
Из этого поста вы узнаете, зачем добавлять в интеграционный слой бизнес-логику, что случается, когда «не летит» Service mesh, и почему иногда костыли — лучшее решение проблемы.

Привет Хабр, на связи Иван Большаков — архитектор интеграционных решений, эксперт департамента разработки ПО КРОК. Я расскажу, как мы делали интеграционный слой для CRM-системы группы контакт-центров торговой сети Пятерочка.
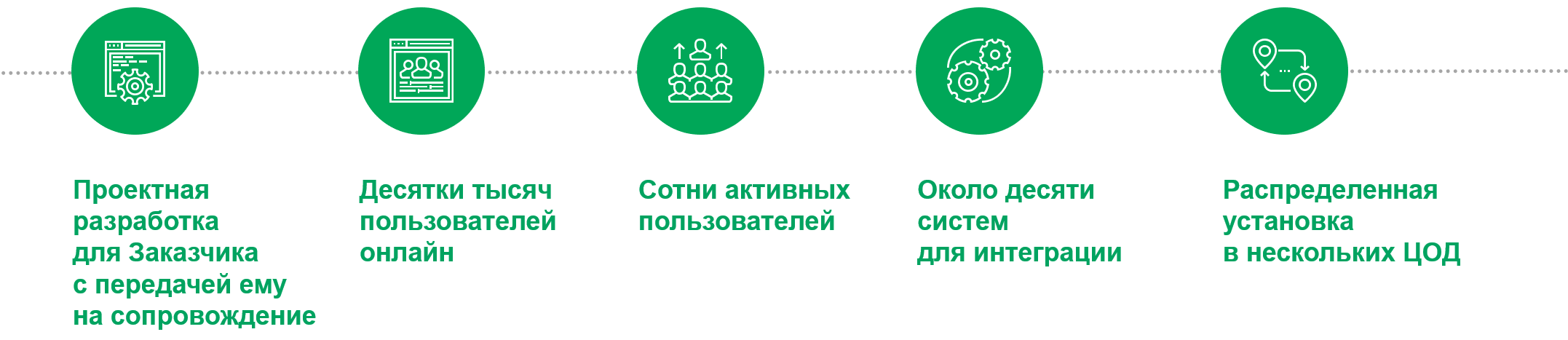
Всего в системе одновременно находятся десятки тысяч пассивных пользователей с открытыми интерфейсами и сотни активных, которые пишут в чаты, принимают звонки и нажимают на кнопки. Операторы одновременно работают с десятком различных систем…
На старте разработки контакт-центры Пятерочки располагались на 7 разных площадках. И все они использовали разные решения для учета звонков: платформы дискретных каналов, обработки обращений и т. д. Решения по обращениям велись в отдельной системе, а уведомления по обращениям делались в ручном режиме.
Между этими системами не было интеграций, так что операторы переключались между окнами, копировали номера телефонов, искали профили клиентов и выполняли массу других рутинных действий.
Все это замедляло обработку обращений и увеличивало время реакции в каждом конкретном случае. Операторы просто не могли решить проблему клиента здесь и сейчас. Вместо этого они тратили силы и время на то, что стоило бы автоматизировать.
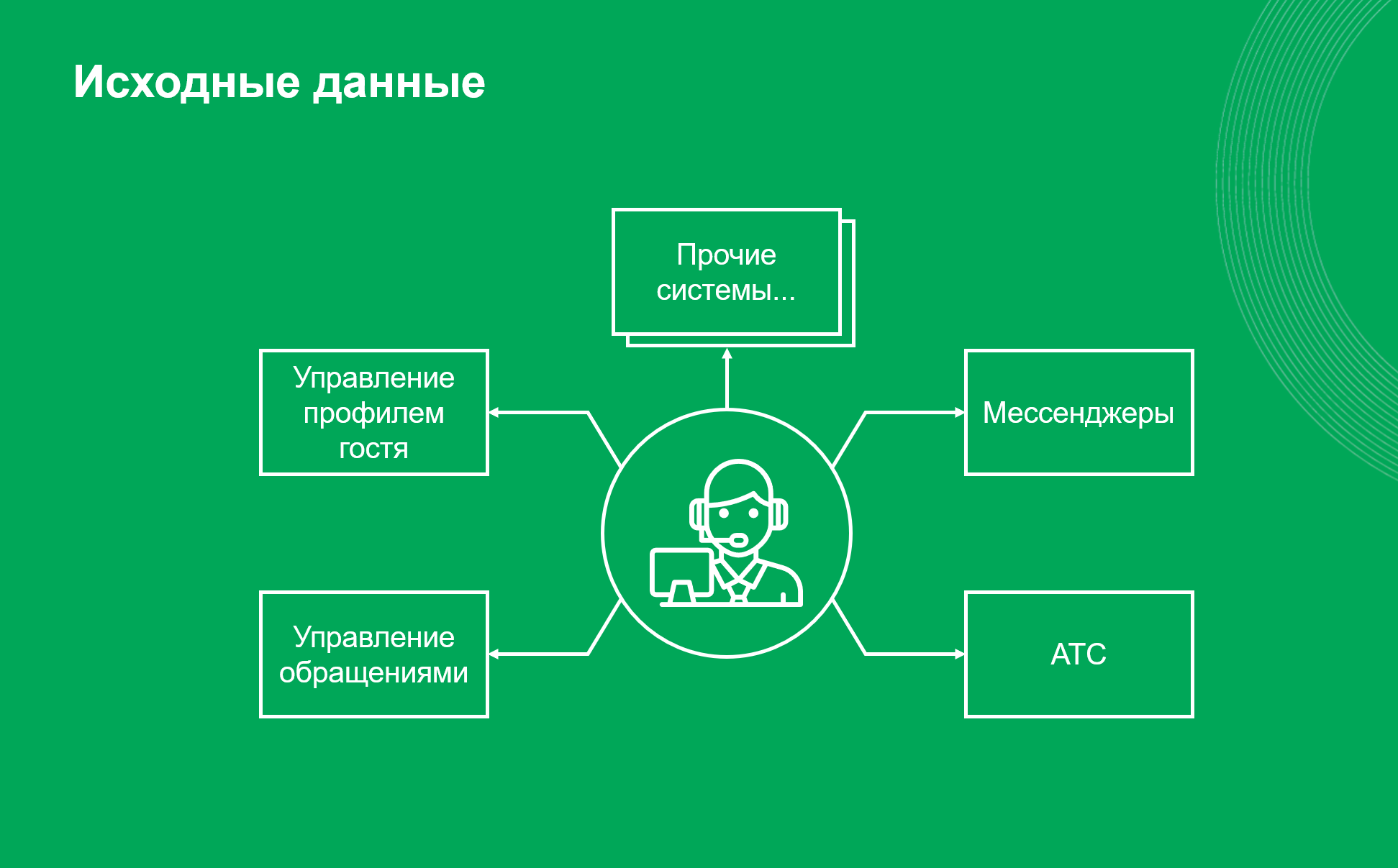
Сотрудники контакт-центров справлялись с работой и могли бы продолжать в том же духе, но заказчик подсчитал, во сколько обходится эта рутина, и уже не мог спать спокойно.
Возможные решения
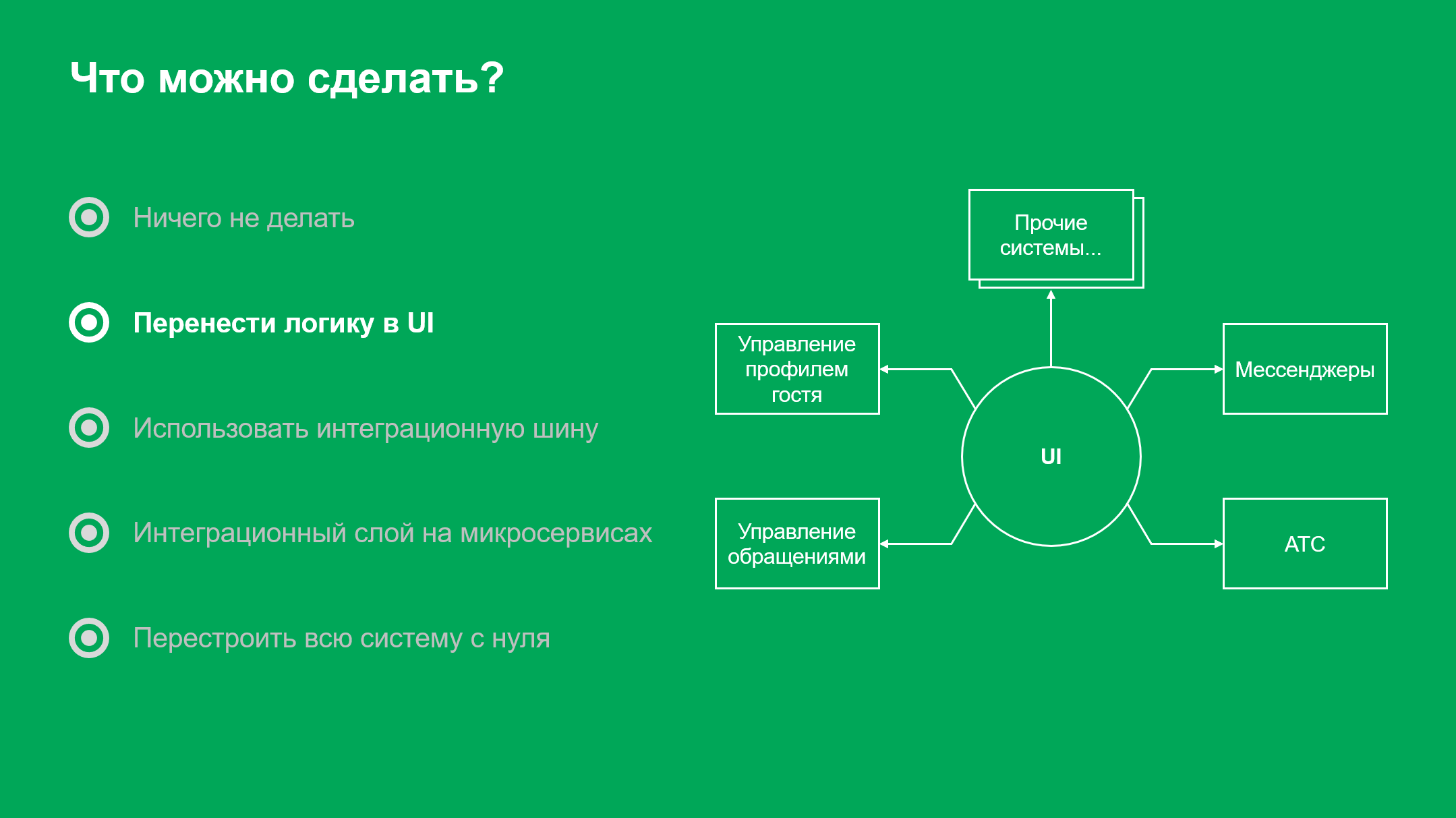
Первое решение, которое мы рассматривали, — перенести логику в веб-приложение оператора контакт-центра. То есть, сделать UI, который будет вызывать методы на бэкендах тех или иных систем.
Логичный выход, который решит проблему заказчика, но не дает дополнительных преимуществ.

Другой вариант — enterprise service bus. Это классический сценарий интеграции: разработать пользовательский интерфейс, подключить его к опубликованным на интеграционной шине методам и наслаждаться жизнью.
Но ESB в 2020 году — уже не самое популярное решение. К тому же, заказчику хотелось реализовать дополнительную функциональность, например, подсистему отчетности, а она требует разработки бэкенда.
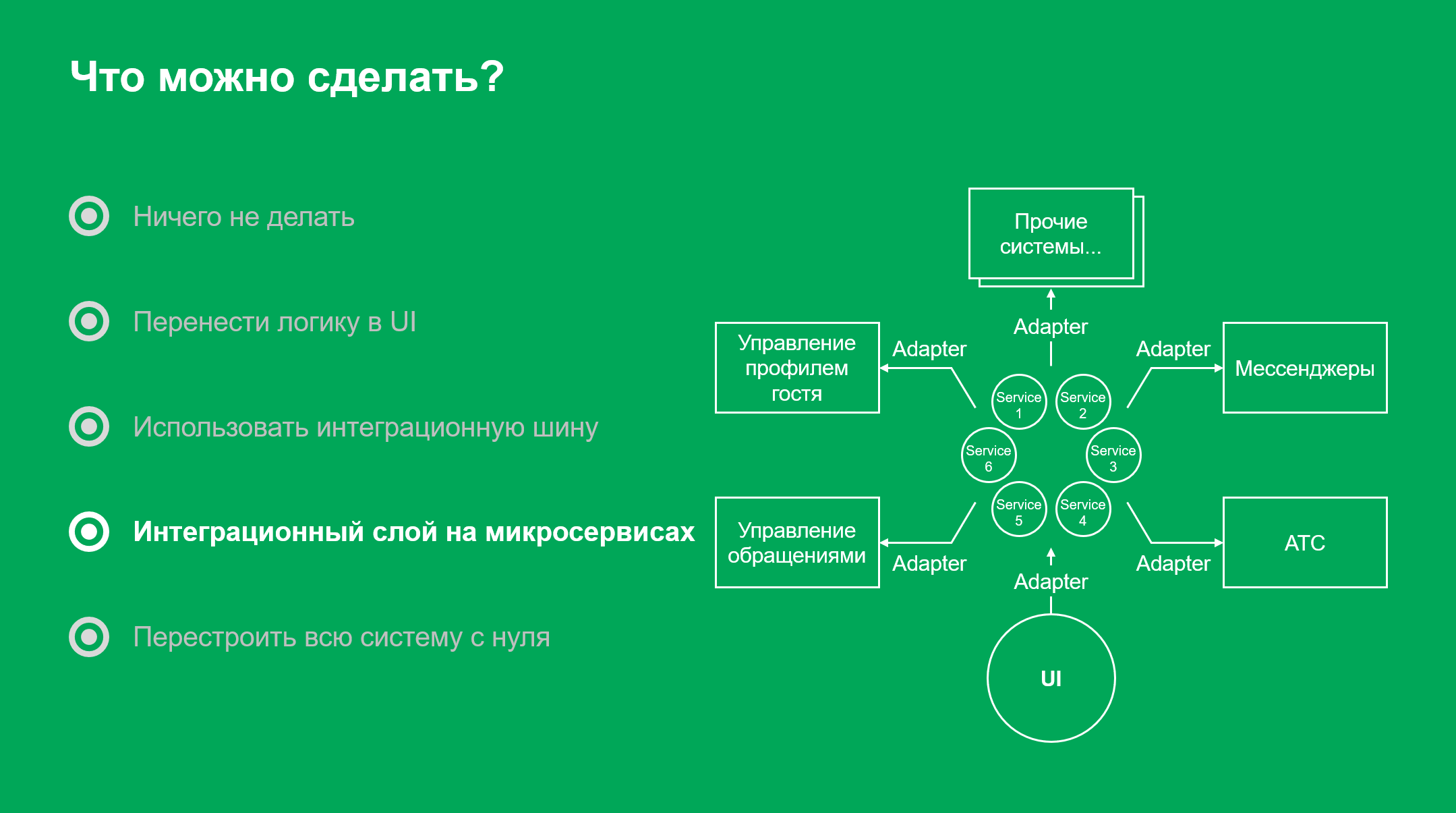
Мы решили использовать для интеграционного слоя микросервисы. Они позволяют реализовать дополнительную бизнес-логику и обеспечивают масштабируемость. Их проще распределить по нескольким ЦОД, по сравнению с ESB.
Кроме того, интеграционный слой на базе микросервисов можно передавать постепенно, с развитием на стороне заказчика.
Архитектура интеграционного слоя
Опыт разработки микросервисов подсказывал нам, что не стоит требовать радикальной доработки информационных систем на стороне заказчика.
Нет гарантий того, что к концу проекта состав и интеграционные контракты систем, с которыми мы работаем, останутся прежними. У Пятерочки несколько контакт-центров от разных подрядчиков, и они могут сменить их в любой момент. Так что, интеграционный слой должен минимально влиять на окружающие системы.
Мы использовали стандартный прием — спроектировали интерфейсы, написали адаптеры для каждой системы и связали их с нашим ядром через законтрактованный API.
Так как в интеграционный слой попала бизнес-логика, выбор пал на событийно-ориентированную архитектуру. В ней проще следить за согласованностью данных.
Проектируя архитектуру интеграционного слоя, мы старались не переусложнять, ведь микросервисность — не самоцель проекта.
Мы не разделяли по сервисам компоненты, которые будут дорабатываться или масштабироваться вместе. Если можно было разрабатывать в составе одного сервиса несколько бизнес-сущностей, — мы это делали. И все равно, в итоге получилось больше 30 микросервисов.
Вся сложность во взаимодействиях
С внешними системами было просто. Мы не могли ничего менять, так что использовали те API, которые они предоставляли.

Внутри системы мы выделили два типа взаимодействий: модифицирующие и читающие. Модифицирующие воздействия реализовали при помощи обмена сообщениями через топики в Kafka. Каждому сервису присвоили топик, который начинается с его имени. Сервис отправляет туда сообщения обо всех событиях, произошедших с его объектами:
«с бизнес-сущностью, которую обрабатывает сервис user, что-то произошло, вот ее новые данные»
Этот топик читают другие сервисы. Они реагируют на изменения и отписываются в свои топики. Так действие пользователя по каскаду распространяется по всей системе.
Это удобно, ведь при необходимости можно перечитать данные из Kafka, и, если что-то пойдет не так, откатить транзакции сразу в нескольких сервисах.
Как видите, вместо оркестрации мы остановились на хореографии. В нашей системе нет центрального сервиса, в котором закожены бизнес-процессы. Они складываются из множества мелких взаимодействий. Кусочек бизнес-логики заложен в каждом сервисе.
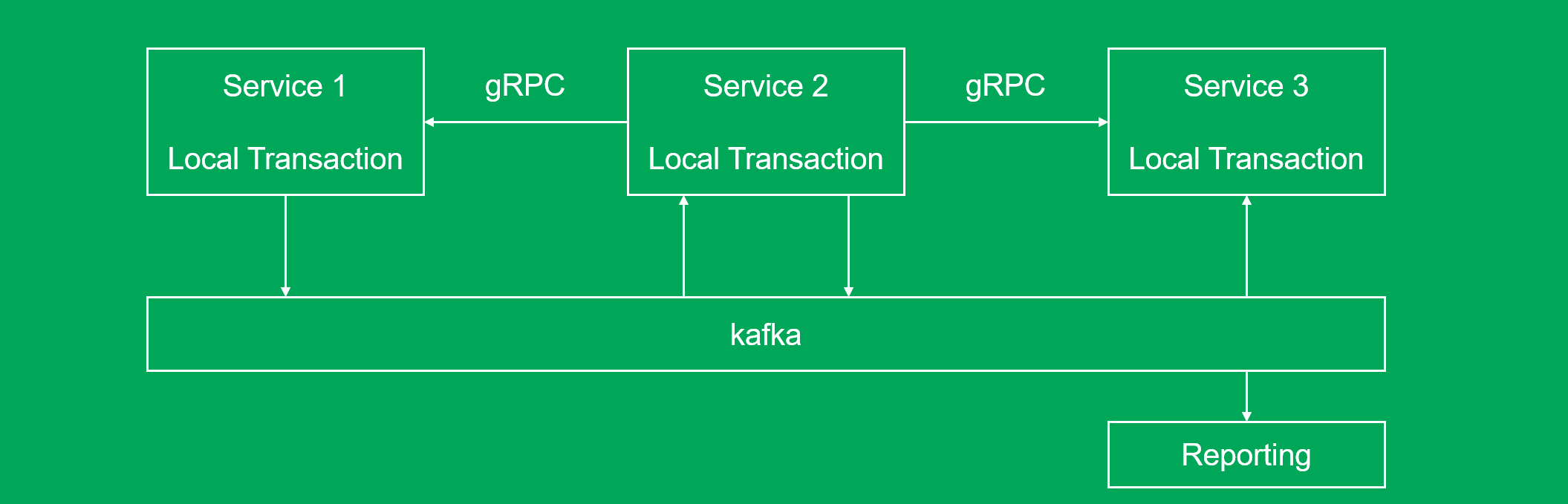
Читающие взаимодействия идут по gRPC. Мы выбрали этот протокол не из-за фич типа стриминга (их пока не используем), а потому, что с его помощью удобно управлять контрактами.
Там, где согласованность не нужна, по gRPC идут и модифицирующие взаимодействия. Так мы снизили сложность системы и сэкономили время разработчиков.
Kafka и очереди сообщений
Мы использовали Kafka в качестве брокера сообщений, потому что купились на отказоустойчивость. Между ЦОДами, где расположены системы заказчика, небольшие задержки, так что она работает неплохо. Однако, где-то в середине проекта мы поняли, что просчитались.

Потребовалась приоритизация сообщений. Нужно было сделать так, чтобы сообщения из одного топика читались, только когда все вычитано из другого. Вообще, приоритизация — стандартная вещь, которая есть хоть в каком-то виде в любом брокере, но Kafka — не брокер.
Для последовательного чтения пришлось прикрутить некрасивый костыль, который проверяет отставание офсета в первом топике и разрешает чтение из другого. Если бы мы использовали RabbitMQ, было бы проще, но, возможно, возникли бы вопросы относительно производительности.
Взаимодействие с фронтом
Здесь обошлось без rocket science. Взаимодействие с фронтом мы выстроили при помощи WebSocket и REST. WebSocket нужен для передачи событий от бека к фронту и высоконагруженных управляющих взаимодействий, а REST — для запроса данных. Правда, пришлось написать отдельный микросервис для фронтенд-разработчиков.

Ходить за несколькими сущностями в три разных сервиса, а потом собирать на фронте какую-то адекватную модель для представления не очень удобно. Куда удобнее использовать composer, который будет брать сразу несколько сущностей со связями между ними и компоновать в один JSON. Для этого отлично подошел Apache Camel. Правда, в следующий раз мы не станем заморачиваться с REST и используем graphQL.
Service mesh и безопасность
Service mesh нужен, чтобы не прописывать вручную всю логику межсервисных взаимодействий. Как правило, для соединения микросервисов мы используем Istio и в этом проекте тоже рассчитывали на эту платформу. Но в этом году все идет как-то не так, как ожидалось.
Мы столкнулись с такой версией OKD, на которую никак не получалось установить Istio. Заказчик собирался в будущем обновить систему оркестрации, но нам нужно было решение здесь и сейчас.
Дедлайн приближался, а инженеры не знали, когда мы справимся с проблемой. Пришлось минимизировать риски и сделать какое-то подобие service mesh, чтобы точно запуститься вовремя.
Конечно, полноценный service mesh на коленке не напишешь, но можно было обойтись без управления трафиком, а мониторинг настроить вручную. Главное, что нам нужно было от service mesh, — это безопасность.

Было необходимо идентифицировать запросы от фронта к бекенду, проверять токены пользователей в каждом микросервисе и делать запросы GET, POST и так далее, в зависимости от роли в токене.
Итак, мы начали пилить собственный service mesh. В его основу легла простая идея: если нельзя (не хочется) поместить логику в код сервиса, сделаем внешний sidecar-контейнер по аналогии с Istio, использовав OpenResty и язык Lua.
Написали в контейнере код, который проверяет подпись токена. В качестве параметров к нему подкладываются правила, описывающие, какие запросы пропускать от пользователей с различным ролями.
Аудит
Теперь, когда у нас были sidecar, на них можно было повесить отправку данных в Kafka и реализовать бизнесовый аудит. Так заказчик будет знать, кто из пользователей системы изменял те или иные важные данные.

Существуют штатные библиотеки для работы с Kafka, но и с ними возникли проблемы. Все ломалось, как только для подключения к Kafka требовался SSL. Спас положение старый добрый kafka-console-producer, который лежит в каждом sidecar и вызывается с параметрами из nginx.
Получился рабочий «почти-service mesh». Казалось бы, можно было расслабиться, но мы чуть не упустили еще одну важную вещь.
Балансировка gRPC
gRPC то работает на HTTP/2, а этот протокол устанавливает соединение и держит, пока оно не порвется. Возможна ситуация, когда инстанс сервиса «A» намертво прицепится к одному из инстансов сервиса «B» и будет направлять все запросы только на него. Тогда от масштабирования сервиса «B» не будет толка. Второй инстанс сервиса «B» останется не нагружен и будет впустую тратить процессорное время и память.

Мы могли сделать полноценную балансировку на клиентской стороне, но было бы неправильно тратить на это время. После внедрения полноценного service mesh эти наработки потеряют актуальность.
Поэтому мы реализовали перехват и подсчет всех вызовов gRPC на уровне кода на стороне клиента. Когда счетчики подходят к определенному значению, вызывается метод, приводящий к переустановке соединения, и балансировщик OKD задействует незагруженный инстанс сервиса «B».
Конечно, не стоит повторять это идеальных условиях, но если возникли неожиданные препятствия, и нужно срочно запуститься, — это решение имеет право на жизнь. Такая балансировка работает. Графики нагрузки по сервисам ровные.
Управление версиями
Напоследок, несколько слов о том, как мы управляли версиями кода.
В проекте задействованы Spring, Maven и Java. Каждый микросервис хранится в собственном микрорепозитории. В первую очередь потому что мы передавали систему заказчику по частям, сервис за сервисом.
Поэтому единой версии коммита для всей системы нет. Но, когда шла активная разработка, нам нужен был механизм контроля версий. Без него систему не получится целостно протестировать, выкатить на стейдж, а затем и на прод.

Прежде всего, мы стали собирать сервисы в образы, которые тегируются коротким хешем коммита. А внутри Maven проекта нет версионирования кода, там вместо версии мы использовали заглушку.
Затем мы выделили отдельный репозиторий со списком всех сервисов и их версиями. Коммит в этот репозиторий и назывался релизом. То есть, мы формировали манифест совместимых между собой версий микросервисов. Конечно, не руками, а через самодельные веб-интерфейсы.
Еще один момент, который стоит упомянуть, — управление версиями интеграционных контрактов между сервисами.
Если сервис «A» и сервис «B» общаются по gRPC, и разработчик сервиса «B» исправит что-то в протофайле и сломает обратную совместимость, это выстрелит только, когда выйдет в рантайм. Слишком поздно. Поэтому мы храним все интеграционные контракты (протофайлы, классы для сериализации Kafka и т. д.) отдельно и подключаем как саб-модули. Благодаря этому решению, многие возможные проблемы проявляются на этапе компиляции.
Что мы вынесли из проекта
В этом проекте мы вновь убедились в том, как важно заранее обследовать инфраструктуру. Но даже после тщательной проверки нельзя расслабляться. Некоторые проблемы, типа несовместимости конкретной версии OKD с Istio, практически невозможно предвидеть.
В конечном счете мы рады, что не переусердствовали в разделении на бизнес-сущности и не разобрали систему на винтики. Можно было разбить каждый микросервис еще на три, но это ничего не дало бы заказчику. Архитектура операционной CRM контакт-центра и так смотрится достаточно красиво, и мы потратили на разработку в полтора раза меньше времени, чем могли бы.
Если подвести итог, то интеграция без ESB имеет право на жизнь, особенно, когда нужно решить задачу в сжатые сроки.
Если у вас появились вопросы, или вы знаете, как красиво сделать приоритизацию сообщений в Kafka, пишите в комментариях или на почту IBolshakov@croc.ru.
