Сталкивались ли вы когда-либо с проблемой в обучении нейросетей, когда датасет слишком большой, чтобы загрузить его в оперативную память полностью и программа выдает Out-of-Memory Error? Например, при обучении классификатора изображений, у нас нет возможности загрузить все картинки в память до обучения. Даже если это и возможно для игрушечных наборов данных, в реальных задачах объёмы данных измеряются в сотнях, тысячах гигабайт. И мы не можем использовать лишь часть датасета, так как качество обученной модели тоже упадёт. Конечно, у нас есть возможность использовать готовые инструменты (например ImageDagaGenerator в библиотеке Tensorflow), но такой подход работает только если у нас стандартные данные, такие как папки с файлами jpg/png или csv файлы. А что делать, если у нас несколько различных типов данных (например, входные данные - это изображения и их текстовое описание), или большое количество табличных данных, где, например, каждый файл это данные за один день? В этих случаях для загрузки и подготовки данных на вход модели придётся писать свой собственный генератор данных.
В данной статье я детально расскажу, как я создавал свой DataGenerator в Kaggle соревновании по определению наличия опухоли головного мозга по МРТ.
Итак, посмотрим на данные, которые нам предоставили. Для обучения у нас имеется 585 примеров. Каждый пример представляет собой МРТ скан в четырех режимах: Fluid Attenuated Inversion Recovery (FLAIR), T1-weighted pre-contrast (T1w), T1-weighted post-contrast (T1Gd), T2-weighted (T2). Скан в каждом режиме представляет собой набор одноканальных изображений в формате DICOM. Возьмем один из примеров и посмотрим разрешение и количество файлов для каждого режима:
from os import listdir
from os.path import isfile, join
import pydicom
examples = ['00000','00178']
for ex in examples:
p1, p2, p3, p4 = 'FLAIR', 'T2w', 'T1w', 'T1wCE'
base_path = f'/kaggle/input/rsna-miccai-brain-tumor-radiogenomic-classification/train/{ex}'
print(f'Образец №{ex}:')
for p in [p1, p2, p3, p4]:
onlyfiles = [f for f in listdir(f'{base_path}/{p}/') if isfile(join(f'{base_path}/{p}/', f))]
img = pydicom.read_file(f'{path}/{onlyfiles[0]}').pixel_array
print(f'Количество файлов в типе {p}: {len(onlyfiles)}, примеры файлов: {onlyfiles[:2]}, разрешение: {img.shape}')

Можно заметить, что количество изображений различно и в каждом режиме и в разных примерах. Теперь загрузим информации о классе каждого образца.
train_df = pd.read_csv("/kaggle/input/rsna-miccai-brain-tumor-radiogenomic-classification/train_labels.csv")
train_df.head()
Столбец ‘BraTS21ID’ означает номер образца, а ‘MGMT_value’ его класс. Добавим для удобства в качестве столбцов пути к каждому режиму образца. Эти столбцы понадобятся нам в дальнейшем.
train_df['FLAIR_path'] = '/kaggle/input/rsna-miccai-brain-tumor-radiogenomic-classification/train/' + train_df['BraTS21ID'].astype(str).str.zfill(5) + '/FLAIR/'
train_df['T1w_path'] = '/kaggle/input/rsna-miccai-brain-tumor-radiogenomic-classification/train/' + train_df['BraTS21ID'].astype(str).str.zfill(5) + '/T1w/'
train_df['T2w_path'] = '/kaggle/input/rsna-miccai-brain-tumor-radiogenomic-classification/train/' + train_df['BraTS21ID'].astype(str).str.zfill(5) + '/T2w/'
train_df['t1wCE_path'] = '/kaggle/input/rsna-miccai-brain-tumor-radiogenomic-classification/train/' + train_df['BraTS21ID'].astype(str).str.zfill(5) + '/t1wCE/'Анализируя полученную информацию, мы делаем вывод, что наш генератор должен приводить все образцы во всех режимах к одинаковому числу изображений и одинаковому разрешению. Одним из параметров генератора мы будем передавать нашу таблицу, откуда мы возьмем пути к папкам и значение (y), которое мы будем предсказывать.
Теперь поговорим о генераторе данных. Согласно документации Tensorflow Keras для наиболее безопасного распараллеливания и обучения желательно использовать класс tf.keras.utils.Sequence, так как он обеспечивает то, что сеть при обучении будет использовать каждый образец за эпоху один раз. Таким образом, нужно создать свой класс, унаследованный от класса Sequence. Необходимо реализовать и методы класса Sequence __getitem__ и __len__. Метод __getitem__ должен возвращать окончательный батч для подачи в сеть. Также при желании можно реализовать метод on_epoch_end для изменения датасета между эпохами.
Расмотрим код генератора для этой задачи (по этой ссылке можно найти весь код из статьи https://www.kaggle.com/fipoka2/generator-test):
import pydicom, re
import tensorflow as tf
class MRIDataGenerator(tf.keras.utils.Sequence):
def __init__(self, df, X_col, y_col, batch_size,
input_size= (256, 256), depth_size=64,
shuffle=True):
self.df = df.copy()
self.X_col = X_col
self.y_col = y_col
self.depth_size = depth_size
self.batch_size = batch_size
self.input_size = input_size
self.shuffle = shuffle
self.n = len(self.df)
def on_epoch_end(self):
if self.shuffle:
self.df = self.df.sample(frac=1).reset_index(drop=True)
def __get_input(self, path, target_size):
def _rescale(self, arr):
def _normalize(self, arr):
def __get_data(self, batches):
def __getitem__(self, index):Задача метода __getitem__ - это выдать один батч данных в формате (x, y), где x – это наши изображения в виде numpy.array размерности [batch_size, input_depth, input_height, input_width, num_channels].
def __getitem__(self, index):
batches = self.df[index * self.batch_size:(index + 1) * self.batch_size]
X, y = self.__get_data(batches)
return X, yВнутри этого метода мы вызываем вспомогательный метод __get_data, задача которого из полученной части данных, сформировать наши массивы. В зависимости от параметров, мы можем использовать все режимы (каналов в этом случае будет 4) или какой-то конкретный.
def __get_data(self, batches):
if self.X_col is None:
PATHS = ['FLAIR_path', 'T1w_path', 'T2w_path', 'T1wCE_path']
X_batch = []
for p in PATHS:
batch_part_path = batches[p]
X_batch.append(np.asarray([self.__get_input(x, self.input_size) for x in batch_part_path]))
y_batch = batches[self.y_col].values
X_batch = np.concatenate(X_batch, axis=4)
else:
path_batch = batches[self.X_col]
X_batch = np.asarray([self.__get_input(x, self.input_size) for x in path_batch])
y_batch = batches[self.y_col].values
return X_batch, y_batchСоздание numpy.array из одного режима происходит путем вызовов вспомогательного метода __get_input. Это ключевой метод генератора, формирующий массив для одного канала одного образца батча, остановимся на нём подробнее.
def __get_input(self, path, target_size):
scan3d = None
onlyfiles = [f for f in listdir(path) if isfile(join(path, f))]
filepatt = 'Image-{}.dcm'
digits = [int(re.search('\d+',i).group()) for i in listdir(path) if re.match(filepatt.format('\d+\\'),i)]
digits.sort()
onlyfiles = [filepatt.format(dig) for dig in digits]
center = len(onlyfiles) // 2
left = max(0, center - (self.depth_size // 2))
right = min(len(onlyfiles), center + (self.depth_size // 2))
onlyfiles = onlyfiles[left: right]
if len(onlyfiles) < self.depth_size:
img_shape = pydicom.read_file(f'{path}{onlyfiles[0]}').pixel_array.shape
add_z = self.depth_size - len(onlyfiles)
scan3d = np.zeros((add_z, target_size[0], target_size[1],1))
scans = []
for f in onlyfiles:
img = pydicom.read_file(f'{path}{f}')
img = img.pixel_array
img = self._rescale(img)
img = np.expand_dims(img, axis=-1)
img = tf.image.resize(img,(target_size[0], target_size[1])).numpy()
img = self._normalize(img)
scans.append(img)
if scan3d is not None:
return np.concatenate([np.array(scans), scan3d])
else:
return np.array(scans)Первым делом, мы упорядочиваем файлы в папке по возрастанию их номера. Это необходимо для корректного создания глубины объёмного изображения. Так как количество изображений в разных примерах и режимах различно, мы берем фиксированное параметризованное значение. Если изображений меньше фиксированного значения, мы добавляем по краям черные фоновые изображения (путем создания матрицы, заполненной нулями). Если же изображений больше, берем нужное количество из середины (по глубине) изображения.
Далее начинаем работать с каждым изображением. Данная работа состоит из трех этапов.
Масштабирование
Изменение размеров
Нормализация/стандартизация
Масштабирование необходимо, так как формат DICOM не использует стандартный масштаб пикселя от 0 до 255, как в обычных изображениях. Для этого используем вспомогательный метод rescale, который отмасштабирует каждый пиксель скана к значению 0-255.
def _rescale(self, arr):
arr_min = arr.min()
arr_max = arr.max()
if (arr_max - arr_min) == 0:
return arr
return (arr - arr_min) / (arr_max - arr_min)Далее нужно изменить разрешение изображения до указанного в параметрах. Для этого используем готовую функцию tf.image.resize из библиотеки TensorFlow. Последним шагом будет нормализация/стандартизация изображения. Для этого будем из каждого значения пикселя вычитать его среднее и делить на стандартное отклонение. Это важный этап, так как стандартизация входных данных может ускорить обучение и снизить вероятность застревания в локальных оптимумах.
def _normalize(self, arr):
img = arr - arr.mean()
# divide by the standard deviation (only if it is different from zero)
if np.std(img) != 0:
img = img / np.std(img)
return imgПосмотрим, как работает наш генератор. Для этого воспользуемся библиотекой imageio и склеим наши изображения в одном из образцов.
import imageio
from IPython.display import Image
def visualize_data_gif(images):
imageio.mimsave("/kaggle/working/1.gif", images, duration=5.0 / images.shape[0])
return Image(filename="/kaggle/working/1.gif", format='png')
gen = MRIDataGenerator(train_df, None, 'MGMT_value', 10, (256, 256), 64, True)
iterator = iter(gen)
data = next(iterator)[0] * 255
images = []
for i in range(4):
a = data[:,:,:,:, i]
images.append(np.stack([a,a,a], axis=4).reshape((*a.shape[:4], 3)))
val = np.concatenate(images, axis=3)
visualize_data_gif(val[5])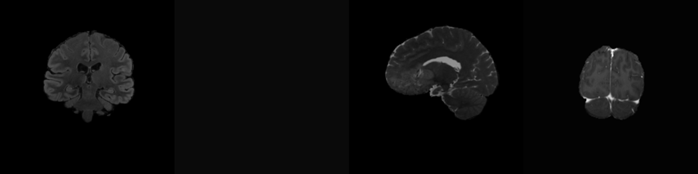
Мы убедились, что из исходных данных генератор корректно собирает объёмное изображение.
Теперь необходимо убедиться, что созданный нами класс корректно работает при обучении нейросети. Создадим простейшую свёрточную 3D нейросеть для классификации и используем наш генератор (из за ограничений используемого GPU возьмем только один режим FLAIR и снизим значения параметров).
depth = 64
resolution = (192, 192)
batches = 8
gen = MRIDataGenerator(train_df, 'FLAIR_path’, 'MGMT_value', batches, resolution, depth, True)
with tf.device('/gpu:0'):
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv3D, MaxPooling3D, Flatten, Dense
model = Sequential()
model.add(Conv3D(32, kernel_size=(3, 3, 3), activation='relu', kernel_initializer='he_uniform', input_shape=(64,192, 192, 1)))
model.add(MaxPooling3D(pool_size=(2, 2, 2)))
model.add(Conv3D(64, kernel_size=(3, 3, 3), activation='relu', kernel_initializer='he_uniform'))
model.add(MaxPooling3D(pool_size=(2, 2, 2)))
model.add(Conv3D(128, kernel_size=(3, 3, 3), activation='relu', kernel_initializer='he_uniform'))
model.add(MaxPooling3D(pool_size=(2, 2, 2)))
model.add(Conv3D(256, kernel_size=(3, 3, 3), activation='relu', kernel_initializer='he_uniform'))
model.add(MaxPooling3D(pool_size=(2, 2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(64, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(1, activation='sigmoid'))
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=[tf.keras.metrics.BinaryAccuracy()]
)
history = model.fit(gen, steps_per_epoch = batches,
verbose=1,
epochs = 10
)
В результате видно, что генератор корректно работает с нейросетью, ошибок при обучении не возникает.
У нас получился генератор, который можно использовать на любых объемах данных с разными размерами. Данные будут загружаться не все сразу, а по мере надобности. Слегка изменив код, можно адаптировать это генератор для загрузки датасетов, состоящих из видеофайлов. Также для более быстрой загрузки, мы можем применить код обработки изображений заранее и в процессе обучения загружать в генераторе данные, уже сохраненные как numpy массивы. Дополнительно можно добавить возможности аугментации данных (такие как сдвиги, повороты и т.д.), код которых придётся самостоятельно добавлять в наш класс. Тем не менее полученный генератор достаточно прост и эффективен, и даже в таком базовом варианте способен эффективно справляться с задачей.
