Дарова, Хабр! Около года назад я решил заработать на ставках на спорт используя свои знания математики и программирования и тогда я наткнулся на небольшую проблему — как же достать нужную мне информацию с сайта? Как парсить веб-страницы? В этой статье я расскажу простыми словами каким тонкостям я научился.
Что ж такое парсинг? Это собирание и систематизирование информации, которая размещена на веб-сайтах с помощью специальных программ, автоматизирующих процесс.
Парсинг обычно используется для анализа ценовой политики и получения контента.
Чтобы забрать деньги у букмекеров мне надо было оперативно получать информацию про коэффициенты на определённые события с нескольких сайтов. В математическую часть вдаваться не будем.
Поскольку я изучал С# у себя в шараге, я решил всё писать на нём. Ребята со Stack Overflow посоветовали использовать Selenium WebDriver. Это драйвер браузера(программная библиотека), который позволяет разрабатывать программы, управляющие поведением браузера. То что надо, подумал я.
Установил библиотеку и побежал смотреть гайды в интернете. Спустя некоторое время я написал программу, которая могла открыть браузер и переходить по некоторым ссылкам.
Ура! Хотя стоп, а как на кнопки нажимать, как доставать нужную информацию? Тут нам поможет XPath.
Если простыми словами, то это язык запросов к элементам XML и XHTML документа.
В этой статье я буду использовать Google Chrome. Однако в других современных браузерах должен быть если не такой же, то очень похожий интерфейс.
Чтобы посмотреть код страницы, на которой вы находитесь надо нажать F12.

Чтобы посмотреть, в каком месте кода находиться элемент на странице(текст, картинка, кнопка) надо нажать на стрелочку в левом верхнем углу и выбрать данный элемент на странице. Теперь перейдем к синтаксису.
Стандартный синтаксис для написания XPath:
//tagname[@attribute='value']
//: Выбирает все узлы в html документе начиная от текущего узла
Tagname: Тег текущего узла.
@: Выбирает атрибуты
Attribute: Имя атрибута узла.
Value: Значение атрибута.
Может быть поначалу непонятно, но после примеров всё должно встать на свои места.
Рассмотри несколько простых примеров:
//input[@type='text']
//label[@id='l25’]
//input[@value= '4']
//a[@href= 'www.walmart.com']
Рассмотрим более сложные примеры для заданного html'я:
XPath = //div[@class= 'contentBlock']//div
Для этого XPath’а будут выбраны следующие элементы:
XPath = //div[@class= 'contentBlock']/div
Обратите внимание на разницу между /(выбирает от корневого узла) и //(выбирает узлы от текущего узла независимо от их местонахождения). Если непонятно, то посмотрите на примеры выше ещё раз.
//div[@class= 'contentBlock']/div[@class= 'listItem']/a[@class= 'link']/span[@class= 'name']
Этот запрос равносилен этим при таком html’е:
//div/div/a/span
//span[@class= 'name']
//a[@class= 'link']/span[@class= 'name']
//a[@class='link' and href= 'habr.com']/span
//span[text() = 'habr' or text() = 'habrhabr']
//div[@class= 'listItem']//span[@class= 'name']
//a[contains(href, 'habr')]/span
//span[contains(text(),'habr')]
Результат:
//span[text()='habr']/parent::a/parent::div
Равносилен
//div/div[@class= 'listItem'][1]
Результат:
parent:: — возвращает предка на один уровень выше.
Есть ещё супер крутая фича, такая как following-sibling:: — возвращает множество элементов на том же уровне, следующих за текущим, аналогично preceding-sibling:: — возвращает множество элементов на том же уровне, предшествующих текущему.
//span[@class= 'name']/following-sibiling::text()[1]
Результат:
Думаю, теперь стало понятнее. Для закрепления материала советую зайти на этот сайт и написать несколько запросов, чтобы найти некоторые элементы этого html’я.
Теперь зная, что такое XPath, вернемся к написанию кода. Поскольку модераторам хабра не нравятся букмекерские конторы, то будет парсить цены на кофе в Walmart'е
Thread.Sleep'ы были написаны, чтобы веб-страничка успевала загрузиться.
Программа откроет сайт магазина Walmart, нажмёт пару кнопок, откроет отдел с кофе и получит название и цены на товары.
Если веб-страничка довольно таки большая и поэтому XPath'ы долго работают или их сложно написать, то надо воспользоваться каким-то другим методом.
Для начала рассмотрим как на сайте появляется контент.

Если простыми словами, то браузер делает запрос серверу с просьбой дать нужную информацию, а сервер в свою очередь, эту информацию предоставляет. Всё это осуществляется с помощью HTTP запросов.
Чтобы посмотреть на запросы, которые отправляет ваш браузер на конкретном сайте, то просто откройте этот сайт, нажмите F12 и перейдите во вкладку Network, после этого перезагрузите страницу.
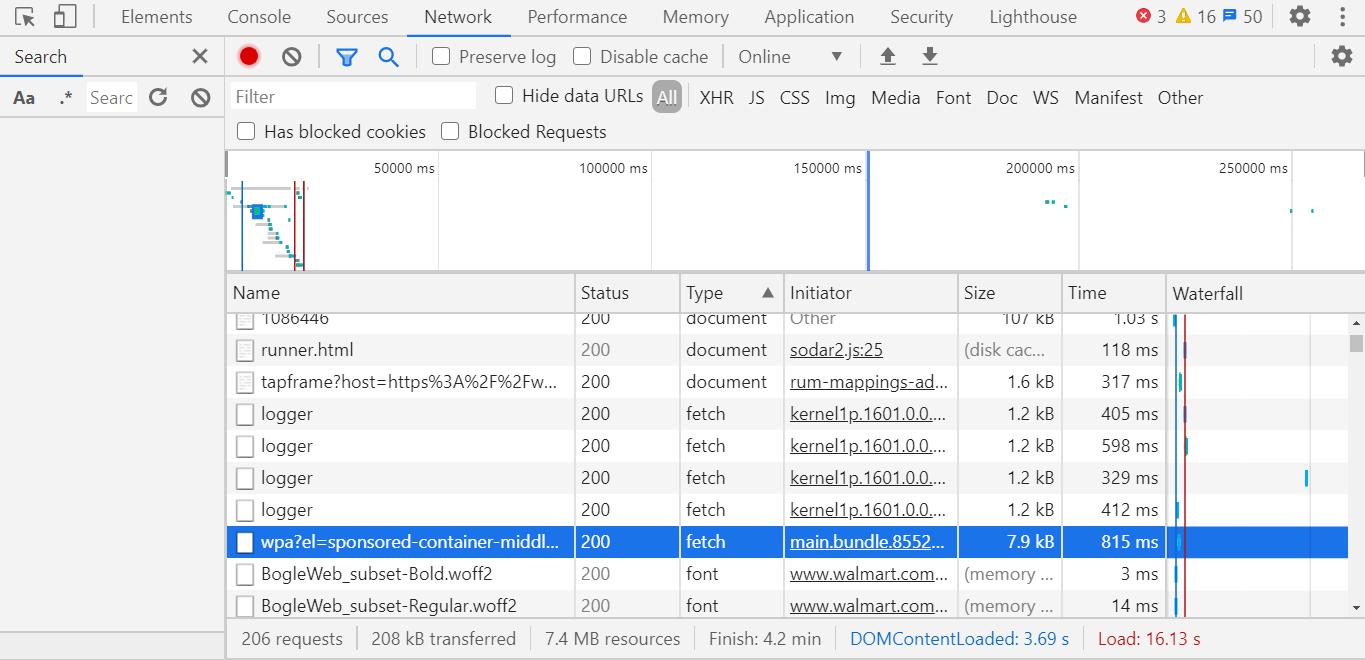
Теперь осталось найти нужный нам запрос.
Как это делать? – рассмотрите все запросы с типом fetch(третья колонка на картинке выше) и смотрите на вкладку Preview.

Если она не пустая, то она должна быть в формате XML или JSON, если нет – продолжайте поиски. Если да, то посмотрите, есть ли здесь нужная вам информация. Чтобы это проверить советую использовать какой – то JSON Viewer или XML Viewer(загуглите и откройте первую ссылку, скопируйте текст с вкладки Response и вставьте в Viewer). Когда вы найдёте нужный вам запрос, то сохраните у себя где то его название(левая колонка) или хост URL'а(вкладка Headers), чтоб потом не искать. Например если на сайте walmart’а открыть отдел кофе, то будет отправляться запрос, юрл которого начинается с walmart.com/cp/api/wpa. Там будет вся информация про кофе в продаже.

Полпути пройдено, теперь этот запрос можно «подделывать» и отправлять сразу через программу, получая нужную информацию за считанные секунды. Осталось распарсить JSON или XML, а это делается намного проще, чем писание XPath'ов. Но зачастую формирование таких запросов вещь довольно таки неприятная(смотри на URL на картинке выше) и если у вас даже всё получиться, то в некоторых случаях вы будете получать такой ответ.
Сейчас вы узнаете, как можно избежать проблем с подражанием запроса используя альтернативу — прокси сервера.
Прокси сервер — устройство, являющееся посредником между компьютером и интернетом.

Было б замечательно, если б наша программа была прокси сервером, тогда можно быстро и удобно обрабатывать нужные респонсы с сервера. Тогда была б такая цепочка Браузер – Программа – Интернет(сервер сайта, который парсим).
Благо для си шарпа есть замечательная библиотека для таких нужд – Titanium Web Proxy.
Создадим класс PServer
Теперь пройдемся по каждому методу отдельно.
proxyServer.BeforeRepsone += OnRespone – добавляем метод обработки ответа с сервера. Он будет вызываться автоматически, когда будет приходить респонс.
explicitEndPoint — Конфигурация прокси сервера,
ExplicitProxyEndPoint(IPAddress ipAddress, int port, bool decryptSsl = true)
IPAddress и port, на котором работает прокси сервер.
decryptSsl – стоит ли расшифровывать SSL. Иначе говоря, если decrtyptSsl = true, то прокси сервер будет обрабатывать все запросы и ответы.
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest — добавляем метод обработки запроса перед его отправкой на сервер. Он также будет вызываться автоматически перед отправкой запроса.
proxyServer.Start() — «запуск» прокси-сервера, с этого момента он начинает обрабатывать запросы и ответы.
e.DecryptSsl = false — текущий запрос и ответ на него не будут обрабатываться.
Если нас не интересует запрос или ответ на него(например картинка или какой – то скрипт), то зачем его расшифровывать? На это тратиться довольно много ресурсов, и если будут расшифровываться все запросы и ответы, то программа будет долго работать. Поэтому если текущий запрос не содержит хост интересующего нас запроса, то расшифровывать его нет смысла.
await e.GetResponseBodyAsString() – возвращает респонс в виде строки.
Чтобы WebDriver подключился к прокси серверу, то надо написать следующие:
Теперь можно обрабатывать нужные вам запросы.
С помощью WebDriver'а можно переходить по страницам, нажимать на кнопки и подражать поведение обычного юзера. С помощью XPath'ов можно извлекать нужную информацию с веб-страниц. Если XPath'ы не работают, то всегда может помочь прокси сервер, который может перехватывать запросы между браузером и сайтом.
Парсинг
Что ж такое парсинг? Это собирание и систематизирование информации, которая размещена на веб-сайтах с помощью специальных программ, автоматизирующих процесс.
Парсинг обычно используется для анализа ценовой политики и получения контента.
Начало
Чтобы забрать деньги у букмекеров мне надо было оперативно получать информацию про коэффициенты на определённые события с нескольких сайтов. В математическую часть вдаваться не будем.
Поскольку я изучал С# у себя в шараге, я решил всё писать на нём. Ребята со Stack Overflow посоветовали использовать Selenium WebDriver. Это драйвер браузера(программная библиотека), который позволяет разрабатывать программы, управляющие поведением браузера. То что надо, подумал я.
Установил библиотеку и побежал смотреть гайды в интернете. Спустя некоторое время я написал программу, которая могла открыть браузер и переходить по некоторым ссылкам.
Ура! Хотя стоп, а как на кнопки нажимать, как доставать нужную информацию? Тут нам поможет XPath.
XPath
Если простыми словами, то это язык запросов к элементам XML и XHTML документа.
В этой статье я буду использовать Google Chrome. Однако в других современных браузерах должен быть если не такой же, то очень похожий интерфейс.
Чтобы посмотреть код страницы, на которой вы находитесь надо нажать F12.

Чтобы посмотреть, в каком месте кода находиться элемент на странице(текст, картинка, кнопка) надо нажать на стрелочку в левом верхнем углу и выбрать данный элемент на странице. Теперь перейдем к синтаксису.
Стандартный синтаксис для написания XPath:
//tagname[@attribute='value']
//: Выбирает все узлы в html документе начиная от текущего узла
Tagname: Тег текущего узла.
@: Выбирает атрибуты
Attribute: Имя атрибута узла.
Value: Значение атрибута.
Может быть поначалу непонятно, но после примеров всё должно встать на свои места.
Рассмотри несколько простых примеров:
//input[@type='text']
//label[@id='l25’]
//input[@value= '4']
//a[@href= 'www.walmart.com']
Рассмотрим более сложные примеры для заданного html'я:
<div class ='contentBlock'>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habr</span>
</a>
<div class = 'textConainer'>
<span class='description'>cool site</span>
"text2"
</div>
</div>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habrhabr</span>
</a>
<div class = 'textConainer'>
<span class='description'>the same site</span>
"text1"
</div>
</div>
</div>XPath = //div[@class= 'contentBlock']//div
Для этого XPath’а будут выбраны следующие элементы:
<div class = 'listItem'>
<div class = 'textConainer'>
<div class = 'listItem'>
<div class = 'textConainer'>XPath = //div[@class= 'contentBlock']/div
<div class = 'listItem'>
<div class = 'listItem'>Обратите внимание на разницу между /(выбирает от корневого узла) и //(выбирает узлы от текущего узла независимо от их местонахождения). Если непонятно, то посмотрите на примеры выше ещё раз.
//div[@class= 'contentBlock']/div[@class= 'listItem']/a[@class= 'link']/span[@class= 'name']
Этот запрос равносилен этим при таком html’е:
//div/div/a/span
//span[@class= 'name']
//a[@class= 'link']/span[@class= 'name']
//a[@class='link' and href= 'habr.com']/span
//span[text() = 'habr' or text() = 'habrhabr']
//div[@class= 'listItem']//span[@class= 'name']
//a[contains(href, 'habr')]/span
//span[contains(text(),'habr')]
Результат:
<span class='name'>habr</span>
<span class='name'>habrhabr</span>//span[text()='habr']/parent::a/parent::div
Равносилен
//div/div[@class= 'listItem'][1]
Результат:
<div class = 'listItem'>parent:: — возвращает предка на один уровень выше.
Есть ещё супер крутая фича, такая как following-sibling:: — возвращает множество элементов на том же уровне, следующих за текущим, аналогично preceding-sibling:: — возвращает множество элементов на том же уровне, предшествующих текущему.
//span[@class= 'name']/following-sibiling::text()[1]
Результат:
"text1"
"text2"Думаю, теперь стало понятнее. Для закрепления материала советую зайти на этот сайт и написать несколько запросов, чтобы найти некоторые элементы этого html’я.
<div class="item">
<a class="link" data-uid="A8" href="https://www.walmart.com/grocery/?veh=wmt" title="Pickup & delivery">
<span class="g_b">Pickup and delivery</span>
</a>
<a class="link" data-uid="A9" href="https://www.walmart.com/" title="Walmart.com">
<span class="g_b">Walmart.com</span>
</a>
</div>
<div class="item">
<a class="link" data-uid="B8" href="https://www.walmart.com/grocery/?veh=wmt" title="Savings spotlight">
<span class="g_b">Savings spotlight</span>
</a>
<a class="link" data-uid="B9" href="https://www.walmartethics.com/content/walmartethics/it_it.html" title="Walmart.com">
<span class="g_b">Walmart.com(Italian)</span>
"italian virsion"
</a>
</div>Теперь зная, что такое XPath, вернемся к написанию кода. Поскольку модераторам хабра не нравятся букмекерские конторы, то будет парсить цены на кофе в Walmart'е
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
IWebDriver driver = new ChromeDriver(pathToFile);
driver.Navigate().GoToUrl("https://walmart.com");
Thread.Sleep(5000);
IWebElement element = driver.FindElement(By.XPath("//button[@id='header-Header sparkButton']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//button[@data-tl-id='GlobalHeaderDepartmentsMenu-deptButtonFlyout-10']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//div[text()='Coffee']/parent::a"));
driver.Navigate().GoToUrl(element.GetAttribute("href"));
Thread.Sleep(10000);
List<string> names = new List<string>(), prices = new List<string>();
List<IWebElement> listOfElements =driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-title']/div")).ToList();
foreach (IWebElement a in listOfElements)
names.Add(a.Text);
listOfElements = driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-price']/span/span[contains(text(),'$')]")).ToList();
foreach (IWebElement a in listOfElements)
prices.Add(a.Text);
for (int i = 0; i < prices.Count; i++)
Console.WriteLine(names[i] + " " + prices[i]);Thread.Sleep'ы были написаны, чтобы веб-страничка успевала загрузиться.
Программа откроет сайт магазина Walmart, нажмёт пару кнопок, откроет отдел с кофе и получит название и цены на товары.
Если веб-страничка довольно таки большая и поэтому XPath'ы долго работают или их сложно написать, то надо воспользоваться каким-то другим методом.
HTTP запросы
Для начала рассмотрим как на сайте появляется контент.

Если простыми словами, то браузер делает запрос серверу с просьбой дать нужную информацию, а сервер в свою очередь, эту информацию предоставляет. Всё это осуществляется с помощью HTTP запросов.
Чтобы посмотреть на запросы, которые отправляет ваш браузер на конкретном сайте, то просто откройте этот сайт, нажмите F12 и перейдите во вкладку Network, после этого перезагрузите страницу.

Теперь осталось найти нужный нам запрос.
Как это делать? – рассмотрите все запросы с типом fetch(третья колонка на картинке выше) и смотрите на вкладку Preview.

Если она не пустая, то она должна быть в формате XML или JSON, если нет – продолжайте поиски. Если да, то посмотрите, есть ли здесь нужная вам информация. Чтобы это проверить советую использовать какой – то JSON Viewer или XML Viewer(загуглите и откройте первую ссылку, скопируйте текст с вкладки Response и вставьте в Viewer). Когда вы найдёте нужный вам запрос, то сохраните у себя где то его название(левая колонка) или хост URL'а(вкладка Headers), чтоб потом не искать. Например если на сайте walmart’а открыть отдел кофе, то будет отправляться запрос, юрл которого начинается с walmart.com/cp/api/wpa. Там будет вся информация про кофе в продаже.
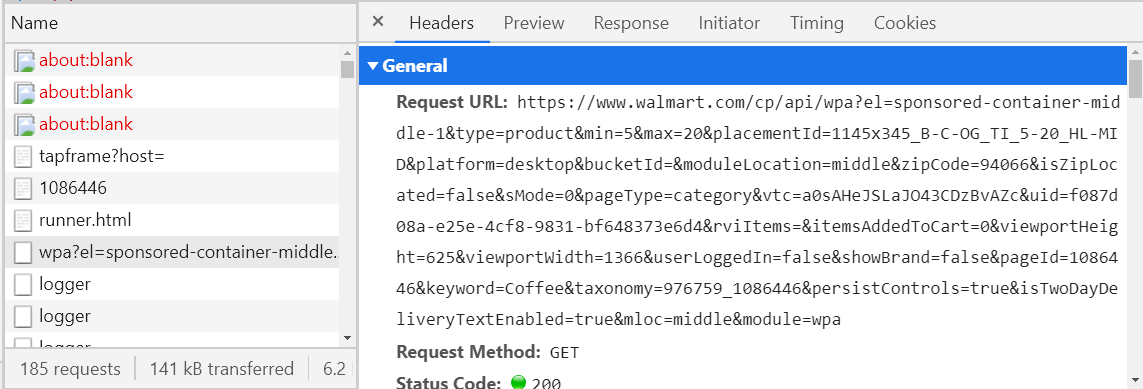
Полпути пройдено, теперь этот запрос можно «подделывать» и отправлять сразу через программу, получая нужную информацию за считанные секунды. Осталось распарсить JSON или XML, а это делается намного проще, чем писание XPath'ов. Но зачастую формирование таких запросов вещь довольно таки неприятная(смотри на URL на картинке выше) и если у вас даже всё получиться, то в некоторых случаях вы будете получать такой ответ.
{
"detail": "No authorization token provided",
"status": 401,
"title": "Unauthorized",
"type": "about:blank"
}Сейчас вы узнаете, как можно избежать проблем с подражанием запроса используя альтернативу — прокси сервера.
Прокси сервер
Прокси сервер — устройство, являющееся посредником между компьютером и интернетом.
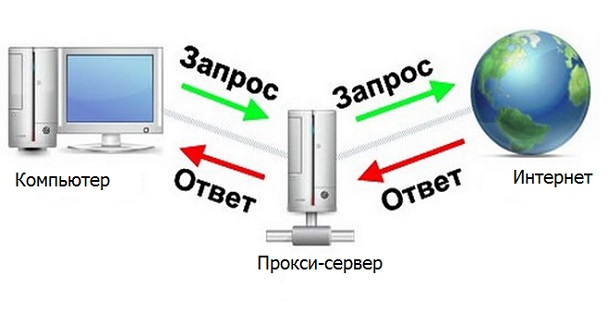
Было б замечательно, если б наша программа была прокси сервером, тогда можно быстро и удобно обрабатывать нужные респонсы с сервера. Тогда была б такая цепочка Браузер – Программа – Интернет(сервер сайта, который парсим).
Благо для си шарпа есть замечательная библиотека для таких нужд – Titanium Web Proxy.
Создадим класс PServer
class PServer
{
private static ProxyServer proxyServer;
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")){
Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}
}Теперь пройдемся по каждому методу отдельно.
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}proxyServer.BeforeRepsone += OnRespone – добавляем метод обработки ответа с сервера. Он будет вызываться автоматически, когда будет приходить респонс.
explicitEndPoint — Конфигурация прокси сервера,
ExplicitProxyEndPoint(IPAddress ipAddress, int port, bool decryptSsl = true)
IPAddress и port, на котором работает прокси сервер.
decryptSsl – стоит ли расшифровывать SSL. Иначе говоря, если decrtyptSsl = true, то прокси сервер будет обрабатывать все запросы и ответы.
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest — добавляем метод обработки запроса перед его отправкой на сервер. Он также будет вызываться автоматически перед отправкой запроса.
proxyServer.Start() — «запуск» прокси-сервера, с этого момента он начинает обрабатывать запросы и ответы.
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}e.DecryptSsl = false — текущий запрос и ответ на него не будут обрабатываться.
Если нас не интересует запрос или ответ на него(например картинка или какой – то скрипт), то зачем его расшифровывать? На это тратиться довольно много ресурсов, и если будут расшифровываться все запросы и ответы, то программа будет долго работать. Поэтому если текущий запрос не содержит хост интересующего нас запроса, то расшифровывать его нет смысла.
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")) Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}await e.GetResponseBodyAsString() – возвращает респонс в виде строки.
Чтобы WebDriver подключился к прокси серверу, то надо написать следующие:
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
ChromeOptions options = new ChromeOptions();
options.AddArguments("--proxy-server=" + IPAddress.Loopback + ":8000");
IWebDriver driver = new ChromeDriver(pathToFile, options);Теперь можно обрабатывать нужные вам запросы.
Заключение
С помощью WebDriver'а можно переходить по страницам, нажимать на кнопки и подражать поведение обычного юзера. С помощью XPath'ов можно извлекать нужную информацию с веб-страниц. Если XPath'ы не работают, то всегда может помочь прокси сервер, который может перехватывать запросы между браузером и сайтом.
