 Многие знают, что ABBYY занимается обработкой и извлечением данных из разных документов. Но у наших продуктов есть и другие интересные возможности. В частности, с помощью решения ABBYY Intelligent Search можно быстро и удобно искать информацию по смыслу в электронных документах из корпоративных систем. Этим уже пользуются крупные российские компании, например, производитель ракетных двигателей АО «НПО Энергомаш».
Многие знают, что ABBYY занимается обработкой и извлечением данных из разных документов. Но у наших продуктов есть и другие интересные возможности. В частности, с помощью решения ABBYY Intelligent Search можно быстро и удобно искать информацию по смыслу в электронных документах из корпоративных систем. Этим уже пользуются крупные российские компании, например, производитель ракетных двигателей АО «НПО Энергомаш». Многолетняя практика показывает, что время вывода космических двигателей на рынок от момента начала работ составляет от 5 до 7 лет. В то же время для удержания лидирующих позиций необходимо сокращать сроки разработки и изготовления до 3 – 4 лет. Кроме того, усиление конкуренции привело к необходимости существенного снижения стоимости выпускаемых двигателей на 30 – 50%.
Указанных показателей невозможно достигнуть без внедрения современных цифровых технологий. Наиболее передовые компании используют инновационные подходы не только на всех стадиях производства, но и на всех стадиях жизненного цикла их изделий. Чем больше компании уходят в цифру, тем острее становится вопрос: как использовать большие данные с максимальной для себя выгодой?
За 90 лет работы НПО Энергомаш накопил вековой объем документов (как бумажных, так и электронных) с ценной информацией о наработках испытателей и конструкторов. Большая часть документов уже хранится в информационных системах компании (ИС). Согласно исследованию IDC, в среднем сотрудники крупных организаций пользуются 5-6 внутренними ИС. Около 36% времени в среднем уходит на поиск информации – в масштабах крупной компании это тысячи рабочих часов в день.
Сегодня мы расскажем, как помогли НПО Энергомаш создать корпоративную интеллектуальную информационно-поисковую систему (КИИПС) на базе ABBYY Intelligent Search – такую же удобную и быструю, как популярные поисковики.
Чем занимается Энергомаш и при чем тут Гагарин
 Со дня основания, 15 мая 1929 года, Энергомаш изготовил более 12 тысяч двигателей для ракет-носителей не только российского, но и зарубежного производства. На этих «моторах» был запущен первый искусственный спутник Земли, отправился в космос «Восток-1» с первым космонавтом Юрием Гагариным на борту, совершил полет космоплан «Буран» и до сих пор осуществляются пуски американских ракет-носителей Atlas и Antares. Например, 26 марта 2020 года ракета-носитель Atlas V, оснащенная двигателями российского производства, вывела на орбиту американский военный спутник стратегической системы связи. В первом полугодии 2020 года двигатели разработки Энергомаш успешно отработали в 11 космических пусках, что составляет 24,4% от всех пусков в мире.
Со дня основания, 15 мая 1929 года, Энергомаш изготовил более 12 тысяч двигателей для ракет-носителей не только российского, но и зарубежного производства. На этих «моторах» был запущен первый искусственный спутник Земли, отправился в космос «Восток-1» с первым космонавтом Юрием Гагариным на борту, совершил полет космоплан «Буран» и до сих пор осуществляются пуски американских ракет-носителей Atlas и Antares. Например, 26 марта 2020 года ракета-носитель Atlas V, оснащенная двигателями российского производства, вывела на орбиту американский военный спутник стратегической системы связи. В первом полугодии 2020 года двигатели разработки Энергомаш успешно отработали в 11 космических пусках, что составляет 24,4% от всех пусков в мире.Сегодня Энергомаш входит в госкорпорацию Роскосмос и возглавляет интегрированную структуру ракетного двигателестроения, в которую входят ведущие предприятия этой отрасли.
В последние годы компания активно внедряет масштабные ИТ-решения, которые широко используют анализ данных, машинное обучение и все возможности технологий обработки естественного языка. Компания поставила стратегическую цель – создать полностью цифровое производство к 2021 году.
К примеру, в рамках проекта «Цифровые технологии проектирования и производства» одной из ключевых задач являлось внедрение PLM-системы (автоматизированной системы управления жизненным циклом изделий). Ее цель – обеспечить создание электронной конструкторской документации (ЭКД) и моделирование на ее основе работы двигателя и других рабочих процессов в технологических и производственных подразделениях НПО Энергомаш и готовность к обмену ЭКД между предприятиями отрасли.
Зачем понадобился поиск по вселенной Энергомаша
Для достижения стратегической цели по созданию цифрового производства компания ведет целый комплекс проектов, в основе которых лежит работа с большими объемами данных. Одним из них является проект создания корпоративной интеллектуальной информационно-поисковой системы.
Цель проекта – сохранить, приумножить и поставить на службу цифровому производству знания и компетенции предприятия, накопленные за десятилетия работы.
В рамках проекта решалось две задачи:
1). Упростить для конструкторов и инженеров поиск полезной информации в документах прошлых лет.
В СССР было создано много разработок, но не все реализованы, потому что не всегда на них выделяли инвестиции или уровень развития технологий не позволял завершить задуманное. В наше время такие разработки могут обрести вторую жизнь. Для этого компания просит опытных конструкторов делиться своими исследовательскими работами и чертежами, которые еще хранятся на бумаге. Это поможет оцифровать ценные данные, сохранить на долгие годы и передать знания молодому поколению ученых и инженеров.
Конечно, поиск документов в электронных системах и раньше существовал в Энергомаш, но сотрудникам было непросто найти нужную информацию для работы.
Под спойлером рассказываем подробнее, как раньше был устроен этот процесс.
В каждой из 7 информационных систем был встроенный поисковый механизм со своими правилами. Например, где-то нужную информацию искали с помощью тегов, которые сотрудники проставляли к документам, где-то – по ключевым словам, то есть тем, которые встречаются в тексте. Соответственно, качество поиска в разных ИС отличалось, а сотрудники сталкивались с некоторыми трудностями:
Сложность также заключалась в том, что за десятки лет изобретательский язык поменялся, стал более простым, одни термины вышли из употребления, появились другие. В результате специалист способен сформулировать, что именно он хочет найти, но правильный поисковой запрос составить не получается: система не выдает нужных документов. Кроме того, часть исследовательских работ еще хранилась в бумажном виде.
В результате:
Приведем пример. В АО «НПО Энергомаш» есть информационная база данных (ИБД) исследовательских, конструкторских и расчетных работ. Сотрудник заходил в нее, вбивал в поиске «рама рд», желая найти полную информацию по запросу в документах, которые размещены в ИБД, а это стандарты организации, технические указания, результаты исследований, методики расчетов и пр. Поиск в системе осуществляется только по тегам, введенным для каждого документа на усмотрение специалиста, вносившего документ в ИБД. В результате поиск выдавал сотруднику только какой-то один документ, в котором встречалось указанное в запросе слово «рама».
Поэтому понадобился такой поиск, который позволил бы найти документы, соответствующие поисковому запросу не только по содержанию, но и по смыслу, не только по тегам, но и по самому тексту документа.
- теги были проставлены не у всех документов;
- не отслеживалась версионность документов;
- невозможно было вести поиск по синонимам, гипонимам и прочим конструкциям, которые передавали тот же смысл другими словами.
Сложность также заключалась в том, что за десятки лет изобретательский язык поменялся, стал более простым, одни термины вышли из употребления, появились другие. В результате специалист способен сформулировать, что именно он хочет найти, но правильный поисковой запрос составить не получается: система не выдает нужных документов. Кроме того, часть исследовательских работ еще хранилась в бумажном виде.
В результате:
- на поиск релевантного документа уходило много времени. Не всегда было понятно, как нужно сформулировать поисковый запрос, чтобы найти нужный документ;
- поисковая выдача содержала только те документы, теги в которых полностью совпадали с текстом запроса, не учитывались варианты с опечатками.
Приведем пример. В АО «НПО Энергомаш» есть информационная база данных (ИБД) исследовательских, конструкторских и расчетных работ. Сотрудник заходил в нее, вбивал в поиске «рама рд», желая найти полную информацию по запросу в документах, которые размещены в ИБД, а это стандарты организации, технические указания, результаты исследований, методики расчетов и пр. Поиск в системе осуществляется только по тегам, введенным для каждого документа на усмотрение специалиста, вносившего документ в ИБД. В результате поиск выдавал сотруднику только какой-то один документ, в котором встречалось указанное в запросе слово «рама».
Поэтому понадобился такой поиск, который позволил бы найти документы, соответствующие поисковому запросу не только по содержанию, но и по смыслу, не только по тегам, но и по самому тексту документа.
2). Упростить и ускорить поиск данных для служебных подразделений: бухгалтерии, юристов и других специалистов, которые составляют, редактируют, согласуют документы в учетных системах и обмениваются информацией.
Компания хотела, чтобы сотрудники могли собирать и анализировать необходимую для работы информацию о финансах, производстве и другие значимые сведения из разнородных корпоративных систем, просто вводя запросы в одной поисковой строке. Необходимо было создать единую точку доступа к данным, хранящимся в информационных системах компании, с обеспечением разграниченного доступа к информации в зависимости от полномочий пользователя в каждой системе.
Почему это важно? Через 7 лет более половины всех данных в мире будут храниться в корпоративных системах, следует из отчета Seagate и IDC Data age. Чтобы необходимая информация всегда была под рукой, ее надо быстро находить. Так, по данным исследования IDC и ABBYY «Рынок искусственного интеллекта в России», представители ИТ (48%) и бизнес-подразделений (33%) видят большие возможности в применении ИИ для корпоративного поиска и классификации документов в ближайшие два года.
Чтобы справиться с этими задачами, компании понадобился удобный сквозной поиск по многочисленным ИС. Энергомаш рассматривал несколько поисковых систем, но в итоге решил попробовать ABBYY Intelligent Search. На выбор повлияло, во-первых, наличие технологий обработки естественного языка, которые позволяют находить документы, релевантные поисковым запросам по смыслу, а не только по ключевым словам. Во-вторых, возможность разграничивать права доступа пользователей к результатам поиска. Подробнее об этом мы расскажем чуть позже, а сейчас – о том, как мы стартовали.
Первый «выход» в поиск
Энергомаш решил проверить работу интеллектуального поиска на 3 тысячах документов из информационной базы данных (ИБД) исследовательских, конструкторских и расчетных работ.
Для этого ABBYY разработала прототип коннектора к ИБД, который связал ABBYY Intelligent Search c базой документов. Коннектор – это java-программа, которая используется для загрузки документов в индекс. Как это работает?
1). Сначала строим полнотекстовый поисковый индекс
Полнотекстовый индекс – это, грубо говоря, список всех слов в документе и его метаданные (номер документа, название, дата создания). Полнотекстовый индекс создается довольно быстро и позволяет искать нужную информацию по ключевым словам – тем, которые встречаются в тексте.


Чтобы построить полнотекстовый индекс, нужен коннектор. Он связывает поисковое решение с определенной информационной системой и собирает («индексирует») характеристики каждого документа, например:
- название ИС, где хранится файл,
- дату последней модификации документа,
- версию документа в источнике,
- формат документа,
- коды языков, на которых составлен документ,
- путь к документу в ИС,
- дату последней индексации документа
- и др.
Эти характеристики в дальнейшем помогут не только ускорить поиск документа, но и упростить для коннектора логику работы с ними. В частности, коннектор анализирует разные версии одного и того же документа, чтобы отдать в индекс только последнюю. Коннектор также получает информацию о документах, которые были удалены из источника.
Создавать поисковый индекс помогает встроенный в ABBYY Intelligent Search краулер (поисковый робот). Он через равные промежутки времени опрашивает коннекторы, проверяет, появились ли в ИС новые документы, какие документы удалены, как изменились права доступа к документам. Соответственно, с заданной периодичностью индекс обновляется.
Индексируются не только текстовые документы, но и файлы в графическом формате. Например, это могут быть скан-копии чертежей в JPEG или PDF без текстового слоя. При работе с изображениями, поисковое решение сначала автоматически распознает текст и добавляет его в поисковый индекс.
Кроме того, система умеет обрабатывать архивные файлы ZIP, RAR, TAR – при условии, что они не защищены паролем. Архивы распаковываются, изображения из них распознаются, текст индексируется.
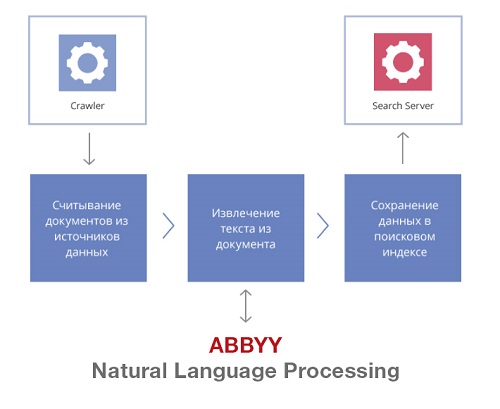

Поисковый индекс содержит произвольный набор полей, которые в том числе могут быть использованы для фильтрации результатов поиска (автор документа, дата создания, номер изделия и др.).
2). Затем применяем технологии обработки естественного языка
В фоновом режиме происходит обогащение поискового индекса семантической информацией. Для этого мы использовали уже имеющуюся у нас семантико-лингвистическую онтологию – проще говоря, описания предметов и явлений реального мира. О том, как мы создавали эту модель, мы уже рассказывали на Хабре здесь и здесь.
С помощью машинного обучения и технологий обработки естественного языка в каждом документе анализируется синтаксис предложений, морфология и семантические значения буквально каждого слова из текста. Эта информация дополняет поисковый индекс и дает возможность искать уже не по ключевым словам, а по синонимам, гипонимам и другим конструкциям, которые передают тот же смысл, но другими выражениями. Таким образом, поисковая система точнее ищет информацию в корпоративных источниках.


Это очень удобно, если наш с вами ровесник сформулировал поисковый запрос своими словами, а найти хочет документы 40-летней давности, где, возможно, нужный ему предмет назывался другими терминами. Например, для запроса «дефект рамы» система подберет все возможные семантические выражения, связанные с этим термином. В результатах могут фигурировать «прогиб», «дыра», «излом» или «факт нарушения конструкторской технологической документации».
Приведем еще один пример:

В результатах поиска по запросу «колебания тяги» будут также отображаться тексты, в которых содержится словосочетание «варьирование тяги».
Технологии обработки естественного языка также помогают поисковой системе автоматически исправлять орфографические опечатки в тексте запроса. Например, система поймет, что в слове «подшибник» есть ошибки, и сразу будет искать документы, в которых упоминается «подшипник».
Итоги первого запуска
Чтобы оценить работу интеллектуального поисковика, специалисты Энергомаш выполнили примерно по 30 запросов по документам ИБД с помощью встроенной в ИБД поисковой системы и с помощью ABBYY Intelligent Search. Затем сравнили результаты поисковой выдачи: какие документы удалось найти обеим системам, какие фразы подсвечивались в сниппетах. В итоге, встроенный в ИБД поиск не выдал результатов по некоторым запросам, так как способен обнаружить только ключевые, а не близкие по значению слова. ABBYY Intelligent Search выдал релевантные по всем запросам документы.
Что касается скорости, то при соблюдении требований к аппаратной платформе поисковый отклик не превышал доли секунды, как у популярных поисковиков. На самые сложные запросы уходило максимум до 3 секунд.
После успешного пилотного проекта Энергомаш принял решение использовать решение ABBYY Intelligent Search в основе Корпоративной интеллектуальной информационно-поисковой системы.
Поехали дальше
Энергомаш подключил к поиску 7 корпоративных источников: систему электронного документооборота LanDocs, файловое хранилище, ИБД, систему поддержки жизненного цикла изделия TeamCenter, систему управления ресурсами Галактика ERP и AMM, информационную систему управления проектами. Для каждой информационной системы создан отдельный индекс. Это делает поисковую систему гибкой в администрировании и дает возможность заново строить индекс по каждой системе в отдельности, задавая новые условия. Доступ в Систему корпоративного поиска организован через внутренний портал предприятия на главной странице. Проект был реализован совместно с партнером – компанией ЛАНИТ – крупнейшей российской многопрофильной группой IT-компаний.
Основные модули системы корпоративного поиска:
- главная страница поисковых запросов и результатов поиска;
- панель администратора (настройка индексов, фильтров, метаданных для каждой информационной системы);
- статистика количества документов (отображает количество документов в индексе по каждой информационной системе за период).
Система корпоративного поиска запущена в промышленную эксплуатацию с 1 июля 2020 года. На момент запуска было проиндексировано 500 тысяч документов. Ожидается, что к концу года при активном использовании системы и подключении новых информационных источников количество документов в индексе достигнет более 1 миллиона.
Как обеспечить безопасность
Как и у любого крупного бизнеса, у НПО Энергомаш есть документы, не предназначенные для доступа всех сотрудников. Ключевым требованием безопасности при запуске проекта было обеспечение доступа к документам в соответствии с ролевой моделью каждой информационной системы. Для этого было сделано:
1). Локальное хранение информации
Поисковое решение ABBYY развернуто на отдельном сервере во внутреннем контуре НПО Энергомаш. Там хранятся все поисковые индексы и их резервные копии на случай потерь и их настройки.
2). Ролевая модель информационной системы
Для безопасности организовано разграничение прав доступа пользователей к результатам поиска по каждой информационной системе. Все корпоративные системы, подключенные к ABBYY Intelligent Search, поддерживают доменную авторизацию. Пользователь входит в систему под доменной учетной записью, выполняет запрос, в результатах поиска видит документ с учетом настроек предпросмотра документа по каждой информационной системе и уровнем доступа, выполненными непосредственно в самой системе корпоративного поиска, и с учетом доступа к документу в самой информационной системе-источнике. Если у пользователя есть права на работу с документом в системе-источнике, то переход в оригинал документа можно осуществить непосредственно из системы корпоративного поиска, нажав на ссылку.
Планы на будущее
По замыслу Энергомаша, интеллектуальный поиск информации поможет упростить и ускорить бизнес-процессы на предприятии, например, опосредованно ускорить выход новых изделий на рынок, повысить их качество и снизить себестоимость. Идеи и проекты, которые сохранились в старых документах, можно будет использовать в современных разработках предприятия. Например, создавать на основе наработок что-то совсем новое и опережать конкурентов на мировом рынке.
Упомянем и о планах на будущее:
- В будущем к системе корпоративного поиска планируется подключать информационные источники других предприятий, входящих в структуру Энергомаша. В этом случае поисковый индекс может расшириться до 2 млн документов.
- Одна из задач, связанная с развитием проекта, – это регулярное повышение качества поисковой выдачи. Для этого разрабатывается административная консоль, которая позволит с помощью веб-интерфейса анализировать статистику поиска. Например, отбирать запросы пользователей, которые не увенчались успехом: если мы видим, что по какому-то запросу пользователи не находят нужного документа, им можно помочь его найти. Например, за конкретным поисковым запросом можно закрепить необходимые ссылки на документы, которые могут быть никак не связаны с запросом тематически. Разумеется, анализ поисковой выдачи станет востребован в полной мере, когда к системе подключится большое количество пользователей и появится статистика использования поисковой системы.
- Энергомаш также планирует исследовать возможность построения сложных аналитических отчетов с использованием функции поиска.
А на ваш взгляд, какие еще задачи можно решить с помощью корпоративного поиска?
Елизавета Титаренко, редактор корпоративного блога ABBYY
