На написание этой небольшой заметки меня подтолкнуло несколько проведенных в последнее время собеседований на должность ведущего разработчика в нашу компанию. Некоторые соискатели, как оказалось, недостаточно разбираются в том, что же это за механизм такой, Dictionary, и как его нужно использовать. Столкнулся даже с весьма радикальным мнением: мол, словарь работает очень медленно, причем из-за того, что при создании сразу же помещается в куче больших объектов (LOH), использовать его в коде нельзя и лучше применять запросы к обычным коллекциям с помощью фильтров LINQ!
Конечно же, это не совсем верные утверждения. Словарь как механизм очень часто бывает востребован как при построении высоконагруженного кода, так и при реализации бизнес-логики. Разработчик должен представлять, как устроен словарь, как он работает с памятью, насколько затратен, сколько «следов» оставит в поколениях и LOH, вызывая излишнюю нагрузку на сборщик мусора; как его лучше инициализировать, в каких случаях вместо него лучше использовать коллекцию пар ключ-значение, в каких – сортированную коллекцию и т.д.
В этой заметке мы постараемся разобраться с некоторыми из этих вопросов.
Реализация словаря от Майкрософт базируется, как всем известно, на механизме хэш-таблиц. Это дает в некоторых сценариях недостижимую для других алгоритмов идеальную константную сложность O(1) на операции вставки, поиска, удаления. В некоторых же сценариях отказ от использования этого механизма чреват существенными проблемами с производительностью и потреблением памяти.
Важной особенностью архитектуры является то, что хранение данных организовано с помощью двух массивов одинакового размера:
int[] _buckets = new int[size];
Entry[] _entries = new Entry[size];Эти массивы хранят полезные данные и служебные элементы для быстрого доступа к ним. Массивы создаются с запасом, то есть они практически всегда не заполнены.
Вспомогательная сущность Entry, «оборачивающая» каждую пару ключ-значение, представляет собой значимый тип:
private struct Entry
{
public uint hashCode;
public int next;
public TKey key;
public TValue value;
}То есть для хранения такой сущности не выделяется отдельное место в куче, она помещается по месту объявления, то есть в данном случае в области памяти, занимаемой массивом _entries. Это заметно лучше, чем в реализации ConcurrentDictionary, где аналогичная сущность представлена ссылочным типом. Подход позволяет снижать нагрузку на память (ведь каждый экземпляр ссылочного типа в 64 разрядной системе требует дополнительно 16 байт на служебные данные и 8 байт непосредственно на ссылку) и на сборщик мусора, которому не нужно тратить время на анализ множества мелких и по сути служебных объектов.
С другой стороны такой массив _entries при активной работе с Dictionary достаточно быстро достигнет 85000 байт и переместится в кучу больших объектов LOH (например, если ключ и значение будут ссылочного типа, то для 64 разрядного приложения это случится при 3372 добавленных значений, а в некоторых случаях и при 1932). Как известно, куча больших объектов при активной работе подвержена фрагментации, что ведет к росту потребляемой приложением неиспользуемой памяти.
Почему разработчики Microsoft не разделили _entries на четыре массива, соответствующих полям Entry? Это бы отдалило перспективу попадания в LOH и в некоторых сценариях снизило потребление памяти (увеличив, скорее всего, частоту сборок мусора). Видимо, посчитали, что выигрыш не настолько велик.
При работе со словарем разработчик должен учитывать, что это не бесплатная структура данных. Для хранения одного значения дополнительно потребляется как минимум 12 байт памяти (4 байта в массиве _buckets и по 4 байта на поля hashCode и next сущности Entry). Создавая в памяти приложения словарь и заполняя его, например, миллионом значений, мы получим как минимум 12МБ перерасхода памяти. Однако только ли этим все ограничится? Нет.
Механизм Dictionary всегда резервирует определенное количество памяти для еще не добавленных элементов. Иначе ни о какой быстрой вставке не могло бы быть и речи. На графике представлена динамика выделения памяти для словаря типа Dictionary<int, int> при добавлении значений (красный цвет). Для сравнения показано, сколько байт занимает полезная нагрузка – хранимые в словаре данные (синий цвет). Количество добавленных элементов от 500 тыс. до 13 млн. Словарь инициализируется на стартовую емкость 500 тыс.

Как видно, стратегия резервирования памяти по умолчанию при работе со словарем достаточно затратна. Если свободное место в словаре закончилось, то алгоритм обычно решает удвоить текущую емкость, что во многих случаях может оказаться ненужным, так как в приложении не наберется столько полезных данных.
Еще одна особенность работы механизмов алгоритма заключается в том, что при каждом расширении емкости _buckets и _entries создаются заново и все существующие значения просто копируются из старых массивов в новые, после чего ссылки на старые «отпускаются», становятся доступными для сборщика мусора. Для словарей с большим количеством значений каждое такое выделение памяти осуществляется сразу в LOH, что приближает вызов полной сборки мусора.
Например, при работе тестов для создания представленного выше графика приложение аллоцировало суммарно 746МБ и выполнило 3 сборки мусора во втором поколении.
Следует так же учитывать, что в текущей реализации Dictionary самостоятельно не умеет отдавать в систему чрезмерно занятую память после массового удаления элементов. До недавних пор такую операцию нельзя было запустить и в коде, оставалось только пересоздавать словарь полностью, впрочем, в последние версии .NET Core был включен соответствующий метод TrimExcess, позволяющий принудительно привести объем выделенной памяти в соответствие количеству хранимых элементов.
В зависимости от логики работы с данными обычно можно подобрать определенную экономную стратегию:
- Если необходимо быстро заполнить словарь, то нужно предварительно оценить объем данных и задать конечную емкость в конструкторе или через EnsureCapacity. Это позволит избежать лишних аллокаций больших областей памяти.
- По графику видно, что стратегия заполнения словаря по умолчанию привела к резервированию 400МБ памяти для хранения 10млн. значений (80МБ полезных данных). Но если задать емкость при вызове конструктора new Dictionary<int, int>(10001000), то для хранения этих же данных будет зарезервировано всего 190МБ. Если объем хранимых данных со временем меняется незначительно, то с этим способом можно будет избежать не только лишних аллокаций при заполнении, но и длительного резервирования ненужной памяти.
- Если объем хранимых данных умеренно растет, то можно запоминать текущую емкость Dictionary и перед ее достижением увеличивать емкость методом EnsureCapacity(capacity*коэффициент), не дав словарю расширяться самостоятельно. Следует учитывать, что вызов этого метода приводит к пересозданию массивов _buckets и _entries и копированию данных из старых сущностей в новые. Поэтому величину новой емкости следует подбирать аккуратно. Текущую емкость можно оценить, вызвав EnsureCapacity(0).
- Если объем хранимых данных в целом находится на одном уровне, но периодически (не часто) ненадолго, но значительно увеличивается, то можно разделить хранение между двумя экземплярами Dictionary: постоянным и периодически создаваемым. Это приведет к тому, что часть выделенной памяти будет существовать долговременно и не внесет вклад в фрагментацию и нагрузку на сборщик мусора. Если пики очень частые, то имеет смысл зарезервировать под них постоянную область памяти (создать словарь под максимально возможную оценку объема данных).
- В некоторых случаях можно вызывать метод TrimExcess. Однако его периодическое использование с большим количеством хранимых значений приведет к фрагментации LOH и поэтому во многих случаях не может считаться самым удачным решением. Не стоит использовать этот метод при частых увеличениях и последующих уменьшениях объема хранимых данных.
Значительное влияние на объем потребляемой памяти оказывает выбор между использованием значимых и ссылочных типов для хранения в Dictionary. Модифицируем предыдущий опыт так, что будет заполняться словарь вида Dictionary<Key, Value>, где:
public class Key
{
public int Item { get; set; }
public Key(int item)
{
Item = item;
}
public override bool Equals(object obj)
{
return Item.Equals(obj);
}
public override int GetHashCode()
{
return Item.GetHashCode();
}
}
public class Value
{
public int Item { get; set; }
public Value(int item)
{
Item = item;
}
}График примет вид.

В чем же причина такого взрывного роста?
Их даже несколько:
- Каждый созданный объект в 64 разрядной системе содержит указатель на блок синхронизации (8 байт) и указатель на таблицу методов (8 байт).
- Ссылка, которая хранится в словаре, добавляет 8 байт к «весу» объекта.
- Поле Item в объектах Key и Value занимает 8 байт, несмотря даже на то, что размер поля Item в обоих случаях составляет 4 байта.
В итоге затраты на хранение одного значения увеличиваются с 20 до 76 байт.
Из результатов опыта можно сделать следующие выводы:
- Если суммарный размер хранимых полей не сильно отличается от размера указателя (то есть не превышает нескольких десятков байт), то следует сделать выбор в сторону использования структурного типа для хранения значений.
- Не стоит злоупотреблять ключами ссылочного типа, в том числе текстового. Содержание такого ключа стоит достаточно дорого.
Мы выяснили, что нужно учитывать при работе с большими объемами данных. А что же с небольшими словарями? Несколько раз сталкивался с проектами, где хранение данных было организовано с помощью огромной коллекции небольших (на 10-20-30 значений) словарей. Оптимальное ли это решение?
Выполним еще один опыт. Проверим, сколько будет занимать поиск по Dictionary<int, int>(int count) в сравнении с поиском по структуре:
struct Entry<TValue>
{
public int[] Keys;
public TValue[] Values;
public Entry(int count)
{
Keys = new int[count];
Values = new TValue[count];
}
public bool TryGetValue(int key, out TValue value)
{
for (int j = 0; j < Keys.Length; ++j)
{
if (Keys[j] == key)
{
value = Values[j];
return true;
}
}
value = default(TValue);
return false;
}
}Здесь count – количество пар ключ-значение, среди которых осуществляется поиск.
Результаты представлены на графике.

Как видно, время поиска с перебором элементов массива линейно растет от 18 наносекунд при count=10 до 134 нс при count=190 (при тестировании создается 50 тыс. таких поисковых массивов). Затраты времени на поиск по словарю сначала существенно превышают поиск перебором (в пике – на 29 нс), но при определенном количестве элементов (в моей тестовой конфигурации при 150) алгоритмы меняются местами, после чего рост времени на поиск по словарю практически прекращается (помним, поиск в словаре при идеальных условиях константный).
Причиной такого поведения является упорядоченность перебора при поиске по массиву, что делает этот поиск предсказуемым для процессора (точнее, для его кэша, попробуйте например поменять при поиске в Entry проход по циклу на обратный, поиск сразу замедлится).
Другой причиной можно назвать заложенную в словарь гибкость, с использованием вызова виртуальных функций (callvirt для GetHashCode и Equals). Такой вызов – достаточно долгая операция. Кстати, в некоторых случаях, если требования к скорости работы алгоритма высоки, можно рассмотреть вопрос о самостоятельной переработке словаря с заменой обобщенного (generic) ключа на ключ конкретного типа. На графике выше приведены результаты скорости поиска в таком модифицированном словаре для нашего тестового случая.
Там же для сравнения приведены результаты аналогичного теста для SortedList<int, int>.
Теперь рассмотрим затраты памяти на работу поисковых алгоритмов.
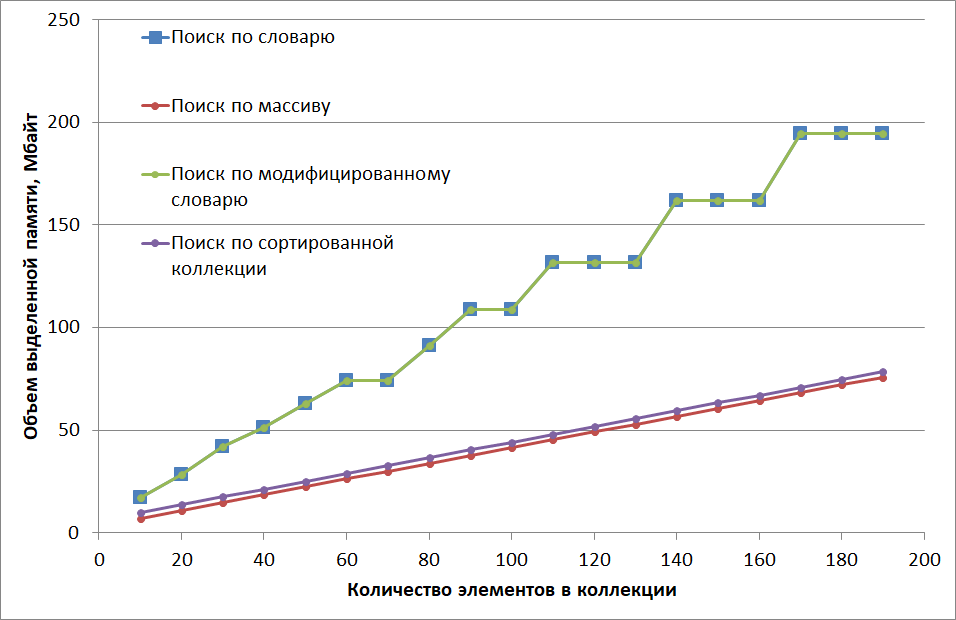
Как видно, архитектура приложения с использованием словарей требует значительно больше памяти на хранение данных.
Я обычно рекомендую придерживаться следующего правила: если число элементов в коллекции не превышает пятидесяти и ключ неуправляемого значимого типа, то для критичного к скорости выполнения кода можно рассмотреть вопрос о возможности использования массивов вместо словарей и сортированных коллекций. Это позволит сэкономить значительное количество ресурсов памяти и процессора.
Во всех представленных примерах нужно учитывать, что в тестовой конфигурации используются данные небольшого размера, поэтому затраты на служебную информацию относительно высоки.
Тестовые проекты можно найти по ссылке.
