На Хабре уже было несколько статей упоминающих deferred constraints.
Но хочется рассказать о них подробнее.

Одна из сильных сторон реляционных СУБД это постоянная бдительность за согласованностью данных (ACID, C — Согласованность). Разработчик может задать ограничения данным, а СУБД будет следить за их исполнением. Это позволяется избежать многих потенциальных ошибок.
Автоматическая проверка ограничений это мощный функционал, который при возможности должен быть использован. Однако, бывают случаи, когда удобно и даже необходимо временно отложить их исполнение.
В PostgreSQL есть 3 уровня проверки ограничений
В PostgreSQL уровень всех ограничений по умолчанию — NOT DEFERRABLE.
Чтобы изменить гранулярность проверки ограничения мы должны явно объявить ограничение как отложенное. При этом некоторые ограничения нельзя отложить. CHECK и NOT NULL всегда будут проверяться для каждой строки. Это поведение PostgreSQL нарушает SQL-стандарт.
Прежде чем рассмотреть когда/зачем использовать отложенные ограничения, давайте рассмотрим как они работают. Вначале создадим отложенное ограничение.
Отложенные ограничения дают транзакциям гибкость. Любая транзакция может выбрать отложить или нет проверку foo_bar_fk:
Кроме того, мы можем использовать другой подход и объявить ограничение при создании как DEFERRABLE INITIALLY DEFERRED. Если транзакция не хочет откладывать проверку такого ограничения, то она может выполнить SET CONSTRAINTS constraint_name IMMEDIATE.
Без явного начала транзакции через BEGIN каждый запрос выполняется в своей неявной транзакции из одного запроса, поэтому нет разницы между IMMEDIATE и DEFERRED для одного запроса.
Попытка отложить ограничения вне транзакции не работает и приведёт к предупреждению WARNING: 25P01: SET CONSTRAINTS can only be used in transaction blocks.
Ещё одно важно замечание. Ограничения UNIQUE и PRIMARY KEY, объявленные как DEFERRABLE INITIALLY IMMEDIATE будут проверяться не на уровне строки, а на уровне запроса. Даже если транзакция не откладывает проверку ограничения, гранулярность всё равно изменится.
Давайте рассмотрим отличие гранулярности проверки на уровне строки и запроса на следующем примере.
UNIQUE ограничение здесь не отложенное, поэтому UPDATE будет в режиме «по строке» и не выполнится со следующей ошибкой.
Если бы PostgreSQL дождался обновления всех строк (как в проверке на уровне «по запросу»), то проблем бы не было. Значение i в строках будет последовательно увеличиваться и в итоге они все станут уникальными. Так как PostgreSQL проверяет ограничения сразу, то после обновления первой строки с i=1 на i=2 состояние таблицы будет 2, 2, 3.
Построчная проверка ограничений хрупка и зависит от физического расположения строк. Например, если бы мы заполнили таблицу в обратном порядке INSERT INTO snowflakes VALUES (3), (2), (1)), то UPDATE сработал бы.
Подводя итог, объявление ограничения отложенным позволяет транзакциям отложить проверку до фиксации. А также влияет на поведение некоторых ограничений вне транзакций. Например, следующий SQL отработает безошибочно.
Классический пример — создание двух таблиц, связанных циклическими проверками согласованности.
Для создание строки в таблице husbands, необходимо в то же время создать строку в таблице wives. В данном случае у нас ничего не получится, так как внешние ключи проверяются на уровне строк, и для вставки в две таблицы нужно два запроса INSERT. Чтобы разрешить данную задачу мы можем отложить проверку ограничений.
Так как циклические ограничения с большой вероятностью нужно всегда откладывать, то мы объявили их отложенными по умолчанию. Теперь мы можем заполнить таблицы данными.
У нас получился аккуратный пример, как по учебнику. Но есть один маленький грязный хак.
PostgreSQL имеет альтернативный вариант решения без использовния отложенных ограничений.
Общие табличные выражения (CTEs) позволяют выполнить несколько SQL-запросов, которые будут считаться одним при проверке ограничений, так как внешние ключи проверяются на уровне запроса.
Хотя мы и нашли способ не использовать отложенные ограничения для циклических внешних ключей, это всё равно хорошее начало чтобы познакомиться с отложенными ограничениями.
В данном примере, мы рассмотрим набор классов школы с ровно одним прикрепленным учителем. Пусть мы хотим переставить учителей двух классов. Ограничения усложняют нам жизнь.
Трюк с CTE не получится так как не отложенное ограничение UNIQUE проверяется на уровне строки, а не запроса.
Чтобы переставить учителей без отложенного ограничения на teacher_id, мы можем
использовать временного учителя.
Использование временного учителя это грязный хак. Более естественно создать таблицу с отложенным ограничением.
Это позволит произвести обмен намного проще:
Теперь будет работать подход CTE с неявной транзакцией, так как ограничение проверяется на уровне запроса, а не строки.
Можно смоделировать список дел в упорядоченном порядке, использую целочисленный столбец position:
Каждая позиция уникальна в рамках списка из-за составного ограничения первичного ключа.
Допустим мы вспомнили, что забыли добавить элемент в начало списка «составить меню». Если мы хотим установить данному элементу позицию 1, то нужно сместить все остальные элементы на +1. Это такая же задача как и в прошлом примере про снежинки.
Объявив первичный ключ как отложенный, мы исправим данную проблему:
В данном случае PostgreSQL будет проверять ограничение на уровне запроса, и нам не нужно дополнительного запроса в транзакции, чтобы отложить проверку ограничения SET… DEFERRED.
Но отложенные ограничения не лучшее решение в данном случае. Изменяемую позицию лучше хранить как дробь (рациональное число), вместо целого. Данный подход всегда позволит найти позицию между двумя существующими элементами. Посмотрите мою статью User-defined Order in SQL. Такой подход позволит не использовать отложенные ограничения.
Отложенные ограничения могут сделать процесс наполнения таблиц более удобным.
Например, отложенные внешние ключи позволяют загружать данные в таблицы в любом порядке. Например вначале потомков, а затем родителей.
В некоторых интернет статьях утверждают, что отложенные ограничения позволяют быстрее выполнять массовые вставки (bulk INSERTs). По моим оценкам, это миф. Во время фиксации транзакции такое же кол-во проверок будет выполнено для отложенных и не отложенных ограничений. Для проверки:
Теперь вставим 5 миллион строк в таблицу child и замерим время вставки и проверки внешнего ключа. Запуск был на моём ноутбуке с PostgreSQL 9.6.3:
Попробуем ещё раз, но теперь отложим проверку ограничения:
Время, которое мы экономим при вставке, мы теряем в момент фиксации транзакции.
Единственный способ ускорить загрузку — это временно отключить проверку внешнего ключа (при условии, что мы заранее знаем, что данные для загрузки верны). Как правило, это плохая идея, потому что мы можем потратить больше времени на последующую отладку неконсистентности данных, чем на проверку согласованности во время вставки.
Кажется что отложенные ограничения это круто! Объявление ограничений отложенными даёт нам большую гибкость, но почему не стоит откладывать все ограничения?
Планировщик запросов СУБД использует факты о данных для выбора правильных и эффективных стратегий выполнения. Его первая обязанность — возвращать правильные результаты, и он будет использовать оптимизацию только тогда, когда ограничения базы данных гарантируют корректность. По определению нет гарантий, что откладываемые ограничения будут выполняться всё время, поэтому они мешают планировщику.
Чтобы узнать больше, я спросил Andrew Gierth, RhodiumToad, в IRC, и получил следующий ответ: «Планировщик может определить, что набор условий в таблице гарантирует уникальность результата. Если существует уникальный, неотложный индекс, он может исключить этап сортировки/уникальности или хеширования. Но при отложенных ограничениях могут присутствовать повторяющиеся значения».
Он обрисовал в общих чертах две оптимизации: одну в PostgreSQL 9 и одну в 10ой версии. Старый функционал — это удаление JOIN'a из запроса:
Заметьте JOIN исчез, и используется обычный Seq Scan:
Но если использовать JOIN по b, с отложенным ограничением, то JOIN останется:
В PostgreSQL 10 есть другая оптимизация, которая превращает semi-JOIN из подзапроса IN в обычный JOIN, когда столбец подзапроса гарантировано уникален.
В случае с b, отложенное ограничение помешает оптимизации
Получение ошибок только после завершения набора запросов усложняет отладку. Ошибка не позволяет точно определить, какой запрос вызвал проблему. Вы можете и не найти нужный запрос по сообщению об ошибке.
В данном случае сообщение даёт достаточно информации, чтобы найти проблемный запрос, но может быть и более сложный случай без конкретных значений.
Ошибки во время фиксации транзакции могут не только сбить с толку, но и внести погрешность в ORM. DataMapper предназначены для упрощенного доступа к СУБД и не все могут правильно обработать ошибки ограничений на уровне транзакций.
Так же любая работа выполненная после отложенного ограничения может быть в итоге потеряна, после отката транзакции. Отложенные ограничения могут тратить CPU впустую.
Последний трюк для развлечения.
Команда SET CONSTRAINTS принимает имя ограничения. Но может быть удобнее отложить ограничения по столбцам. PostgreSQL information_schema позволяет искать ограничения по столбцам.
В примере выше мы могли бы использовать данную функцию для того чтобы отложить ограничения по столбца child и parent_id.
- Postgres: bloat, pg_repack и deferred constraints
- Ограничения (сonstraints) PostgreSQL: exclude, частичный unique, отложенные ограничения и др
Но хочется рассказать о них подробнее.

От переводчика: терминология
- Constraint — ограничение
- SQL statement — SQL-запрос
Одна из сильных сторон реляционных СУБД это постоянная бдительность за согласованностью данных (ACID, C — Согласованность). Разработчик может задать ограничения данным, а СУБД будет следить за их исполнением. Это позволяется избежать многих потенциальных ошибок.
Автоматическая проверка ограничений это мощный функционал, который при возможности должен быть использован. Однако, бывают случаи, когда удобно и даже необходимо временно отложить их исполнение.
Гранулярность проверки ограничений
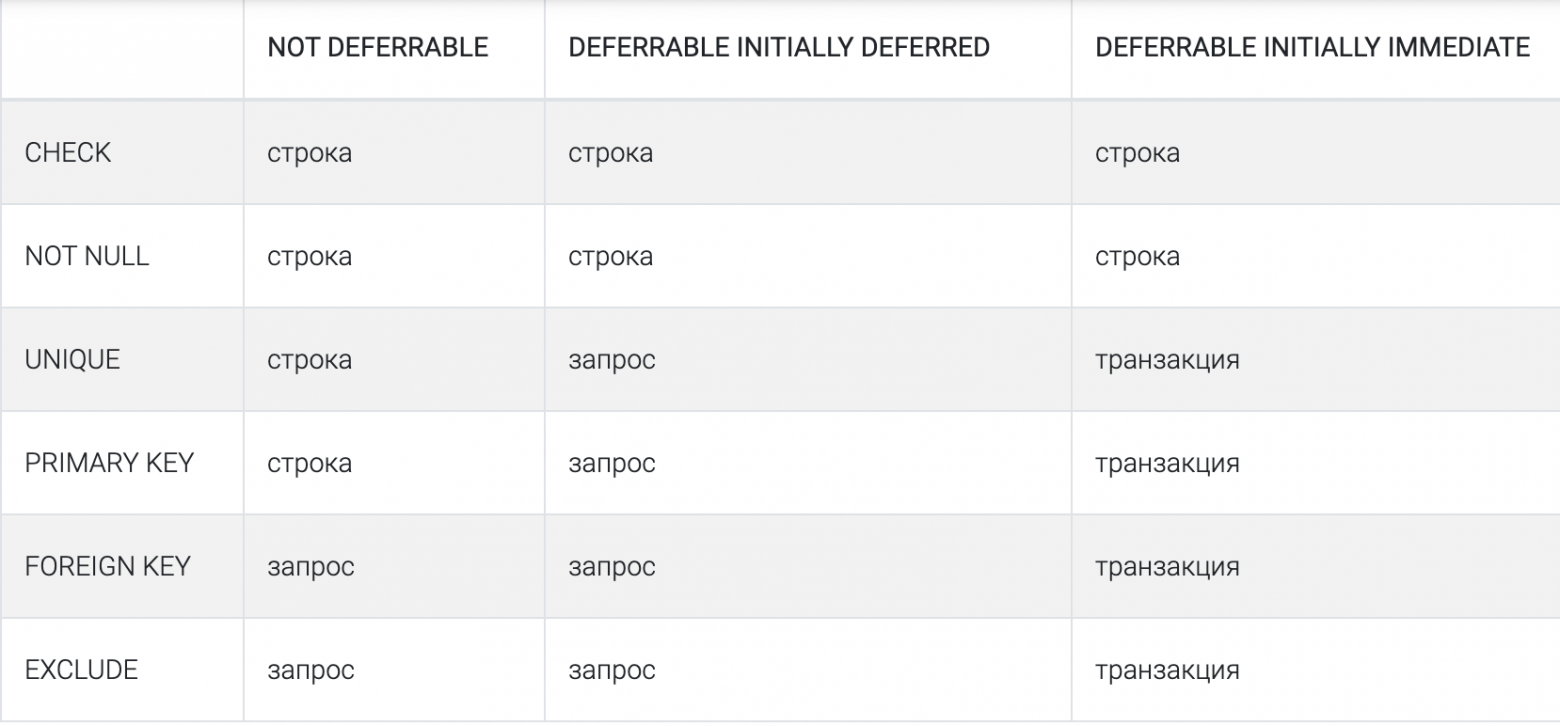
В PostgreSQL есть 3 уровня проверки ограничений
- По строке. SQL-запрос, который обновляет множество строк, остановится на первой строке, не удовлетворяющей ограничению.
- По запросу. В этом случае запрос произведет все изменения, прежде чем проверить ограничения.
- По транзакции. Любой запрос внутри транзакции может нарушить ограничение. Но в момент фиксации, ограничения будут проверены и транзакция откатится, если хотя бы одно из них не будет выполнено.
В PostgreSQL уровень всех ограничений по умолчанию — NOT DEFERRABLE.

Чтобы изменить гранулярность проверки ограничения мы должны явно объявить ограничение как отложенное. При этом некоторые ограничения нельзя отложить. CHECK и NOT NULL всегда будут проверяться для каждой строки. Это поведение PostgreSQL нарушает SQL-стандарт.
От переводчика
Вероятно, имеется ввиду стандарт SQL92. Раздел 4.10 Integrity constraints
Every constraint descriptor includes:
Every constraint descriptor includes:
- the name of the constraint;
- an indication of whether or not the constraint is deferrable;
- an indication of whether the initial constraint mode is deferred or immediate;
Прежде чем рассмотреть когда/зачем использовать отложенные ограничения, давайте рассмотрим как они работают. Вначале создадим отложенное ограничение.
ALTER TABLE foo
ADD CONSTRAINT foo_bar_fk
FOREIGN KEY (bar_id) REFERENCES bar (id)
DEFERRABLE INITIALLY IMMEDIATE; -- магия, объявляющая ограничение с возможностью быть отложенным, но по умолчанию оно будет проверяться сразу.
Отложенные ограничения дают транзакциям гибкость. Любая транзакция может выбрать отложить или нет проверку foo_bar_fk:
BEGIN;
-- Отложить проверку ограничения
SET CONSTRAINTS foo_bar_fk DEFERRED;
-- ...
-- Производим операции над bar_id
-- ...
COMMIT; -- В данном месте произойдёт проверка ограничения
Кроме того, мы можем использовать другой подход и объявить ограничение при создании как DEFERRABLE INITIALLY DEFERRED. Если транзакция не хочет откладывать проверку такого ограничения, то она может выполнить SET CONSTRAINTS constraint_name IMMEDIATE.
Без явного начала транзакции через BEGIN каждый запрос выполняется в своей неявной транзакции из одного запроса, поэтому нет разницы между IMMEDIATE и DEFERRED для одного запроса.
Попытка отложить ограничения вне транзакции не работает и приведёт к предупреждению WARNING: 25P01: SET CONSTRAINTS can only be used in transaction blocks.
Ещё одно важно замечание. Ограничения UNIQUE и PRIMARY KEY, объявленные как DEFERRABLE INITIALLY IMMEDIATE будут проверяться не на уровне строки, а на уровне запроса. Даже если транзакция не откладывает проверку ограничения, гранулярность всё равно изменится.
Давайте рассмотрим отличие гранулярности проверки на уровне строки и запроса на следующем примере.
CREATE TABLE snowflakes ( i int UNIQUE NOT DEFERRABLE);
INSERT INTO snowflakes VALUES (1), (2), (3);
UPDATE snowflakes SET i = i + 1;
UNIQUE ограничение здесь не отложенное, поэтому UPDATE будет в режиме «по строке» и не выполнится со следующей ошибкой.
ERROR: 23505: duplicate key value violates unique constraint "snowflakes_i_key"
DETAIL: Key (i)=(2) already exists.
Если бы PostgreSQL дождался обновления всех строк (как в проверке на уровне «по запросу»), то проблем бы не было. Значение i в строках будет последовательно увеличиваться и в итоге они все станут уникальными. Так как PostgreSQL проверяет ограничения сразу, то после обновления первой строки с i=1 на i=2 состояние таблицы будет 2, 2, 3.
Построчная проверка ограничений хрупка и зависит от физического расположения строк. Например, если бы мы заполнили таблицу в обратном порядке INSERT INTO snowflakes VALUES (3), (2), (1)), то UPDATE сработал бы.
Подводя итог, объявление ограничения отложенным позволяет транзакциям отложить проверку до фиксации. А также влияет на поведение некоторых ограничений вне транзакций. Например, следующий SQL отработает безошибочно.
CREATE TABLE snowflakes ( i int UNIQUE DEFERRABLE INITIALLY IMMEDIATE);
INSERT INTO snowflakes VALUES (1), (2), (3);
UPDATE snowflakes SET i = i + 1;
Зачем нужны отложенные ограничения?
Циклические внешние ключи
Классический пример — создание двух таблиц, связанных циклическими проверками согласованности.
CREATE TABLE husbands (
id int PRIMARY KEY,
wife_id int NOT NULL
);
CREATE TABLE wives (
id int PRIMARY KEY,
husband_id int NOT NULL
);
ALTER TABLE husbands ADD CONSTRAINT h_w_fk
FOREIGN KEY (wife_id) REFERENCES Wives;
ALTER TABLE wives ADD CONSTRAINT w_h_fk
FOREIGN KEY (husband_id) REFERENCES husbands;
Для создание строки в таблице husbands, необходимо в то же время создать строку в таблице wives. В данном случае у нас ничего не получится, так как внешние ключи проверяются на уровне строк, и для вставки в две таблицы нужно два запроса INSERT. Чтобы разрешить данную задачу мы можем отложить проверку ограничений.
ALTER TABLE husbands ALTER CONSTRAINT h_w_fk
DEFERRABLE INITIALLY DEFERRED;
ALTER TABLE wives ALTER CONSTRAINT w_h_fk
DEFERRABLE INITIALLY DEFERRED;
Так как циклические ограничения с большой вероятностью нужно всегда откладывать, то мы объявили их отложенными по умолчанию. Теперь мы можем заполнить таблицы данными.
BEGIN;
INSERT INTO husbands (id, wife_id) values (1, 1);
INSERT INTO wives (id, husband_id) values (1, 1);
COMMIT;
-- и жили они долго и счастливо :)
У нас получился аккуратный пример, как по учебнику. Но есть один маленький грязный хак.
PostgreSQL имеет альтернативный вариант решения без использовния отложенных ограничений.
-- Сделаем ограничения вновь проверяемыми сразу
ALTER TABLE husbands ALTER CONSTRAINT h_w_fk
NOT DEFERRABLE;
ALTER TABLE wives ALTER CONSTRAINT w_h_fk
NOT DEFERRABLE;
-- Вместо двух INSERT выполним один SQL-запрос
WITH wife AS (
INSERT INTO wives (id, husband_id)
VALUES (2, 2)
)
INSERT INTO husbands (id, wife_id)
VALUES (2, 2);
Общие табличные выражения (CTEs) позволяют выполнить несколько SQL-запросов, которые будут считаться одним при проверке ограничений, так как внешние ключи проверяются на уровне запроса.
Хотя мы и нашли способ не использовать отложенные ограничения для циклических внешних ключей, это всё равно хорошее начало чтобы познакомиться с отложенными ограничениями.
Перестановка элементов, по одному на группу
В данном примере, мы рассмотрим набор классов школы с ровно одним прикрепленным учителем. Пусть мы хотим переставить учителей двух классов. Ограничения усложняют нам жизнь.
CREATE TABLE classes (
id int PRIMARY KEY,
teacher_id int UNIQUE NOT NULL
);
INSERT INTO classes VALUES (1, 1), (2, 2);
Трюк с CTE не получится так как не отложенное ограничение UNIQUE проверяется на уровне строки, а не запроса.
WITH swap AS (
UPDATE classes
SET teacher_id = 2
WHERE id = 1
)
UPDATE classes
SET teacher_id = 1
WHERE id = 2;
ERROR: 23505: duplicate key value violates unique constraint "classes_teacher_id_key"
DETAIL: Key (teacher_id)=(1) already exists.
Чтобы переставить учителей без отложенного ограничения на teacher_id, мы можем
использовать временного учителя.
-- Временный учитель 999, позволит произвести перестановку
UPDATE classes SET teacher_id = 999 WHERE id = 1;
UPDATE classes SET teacher_id = 1 WHERE id = 2;
UPDATE classes SET teacher_id = 2 WHERE id = 1;
Использование временного учителя это грязный хак. Более естественно создать таблицу с отложенным ограничением.
CREATE TABLE classes (
id int PRIMARY KEY,
teacher_id int NOT NULL UNIQUE
DEFERRABLE INITIALLY IMMEDIATE
);
Это позволит произвести обмен намного проще:
BEGIN;
SET CONSTRAINTS classes_teacher_id_key DEFERRED;
UPDATE classes SET teacher_id = 1 WHERE id = 2;
UPDATE classes SET teacher_id = 2 WHERE id = 1;
COMMIT;
Теперь будет работать подход CTE с неявной транзакцией, так как ограничение проверяется на уровне запроса, а не строки.
Перенумерация списка
Можно смоделировать список дел в упорядоченном порядке, использую целочисленный столбец position:
CREATE TABLE todos (
list_id int,
position int,
task text,
PRIMARY KEY (list_id, position)
);
INSERT INTO todos VALUES
(1, 1, 'write grocery list'),
(1, 2, 'go to store'),
(1, 3, 'buy items');
Каждая позиция уникальна в рамках списка из-за составного ограничения первичного ключа.
Допустим мы вспомнили, что забыли добавить элемент в начало списка «составить меню». Если мы хотим установить данному элементу позицию 1, то нужно сместить все остальные элементы на +1. Это такая же задача как и в прошлом примере про снежинки.
Объявив первичный ключ как отложенный, мы исправим данную проблему:
CREATE TABLE todos (
list_id int,
position int,
task text,
PRIMARY KEY (list_id, position)
DEFERRABLE INITIALLY IMMEDIATE
);
В данном случае PostgreSQL будет проверять ограничение на уровне запроса, и нам не нужно дополнительного запроса в транзакции, чтобы отложить проверку ограничения SET… DEFERRED.
UPDATE todos
SET position = position + 1
WHERE list_id = 1;
INSERT INTO todos VALUES
(1, 1, 'plan menus');
Но отложенные ограничения не лучшее решение в данном случае. Изменяемую позицию лучше хранить как дробь (рациональное число), вместо целого. Данный подход всегда позволит найти позицию между двумя существующими элементами. Посмотрите мою статью User-defined Order in SQL. Такой подход позволит не использовать отложенные ограничения.
Загрузка данных в таблицы
Отложенные ограничения могут сделать процесс наполнения таблиц более удобным.
Например, отложенные внешние ключи позволяют загружать данные в таблицы в любом порядке. Например вначале потомков, а затем родителей.
В некоторых интернет статьях утверждают, что отложенные ограничения позволяют быстрее выполнять массовые вставки (bulk INSERTs). По моим оценкам, это миф. Во время фиксации транзакции такое же кол-во проверок будет выполнено для отложенных и не отложенных ограничений. Для проверки:
CREATE TABLE parent (
id int PRIMARY KEY,
name text NOT NULL
);
CREATE TABLE child (
id int PRIMARY KEY,
parent_id int REFERENCES parent
DEFERRABLE INITIALLY IMMEDIATE,
name text
);
INSERT INTO parent
SELECT
generate_series(1,1000000) AS id,
md5(random()::text) as name;
Теперь вставим 5 миллион строк в таблицу child и замерим время вставки и проверки внешнего ключа. Запуск был на моём ноутбуке с PostgreSQL 9.6.3:
INSERT INTO child
SELECT
generate_series(1,5000000) AS id,
generate_series(1,1000000) AS parent_id,
md5(random()::text) as name;
--
-- Time: 89064.987 ms
Попробуем ещё раз, но теперь отложим проверку ограничения:
BEGIN;
SET CONSTRAINTS child_parent_id_fkey DEFERRED;
INSERT INTO child
SELECT
generate_series(1,5000000) AS id,
generate_series(1,1000000) AS parent_id,
md5(random()::text) as name;
--
-- Time: 40828.810 ms
COMMIT;
--
-- Time: 47211.533 ms
-- Total: 88040.343 ms
Время, которое мы экономим при вставке, мы теряем в момент фиксации транзакции.
Единственный способ ускорить загрузку — это временно отключить проверку внешнего ключа (при условии, что мы заранее знаем, что данные для загрузки верны). Как правило, это плохая идея, потому что мы можем потратить больше времени на последующую отладку неконсистентности данных, чем на проверку согласованности во время вставки.
Причины не использовать отложенные ограничения
Кажется что отложенные ограничения это круто! Объявление ограничений отложенными даёт нам большую гибкость, но почему не стоит откладывать все ограничения?
Планировщик запросов и штраф производительности
Планировщик запросов СУБД использует факты о данных для выбора правильных и эффективных стратегий выполнения. Его первая обязанность — возвращать правильные результаты, и он будет использовать оптимизацию только тогда, когда ограничения базы данных гарантируют корректность. По определению нет гарантий, что откладываемые ограничения будут выполняться всё время, поэтому они мешают планировщику.
Чтобы узнать больше, я спросил Andrew Gierth, RhodiumToad, в IRC, и получил следующий ответ: «Планировщик может определить, что набор условий в таблице гарантирует уникальность результата. Если существует уникальный, неотложный индекс, он может исключить этап сортировки/уникальности или хеширования. Но при отложенных ограничениях могут присутствовать повторяющиеся значения».
Он обрисовал в общих чертах две оптимизации: одну в PostgreSQL 9 и одну в 10ой версии. Старый функционал — это удаление JOIN'a из запроса:
CREATE TABLE foo (
a integer UNIQUE,
b integer UNIQUE DEFERRABLE
);
EXPLAIN
SELECT t1.*
FROM foo t1
LEFT JOIN foo t2
ON (t1.a = t2.a);
Заметьте JOIN исчез, и используется обычный Seq Scan:
QUERY PLAN
----------------------------------------------------------
Seq Scan on foo t1 (cost=0.00..32.60 rows=2260 width=8)
Но если использовать JOIN по b, с отложенным ограничением, то JOIN останется:
EXPLAIN
SELECT t1.*
FROM foo t1
LEFT JOIN foo t2
ON (t1.b = t2.b);
QUERY PLAN
----------------------------------------------------------------------
Hash Left Join (cost=60.85..124.53 rows=2260 width=8)
Hash Cond: (t1.b = t2.b)
-> Seq Scan on foo t1 (cost=0.00..32.60 rows=2260 width=8)
-> Hash (cost=32.60..32.60 rows=2260 width=4)
-> Seq Scan on foo t2 (cost=0.00..32.60 rows=2260 width=4)
В PostgreSQL 10 есть другая оптимизация, которая превращает semi-JOIN из подзапроса IN в обычный JOIN, когда столбец подзапроса гарантировано уникален.
EXPLAIN
SELECT *
FROM foo
WHERE a IN (
SELECT a FROM foo
);
-- Планировщик понял, что столбец а уникальный
QUERY PLAN
-------------------------------------------------------------------------
Hash Join (cost=60.85..121.97 rows=2260 width=8)
Hash Cond: (foo.a = foo_1.a)
-> Seq Scan on foo (cost=0.00..32.60 rows=2260 width=8)
-> Hash (cost=32.60..32.60 rows=2260 width=4)
-> Seq Scan on foo foo_1 (cost=0.00..32.60 rows=2260 width=4)
В случае с b, отложенное ограничение помешает оптимизации
EXPLAIN
SELECT *
FROM foo
WHERE b IN (
SELECT b FROM foo
);
QUERY PLAN
-------------------------------------------------------------------------
Hash Semi Join (cost=60.85..124.53 rows=2260 width=8)
Hash Cond: (foo.b = foo_1.b)
-> Seq Scan on foo (cost=0.00..32.60 rows=2260 width=8)
-> Hash (cost=32.60..32.60 rows=2260 width=4)
-> Seq Scan on foo foo_1 (cost=0.00..32.60 rows=2260 width=4)
Усложнение отладки
Получение ошибок только после завершения набора запросов усложняет отладку. Ошибка не позволяет точно определить, какой запрос вызвал проблему. Вы можете и не найти нужный запрос по сообщению об ошибке.
CREATE TABLE u (
i int UNIQUE DEFERRABLE INITIALLY IMMEDIATE
);
BEGIN;
SET CONSTRAINTS u_i_key DEFERRED;
INSERT INTO u (i) VALUES (1), (2);
-- ... другие SQL-запросы
INSERT intu u (i) VALUES (2), (3);
-- ... другие SQL-запросы
INSERT intu u (i) VALUES (3), (4);
COMMIT;
ERROR: 23505: duplicate key value violates unique constraint "u_i_key"
DETAIL: Key (i)=(2) already exists.
В данном случае сообщение даёт достаточно информации, чтобы найти проблемный запрос, но может быть и более сложный случай без конкретных значений.
Ошибки во время фиксации транзакции могут не только сбить с толку, но и внести погрешность в ORM. DataMapper предназначены для упрощенного доступа к СУБД и не все могут правильно обработать ошибки ограничений на уровне транзакций.
Так же любая работа выполненная после отложенного ограничения может быть в итоге потеряна, после отката транзакции. Отложенные ограничения могут тратить CPU впустую.
Откладывание ограничения по столбцу
Последний трюк для развлечения.
Команда SET CONSTRAINTS принимает имя ограничения. Но может быть удобнее отложить ограничения по столбцам. PostgreSQL information_schema позволяет искать ограничения по столбцам.
CREATE VIEW deferrables AS
SELECT table_schema, table_name, column_name,
conname, contype
FROM
pg_constraint,
information_schema.constraint_column_usage
WHERE constraint_name = conname
AND condeferrable = TRUE;
-- Отложить все ограничения для столбца
CREATE FUNCTION defer_col_constraints(
t_name information_schema.sql_identifier,
c_name name
) RETURNS void AS $$
DECLARE
names text;
BEGIN
names := (
SELECT array_to_string(array_agg(conname), ', ')
FROM deferrables
WHERE table_name = $1
AND column_name = $2
);
EXECUTE format(
'SET CONSTRAINTS %s DEFERRED',
names
);
END;
$$ LANGUAGE plpgsql;
В примере выше мы могли бы использовать данную функцию для того чтобы отложить ограничения по столбца child и parent_id.
BEGIN;
SELECT defer_col_constraints('child', 'parent_id');
-- ...
COMMIT;
