
В первой части Разработка стековой виртуальной машины и компилятора под неё (часть I) сделал свою элементарную стековую виртуальную машину, которая умеет работать со стеком, делать арифметику с целыми числами со знаком, условные переходы и вызовы функций с возвратом. Но так как целью было создать не только виртуальную машину, но и компилятор C подобного языка, пришло время сделать первые шаги в сторону компиляции. Опыта никакого. Буду действовать по разумению.
Одним из первых этапов компиляции является лексический разбор исходного кода нашего "C подобного языка" (кстати, надо какое-то название дать как только он станет более формальным). Задача простая - "нарубить" массив символов (исходный код) на список классифицированных токенов, чтобы последующий синтаксический разбор и генерация кода не вызывали сложности.
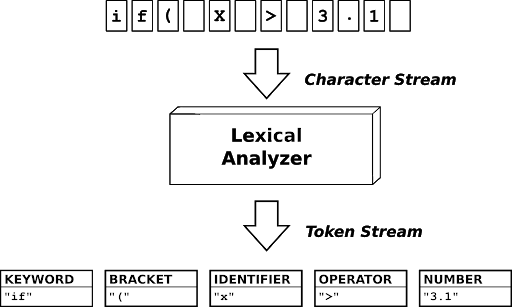
Итак, первый шаг - определиться с типами токенов, символами которые будут отделять токены друг от друга, а также определить структуру для хранения токена (тип, текст токена, длина, строка и столбец в исходном коде). Интуитивно будем ориентироваться на синтаксис C.
constexpr char* BLANKS = "\x20\n\t";
constexpr char* DELIMETERS = ",;{}[]()=><+-*/&|~^!.";
enum class TokenType {
NONE = 0, UNKNOWN, IDENTIFIER,
CONST_CHAR, CONST_INTEGER, CONST_REAL, CONST_STRING,
COMMA, MEMBER_ACCESS, EOS,
OP_BRACES, CL_BRACES, OP_BRACKETS, CL_BRACKETS, OP_PARENTHESES, CL_PARENTHESES,
BYTE, SHORT, INT, LONG, CHAR, FLOAT, DOUBLE, STRING, IF, ELSE, WHILE, RETURN,
ASSIGN, EQUAL, NOT_EQUAL, GREATER, GR_EQUAL, LESS, LS_EQUAL,
PLUS, MINUS, MULTIPLY, DIVIDE, AND, OR, XOR, NOT, SHL, SHR,
LOGIC_AND, LOGIC_OR, LOGIC_NOT
};
typedef struct {
TokenType type;
char* text;
WORD length;
WORD row;
WORD col;
} Token;
Далее напишем класс для разбора, ключевым методом которого станет parseToTokens(char*). Тут алгоритм простой: идем до разделителя (BLANKS и DELIMETERS), определяем начало и конец токена, классифицируем его и добавляем в вектор (список) токенов. Особые случаи разбора - это отличать целые числа от вещественных, вещественные числа (например, "315.0") отличать от применения оператора доступа к членам структуры/объекта ("obj10.field1"), а также отличать ключевые слова от других идентификаторов.
void VMLexer::parseToTokens(const char* sourceCode) {
TokenType isNumber = TokenType::UNKNOWN;
bool insideString = false; // inside string flag
bool isReal = false; // is real number flag
size_t length; // token length variable
char nextChar; // next char variable
bool blank, delimeter; // blank & delimeter char flags
tokens->clear(); // clear tokens vector
rowCounter = 1; // reset current row counter
rowPointer = (char*)sourceCode; // set current row pointer to beginning
char* cursor = (char*)sourceCode; // set cursor to source beginning
char* start = cursor; // start new token from cursor
char value = *cursor; // read first char from cursor
while (value != NULL) { // while not end of string
blank = isBlank(value); // is blank char found?
delimeter = isDelimeter(value); // is delimeter found?
length = cursor - start; // measure token length
// Diffirentiate real numbers from member access operator '.'
isNumber = identifyNumber(start, length - 1); // Try to get integer part of real number
isReal = (value=='.' && isNumber==TokenType::CONST_INTEGER); // Is current token is real number
if ((blank || delimeter) && !insideString && !isReal) { // if there is token separator
if (length > 0) pushToken(start, length); // if length > 0 push token to vector
if (value == '\n') { // if '\n' found
rowCounter++; // increment row counter
rowPointer = cursor + 1; // set row beginning pointer
}
nextChar = *(cursor + 1); // get next char after cursor
if (!blank && isDelimeter(nextChar)) { // if next char is also delimeter
if (pushToken(cursor, 2) == TokenType::UNKNOWN) // try to push double char delimeter token
pushToken(cursor, 1); // if not pushed - its single char delimeter
else cursor++; // if double delimeter, increment cursor
} else pushToken(cursor, 1); // else push single char delimeter
start = cursor + 1; // calculate next token start pointer
}
else if (value == '"') insideString = !insideString; // if '"' char - flip insideString flag
else if (insideString && value == '\n') { // if '\n' found inside string
// TODO warn about parsing error
}
cursor++; // increment cursor pointer
value = *cursor; // read next char
}
length = cursor - start; // if there is a last token
if (length > 0) pushToken(start, length); // push last token to vector
}
Наряду с методом parseToTokens, помогать в разборе и классификации нам будут простые методы, определяющие разделители и тип найденного токена. Плюс метод добавления токена в вектор.
class VMLexer {
public:
VMLexer();
~VMLexer();
void parseToTokens(const char* sourceCode);
Token getToken(size_t index);
size_t getTokenCount();
WORD tokenToInt(Token& tkn);
private:
vector<Token>* tokens;
WORD rowCounter;
char* rowPointer;
bool isBlank(char value);
bool isDelimeter(char value);
TokenType pushToken(char* text, size_t length);
TokenType getTokenType(char* text, size_t length);
TokenType identifyNumber(char* text, size_t length);
TokenType identifyKeyword(char* text, size_t length);
};Попробуем используя класс VMLexer разобрать строку исходного кода C подобного языка (исходный код бессмысленный, просто набор случайных токенов для проверки разбора):
int main()
{
printf ("Wow!");
float a = 365.0 * 10 - 10.0 / 2 + 3;
while (1 != 2) {
abc.v1 = 'x';
}
if (a >= b) return a && b; else a || b;
};В итоге получаем в консоли следующий перечень классифицированных токенов:

Отлично, у нас есть базовый лексер. Теперь его надо как-то применить. Например, осуществить синтаксический разбор арифметического выражения и сгенерировать код для виртуальной машины по следующим правилам:

Для простоты сначала реализуем примитивный компилятор арифметических выражений с целыми числами по приведенным выше правилам. Синтаксический разбор выражения и генерацию кода (два в одном) напишем вот так:
void VMCompiler::parseExpression() {
Token tkn;
parseTerm();
tkn = lexer->getToken(currentToken);
while (tkn.type==TokenType::PLUS || tkn.type==TokenType::MINUS) {
currentToken++;
parseTerm();
if (tkn.type == TokenType::PLUS) {
destImage->emit(OP_ADD);
} else {
destImage->emit(OP_SUB);
}
tkn = lexer->getToken(currentToken);
}
}
void VMCompiler::parseTerm() {
Token tkn;
parseFactor();
currentToken++;
tkn = lexer->getToken(currentToken);
while (tkn.type == TokenType::MULTIPLY || tkn.type == TokenType::DIVIDE) {
currentToken++;
parseFactor();
if (tkn.type == TokenType::MULTIPLY) {
destImage->emit(OP_MUL);
} else {
destImage->emit(OP_DIV);
}
currentToken++;
tkn = lexer->getToken(currentToken);
}
}
void VMCompiler::parseFactor() {
Token tkn = lexer->getToken(currentToken);
bool unaryMinus = false;
if (tkn.type == TokenType::MINUS) {
currentToken++;
tkn = lexer->getToken(currentToken);
unaryMinus = true;
}
if (unaryMinus) destImage->emit(OP_CONST, 0);
if (tkn.type == TokenType::OP_PARENTHESES) {
currentToken++;
parseExpression();
} else if (tkn.type == TokenType::CONST_INTEGER) {
destImage->emit(OP_CONST, lexer->tokenToInt(tkn));
}
if (unaryMinus) destImage->emit(OP_SUB);
}Попробуем передать компилятору выражение "-3+5*(6+2)*3+15/5", дизассемблируем сгенерированный код в консоль и сразу исполняем его на виртуальной машине. Ожидаем, что результат вычисления должен остаться на вершине стека - 120.

Ура! Получилось! Мы имеем простую, но рабочую виртуальную машину, лексер, компилятор целочисленных выражений с константами. Всё это очень воодушевляет!
P.S. Конечно, правильно было бы построить полноценное AST (abstract syntax tree), таблицу символов и много чего еще для удобной генерации кода, о чем узнал из комментариев, но первые шаги в сторону компилятора уже сделаны.
