Часть 2-ая

Всем привет, друзья! Писать приходится урывками, катастрофически не хватает времени. Вспомним краткое содержание предыдущей серии…
В первой части статьи, мы с вами идентифицировали алгоритм шифрования RC4 и расшифровали конфигурационные данные REvil. Не плохо вроде, но мало! Описанный в статье процесс получения конфига на самом деле достаточно простой и не долгий. Можно было вообще не заморачиваться с идентификацией алгоритма шифрования, найти нужно место в коде и просто сдампить в отладчике. И это иногда будет и проще, и быстрее! Когда планировал статью, признаться, не думал делить ее на части. Но на каждый этап деобфускации трачу слишком много букв и картинок, поэтому и решил всё же разделить, чтобы не перегружать. Получение данных конфигурации не являлось конечной целью, так что идем дальше. И без результатов первого этапа никак не обойтись.
Хочется подчеркнуть: то, о чем идет речь в статье, не привязана конкретно к семейству REvil, мы говорим об общих подходах к реверсу и деобфускации. Причем, выработав навыки, каждый выберет свою кратчайшую дорогу, и необязательно будет делать так, как написано здесь.
Одновременно с этим есть приятная возможность вскользь коснуться актуальной сейчас темы – программ-вымогателей. К слову сказать, на днях анализировал образец другого шифровальщика BlackMatter. Будем честными, по сути, это новый DarkSide, ребята слегонца "переобулись", несмотря на все их заявления в прессе. Хотя и сам факт интервью тоже вызывает некоторые сомнения. Когда появляется новый образец, ресерчеры сразу набрасываются на него, и начинается гонка, кто же быстрее опубликует результаты технического анализа. Соответственно для начала надо быстро деобфусцировать образец.
Для деобфускации BlackMatter, я использовал те же подходы, о которых идет речь в этой статье. Когда в голове есть готовый алгоритм решения задачи, она решается очень быстро. Говоря про алгоритмы, сразу вспомнились подготовительные курсы в МИИТ, правда, потом поступать туда не стал – передумал. Математику на курсах вела отличная бабуля, не раз закаленная в боях на математических фронтах. Чтобы проверить математическое мышление абитуриента, она на вступительном экзамене рассказывала ему следующий алгоритм кипячения воды: налить в чайник воды, зажечь газ, поставить чайник на плиту и дождаться закипания воды. После этого задавала абитуриенту вопрос: "А что делать, если в чайнике уже есть вода? Какие Ваши действия?". Томить не буду, ее правильный ответ был таков – вылить воду из чайника и свести задачу к уже известному алгоритму. Все логично! Математики – рациональные люди, не любят лишней работы.
К образцу BlackMatter обязательно вернемся позже, в части про деобфускацию вызовов функций API. Подход для него использовался немного другой, но наиболее часто используемый в подобных случаях. И он будет полезен.
Все скрипты, которые используются в статьях, я по мере изложения выкладываю на GitHub.
В данной части будем идти постепенно и поэтапно для выработки конечного кода скрипта.
Расшифровка строк
По результатам анализа содержимого функции шифрования/расшифровки rc4 обязательно устанавливаем ее тип (кнопка "Y" на имени). Благодаря этому IDA облегчит дальнейший анализ кода, связанного с этой функцией.

Вполне логично любопытство, где же еще используется функция rc4. Для этого соответственно смотрим список ссылок на нее (xrefs) (кнопка "X" на имени функции).
 на функцию rc4")
Функция load_cfg – это та самая функция, где содержался код проверки целостности данных конфигурации и осуществлялась их расшифровка. Помимо этого в ней также производится разбор параметров конфигурации, поэтому и дано соответствующее название – load_cfg. А вот sub_406461 незнакомая функция.

Как видим, функция просто представляет собой обертку rc4, причем IDA неплохо помогла с аргументами после установки типа для rc4. И благодаря этому несложно понять, что arg_0 содержит адрес некоего блока с данными, а arg_4 – позицию в этом блоке. То есть по указанной в arg_4 позиции в блоке arg_0 содержится ключ шифрования RC4 длиной key_len, за которым следом идут данные длиной data_len. Смотрим, где вызывается эта функция (xrefs).
 на функцию sub_406461")
123 раза – это достаточно много! Ради интереса посмотрим, как обстоят дела со строками программы (Shift-F12).
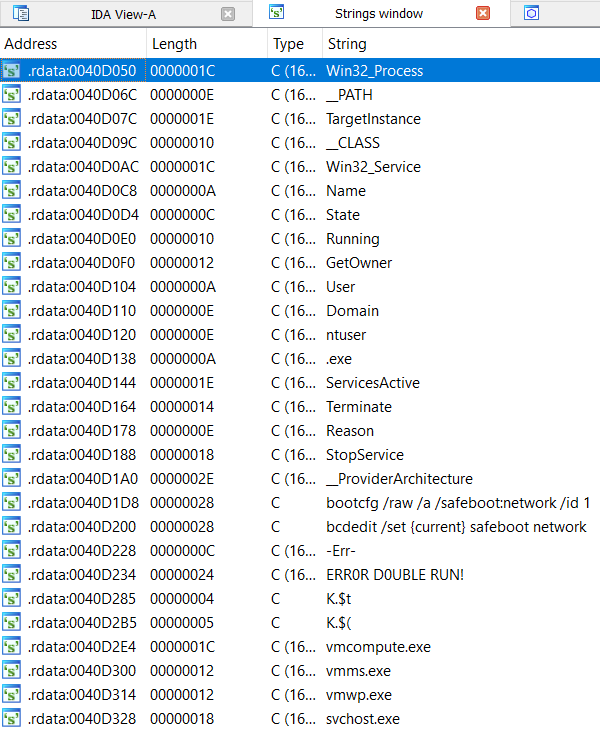
Маловато будет строк-то! Хотя некоторые из них крайне характерные и неприлично намекают на что-то явно нехорошее. Странно, что они в таком виде остались в программе. Авторы почему-то не захотели прятать их, но это, как говорится, дело хозяйское.
Вызовов функций шифрования/расшифровки sub_406461 много (123), а строк наоборот – мало. Ясное дело, что просто так не бывает, что где-то много, а где-то мало. Можно даже по этому поводу вывести закон сохранения количества строк программы. :-) Поэтому вряд ли ошибемся, если предположим, что функция sub_406461 предназначена для расшифровки строк программы.
Соответственно переименуем эту функцию как decrypt_str (или как кому заблагорассудится, не важно) и обязательно установим тип.

Расшифровка строк в знакомой уже функции load_cfg.

Обращаем еще раз внимание, как IDA после установки типа функции помогает с ее аргументами в коде вызова, добавляя комментарии с именами аргументов в места непосредственной передачи значений, а также при возможности еще и переименовывая переменные.

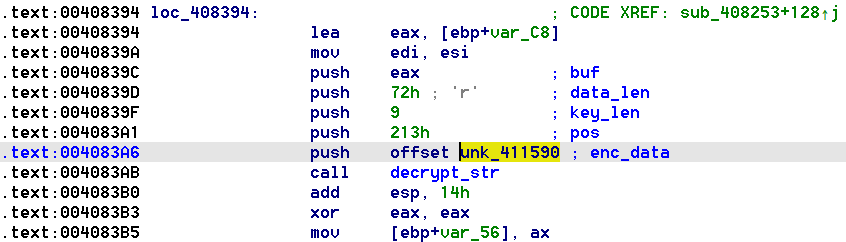
С принципом шифрования строк разобрались. Можно пойти в лоб: взять и 123 раза вручную расшифровать строки. Но лучше воспользоваться мощью IDAPython и написать скрипт, который сделает это автоматически. Для этого потребуется извлечь значения аргументов функции decrypt_str, указанные при каждом ее вызове: адрес блока зашифрованных данных (enc_data), позицию в блоке (pos), длину ключа шифрования (key_len) и длину зашифрованных данных (data_len). Далее по этим значениям расшифровать строки и указать их, например, в комментариях к соответствующим вызовам функции decrypt_str.
Для начала надо перечислить все вызовы функции decrypt_str (xrefs). Для этого можно воспользоваться функцией-генератором CodeRefsTo (модуль idautils). Простой пример ниже выведет адреса всех вызовов decrypt_str:
import idautils
for xref in CodeRefsTo(0x406461, 1):
print(hex(xref))Теперь необходимо получить значения аргументов функции decrypt_str. Посмотрим на код расшифровки строк на изображении выше. Функция decrypt_str имеет декларацию вызова __cdecl, в которой аргументы передаются через стек справа налево, а стек после завершения функции очищается кодом вызывающей функции. По адресу 401623h стек очищается сразу для 4-х вызовов функции decrypt_str. Можно, кстати, даже проверить: 50h (80) в стеке на 4 вызова, что соответствует размеру аргументов – 20 байт, то есть пяти 32-битным значениям (DWORD) аргументов, что действительно соответствует истине. Если для функции корректно указан тип, IDA правильно распознает аргументы функции и определит адреса инструкций, с помощью которых осуществляется непосредственная передача значений аргументов. Для __cdecl, скорее всего, это будет инструкция push, но может быть и mov в зависимости от использованного разработчиками компилятора, например, GCC "балует" таким. Информацию об аргументах функции можно получить и в IDAPython с помощью функции get_arg_addrs (модуль idaapi), которая возвращает для указанного адреса вызова функции список с адресами инструкций передачи соответствующих значений аргументов. Использование get_arg_addrs не обязательно, но с помощью нее намного легче парсить значения аргументов функции.
Как видим на изображении выше непосредственные значения первых аргументов (enc_data, pos, key_len) помещаются в стек с помощью инструкции push, а вот значение data_len передается с помощью регистра edi. Такая передача аргумента data_len обусловлена, возможно, некоторой оптимизацией кода компилятором. Три последние зашифрованные строки на изображении имеют одинаковый размер (3), поэтому компилятор решил использовать регистр, который не изменяется после выполнения функции decrypt_str. Таким регистром оказался edi, но мог быть и esi или ebx. Компилятор поместил в edi значение 3 через стек, воспользовавшись двумя инструкциями:
push 3
pop ediТакой код создан компилятором, это могла быть оптимизация программы по размеру или просто такой код генерится компилятором по умолчанию для таких случаев. Этот код занимает 3 байта при условии, что константа находится в диапазоне от -128 до 127, вместо 5 байт, если воспользоваться инструкцией mov:
mov edi, 3Это все прекрасно, конечно, но такой вариант установки значения регистра через стек придется учитывать, чтобы извлечь значение data_len. Другой проблемой стал еще такой код:

Теперь значение enc_data передается в функцию с помощью регистра esi, а адрес блока зашифрованных данных ему присваивается выше с помощью инструкции mov. Кроме того, оказалось, что используется не один блок зашифрованных данных, а целых два, но это уже не так критично.
В итоге напишем для скрипта IDAPython функцию получения значения аргумента get_arg_val. На вход функция получает адрес инструкции, осуществляющей передачу значения аргумента в функцию, а возвращает соответственно значение аргумента.
def get_arg_val(arg_ea):
inst = DecodeInstruction(arg_ea)
if (inst.itype != idaapi.NN_push):
return None
if (inst.ops[0].type == o_imm):
return inst.ops[0].value
if (inst.ops[0].type != o_reg):
return None
reg = inst.ops[0].reg
min_ea = get_func_attr(arg_ea, FUNCATTR_START)
ea = ida_bytes.prev_head(arg_ea, min_ea)
while (ea != BADADDR):
inst = DecodeInstruction(ea)
if (inst.ops[0].type == o_reg) and (inst.ops[0].reg == reg):
if (inst.itype == idaapi.NN_mov):
# mov reg, imm
if (inst.ops[1].type == o_imm):
return inst.ops[1].value
break
elif (inst.itype == idaapi.NN_pop):
# pop reg, push imm
ea2 = ida_bytes.prev_head(ea, min_ea)
if (ea2 == BADADDR):
break
inst = DecodeInstruction(ea2)
if (inst.itype == idaapi.NN_push):
if (inst.ops[0].type == o_imm):
return inst.ops[0].value
break
ea = ida_bytes.prev_head(ea, min_ea)
return NoneЛогика работы функции проста. Декодируем инструкцию передачи значения с помощью функции DecodeInstruction (модуль idautils), проверяем, что инструкция только push, если в качестве операнда используется непосредственное значение, извлекаем его и возвращаем. В ином случае должен использоваться регистр. Ищем использующую указанный регистр инструкцию mov с непосредственным значением или pop, перед которой находится инструкция push с непосредственным значением. Для этого с помощью функций prev_head (модуль ida_bytes) и DecodeInstruction (модуль idautils) перечисляются в обратном порядке и декодируются инструкции до успешного получения значения или достижения начала вызывающей функции.
Если посмотреть на код, может возникнуть ощущение некоторой "костыльности" в нем. Увы, мне иногда кажется, что реверсерами становятся неудавшиеся программисты. Тут важно понять, что мы пишем скрипт – вспомогательный инструмент для деобфускации с целью дальнейшего анализа кода программы, а не какую-то новую программу. Код скрипта не обязан быть очень красивым, прежде всего, он должен быть рабочим, аккуратным и по делу эффективным, а время, затраченное на его разработку, не должно быть большим. Иначе будет проще вручную расшифровать 123 строки. Короче говоря, КПД процесса разработки скрипта должен быть высоким. Но при этом я все же стараюсь писать с некоторой долей перфекционизма, предполагая, что этот скрипт, возможно, станет источником для быстрой разработки нового скрипта уже для другого подобного случая. Писать следует аккуратно, добавляя по возможности комментарии, чтобы потом не вспоминать, почему сделано так, а не иначе. А забывается все, поверьте, очень быстро!
Код расшифровки строки:
def decrypt_str(call_ea):
arg_addrs = idaapi.get_arg_addrs(call_ea)
if (arg_addrs is None):
return None
arg_vals = list(range(4));
for i in range(4):
arg_vals[i] = get_arg_val(arg_addrs[i])
if arg_vals[i] is None:
return None
enc_data_ea = arg_vals[0] + arg_vals[1]
key = ida_bytes.get_bytes(enc_data_ea, arg_vals[2])
enc_data = ida_bytes.get_bytes(enc_data_ea + arg_vals[2], arg_vals[3])
dec_data = rc4.rc4(enc_data, key)
if (len(dec_data) == 0):
return ''
if (len(dec_data) & 1) or (dec_data[1] != 0):
return dec_data.decode()
return dec_data.decode('UTF-16')Извлекаем, если получается, необходимые значения аргументов функции расшифровки строки decrypt_str, далее расшифровываем с помощью RC4 строку. А далее видим еще один "костыль", связанный уже как раз с использованием двух блоков зашифрованных данных (410278h и 411590h), что отметили выше. Почему же блоков 2? Все просто! Выяснилось, что один блок содержит Unicode-строки, а другой – обычные. Поэтому ничего более оригинального я не придумал, как определять Unicode-строку по четной длине и первому нулевому байту, что в принципе справедливо для латиницы в Unicode. При этом учитывал, что строки не имеют завершающих нулевых символов (L'\0' и '\0').
Теперь основной код скрипта с циклом перечисления адресов вызовов функции decrypt_str:
DECRYPT_STR_FUNC_EA = 0x406461
DECRYPT_STR_FUNC_NAME = 'decrypt_str'
DECRYPT_STR_FUNC_TYPE = \
'void * __cdecl decrypt_str(void *enc_data, unsigned int pos, ' \
'unsigned int key_len, unsigned int data_len, void *dest)'
ida_name.set_name(DECRYPT_STR_FUNC_EA, DECRYPT_STR_FUNC_NAME)
if SetType(DECRYPT_STR_FUNC_EA, DECRYPT_STR_FUNC_TYPE) == 0:
raise Exception('Failed to set type of ' + DECRYPT_STR_FUNC_NAME + '.')
auto_wait()
enc_str_count = 0
dec_str_count = 0
for xref in CodeRefsTo(DECRYPT_STR_FUNC_EA, 1):
enc_str_count += 1
dec_str = decrypt_str(xref)
if (dec_str is None):
print('%08X: Failed to decrypt string.' % xref)
continue
s = dec_str.encode('unicode_escape').decode().replace('\"', '\\"')
set_cmt(xref, '\"' + s + '\"', 1)
dec_str_count += 1
print(str(enc_str_count) + ' string(s) found.')
print(str(dec_str_count) + ' string(s) decrypted.')В скрипте устанавливаем имя функции decrypt_str и обязательно ее тип. После используем функцию auto_wait (модуль idc), чтобы дать возможность IDA отработать во всех местах вызова decrypt_str после установки ее типа. Иначе код ниже может отработать раньше, прежде чем IDA наведет "марафет". Расшифрованную строку выводим в виде комментария к вызову функции decrypt_str. В принципе, если бы зашифрованная строка имела конкретный адрес, что бывает довольно таки часто, целесообразно было бы добавить комментарий и туда, а заодно еще и переименовать переменную по этому адресу. В данном случае это смысла не имеет. Предварительно, чтобы было все красиво и корректно, кодируем escape-символы и экранируем кавычки в расшифрованной строке. Было бы совсем чудесно, пометить Unicode-строки, например, буквой L в начале, перед открывающей кавычкой. Нередко расшифрованные строки в том виде, как они есть, дополнительно еще сохраняю и в файл.
Правилом хорошего тона будет и вывод статистики, сколько всего строк найдено, сколько расшифровано, а также отображение ошибок расшифровки строк, чтобы была возможность оперативно поправить код.
Скрипт расшифровки строк полностью.
import idautils
import idaapi
import rc4
DECRYPT_STR_FUNC_EA = 0x406461
DECRYPT_STR_FUNC_NAME = 'decrypt_str'
DECRYPT_STR_FUNC_TYPE = \
'void * __cdecl decrypt_str(void *enc_data, unsigned int pos, ' \
'unsigned int key_len, unsigned int data_len, void *dest)'
def get_arg_val(arg_ea):
inst = DecodeInstruction(arg_ea)
if (inst.itype != idaapi.NN_push):
return None
if (inst.ops[0].type == o_imm):
return inst.ops[0].value
if (inst.ops[0].type != o_reg):
return None
reg = inst.ops[0].reg
min_ea = get_func_attr(arg_ea, FUNCATTR_START)
ea = ida_bytes.prev_head(arg_ea, min_ea)
while (ea != BADADDR):
inst = DecodeInstruction(ea)
if (inst.ops[0].type == o_reg) and (inst.ops[0].reg == reg):
if (inst.itype == idaapi.NN_mov):
# mov reg, imm
if (inst.ops[1].type == o_imm):
return inst.ops[1].value
break
elif (inst.itype == idaapi.NN_pop):
# pop reg, push imm
ea2 = ida_bytes.prev_head(ea, min_ea)
if (ea2 == BADADDR):
break
inst = DecodeInstruction(ea2)
if (inst.itype == idaapi.NN_push):
if (inst.ops[0].type == o_imm):
return inst.ops[0].value
break
ea = ida_bytes.prev_head(ea, min_ea)
return None
def decrypt_str(call_ea):
arg_addrs = idaapi.get_arg_addrs(call_ea)
if (arg_addrs is None):
return None
arg_vals = list(range(4));
for i in range(4):
arg_vals[i] = get_arg_val(arg_addrs[i])
if arg_vals[i] is None:
return None
enc_data_ea = arg_vals[0] + arg_vals[1]
key = ida_bytes.get_bytes(enc_data_ea, arg_vals[2])
enc_data = ida_bytes.get_bytes(enc_data_ea + arg_vals[2], arg_vals[3])
dec_data = rc4.rc4(enc_data, key)
if (len(dec_data) == 0):
return ''
if (len(dec_data) & 1) or (dec_data[1] != 0):
return dec_data.decode()
return dec_data.decode('UTF-16')
ida_name.set_name(DECRYPT_STR_FUNC_EA, DECRYPT_STR_FUNC_NAME)
if SetType(DECRYPT_STR_FUNC_EA, DECRYPT_STR_FUNC_TYPE) == 0:
raise Exception('Failed to set type of ' + DECRYPT_STR_FUNC_NAME + '.')
auto_wait()
enc_str_count = 0
dec_str_count = 0
for xref in CodeRefsTo(DECRYPT_STR_FUNC_EA, 1):
enc_str_count += 1
dec_str = decrypt_str(xref)
if (dec_str is None):
print('%08X: Failed to decrypt string.' % xref)
continue
s = dec_str.encode('unicode_escape').decode().replace('\"', '\\"')
set_cmt(xref, '\"' + s + '\"', 1)
dec_str_count += 1
print(str(enc_str_count) + ' string(s) found.')
print(str(dec_str_count) + ' string(s) decrypted.')Итак, результаты выполнения скрипта…

Как видим, скрипт успешно расшифровал все 123 строки. Надо отметить, что скрипт будет работоспособен и в только что открытом в дизассемблере образце, так как производит сам все необходимые действия для расшифровки строк.
Тот же самый фрагмент кода из функции load_cfg, что был выше.

Удобно посмотреть все расшифрованные строки в окне со списком ссылок (xrefs) на функцию decrypt_str.
 на функцию decrypt_str с расшифрованными строками")
Хочется еще раз отметить, что средства автоматизации, такие как IDAPython, должны облегчать жизнь, а не усложнять и добавлять в нее новые проблемы. И в связи с этим не могу не вспомнить одного товарища, своего бывшего коллегу. У него редкий дар: он любую поставленную задачу умеет раскладывать на подзадачи, причем каждая из этих подзадач сложнее первоначальной задачи. Потом, он начинает искать тех, кто поможет ему решить эти подзадачи... Так вот! Это не наши методы!
