек, решили расположить второй ЦОД недалеко от первого.
В пределах МКАД для минимизации сетевых задержек и не ближе 20 км к первому объекту для обеспечения независимости обоих ЦОДов от одних и тех же городских объектов инфраструктуры и возможных техногенных или природных катастроф.
При анализе рынка ориентировались на такой важный критерий, как сертификация дата-центров по уровню доступности и надежности. Самым распространенным в России и мире является стандарт, разработанный компанией Uptime Institute, которая проводит аудит дата-центров во всем мире. Стоит отметить, что есть много дата-центров, у которых сертифицирована только проектная документация, но это еще не говорит о том, что сам дата-центр построен, проверен и эксплуатируется по стандартам.
Случай из нашей практики: один провайдер услуг дата-центров Москвы заявил нам о соответствии проекта ЦОДа стандарту Tier III и предложил заключить договор с обещанием 100% доступности, то есть 0 минут простоя в год! Лично посетив объект, мы поняли, что официальных сертификаций, гарантирующих уровень качества, нет, а инфраструктура явно не тянет на Tier III. ЦОД располагался на первом этаже жилого дома, и единственный генератор-прицеп стоял на улице без какой-либо физической защиты.
Поэтому в требования к конкурсу мы включали не только сертификацию проекта, но и сертификацию реализации и процессов управления.
Далее определялись с поставщиками оптических каналов связи между нашими ДЦ и каналов в точки обмена трафиком (IX) там, где мы организуем стыки с провайдерами или нашими партнерами. Основной критерий был в том, чтобы оптические каналы связи были независимыми, шли разными трассами.
И, конечно, оставались другие закупки — в первую очередь это сетевое оборудование, стойки (специализированные шкафы для установки серверов), power distribution unit (интеллектуальные блоки распределения электропитания), а также кабели и патч-корды.
Стоит отметить, что мы особенно внимательно выбирали поставщика, который будет перевозить оборудование. Важно, чтобы компания имела опыт перевозки серверов, а грузчики понимали, что это не мебель и грузить, а также ехать следует особенно осторожно. Кроме того, мы застраховали перевозимое оборудование на случай его повреждения при перевозке.
Апгрейд сетевой инфраструктуры
Касательно сетевой инфраструктуры, у нас было два варианта. Первый — перевозить старое сетевое оборудование, «как есть». Второй — сперва построить новую сетевую инфраструктуру в новом дата-центре и только тогда перевозить серверное оборудование.
Так как мы понимали, что уже «уперлись» в пропускную способность сети в старом ЦОДе и нам нужны запас и возможность масштабирования минимум на ближайшие 3–5 лет, было принято решение строить сетевую инфраструктуру в новом ЦОДе с нуля и проводить обновление на новое поколение оборудования.
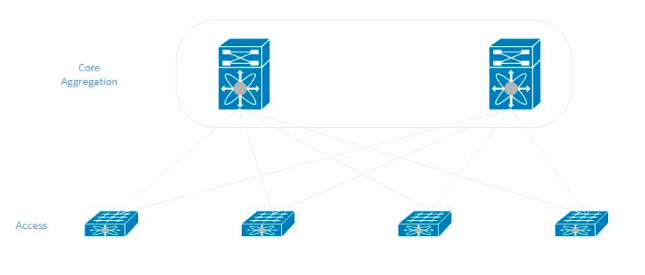
Мы придерживались классической модели при построении сети в новом дата-центре. В каждой стойке серверы подключаются в два коммутатора доступа, которые, в свою очередь, соединены с центральными коммутаторами агрегирования (они же ядро сети).
Учения
При переезде мы решили полностью выключить дата-центр, за один раз всё перевезти и включить на новом месте. Для этого компания должна была научиться обходиться без одного из двух дата-центров. Здесь потребовалось участие почти всех наших администраторов для того, чтобы информационные системы на разных платформах, на разных операционных системах, с разными базами данных бесперебойно работали на оставшейся площадке.
Для самых критичных сервисов был обеспечен резерв, который оставался доступным даже при одном выключенном ЦОДе.
После проведения работ по резервированию начались учения. Сначала мы отключали отдельные сети, сегменты и только потом ЦОД полностью. За 2019 год мы 10 раз провели тестовое отключение дата-центра — смотрели, как ведут себя наши 300 информационных систем. Многократно проверив автономность, убедились, что можем без проблем проводить отключение.
А дальше…
Неделя X
На одну из пятниц назначили выключение всего оборудования в дата-центре — утром выкатывали последние релизы, а потом объявили на них мораторий.
В Яндекс.Деньгах может выходить по 60 и больше релизов в день, и все они проводятся на оба дата-центра.
Мы остановили релизы, убедились, что система работает стабильно и никакие фиксы не требуются в наших компонентах. Начиная с 15:00 начали постепенно гасить все приложения, базы данных, серверы. В течение ночи с пятницы на субботу выждали время, убедились, что ничего плохого не происходит, — значит, можем ехать. Утром в субботу команда из 15 человек начала демонтировать оборудование и перевозить его в новый дата-центр.

У нас ушел целый день субботы на демонтаж и перевозку оборудования. Дальше начался процесс монтажа оборудования, коммутации, подключения его к электропитанию.

В субботу ночью мы смонтировали и подключили первую партию серверов. Основная работа началась в воскресенье — к вечеру выходных было смонтировано почти всё оборудование. А коммутацию мы закончили только в понедельник вечером.

Во вторник утром мы провели финальное тестирование сетей, каналов связи и уже были готовы поднимать наши системы. Начали поднимать первую партию серверов, но что-то пошло не так…
Мы начали получать массовые жалобы от администраторов о том, что в серверах не работает сеть: или полностью, или один из двух интерфейсов. Стали искать проблемы на стороне сетевого оборудования, в операционных системах, в настройках операционных систем.
Симптомы были схожими — начали смотреть, что же может быть причиной. Мы заметили, что стоит сильнее пошевелить патч-корды рядом с портами коммутаторов и часть рабочих линков гаснет.

Обнаружив это, мы поняли, что значительная часть этих патч-кордов (около 40% из 2000 штук) бракованная. Мы перевезли все имеющиеся патч-корды другого проверенного производителя в новый дата-центр и в экстренном порядке начали проводить перекоммутацию наиболее критичных серверов. На это ушел еще один день.
С вечера среды на утро четверга команда начала поднимать основной блок информационных систем.
После того, как мы подняли критичные сервисы и запустили резерв платежной системы, мы включили часть тестовых стендов нового ЦОДа и резерв систем backoffice, чтобы все наши внутренние системы работали с двумя дата-центрами. К концу недели почти вся ИТ-инфраструктура перевезенного ЦОДа была запущена.
Изначально был план на 5 дней, а с внештатной ситуацией, связанной с бракованными патч-кордами, получилась неделя. Ниже расписали наглядно таймлайн наших действий.
План переезда — ожидание:
- Пятница — гасим сети и приложения;
- Суббота — везем и начинаем сборку;
- Воскресенье — установка серверов, запуск сетей;
- Понедельник — заканчиваем сети, запуск приложений;
- Вторник — включаем всё.
Реальность:
- Пятница — гасим сети и приложения;
- Суббота — везем и начинаем сборку;
- Воскресенье — монтаж серверов, запуск сетей;
- Понедельник — разводка кабелей, запуск сетей;
- Вторник — включаем серверы, 100+ не работает;
- Среда — брак в проводах, замена, запуск App и БД;
- Четверг — закончили замену для ПС, запуск App.
Жизнь после переезда
Что мы получили от переезда?
Прежде всего оба наших дата-центра теперь уровня Tier III Uptime Institute. Поставщики дата-центров нам гарантируют уровень доступности Uptime 99,982%, что составляет до 1,6 часа простоя в год. Мы уверены в надежности каналов связи между нашими площадками. Также теперь нет ограничений по расширению нашей ИТ-инфраструктуры.
Идея переезда дала нам отличную возможность обновить сетевое оборудование в части пропускной способности. А также мы провели рефакторинг электропитания в стойках — установили «умные PDU», зарезервировали серверы по питанию.
А еще при переезде мы смогли «причесать» коммутацию, и теперь она выглядит аккуратнее.

Поэтому в целом система начала работать стабильнее, и наши клиенты получают более качественный сервис.
Какие выводы извлекли для себя?
Выполняя крупные проекты нужно думать о рисках, представлять, какие могут быть подводные камни. Наш пример с Ethernet-кабелями показал, что недостаточно сделать контрольную закупку и провести тестирование кабельной продукции выбранного производителя. Чтобы снизить риски, стоило проводить выборочное тестирование партии из 2000 кабелей.
Также стоит учитывать, что некоторые серверы могут не пережить переезда и просто не включиться по различным причинам. Так или иначе, дорога — это тряска и механические воздействия. Из 600 единиц перевезённого оборудования 6 блоков сломались. Из достаточно большого количества серверов пострадал лишь 1%, не вылетело ни одного диска — мы считаем, это отличный результат.
Вот так прошел переезд дата-центра Яндекс.Денег на новое место. Надеемся, что наш опыт поможет вам избежать возможных ошибок и, может быть, натолкнет вас на другие интересные решения.
