Comments 33
Если и сравнивать, то хотя бы с OpenCV, в котором есть такая же функция. Да и само сравнение в виде пары примеров — это смешно. Ни бенчмарков, ни нормальных метрик.
Именно, думаю, можно за вечер натренировать сеточку распознавать хотдоги КРУЧЕ ЧЕМ В ГУГЛ!!1
Разве это не здорово, что за один вечер можно стать топ1 мира по решению глобальной, пусть и несущественной, задачи?
Я уверен, что такие же решения уже есть, просто тут они не рассматриваются.
Это еще как здорово! Просто статья написана таким образом, что у читателя может сложиться мнение что решения от Google и Microsoft совсем никчемные.
Но все равно, как-то, слишком уж слабо себя гиганты показали. При их возможностях могли бы и некий общий классификатор входящего изображения сделать, чтобы он уже запускал более точные модели.
Типа, если на фото парковка, то апприорная вероятность увидеть там машину — 99%, а футляр для очков, или гигантскую детскую игрушку — 0.01
Тем более, что Ваше мнение неочевидно. Данные сервисы отлично решают задачу общего описания изображений. И в этом они хороши. Без четкой задачи (обведи все машины) сеть должна сделать абстрактное «всё». Что она должна отмечать? Дома? Окна на домах? Стекла? Раму? Кирпичи?
P.S. Например, с помощью этих сервисов можно автоматически проставлять тэги на фотографиях или генерировать текстовые описания.
Подумал минут 5, и так много разных идей для проектов, которые можно посторить поверх хорошего API для распознавания картинок приходит в голову (всякие аналитики для оффлайн ритейла, монниторинги состояния производства, подсчеты болтов на конвеере), но почти все натыкается на ограничения.
И вот обидно же. Белорусской фирме сейчас надо пиарить не приложение с подсчётом машин, а с подсчётом людей в толпе. Чтобы считать размер митингов. Тогда могли бы сколько угодно кривых сравнений делать.
Сдаётся мне, что они так и сделали, посмотрели на результаты, погрустнели, и решили, что продать подсчёт машин будет легче.
Я, вот, с камер кинул им пару картинок в API. Но результатом был весьма разочарован. Датасет еще не айс.
Не помню, в гугл\майрософт стандартная база моделей, или возможность выбора модели для распознования?
к примеру, тотже openCV, который отсутствует в сравнении (догадываюсь почему), может выдавать результат разной точности, смотря какая модель, смотря какой метод распознования и т.п.
А также сильно подозреваю, что модели зависимы от масштаба объекта. По-хорошему, к каждой модели бы прикладывать, на какой дальности и в каких ракурсах там были машины при тренировке.
Общие системы справились хуже, чем специально обученная. Внезапно!

ЗЫ Картинка взята из интернета и авторство неизвестно.
У нас длиннее всех! *
* — когда все остальные в холодной воде
p.s. простите, не смог удержаться — накрыло воспоминаниями молодости
Источник: https://pjreddie.com/darknet/yolo/
Т.е. — система распознования от YOLO, ваше — оформление и тренировка на ваших подборках?
фреймворк YOLOv3 Darknet. Эксперименты показали, что именно он создает меньше всего проблем в реализации.
А можно немного подробнее о проблемах реализации? почему именно YOLO?
Кстати, аугментацию 3d графикой не думали применить? На первый взгляд, ваши кейсы очень хорошо генерируются

Разве это не крайне странно, что нейросеть распознала часть диска, но не целое?



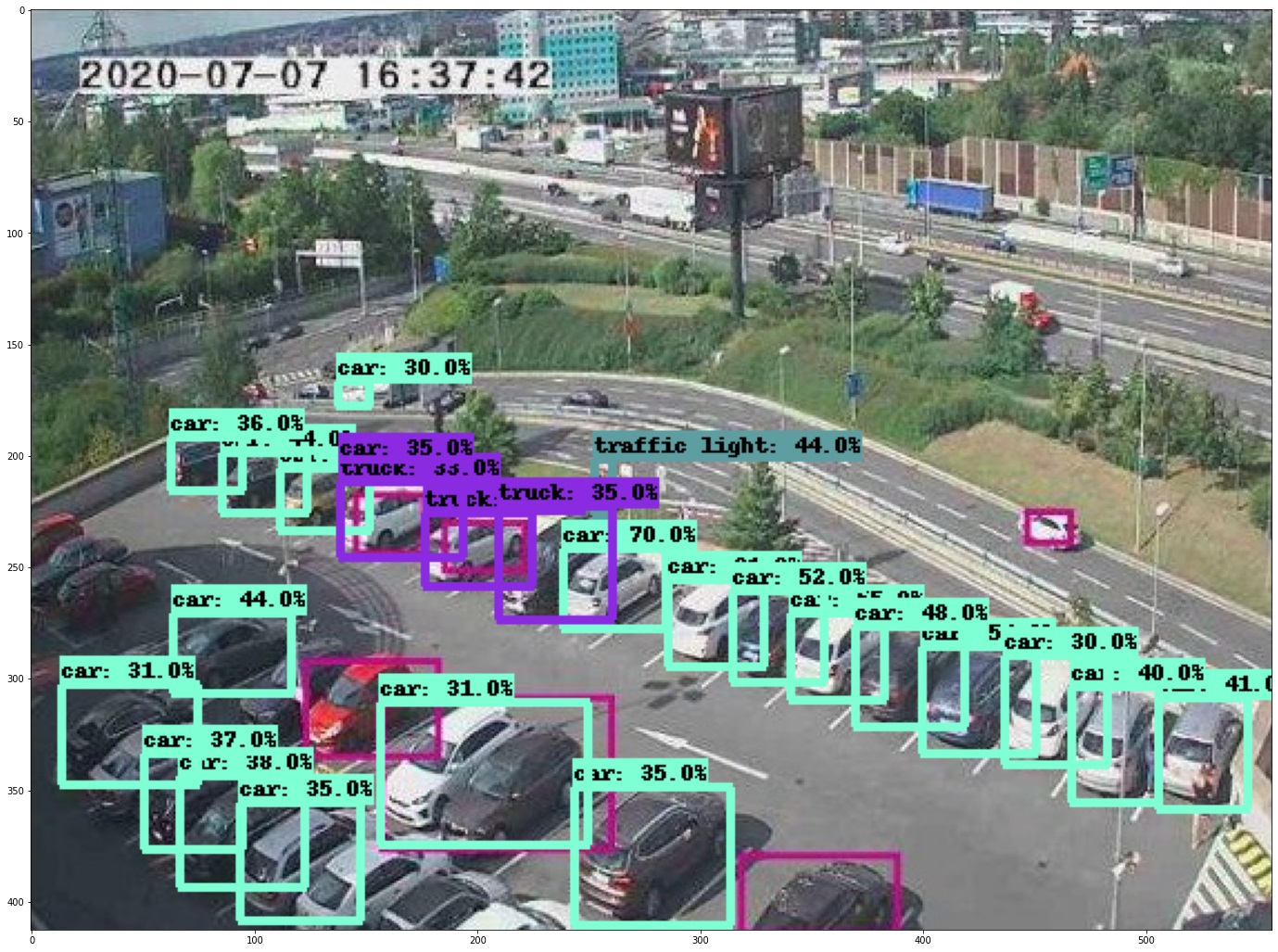
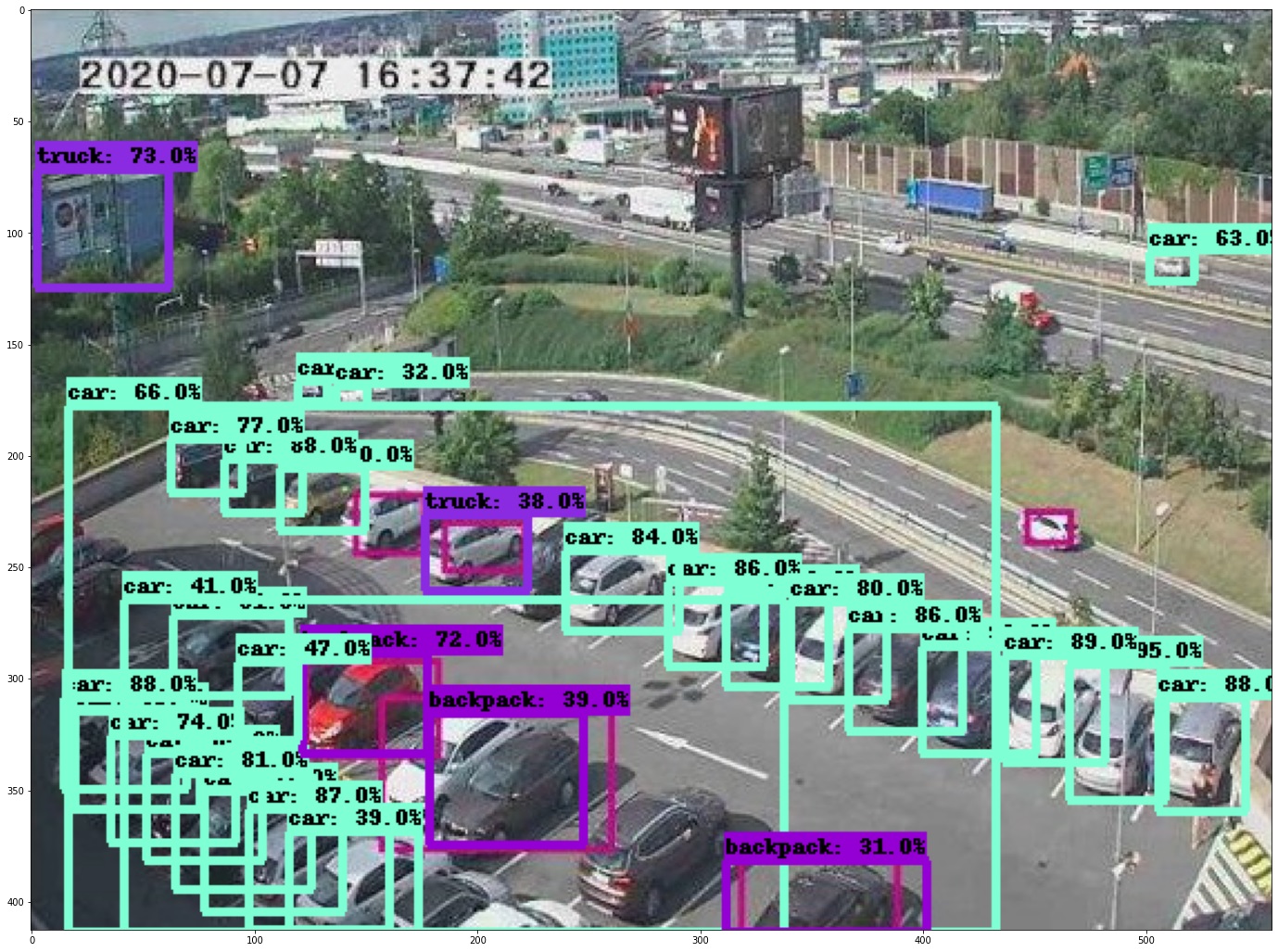
Какие нейросети используются в "Google AI" и "Microsoft Computer Vision"? Потому что вот прямо сейчас взял довольно старую разработку от Google "EfficientDet D7" с COCO 2017 (80 категорий объектов) и она без всякого дообучения выдает сравнимое качество распознавания:

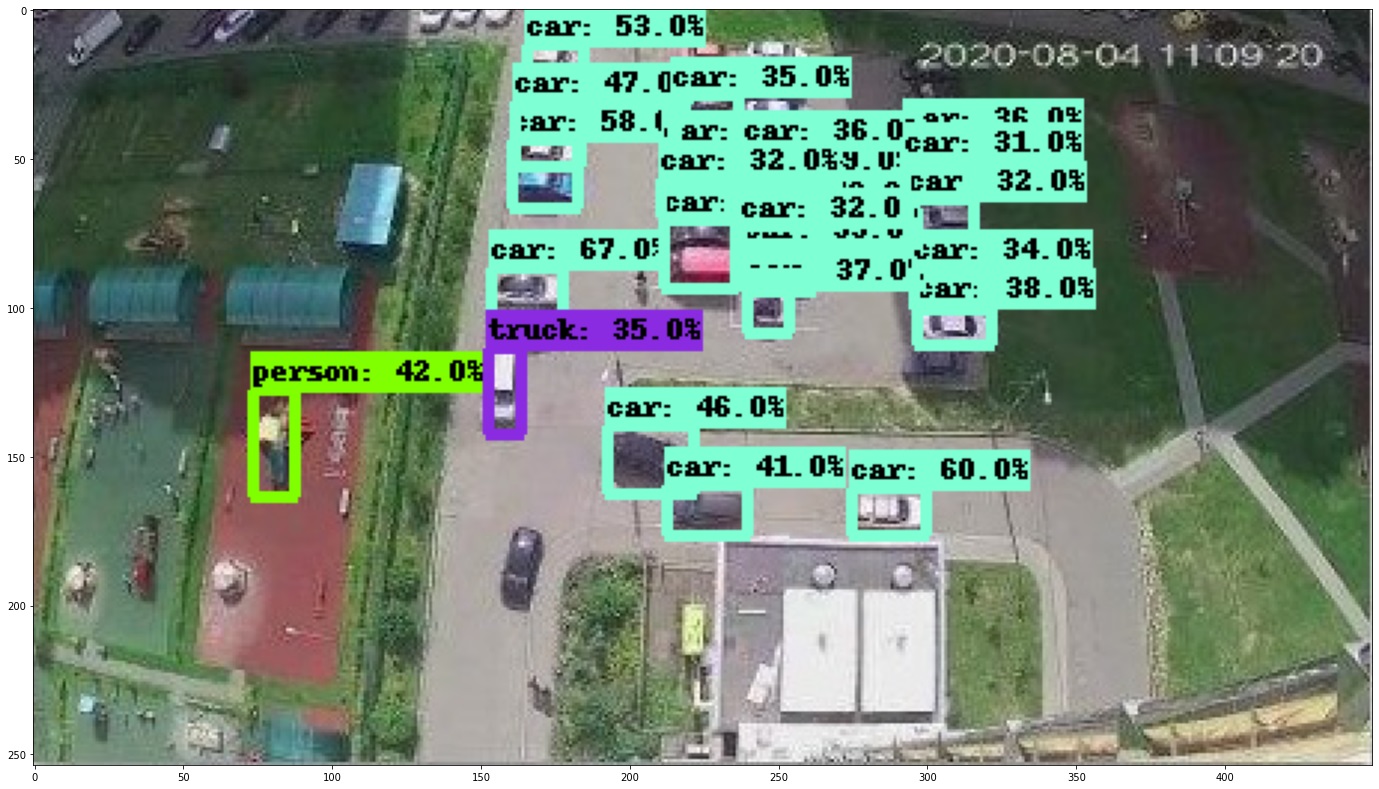
Другие более менее современные нейросети тоже не сильно уступают: CenterNet: https://habrastorage.org/webt/xq/eb/ke/xqebkeq1owrwjpm2jytlfhi86lm.jpeg, Faster R-CNN: https://habrastorage.org/webt/1g/rs/96/1grs96te3un9p5n_diajm5g27na.jpeg. Не стал вставлять картинки, чтобы не загромождать комментарий.
{kind=link}
{kind=link}
Так как исходных картинок в статье нет, то пришлось вырезать прямо из скриншотов в этой статье. Первая (https://habrastorage.org/webt/vy/ya/sf/vyyasfjdaozweeurigu_gdwszco.jpeg) получилась всего 557х413 пикселей и вторая (https://habrastorage.org/webt/2d/3f/ny/2d3fnyuny7qj97ohz_jctgrnvgq.jpeg) 450х254 пикселей. Хотя в статье видно, что оригинальные картинки были как минимум в два раза больше по разрешению. Думаю, с оригиналами получилось бы еще лучше.
{kind=link}
{kind=link}
Но использовать YOLO3 и дообучать под свой датасет это правильно, конечно. Хотя уже вышел YOLO4 (и какой-то левый YOLO5, но на самом деле это примерно как YOLO4). Кроме того, для вида сверху (без перспективы) есть сетки с Oriented Box и соответствующие датасеты/соревнования (такие как DOTA, пример сетки ), которые не чувствительны к поворотам.
P.S. Эти примеры запустил в браузере через этот Google Colab, ссылка для желающих повторить: https://colab.research.google.com/github/tensorflow/hub/blob/master/examples/colab/tf2_object_detection.ipynb. А здесь список нейросетей в нем (выбираются из списка в самом Colab ноутбуке): https://tfhub.dev/tensorflow/collections/object_detection/1
Вы сейчас их сервис сделали бессмысленным. Осталось только геометки и карту прикрутить, что не трудно. Теперь все то же сможет сделать любая домохозяйка. А там целый стартап. Чтож вы так, а?
Нет, не бессмысленным. YOLO3 одна из лучших нейросетей и идёт вровень с десятком других современных архитектур. Так что ее выбор полностью оправдан. Просто удивили такие странные результаты сравнений в статье, такого не должно быть.
Новые архитектуры регулярно появляются, но там нет такой большой разницы, улучшения максимум на единицы процентов, а не в разы. А основная и самая трудоемкая работа для практического применения всегда заключается в дообучении какой-нибудь современной нейросети под свой датасет. Так что с этим в статье все нормально, стартап имеет право на существование. Там ведь ещё огромная сложность с выбором минимального score, по которому отсекать результаты. Для этого тоже нужен довольно большой свой датасет. Чтобы по нему выбрать что важнее — детектировать все объекты, но при этом будет много ложных срабатываний, или надёжное срабатывание без ложных целей, но при этом часть объектов будет пропущена. Кроме того, простая замена 80 категорий на 1-2 (как, видимо, сделали в статье) резко уменьшает размер нейоросети и ускоряет ее работу. Если не считать провокационного заголовка и некорректного сравнения с какими-то жутко устаревшими сетями (подозреваю, там mobilenet какой-нибудь, возможно даже первый, если в cloud сервисе крутится на CPU), то ребята все сделали правильно. Результат тоже очень хорош, лучшего на текущем этапе развития нейросетей особо и не добиться.
Белорусский AI сервис опередил Google и Microsoft AI в распознавании автомобилей