Приветствую, это текстовая версия моего доклада на JPoint-2021. Как обычно я сделал упор на случаи из жизни и на повседневные вещи, используемые каждым разработчиком. Под кат приглашаются интересующиеся производительностью и им сочувствующие.
Что такое нюанс?
Если верить Большому энциклопедическому словарю, то нюанс (франц. nuance) - это оттенок, тонкое различие, едва заметный переход (в цвете, мысли, звуке и т. п.). Очень пошлое (и вместе с тем очень верное) объяснение определения дано в виде анекдота тут.
Откуда вообще берутся нюансы?
Действительно: почему отнюдь не всегда глядя на код мы можем с полной уверенностью сделать вывод о том, насколько быстро он будет работать? Краткий ответ: потому что Java многослойна. Развёрнутый ответ: потому что проделывая путь от исходного кода до машинных команд ваша программа может претерпеть настолько существенные изменения, что её поведение будет отличаться от ожидаемого. В общих чертах исполнение программы выглядит так:
компилятор превращает исходный код в байт-код
байт-код исполняется виртуальной машиной
оптимизирующий компилятор (многоуровневый) меняет код на лету по мере его исполнения
процессор исполняет инструкции, полученные от компилятора
Нюансы существуют на каждом из этапов, где-то они более очевидны, где-то неочевидны вовсе.
Какие бывают нюансы?
нюансы реализации/алгоритма
нюансы исполнения
нюансы измерения
Начнём, как это ни странно, с конца.
Нюансы измерения
Все знают, что неправильно написанный бенчмарк даёт совершенно неверные результаты. Из этого наблюдения часто делается ложный и, по моему мнению, опасный вывод: если бенчмарк написан правильно, то его результаты можно использовать как неопровержимое доказательство очевидной полезности тех или иных изменений в коде.
Предположим, мы хотим узнать, какой из способов перебора массива будет быстрее:
byte[] bunn;
for (int i = 0; i < bunn.length; i++) { // перебор "по старому стилю"
use(bunn[i]);
}
for (byte bunny : bunn) { // подсластим синтаксис
use(bunny);
}Казалось бы:

Оба способа делают одно и то же, тем более, что for-eachявляется по сути синтаксическим сахаром для for-i. Но есть нюанс :)
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class LoopyBenchmarks {
@Param({ "32", "1024", "32768" })
int size;
byte[] bunn;
@Setup
public void prepare() {
bunn = new byte[size];
}
@Benchmark
public void goodOldLoop(Blackhole fox) {
for (int y = 0; y < bunn.length; y++) {
fox.consume(bunn[y]);
}
}
@Benchmark
public void sweetLoop(Blackhole fox) {
for (byte bunny : bunn) {
fox.consume(bunny);
}
}
}Этот мопед не мой, ниже я дам ссылку на автора, а пока давайте посмотрим на прогон:
Benchmark (size) Score Error Units
goodOldLoop 32 46.630 0.097 ns/op
goodOldLoop 1024 1199.338 0.705 ns/op
goodOldLoop 32768 37813.600 56.081 ns/op
sweetLoop 32 19.304 0.010 ns/op
sweetLoop 1024 475.141 1.227 ns/op
sweetLoop 32768 14295.800 36.071 ns/opВпечатляет, правда?
Использование синтаксического сахара дало почти двукратный прирост производительности на пустом месте! Нужно срочно переписывать код своего проекта!
Так думает начинающий разработчик и энтузиаст производительности (так когда-то думал и я). Более опытные не торопятся с выводами, ведь бенчмарк бенчмарку рознь. Быть может в наши исследования вкралась методологическая ошибка? К счастью для нас, создатели JMH описали примеры на все случаи жизни, среди которых находим нужный:
@Fork(3)
@State(Scope.Thread)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class JMHSample_34_SafeLooping {
@Param({"1", "10", "100", "1000"})
int size;
int[] xs;
@Setup
public void setup() {
xs = new int[size];
for (int c = 0; c < size; c++) {
xs[c] = c;
}
}
@Benchmark
public void measureRight_1(Blackhole bh) {
for (int x : xs) {
bh.consume(work(x));
}
}
static final int BASE = 42;
static int work(int x) {
return BASE + x;
}
}Получается, всё сделано как в лучших домах Потсдама и данные сами по себе верны, но из них сделан неправильный вывод. А правильный вывод сделал Ницан Вакарт в статье The volatile read surprise:
// старая версия класса org.openjdk.jmh.infra.Blackhole (до JMH 1.3)
public volatile byte b1, b2;
public volatile BlackholeL2 nullBait = null;
/**
* Consume object. This call provides a side effect
* preventing JIT to eliminate dependent computations.
*
* @param b object to consume.
*/
public final void consume(byte b) {
if (b == b1 & b == b2) {
// SHOULD NEVER HAPPEN
nullBait.b1 = b; // implicit null pointer exception
}
}Внутри метода Blackhole::consume происходит два чтения из волатильных полей, которые создают эффект чёрного ящика, не давая компилятору выбросить источник аргумента b, и вынуждая исполнение отказаться от оптимизации доступа к полю bunn и каждый раз делать честное чтение из памяти, а не из кэша.
Поэтому простое считывание поля в переменную и проход по ней волшебным образом выравнивают показатели:
@Benchmark
public void goodOldLoopReturns(Blackhole fox) {
byte[] sunn = bunn; // make a local copy of the field
for (int y = 0; y < sunn.length; y++) {
fox.consume(sunn[y]);
}
}Метод goodOldLoopReturnsработает так же быстро, как и for-each
Benchmark (size) Score Error Units
goodOldLoopReturns 32 19.306 0.045 ns/op
goodOldLoopReturns 1024 476.493 1.190 ns/op
goodOldLoopReturns 32768 14292.286 16.046 ns/op
sweetLoop 32 19.304 0.010 ns/op
sweetLoop 1024 475.141 1.227 ns/op
sweetLoop 32768 14295.800 36.071 ns/opТаким образом, for-each выигрывал лишь из-за неявной записи поля в переменную:
@Benchmark
public void sweetLoop(Blackhole fox) {
for (byte bunny : bunn) {
fox.consume(bunny);
}
}после сборки превращается в
@Benchmark
public void sweetLoop(Blackhole fox) {
byte[] var2 = this.bunn; // <---
int var3 = var2.length;
for(int var4 = 0; var4 < var3; ++var4) {
byte bunny = var2[var4];
fox.consume(bunny);
}
}Мораль сей басни выражена в послесловии к выводу каждого бенчмарка:
REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial experiments, perform baseline and negative tests that provide experimental control, make sure the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts. Do not assume the numbers tell you what you want them to tell.
На языке родных осин это означает, что правильное толкование полученных данных столь же важно, как и написание правильного бенчмарка. Цифры сами по себе ничто, понимание - всё.
Небольшое послесловие к Blackhole
Начиная с версии 1.3 и до 1.28 класс Blackhole был переписан, чтобы уменьшить вредное воздействие волатильного доступа:
public volatile byte b1; // только b1 объявлен как volatile
public byte b2;
public final void consume(byte b) {
byte b1 = this.b1;
byte b2 = this.b2;
if (b == b1 & b == b2) {
nullBait.b1 = b;
}
}Теперь разница стала заметно скромнее:
(size) Score Error Units
goodOldLoop 32 70.307 ± 0.752 ns/op
goodOldLoop 1024 2239.560 ± 21.611 ns/op
goodOldLoop 32768 70890.224 ± 3475.436 ns/op
sweetLoop 32 103.163 ± 39.564 ns/op
sweetLoop 1024 1812.092 ± 4.234 ns/op
sweetLoop 32768 57918.608 ± 249.921 ns/op
goodOldLoopReturns 32 59.757 ± 0.748 ns/op
goodOldLoopReturns 1024 1843.383 ± 37.246 ns/op
goodOldLoopReturns 32768 57704.539 ± 217.073 ns/opТем не менее, это ещё не предел (в пределе разницы быть вообще не должно). Начиная с версии 1.29 разработчики добавили возможность реализации чёрного ящика с помощью компиляторных хитростей:
private static final boolean COMPILER_BLACKHOLE = Boolean.getBoolean("compilerBlackholesEnabled");
public final void consume(byte b) {
if (COMPILER_BLACKHOLE) {
consumeCompiler(b);
} else {
consumeFull(b); // старый подход с волатильностью
}
}
// Compiler blackholes block: let compilers figure out how to deal with it.
private static void consumeCompiler(byte v) {}
// Full blackholes block: confuse compilers to get blackholing effects.
// See implementation comments at the top to understand what this code is doing.
private void consumeFull(byte b) {
byte b1 = this.b1; // volatile read
byte b2 = this.b2;
if ((b ^ b1) == (b ^ b2)) {
nullBait.b1 = b; // implicit null pointer exception
}
}Критик наверняка скажет: "Но это выдуманный пример!". На деле, не такой уж и выдуманный:
byte[] bunn;
@Benchmark
public void goodOldLoop(Blackhole fox) {
for (int y = 0; y < bunn.length; y++) {
fox.consume(bunn[y]);
}
}
//-------------------
E[] elements;
@Override
public void forEach(Consumer<E> consumer) {
for (int i = 0; i < elements.length; i++) {
consumer.accept(elements[i]);
}
}Да-да, наш метод как две капли воды похож на реализацию Iterable.forEach(Consumer), который есть у любой коллекции. Выше мы убедились, что в 99 случаях из 100 способ перебора не важен, но на всякий сотый случай все коллекции на основе массива используют либо for-each, либо выполняют явную синхронизацию на стеке:
j.u.ArrayList
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
final Object[] es = elementData;
final int size = this.size;
for (int i = 0; modCount == expectedModCount && i < size; i++)
action.accept(elementAt(es, i));
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}j.u.Arrays$ArrayList
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
for (E e : a) {
action.accept(e);
}
}j.u.c.CopyOnWriteArrayList
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
for (Object x : getArray()) {
@SuppressWarnings("unchecked") E e = (E) x;
action.accept(e);
}
}j.u.ArrayDeque
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final Object[] es = elements;
for (int i = head, end = tail, to = (i <= end) ? end : es.length;
; i = 0, to = end) {
for (; i < to; i++)
action.accept(elementAt(es, i));
if (to == end) {
if (end != tail) throw new ConcurrentModificationException();
break;
}
}
}На этом примере хорошо виден круговорот очевидностей и нюансов в природе:
бенчмарк показал очевидную разницу между for-i и for-each
нюанс: причина в инфраструктуре JMH
очевидно, что в 99 случаях из 100 способ перебора массива не влияет на производительность
нюанс: есть редкие случаи, когда всё же влияет
Нюансы исполнения
Рассмотрим метод o.s.util.StringUtils.uriDecode(String, Charset). Он нужен для превращения кодированной ссылки вроде
https%3A%2F%2Fru.wikipedia.org%2Fwiki%2F%D0%9E%D1%80%D0%B3%D0%B0%D0%BD%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F_%D0%9E%D0%B1%D1%8A%D0%B5%D0%B4%D0%B8%D0%BD%D1%91%D0%BD%D0%BD%D1%8B%D1%85_%D0%9D%D0%B0%D1%86%D0%B8%D0%B9в более удобочитаемую
https://ru.wikipedia.org/wiki/Организация_Объединённых_НацийМетод довольно громоздкий, а нас интересует последняя строка:
public static String uriDecode(String source, Charset charset) {
int length = source.length();
if (length == 0) {
return source;
}
Assert.notNull(charset, "Charset must not be null");
ByteArrayOutputStream bos = new ByteArrayOutputStream(length);
boolean changed = false;
for (int i = 0; i < length; i++) {
// ...
}
return changed ? new String(bos.toByteArray(), charset) : source;
}А в ней - использование метода ByteArrayOutputStream.toByteArray():
return changed ? new String(bos.toByteArray(), charset) : source;Этот метод возвращает копию массива, хранящегося внутри ByteArrayOutputStream:
public synchronized byte[] toByteArray() {
return Arrays.copyOf(this.buf, this.count);
}Всё логично: строка создаётся из копии массива. Теперь взглянем на соседний метод ByteArrayOutputStream.toString(String charsetName):
public synchronized String toString(String charsetName) throws Exception {
return new String(buf, 0, count, charsetName);
}Он делает то же самое, что и new String(bos.toByteArray(), charset), только без создания промежуточной копии. Поскольку и ByteArrayOutputStream.toString(), и ByteArrayOutputStream.toByteArray() синхронизированы, а внутри строки в любом случае создаётся новый byte[], то выражение new String(bos.toByteArray(), charset) можно заменить выражением bos.toString(charset), обработав при этом сопутствующее исключение.
Здравый смысл подсказывают, что избавившись от создания промежуточного массива мы получим прирост производительности. Бенчмарк подтверждает догадку:
(length) Score Error Units
newString 0 66.084 ± 2.121 ns/op
newString 10 53.232 ± 1.569 ns/op
newString 100 96.067 ± 1.466 ns/op
newString 1000 667.188 ± 33.071 ns/op
toString 0 44.601 ± 0.656 ns/op
toString 10 45.151 ± 0.397 ns/op
toString 100 77.924 ± 0.645 ns/op
toString 1000 511.302 ± 1.730 ns/op
newString:·gc.alloc.rate.norm 0 96.000 ± 0.001 B/op
newString:·gc.alloc.rate.norm 10 136.000 ± 0.001 B/op
newString:·gc.alloc.rate.norm 100 400.000 ± 0.001 B/op
newString:·gc.alloc.rate.norm 1000 3096.001 ± 0.001 B/op
toString:·gc.alloc.rate.norm 0 40.000 ± 0.001 B/op
toString:·gc.alloc.rate.norm 10 64.000 ± 0.001 B/op
toString:·gc.alloc.rate.norm 100 240.000 ± 0.001 B/op
toString:·gc.alloc.rate.norm 1000 2040.001 ± 0.001 B/opНаш расчёт оправдался: прирост есть как по времени, так и по памяти. Теперь проверим, улучшилась ли производительность StringUtils.uriDecode(String, Charset):
Score Error Units
before
uriDecode 766.285 ± 22.110 ns/op
uriDecode:·gc.alloc.rate.norm 816.001 ± 0.001 B/op
after
uriDecode 720.208 ± 5.968 ns/op
uriDecode:·gc.alloc.rate.norm 712.001 ± 0.001 B/opВремя исполнения уменьшилось на 6%, а потребление памяти - на 12,75%. Вроде бы мелочь, но приятно, тем более что замену можно автоматизировать.
Где раскодирование, там и кодирование
Этот же подход можно применить к прочим подобным классам, например, к java.io.CharArrayWriter:
public char[] toCharArray() {
synchronized(this.lock) {
return Arrays.copyOf(this.buf, this.count);
}
}
public String toString() {
synchronized(this.lock) {
return new String(this.buf, 0, this.count);
}
}Проверим, насколько метод toString() выигрывает у промежуточного массива:
(length) Score Error Units
toCharArray 5 19.767 ± 0.134 ns/op
toCharArray 10 18.664 ± 0.128 ns/op
toCharArray 50 21.823 ± 0.264 ns/op
toCharArray 100 29.041 ± 0.145 ns/op
toCharArray 1000 250.129 ± 2.446 ns/op
toString 5 15.361 ± 0.752 ns/op
toString 10 14.472 ± 0.251 ns/op
toString 50 16.048 ± 0.102 ns/op
toString 100 19.245 ± 0.137 ns/op
toString 1000 82.624 ± 1.824 ns/op
toCharArray:·gc.alloc.rate.norm 5 80.000 ± 0.001 B/op
toCharArray:·gc.alloc.rate.norm 10 96.000 ± 0.001 B/op
toCharArray:·gc.alloc.rate.norm 50 216.000 ± 0.001 B/op
toCharArray:·gc.alloc.rate.norm 100 360.000 ± 0.001 B/op
toCharArray:·gc.alloc.rate.norm 1000 3056.000 ± 0.001 B/op
toString:·gc.alloc.rate.norm 5 48.000 ± 0.001 B/op
toString:·gc.alloc.rate.norm 10 56.000 ± 0.001 B/op
toString:·gc.alloc.rate.norm 50 96.000 ± 0.001 B/op
toString:·gc.alloc.rate.norm 100 144.000 ± 0.001 B/op
toString:·gc.alloc.rate.norm 1000 1040.000 ± 0.001 B/opВ JDK есть даже подопытный компонент - java.net.URLEncoder, использующий CharArrayWriter в методе encode() схожим образом:
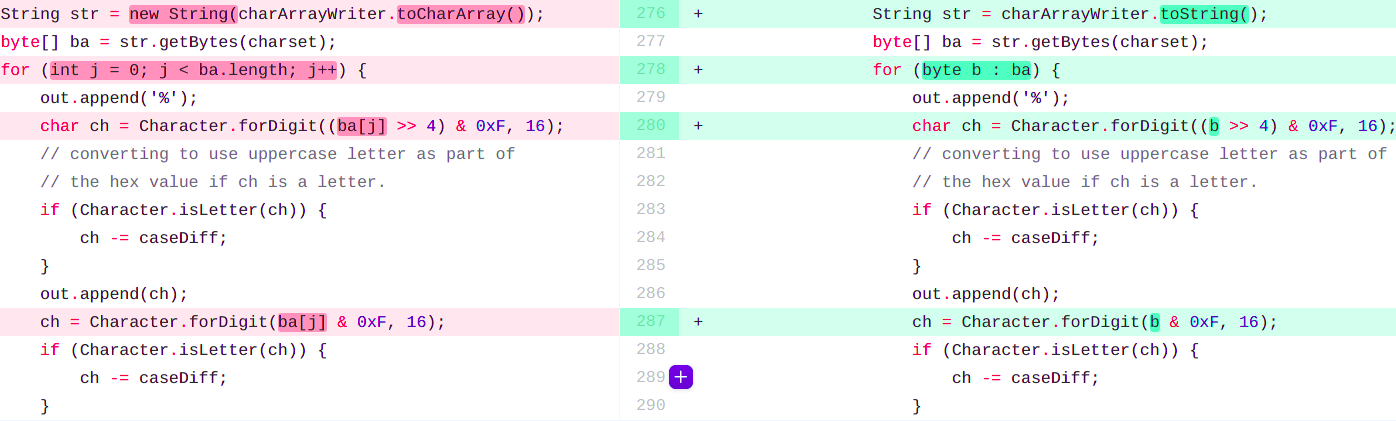
String str = new String(charArrayWriter.toCharArray());Получается, здесь возможна аналогичная замена:
String str = charArrayWriter.toString();Соберём JDK и измерим производительность:
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Fork(jvmArgsAppend = {"-Xms2g", "-Xmx2g"})
public class UrlEncoderBenchmark {
Charset charset = Charset.defaultCharset();
String utf8Url = "https://ru.wikipedia.org/wiki/Организация_Объединённых_Наций";
@Benchmark
public String encodeUtf8() {
return URLEncoder.encode(utf8Url, charset);
}
}И вдруг:
Score Error Units
before 1108.668 ± 6.226 ns/op
after 1454.647 ± 6.067 ns/op <-- !
before:·gc.alloc.rate.norm 1712.202 ± 0.003 B/op
after:·gc.alloc.rate.norm 1528.219 ± 0.007 B/opТеперь мы потребляем меньше памяти, но, время выполнения выросло почти на четверть! Почему в одном случае всё отработало хорошо, а в похожем как две капли воды мы не только не получили прироста, но и наоборот - производительность ухудшилась? С этим вопросом я пошел в hotspot-compiler-dev, т. к. был уверен, что речь идёт об ошибке оптимизирующего компилятора. Так выглядит лог вклеивания до моих изменений:
@ 186 j.i.CharArrayWriter::flush (1 bytes) inline (hot)
!m @ 195 j.i.CharArrayWriter::toCharArray (26 bytes) inline (hot)
@ 15 j.u.Arrays::copyOf (19 bytes) inline (hot)
@ 11 j.l.Math::min (11 bytes) (intrinsic)
@ 14 j.l.System::arraycopy (0 bytes) (intrinsic)
@ 198 j.l.String::<init> (10 bytes) inline (hot)
@ 6 j.l.String::<init> (74 bytes) inline (hot)
@ 1 j.l.Object::<init> (1 bytes) inline (hot)
@ 36 j.l.StringUTF16::compress (20 bytes) inline (hot)
@ 9 j.l.StringUTF16::compress (50 bytes) (intrinsic)
@ 67 j.l.StringUTF16::toBytes (34 bytes) (intrinsic)А таким он стал после (внимание на вторую и седьмую строки):
@ 186 j.i.CharArrayWriter::flush (1 bytes) inline (hot)
!m @ 191 j.i.CharArrayWriter::toString (31 bytes) already compiled into a big method
@ 199 j.l.String::getBytes (25 bytes) inline (hot)
@ 14 j.l.String::coder (15 bytes) inline (hot)
! @ 21 j.l.StringCoding::encode (324 bytes) inline (hot)
@ 10 j.l.StringCoding::encodeUTF8 (132 bytes) inline (hot)
@ 7 j.l.StringCoding::encodeUTF8_UTF16 (369 bytes) hot method too big
@ 15 j.l.StringCoding::hasNegatives (25 bytes) (intrinsic)
@ 24 j.u.Arrays::copyOf (19 bytes) inline (hot)
@ 11 j.l.Math::min (11 bytes) (intrinsic)
@ 14 j.l.System::arraycopy (0 bytes) (intrinsic)
Мы видим, что CharArrayWriter::toString и StringCoding::encodeUTF8_UTF16 не были встроены в точку вызова из-за своего размера (хотя оба скомпилированы полностью). Также в логе компиляции появилась такая запись (внимание на последнюю строку):
<method id="1166" holder="1154" name="toString" return="1032" flags="1" bytes="31" compile_id="1062" compiler="c2" level="4" iicount="11163">
<dependency type="unique_concrete_method" ctxk="1154" x="1166">
<call method="1166" count="75859" prof_factor="1,000000" inline="1">
<inline_fail reason="already compiled into a big method">Таким образом, в скомпилированном коде появилась дыра, где нам нужно сделать честный вызов метода, что ломает многие оптимизации, ведь компилятор не знает, что нас ждёт внутри чёрного ящика (точно так же Blackhole ломал оптимизации в первом примере).
Увеличение объёма кода вызвано использованием другого конструктора:
// вызывается при использовании копии массива
public String(char value[]) {
this(value, 0, value.length, null);
}
// вызывается при использовании CharArrayWriter.toString()
public String(char[] value, int offset, int count) {
this(value, offset, count, rangeCheck(value, offset, count));
}
// здесь выполняется основная работа
String(char[] value, int off, int len, Void sig) {...}Очевидно, что преобразование char[]-> byte[] выполняется внутри последнего конструктора, а единственная разница заключается в проверке границ в скромном методе rangeCheck(char[], int, int):
private static Void rangeCheck(char[] value, int offset, int count) {
checkBoundsOffCount(offset, count, value.length);
return null;
}
static void checkBoundsOffCount(int offset, int count, int length) {
if (offset < 0 || count < 0 || offset > length - count) {
throw new StringIndexOutOfBoundsException(
"offset " + offset + ", count " + count + ", length " + length);
}
}но этого оказалось достаточно. Выяснилось, что
C2 uses a bunch of of heuristics. Here, it's detected that
CharArrayWriter::toStringis large and has already been compiled so there's no sense inlining another copy of it. This isn't necessarily true, but it's a good guess. Try playing withInlineSmallCodestart with = 1000, and increases it from there to see if it helps.
Определение -XX:InlineSmallCode звучит так:
Inline a previously compiled method only if its generated native code size is less than this. The default value varies with the platform on which the JVM is running.
Более развёрнутое (и более простое, как мне кажется) определение дано в статье "Java HotSpot JIT компилятор — устройство, мониторинг и настройка (часть 2)", которая категорически рекомендуется к прочтению:
Встраиванию не подлежат скомпилированные на последнем уровне методы, занимающие более 1000 байт при выключенной многоуровневой компиляции и 2000 байт при включенной
Несмотря на всё вышесказанное я создал ПР и протолкнул свои изменения:
Сделать это мне удалось благодаря другому ПР, на первый взгляд никак не связанному с моим: 8254913: Increase InlineSmallCode default from 2000 to 2500 for x64.
После него удалось получить желаемый прирост:
original 1166.3 ns/op
patched 1058.8 ns/opВозникает закономерный вопрос: а почему бы не вклеить вообще всё и получить цельный кусок ассемблера? Ответ:
If you never share code you ends up with several giga bytes of assembly codes which destroy your perf because you start to have a lot of cache miss on the instructions. So there is a trade off between a theoritical fully inlined program and a never inlined program.
Действительно, давайте представим себе полностью вклеенную программу: у нас есть цельный кусок ассемблера. Получается, что если раньше мы использовали повторно тело какого-нибудь String.isEmpty(), то теперь тело этого метода будет вклеено в каждую точку обращения к нему. В этом случает объём скомпилированного кода из-за отсутствия переиспользования вырастет лавинообразно. Поместится ли такой кусок в кэш целиком? Вряд ли, что приведёт к промахам при обращении к кэшу (cache-miss), а это будет бить по производительности, ведь процессору будет необходимо постоянно подгружать нужный код из ОЗУ в кэш.
Ввиду сказанного выше разработчики ВМ и компилятора пришли к компромиссу между встраиванием и повторным использованием.
Вывод для разработчика:
улучшения "под копирку" работают не всегда
после улучшения всегда проверяйте конечный сценарий
Нюансы реализации
Работающие со вводом-выводом знают, что буферизация - это эффективное средство улучшить производительность ведь чтение и/или запись отдельных байтов стоят дорого:
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Fork(jvmArgsAppend = {"-Xms2g", "-Xmx2g"})
public class BufferedReaderBenchmark {
private File file;
@Setup
public void setUp() throws Exception {
String path = "tsypanov/strings/buffered/BufferReaderBenchmark.class";
URL resource = getClass()
.getClassLoader()
.getResource(path);
file = new File(resource.getFile());
}
@Benchmark
public void readFromFile(Blackhole bh) throws Exception {
int value;
try (var is = new FileInputStream(file)) {
while ((value = is.read()) != -1) {
bh.consume(value);
}
}
}
}
Метод readFromFile()считывает содержимое файла байт за байтом:
Benchmark Score Error Units
readFromFile 2561.488 ± 16.869 us/op
readFromFile:·gc.alloc.rate.norm 148.550 ± 2.144 B/opПопробуем буферизацию:
@Benchmark
public void readBufferedFromFile(Blackhole bh) throws Exception {
int value;
try (var is = new BufferedInputStream(new FileInputStream(file))) {
while ((value = is.read()) != -1) {
bh.consume(value);
}
}
}Отлично, считывание ускорилось в скромных 20 раз:
Benchmark Score Error Units
readFromFile 2561.488 ± 16.869 us/op
readBufferedFromFile 92.418 ± 3.145 us/op
readFromFile:·gc.alloc.rate.norm 148.550 ± 2.144 B/op
readBufferedFromFile:·gc.alloc.rate.norm 8393.668 ± 0.264 B/opЭто стало возможным за счёт использования промежуточного массива, куда считывается сразу пачка данных, сильно удешевляя тем самым чтение отдельного байта. Разумеется, бесплатно ничего не достаётся, о чём свидетельствует взрывной рост потребления памяти. И всё же общая производительность существенно улучшается, что показывает прогон с измерением пропускной способности:
Benchmark Score Error Units
readFromFile 388.860 ± 0.960 ops/s
readBufferedFromFile 4762.997 ± 609.229 ops/sДаже выросшее потребление памяти (и соответственно, нагрузка на GC) не мешает буферизированному чтению более чем на порядок превосходить обычное.
Вроде всё просто и очевидно. Где же нюанс? А нюанс возникает, когда буферизацией начинают злоупотреблять:
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Fork(jvmArgsAppend = {"-Xms2g", "-Xmx2g"})
public class BufferedReaderBenchmark {
private URL url;
@Setup
public void setUp() throws Exception {
String path = "tsypanov/strings/buffered/BufferReaderBenchmark.class";
URL resource = getClass()
.getClassLoader()
.getResource(path);
url = resource.toURI().toURL();
}
@Benchmark
public void readFromURL(Blackhole bh) throws Exception {
int value;
try (var is = url.openStream()) {
while ((value = is.read()) != -1) {
bh.consume(value);
}
}
}
@Benchmark
public void readBufferedFromURL(Blackhole bh) throws Exception {
int value;
try (var is = new BufferedInputStream(url.openStream())) {
while ((value = is.read()) != -1) {
bh.consume(value);
}
}
}
}Этот бенчмарк полностью повторяет предыдущий за одним исключением: здесь читаем не из файла напрямую, а из ссылки на него. Получается так:
Benchmark Score Error Units
readFromURL 93.332 ± 3.190 us/op
readBufferedFromURL 93.802 ± 7.419 us/op
readFromURL:·gc.alloc.rate.norm 8592.120 ± 3.636 B/op
readBufferedFromURL:·gc.alloc.rate.norm 16835.122 ± 0.246 B/opЗдесь буферизация не ускорила чтение, но потребление памяти выросло почти в 2 раза. Причина в реализации FileURLConnection.connect(), который вызывается из FileURLConnection.getInputStream():
public void connect() throws IOException {
if (!connected) {
try {
filename = file.toString();
isDirectory = file.isDirectory();
if (isDirectory) {
//...
} else {
is = new BufferedInputStream(new FileInputStream(filename)); // <-
}
} catch (IOException e) {
throw e;
}
connected = true;
}
}Здесь возвращается уже буферизированный поток чтения, поэтому дополнительное оборачивание приводит к переливанию из пустого в порожнее, что увеличивает потребление памяти и снижает пропускную способность:
Benchmark Score Error Units
readBufferedFromURL 11840.985 ± 37.790 ops/s
readBufferedFromURL:·gc.count 1281.000 counts
readBufferedFromURL:·gc.time 711.000 ms
readFromURL 12106.742 ± 40.567 ops/s
readFromURL:·gc.count 667.000 counts
readFromURL:·gc.time 435.000 msОбратите внимание на существенно выросшее количество сборок мусора и затраченное на них время.
На мой взгляд, это - большая недоработка, корнями уходящая в 1996 год с медленным железом и файловыми системами, из-за чего разработчики JDK решили буферизировать поток ввода из файла по умолчанию. В 2021 году это скорее вредит:
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Fork(jvmArgsAppend = {"-Xms2g", "-Xmx2g"})
public class FileInputStreamBenchmark {
private final String file = "/home/s.tsypanov/.bashrc"; // 4362 байта
//private final String file = "/home/s.tsypanov/IMAG2549.jpg"; // 2,7 МБ
@Benchmark
public Object readAllBytes() throws IOException {
try (var fileInputStream = new FileInputStream(file)) {
return fileInputStream.readAllBytes();
}
}
@Benchmark
public Object readAllBytesBuffered() throws IOException {
try (var in = new FileInputStream(file)) {
return new BufferedInputStream(in).readAllBytes();
}
}
}Этот бенчмарк использует новый метод InputStream.readAllBytes()для считывания всего файла (именно это нужно обычному разработчику в 9 случаях из 10):
Score Error Units
read 5.9 ± 0.03 us/op
readBuffered 7.3 ± 0.01 us/op
read:·gc.alloc.rate.norm 12782.4 ± 3.92 B/op
readBuffered:·gc.alloc.rate.norm 21030.4 ± 3.92 B/opСмотрите, как любопытно получается: при чтении файла из локальной файловой системы буферизация не только не помогает, но и мешает. Попробуем сделать то же для большого (относительно размера буфера) файла (см. закомментированный код выше):
Score Error Units
read 1068.1 ± 19.95 us/op
readBuffered 1068.1 ± 10.99 us/op
read:·gc.alloc.rate.norm 5478584.1 ± 0.17 B/op
readBuffered:·gc.alloc.rate.norm 5486832.1 ± 0.17 B/opЗдесь отрицательное влияние буферизации почти незаметно. Причина замедления в обоих случаях одна и та же: промежуточный буфер внутри BufferedInputStream:
private void fill() throws IOException {
byte[] buffer = getBufIfOpen();
if (markpos < 0)
pos = 0; /* no mark: throw away the buffer */
else if (pos >= buffer.length) /* no room left in buffer */
/* ... */
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos); // <---
if (n > 0)
count = n + pos;
}Метод fill()использует InputStream.read(byte[], int, int)для чтения большой пачки данных, но ровно это же напрямую делает InputStream.readNBytes(int):
public byte[] readNBytes(int len) throws IOException {
//...
int total = 0;
int remaining = len;
int n;
do {
byte[] buf = new byte[Math.min(remaining, DEFAULT_BUFFER_SIZE)];
int nread = 0;
// read to EOF which may read more or less than buffer size
while ((n = read(buf, nread,
Math.min(buf.length - nread, remaining))) > 0) {
nread += n;
remaining -= n;
}
//...
}
//...
return result;
}Мне кажется, что изначально разработчикам вместо явной буферизации (которую теперь уже не выпилить) стоило бы указать в документации, что возвращаемый поток не буферизирован, и при необходимости клиент должен сделать это самостоятельно. Именно это делает Files.newInputStream(Path):
/**
* The stream will not be buffered,
* and is not required to support the mark or reset methods.
*/
public static InputStream newInputStream(Path path, OpenOption... options) {}Грамотные разработчики библиотек тоже указывают наличие/отсутствие буферизации потока ввода/вывода, как это сделано в org.apache.commons.io.IOUtils:
/**
* All the methods in this class that read a stream are buffered internally.
* This means that there is no cause to use a BufferedInputStream
* or BufferedReader. The default buffer size of 4K has been shown
* to be efficient in tests.
*
* Applications can re-use buffers by using the underlying methods directly.
* This may improve performance for applications that need to do a lot of copying.
*/
public class IOUtils {
/**
* This method buffers the input internally, so there is no need
* to use a BufferedInputStream.
*/
List<String> readLines(InputStream input, Charset encoding) {}
}Промежуточный вывод для разработчика
В наличии есть 2 бенчмарка, которые делают одно и то же, но разными способами. Первый бенчмарк неопровержимо доказывает пользу буферизации, второй - столько же неопровержимо доказывает её вред. Какому бенчмарку верить? Оба написаны и работают правильно, а для принятия решения в конкретной ситуации необходимо вникнуть в контекст.
Мне кажется, что привычка буферизировать любой поток ввода-вывода вредна, см.
Извлечение пользы из сакрального знания
Рассмотрим часть кода класса o.s.core.type.classreading.SimpleMetadataReader, использующегося для считывания метаданных загруженных классов в "Спринге":
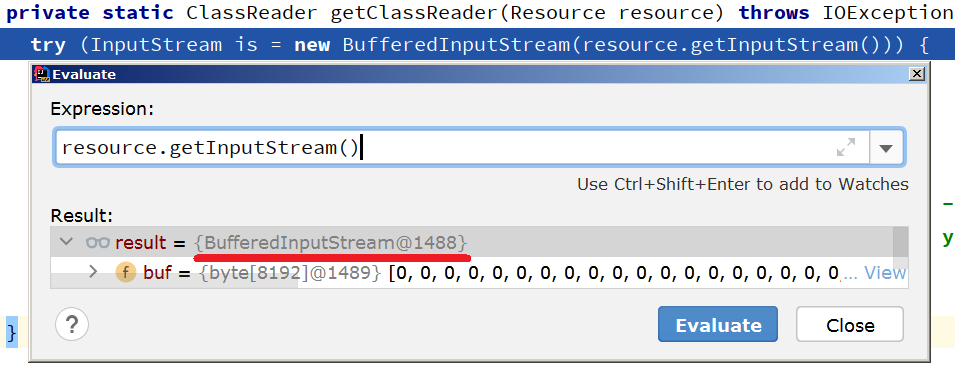
private static ClassReader getClassReader(Resource resource) throws IOException {
try (InputStream is = new BufferedInputStream(resource.getInputStream())) {
try {
return new ClassReader(is);
}
catch (IllegalArgumentException ex) {
throw new NestedIOException("..." + resource, ex);
}
}
}Здесь resource.getInputStream() оборачивается в BufferedInputStream и вы, вероятно, уже догадываетесь, куда ветер дует:
Также буферизированное чтение происходит внутри класса o.s.asm.ClassReader:
static byte[] readStream(InputStream is, boolean close) throws IOException {
if (is == null) {
throw new IOException("Class not found");
}
try (ByteArrayOutputStream outputStream = new ByteArrayOutputStream()) {
byte[] data = new byte[INPUT_STREAM_DATA_CHUNK_SIZE];
int bytesRead;
while ((bytesRead = is.read(data, 0, data.length)) != -1) {
outputStream.write(data, 0, bytesRead);
}
outputStream.flush();
return outputStream.toByteArray();
} finally {
if (close) {
is.close();
}
}
}Вновь делается двойная работа, бесполезность которой позволяет оценить этот бенчмарк:
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Fork(jvmArgsAppend = {"-Xms2g", "-Xmx2g"})
public class MetadataReaderBenchmark {
final MetadataReaderFactory factory = new SimpleMetadataReaderFactory();
@Benchmark
public Object read() throws IOException {
String className = AnnotatedComponent.class.getName();
return factory
.getMetadataReader(className)
.getAnnotationMetadata();
}
// подопытный компонент
@Component("myComp")
@Scope(BeanDefinition.SCOPE_PROTOTYPE)
private static class AnnotatedComponent implements Serializable {
private final Dependency dep;
@Autowired
public AnnotatedComponent(@Qualifier("myDep") Dependency dep) {
this.dep = dep;
}
private static class Dependency {
}
}
}Запустив его дважды (с оборачиванием и без него) получаем:
Java 8
original
Score Error Units
read 122.041 ± 1.286 us/op
read:·gc.alloc.rate.norm 50795.798 ± 13.941 B/op
patched
Score Error Units
read 119.524 ± 1.171 us/op
read:·gc.alloc.rate.norm 42635.578 ± 10.866 B/op
Java 11
original
Score Error Units
read 114.142 ± 3.338 us/op
read:·gc.alloc.rate.norm 32761.715 ± 29.115 B/op
patched
Score Error Units
read 108.903 ± 1.281 us/op
read:·gc.alloc.rate.norm 24652.976 ± 32.380 B/opТаким образом, просто выбросив ненужную буферизацию мы получили неплохую экономию памяти и небольшое снижение времени выполнения.
Будет ли от этого толк в масштабе приложения? Чтобы проверить это можно собрать Спринг с указанным изменением и воспользоваться бенчмарком:
@State(Scope.Thread)
@BenchmarkMode(Mode.SingleShotTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@Fork(jvmArgsAppend = {"-Xms2g", "-Xmx2g"})
public class SpringBootApplicationBenchmark {
private ConfigurableApplicationContext context;
@Benchmark
public Object startUp() {
return context = SpringApplication.run(BenchmarkApplication.class);
}
@TearDown(Level.Invocation)
public void close() {
context.close();
}
}Здесь мы измеряем время, необходимое для запуска приложения на Спринг-Буте:
original
startUp 760.1 ± 13.5 ms/op
startUp:·gc.alloc.rate.norm 50429174.6 ± 18132.0 B/op
patched
startUp 718.7 ± 20.5 ms/op
startUp:·gc.alloc.rate.norm 49776228.7 ± 19919.8 B/opПока не особо впечатляет, но даже такое простое изменение даёт прирост.
Критически настроенный читатель посчитает это изменение чересчур резким, ведь у интерфейса Resource есть 44 (!) реализации:

Возможно, нам стоит использовать более щадящий подход а-ля Котлин:
// получение буферизированного потока ввода
return File(name).inputStream().buffered();
// реализация InputStream.buffered()
@kotlin.internal.InlineOnly
fun InputStream.buffered(size: Int = DEFAULT_BUFFER_SIZE) =
if (this is BufferedInputStream)
this
else
BufferedInputStream(this, size)Раз всё дело в избыточном заворачивании в BufferedInputStream, то ничто не мешает нам соорудить что-то вроде:
static InputStream buffered(InputStream is) {
return is instanceof BufferedInputStream
? is
: new BufferedInputStream(is);
}и использовать его в SimpleMetadataReader-е.
Но и тут есть нюансы, ведь у InputStreama есть множество реализаций, например, ByteArrayInputStream, который не является подклассом BufferedInputStream-а, а значит он будет обёрнут:
public class ByteArrayInputStream extends InputStream {
protected byte buf[];
public synchronized int read() {
return pos < count ? buf[pos++] & 0xff : -1;
}
public synchronized int read(byte b[], int off, int len) {
//...
System.arraycopy(buf, pos, b, off, len);
}
}Уже поверхностное рассмотрение кода показывается бессмысленность использования BufferedInputStream-а, что подтверждается бенчмарком:
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class ByteArrayInputStreamBenchmark {
@Benchmark
public Object read(Data data) {
return data.bais.readAllBytes();
}
@Benchmark
public Object readBuffered(Data data) throws IOException {
return new BufferedInputStream(data.bais).readAllBytes();
}
@State(Scope.Thread)
public static class Data {
@Param({"8", "128", "512", "1024"})
private int length;
private byte[] bytes;
private ByteArrayInputStream bais;
@Setup(Level.Iteration)
public void setUp() {
bytes = new byte[length];
ThreadLocalRandom.current().nextBytes(bytes);
}
@Setup(Level.Invocation)
public void setUpBais() {
bais = new ByteArrayInputStream(bytes);
}
}
}дающим совершенно сногсшибательные результаты:
length
read 8 35.673 ± 0.591 ns/op
read 128 38.245 ± 0.918 ns/op
read 512 46.110 ± 1.652 ns/op
read 1024 60.487 ± 0.687 ns/op
readBuffered 8 869.221 ± 3.573 ns/op
readBuffered 128 876.611 ± 10.665 ns/op
readBuffered 512 890.678 ± 3.481 ns/op
readBuffered 1024 914.731 ± 8.759 ns/op
read:·gc.alloc.rate.norm 8 56.000 ± 0.001 B/op
read:·gc.alloc.rate.norm 128 176.000 ± 0.001 B/op
read:·gc.alloc.rate.norm 512 560.000 ± 0.001 B/op
read:·gc.alloc.rate.norm 1024 1072.000 ± 0.001 B/op
readBuffered:·gc.alloc.rate.norm 8 16512.001 ± 0.001 B/op
readBuffered:·gc.alloc.rate.norm 128 16632.001 ± 0.001 B/op
readBuffered:·gc.alloc.rate.norm 512 17016.001 ± 0.001 B/op
readBuffered:·gc.alloc.rate.norm 1024 17528.001 ± 0.001 B/opОбратите внимание на огромный перерасход памяти: 17 килобайт использовано для чтения 1. Всё очень и очень празднично.
Хорошо, немного поправим наше решение:
public static InputStream buffered(InputStream is) {
return requiresBuffer(is) ? is : new BufferedInputStream(is);
}
private static boolean requiresBuffer(InputStream is) {
return is instanceof BufferedInputStream
|| is instanceof ByteArrayInputStream;
}Теперь найдём наиболее часто используемые реализации. Вот один из примеров:

Но и для этого класса буферизация оказывается вредной.
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class ResourceLoadBenchmark {
private Resource resource;
@Setup
public void setUp(){
String str = "classpath:org/springframework/boot/autoconfigure/orm"
+ "/jpa/DataSourceInitializedPublisher$Registrar.class";
DefaultResourceLoader defaultResourceLoader = new DefaultResourceLoader();
resource = defaultResourceLoader.getResource(str);
}
@Benchmark
public Object read() throws IOException {
try (InputStream is = resource.getInputStream()) {
return new ClassReader(is);
}
}
@Benchmark
public Object readBuffered() throws IOException {
try (InputStream is = new BufferedInputStream(resource.getInputStream())) {
return new ClassReader(is);
}
}
}read 23.095 ± 0.548 us/op
readBuffered 23.044 ± 0.229 us/op
read:·gc.alloc.rate.norm 36804.834 ± 31.763 B/op
readBuffered:·gc.alloc.rate.norm 44993.634 ± 31.439 B/opСобрав статистику выкатываем итоговую версию:
private static boolean requiresBuffer(InputStream is) {
return is instanceof BufferedInputStream
|| is instanceof ByteArrayInputStream
|| is instanceof ChannelInputStream
|| is instanceof ZipFile.ZipFileInflaterInputStream;
}И сразу появляется неудобство:
// класс приватный и в коде выше ошибка компиляции
private class ZipFileInflaterInputStream extends InflaterInputStream {
//...
}Злоключения на этом не заканчиваются, ведь кодовая база "Спринга" всё ещё использует "восьмёрку", но рано или поздно настанет день обновления, и тогда у нас появится ещё одна ошибка:
error: package sun.nio.ch is not visible
import sun.nio.ch.ChannelInputStream;
^
(package sun.nio.ch is declared in module java.base, which does not
export it to the unnamed module)В "девятке" пакет sun.nio.ch не экспортируется модулем java.base, поэтому использовать его больше не получится.
Если бы мы жили в идеальном мире, то InputStream был бы интерфейсом, в который было бы достаточно добавить один метод:
public interface InputStream extends Closeable {
default boolean isBuffered() {
return false;
}
}и использовать его вот так:
public static InputStream buffered(InputStream is) {
return is.isBuffered() ? is : new BufferedInputStream(is);
}Теперь вернёмся к org.springframework.asm.ClassReader, возможно из него можно выжать ещё что-нибудь.
static byte[] readStream(InputStream is, boolean close) throws IOException {
try (ByteArrayOutputStream outputStream = new ByteArrayOutputStream()) {
byte[] data = new byte[INPUT_STREAM_DATA_CHUNK_SIZE];
int bytesRead;
while ((bytesRead = is.read(data, 0, data.length)) != -1) {
outputStream.write(data, 0, bytesRead);
}
outputStream.flush();
return outputStream.toByteArray();
} finally {
if (close) {
is.close();
}
}
}Большой недостаток этого метода в выделении буфера постоянного размера:

Обратите внимание: для чтения 421 байта выделено 4 кБ - в 10 раз больше, чем необходимо. Также в том случае, когда метод InputStream.read(byte[], int, int)смог считать все данные сразу в буфер нужного размера, вызов OutputStream.toByteArray()стал бы ненужен, ведь массив data уже содержит все данные, а значит можно вернуть его из метода избежав копирования.
Зайдём в лоб и воспользуемся InputStream.available():
int expectedLength = inputStream.available();
try (ByteArrayOutputStream os = new ByteArrayOutputStream()) {
byte[] data = new byte[expectedLength];
int bytesRead;
while ((bytesRead = inputStream.read(data, 0, available)) != -1) {
os.write(data, 0, bytesRead);
}
os.flush();
return expectedLength == os.size() ? data : os.toByteArray();
}И тут же облом:
/**
* ... A single read or skip of this many bytes will not block, but
* may read or skip fewer bytes.
* ...
* It is never correct to use the return value of this method
* to allocate a buffer intended to hold all data in this stream.
**/
public int available() throws IOException { }Мы не можем полагаться на expectedLength == os.size(), т. к. возможен случай, в котором InputStream.available()вернёт 3 кБ, но при чтении будет получено только 2, из-за чего мы пойдём на второй проход по циклу. В итоге условие expectedLength == os.size()будет выполнено, но data будет содержать только 1 кБ из 3, что закончится падением контекста.
Что ж, изменим код чтобы явно отслеживать количество чтений:
int expectedLength = inputStream.available();
try (ByteArrayOutputStream os = new ByteArrayOutputStream()) {
byte[] data = new byte[expectedLength];
int bytesRead;
int readCount = 0;
while ((bytesRead = inputStream.read(data, 0, bufferSize)) != -1) {
os.write(data, 0, bytesRead);
readCount++;
}
os.flush();
return readCount == 1 ? data : os.toByteArray();
}Это вполне рабочий вариант, но он всё ещё таит скрытую угрозу:
var file = new File("/home/s.tsypanov/.bashrc");
var fileInputStream = new FileInputStream(file);
var available = fileInputStream.available(); // 4362 байта
var arrayLength = fileInputStream.readAllBytes().length; // 4362 байта
var file = new File("/proc/self/stat");
var fileInputStream = new FileInputStream(file);
var available = fileInputStream.available(); // 0 байт
var arrayLength = fileInputStream.readAllBytes().length; // 324 байтаОказывается, Линукс допускает существование файлов, которые притворяются пустыми, но в действительности содержат данные. Конечно, если classpath вашего приложения расположен в /proc, то вы более чем странный человек, но такую возможность исключать нельзя, поэтому перестрахуемся:
int expectedLength = inputStream.available();
int bufferSize = expectedLength < 256
? INPUT_STREAM_DATA_CHUNK_SIZE
: expectedLength;
// ...
byte[] data = new byte[bufferSize];И это даже приносит пользу!
original
startUp 760.1 ± 13.5 ms/op
startUp:·gc.alloc.rate.norm 50429174.6 ± 18132.0 B/op
no BufferedInputStream
startUp 718.7 ± 20.5 ms/op
startUp:·gc.alloc.rate.norm 49776228.7 ± 19919.8 B/op
улучшенный ClassReader.readStream()
startUp 614.8 ± 7.0 ms/op <--- !
startUp:·gc.alloc.rate.norm 49003403.9 ± 21786.8 B/opОкрылённый успехом я создал ПР Improve performance of ASM's ClassReader.readStream() , забыв, что ClassReader целиком скопирован из библиотек ASM, поэтому правильнее всё-таки создать ПР туда, что я и сделал. Однако, разработчикам ASM-а идея показалась слишком смелой, поэтому пока изменения лежат без движения. Нужно отметить, что ASM - это не совсем обычная библиотека, многие её используют путём копирования исходников в свой проект (кроме Спринга так же сделали в JDK).
В любом случае, похожий финт ушами в можете делать в своих проектах самостоятельно.
Вывод для разработчика
производительность ввода-вывода - это "страна, где много-много диких обезьян" и всё в ней делается на свой страх и риск
ни один из рецептов не должен быть догмой, даже такая очевидно полезная вещь, как буферизация нередко вредит
указывайте в документации ваших методов необходимость буферизации или её отсутствия. Да, это детали реализации, но часто они очень важны
Итоговые выводы
правильно истолковать цифры бенчмарка столь же важно, как и правильно написать этот самый бенчмарк
без понимания природы цифр сами по себе они бесполезны
измерять нужно именно конечный сценарий, улучшение частного может ухудшить целое
изменения под копирку работают не всегда
вникайте в контекст, производительность – это немного про археологию
в производительности изучайте реализации, а не только интерфейс, а также не доверяйте слепа красотам/ужасам документации
З.Ы. Бенчмарки для IO лежат тут.
