
Каждый бизнес желает знать, где сидит
фазанцелевая аудитория
Всем привет! Геоаналитика преследует меня вот уже 3 года, скоро пойдет 4-й. Начиналось все в компании Тандер (Магнит), где я в роли одного из Дата Сайнтистов проекта прогнозировала потенциальный оборот магазинов, а продолжается в Билайне, где я теперь уже занимаюсь предиктивом не только для ритейла, но и для других форматов. Помимо этого, мне удалось применить геоаналитику для анализа инвестиционной привлекательности коммерческой недвижимости, а также поработать с микробизнесом и предпринимателями, которые не обладают миллионными бюджетами для геомаркетинговых исследований, но в то же время, не очень хотят терять миллионы после выбора неудачного места открытия. Присаживайтесь поудобнее, надеюсь, будет полезно и интересно (а именно: предпринимателям, малому бизнесу, где важен правильный выбор локации и аналитикам того самого бизнеса)
В этой статье рассмотрим кейс "Как выбрать помещение для открытия кофейни?". В целом, данный подход масштабируется на любые виды бизнеса, где важна локация и то, что на ней происходит/находится.
Содержание:
Введение в геоаналитику и геомаркетинг
Работа с гексагонами: познакомимся с гексагонами (Uber H3), научимся их выгружать, визуализировать
Выгрузка, визуализация и анализ гео данных из OSM
Где открыть кофейню?
Бибилиотеки: geopandas, json, shapely, folium, osmnx, h3
Волшебство: пересечение (пространственный join) полигонов и точек, визуализация гео данных (нанесение точек/полигонов на карту osm и ее различное форматирование), поиск ближайших объектов и др.
Введение в геоаналитику и геомаркетинг
Геома́ркетинг (географический маркетинг) — маркетинговая дисциплина, направленная на взаимодействие с локальной аудиторией, выделенной по географическому признаку, с целью планирования, продвижения и осуществления деятельности в области сбыта продукции (wikipedia)
Проще говоря, геоаналитика - это набор инструментов и методов по работе с пространственными данными, т. е. гео (координаты, геометрии (полигоны, линии и пр.)) + аналитика (обработка, визуализация, выводы), а геомаркетинг - это дисциплина, направленная на исследование локации на предмет состава проживающей/работающей/проходящей аудитории для открытия бизнеса/проведения маркетинговых кампаний
Области применения:
розничная торговля продуктами питания (FMCG)
здравоохранение (аптеки, частные клиники)
общепит (кафе, рестораны, бары)
банковский сектор и страхование
бьюти - индустрия (салоны красоты, магазины парфюмерии и косметики)
DIY (строительные магазины)
девелопмент торговых центров и др.
Типовые задачи:
выбор оптимального размещения нового объекта
оценка потенциального объема продаж, определение класса (масс-маркет, бизнес, люкс) и состава реализуемой продукции/услуг
определение эффективного пути использования имеющегося объекта
выбор оптимальной локации для размещения наружной рекламы и др. маркетинговых оффлайн активностей
4 принципа масштабирования сети:

1) Перехват трафика
Этот принцип подразумевает открытие сетевых точек в зонах с высоким пешеходным трафиком (важно: высокий пешеходный трафик не всегда равен большому количеству целевой аудитории (ЦА) => анализируем состав ЦА), а также вблизи уже открытых точек конкурентов (важно: конкурентное преимущество)
2) Синергия
Эффект синергии достигается благодаря открытию смежных ниш бизнеса. Например: рядом с детскими товарами открывается магазин с товарами для дома/мам и пр.
3) Доступность
Принцип наименьших усилий (подробнее) - это принцип, который основан на том, что человек по природе своей стремится приложить как можно меньше усилий для получения желаемого. При наличии различных возможностей – клиент пойдёт туда, где ближе/привычнее/комфортнее. Критерии: радиус охвата, пешеходная доступность, транспортная доступность
4) Кластеризация
Торговые точки должны быть кластеризованы (распределены на группы) как минимум по следующим категориям: бюджет района, тип населенного пункта (большой/малый, поселки и пр.), формат торговой точки. Это означает, что для каждой группы необходима индивидуальная стратегия масштабирования, ценообразования, ассортиментной политики и т.д.
Его величество, BIG DATA
Развитие технологий получения, обработки и хранения геоданных позволяют творить потрясающие вещи в рамках геомаркетинговых исследований.
Используя различные приложения вы делитесь своей геопозицией
Совершая звонки, смс, используя интернет, вы автоматом попадаете в базы данных телеком операторов, поисковых порталов, а также web-сервисов
Подключаясь к WIFI в кафе, ТЦ, вы тоже попадаете в чью-то базу
И это еще не весь список, но важно отметить, что в любом геомаркетинговом исследовании эти данные обезличены и выглядят примерно так: "в радиусе 500 м проживает 666 женщин и 999 мужчин"
Какую информацию может содержать геомаркетинговое исследование локации?
Трафик (автомобильный, пешеходный):
Активность (кол-во пешеходов, кол-во автомобилей, кол-во проживающих/работающих)
Социально - демографический профиль: пол, возраст, доходы
Экономическая активность: количество чеков по категориям покупок, средний чек (ОФД)
Интересы (основаны на поисковых запросах, часто посещаемых приложениях и пр.) и др.
Геоданные:
Количество магазинов, школ, остановок, офисов, ТЦ, пешеходных переходов, парков, достопримечательностей, в общем - все, что вы можете найти на карте
На сегодняшний день, услуги по геоаналитике, геомеркетингу, внутренним ГИС - системам предоставляют компании - владельцы таких данных, а также подрядчики, которые эти данные покупают у владельцев.

Это действительно один из самых мощных способов снизить риск "вложить кучу денег в открытие, но прогадать с местом", а автоматизация процесса поиска потенциальных мест открытия и их анализа помогает быстрее масштабировать сеть. Федеральные сети уже давно сформировали собственные отделы геоаналитики и активно закупают данные. Но как быть предпринимателям и микро бизнесу, который не готов тратить миллионы?
Если вы - аналитик, владеющий Python, который анализирует/прогнозирует потенциал локации или тот самый бизнес, который ищет место для открытия, а может просто любопытный прохожий, кот, бот - читайте до конца и дайте обратную связь в комментариях. Это моя первая статья, но, если понравится писать, будет продолжение=)
Гексагоны (H3: Uber’s Hexagonal Hierarchical Spatial Index)

Uber опубликовал open source проект, с помощью которого можно легко и просто нанести на карту красивые шестиугольники :) Подробнее.
Сделаем сразу импорт всех библиотек:
import geopandas as gpd
import pandas as pd
import numpy as np
import json
import h3
import folium
import osmnx as ox
from shapely import wkt
from folium.plugins import HeatMap
from shapely.geometry import PolygonПосмотрим как выглядит гексагон для рандомной точки в г. Краснодар:
def visualize_hexagons(hexagons, color="red", folium_map=None):
polylines = []
lat = []
lng = []
for hex in hexagons:
polygons = h3.h3_set_to_multi_polygon([hex], geo_json=False)
outlines = [loop for polygon in polygons for loop in polygon]
polyline = [outline + [outline[0]] for outline in outlines][0]
lat.extend(map(lambda v:v[0],polyline))
lng.extend(map(lambda v:v[1],polyline))
polylines.append(polyline)
if folium_map is None:
m = folium.Map(location=[sum(lat)/len(lat), sum(lng)/len(lng)], zoom_start=20, tiles='cartodbpositron')
else:
m = folium_map
for polyline in polylines:
my_PolyLine=folium.PolyLine(locations=polyline,weight=8,color=color)
m.add_child(my_PolyLine)
return m
h3_address = h3.geo_to_h3(45.035470, 38.975313, 9) # 9 - индекс, определяющий размер гексагона
visualize_hexagons([h3_address])
OSM
OSM или Open Street Map - это открытый ресурс с геоданными по всему миру. Подробнее о проекте.
Подробнее про объекты карты, которые мы будем выгружать и анализировать.
Теперь, с помощью osmnx и h3 сотворим магию и сгенерим гексагоны внутри полигона г. Краснодара:
1) Выгрузим границы г. Краснодара из OSM
def visualize_polygons(geometry):
lats, lons = get_lat_lon(geometry)
m = folium.Map(location=[sum(lats)/len(lats), sum(lons)/len(lons)], zoom_start=13, tiles='cartodbpositron')
overlay = gpd.GeoSeries(geometry).to_json()
folium.GeoJson(overlay, name = 'boundary').add_to(m)
return m
# выводим центроиды полигонов
def get_lat_lon(geometry):
lon = geometry.apply(lambda x: x.x if x.type == 'Point' else x.centroid.x)
lat = geometry.apply(lambda x: x.y if x.type == 'Point' else x.centroid.y)
return lat, lon
# выгрузим границы Краснодара из OSM
cities = ['Краснодар']
polygon_krd = ox.geometries_from_place(cities, {'boundary':'administrative'}).reset_index()
polygon_krd = polygon_krd[(polygon_krd['name'] == 'городской округ Краснодар')]
# посмотрим что получилось
visualize_polygons(polygon_krd['geometry'])
2) Сгенерим гексагоны внутри полигона:
def create_hexagons(geoJson):
polyline = geoJson['coordinates'][0]
polyline.append(polyline[0])
lat = [p[0] for p in polyline]
lng = [p[1] for p in polyline]
m = folium.Map(location=[sum(lat)/len(lat), sum(lng)/len(lng)], zoom_start=13, tiles='cartodbpositron')
my_PolyLine=folium.PolyLine(locations=polyline,weight=8,color="green")
m.add_child(my_PolyLine)
hexagons = list(h3.polyfill(geoJson, 8))
polylines = []
lat = []
lng = []
for hex in hexagons:
polygons = h3.h3_set_to_multi_polygon([hex], geo_json=False)
# flatten polygons into loops.
outlines = [loop for polygon in polygons for loop in polygon]
polyline = [outline + [outline[0]] for outline in outlines][0]
lat.extend(map(lambda v:v[0],polyline))
lng.extend(map(lambda v:v[1],polyline))
polylines.append(polyline)
for polyline in polylines:
my_PolyLine=folium.PolyLine(locations=polyline,weight=3,color='red')
m.add_child(my_PolyLine)
polylines_x = []
for j in range(len(polylines)):
a = np.column_stack((np.array(polylines[j])[:,1],np.array(polylines[j])[:,0])).tolist()
polylines_x.append([(a[i][0], a[i][1]) for i in range(len(a))])
polygons_hex = pd.Series(polylines_x).apply(lambda x: Polygon(x))
return m, polygons_hex, polylines
# polygon_hex , polylines - геометрии гексагонов в разных форматах
# сгенерим гексагоны внутри полигона г. Краснодар
geoJson = json.loads(gpd.GeoSeries(polygon_krd['geometry']).to_json())
geoJson = geoJson['features'][0]['geometry']
geoJson = {'type':'Polygon','coordinates': [np.column_stack((np.array(geoJson['coordinates'][0])[:, 1],
np.array(geoJson['coordinates'][0])[:, 0])).tolist()]}
m, polygons, polylines = create_hexagons(geoJson)
m
Выгрузка, визуализация и анализ геоданных из OSM
Выгружаем объекты карты из OSM:
def osm_query(tag, city):
gdf = ox.geometries_from_place(city, tag).reset_index()
gdf['city'] = np.full(len(gdf), city.split(',')[0])
gdf['object'] = np.full(len(gdf), list(tag.keys())[0])
gdf['type'] = np.full(len(gdf), tag[list(tag.keys())[0]])
gdf = gdf[['city', 'object', 'type', 'geometry']]
print(gdf.shape)
return gdf
# Выгрузим интересующие нас категории объектов
tags = [
{'building' : 'apartments'}, {'building' : 'detached'},
{'building' : 'dormitory'}, {'building' : 'hotel'},
{'building' : 'house'}, {'building' : 'semidetached_house'},
{'building' : 'terrace'}, {'building' : 'commercial'},
{'building' : 'office'}, {'building' : 'terrace'},
{'building' : 'terrace'}, {'building':'retail'},
{'building':'train_station'},
{'highway' : 'bus_stop'}, {'footway':'crossing'},
{'amenity':'cafe'}, {'amenity':'fast_food'},
{'amenity':'restaurant'}, {'amenity':'college'},
{'amenity':'language_school'}, {'amenity':'school'},
{'amenity':'university'}, {'amenity':'atm'},
{'amenity':'bank'}, {'amenity':'clinic'},
{'amenity':'hospital'}, {'amenity':'pharmacy'},
{'amenity':'theatre'}, {'amenity':'townhall'},
{'amenity':'bench'},
]
cities = ['Краснодар, Россия']
gdfs = []
for city in cities:
for tag in tags:
gdfs.append(osm_query(tag, city))
# посмотрим что получилось
data_poi = pd.concat(gdfs)
data_poi.groupby(['city','object','type'], as_index = False).agg({'geometry':'count'})
# добавим координаты/центроиды
lat, lon = get_lat_lon(data_poi['geometry'])
data_poi['lat'] = lat
data_poi['lon'] = lon
Spatial Join
Теперь, нам надо сджойнить полученные объекты с гексагонами:
# sjoin - spatial join - пересекаем гексагоны с объектами (определяем какие объекты находятся в разрезе каждого гексагона)
gdf_1 = gpd.GeoDataFrame(data_poi, geometry=gpd.points_from_xy(data_poi.lon, data_poi.lat))
gdf_2 = pd.DataFrame(polygons, columns = ['geometry'])
gdf_2['polylines'] = polylines
gdf_2['geometry'] = gdf_2['geometry'].astype(str)
geometry_uniq = pd.DataFrame(gdf_2['geometry'].drop_duplicates())
geometry_uniq['id'] = np.arange(len(geometry_uniq)).astype(str)
gdf_2 = gdf_2.merge(geometry_uniq, on = 'geometry')
gdf_2['geometry'] = gdf_2['geometry'].apply(wkt.loads)
gdf_2 = gpd.GeoDataFrame(gdf_2, geometry='geometry')
itog_table = gpd.sjoin(gdf_2, gdf_1, how='left', op='intersects')
itog_table = itog_table.dropna()
itog_table.head()
Посмотрим как по городу распределены кофейни:
def create_choropleth(data, json, columns, legend_name, feature, bins):
lat, lon = get_lat_lon(data['geometry'])
m = folium.Map(location=[sum(lat)/len(lat), sum(lon)/len(lon)], zoom_start=13, tiles='cartodbpositron')
folium.Choropleth(
geo_data=json,
name="choropleth",
data=data,
columns=columns,
key_on="feature.id",
fill_color="YlGn",
fill_opacity=0.7,
line_opacity=0.2,
legend_name=legend_name,
nan_fill_color = 'black',
bins = bins
).add_to(m)
folium.LayerControl().add_to(m)
return m
# подготовим данные
itog_table['geometry'] = itog_table['geometry'].astype(str) #для groupby
itog_table['id'] = itog_table['id'].astype(str) #для Choropleth
agg_all = itog_table.groupby(['geometry','type','id'], as_index = False).agg({'lat':'count'}).rename(columns = {'lat':'counts'})
agg_all['geometry'] = agg_all['geometry'].apply(wkt.loads) #возвращаем формат геометрий
agg_all_cafe = agg_all.query("type == 'cafe'")[["geometry","counts",'id']]
agg_all_cafe['id'] = agg_all_cafe['id'].astype(str)
data_geo_1 = gpd.GeoSeries(agg_all_cafe.set_index('id')["geometry"]).to_json()
create_choropleth(agg_all_cafe, data_geo_1, ["id","counts"], 'Cafe counts', 'counts', 5)
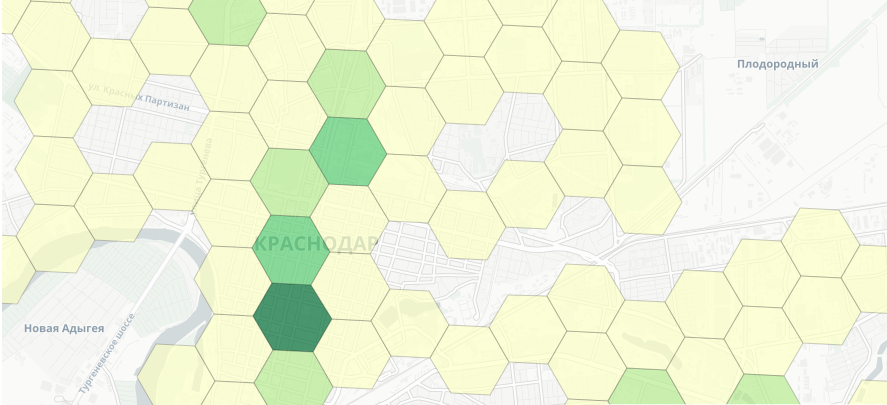
Выгрузим доступную инфу о жилых многоэтажных зданиях:
gdf_aparts = ox.geometries_from_place(city, {'building' : 'apartments'}).reset_index()
# полнота building:levels (этажи)
print(np.round(len(gdf_aparts['building:levels'].dropna())/len(gdf_aparts['building:levels']), 2))
# полнота building:flats (квартиры)
print(np.round(len(gdf_aparts['building:flats'].dropna())/len(gdf_aparts['building:flats']), 2))parts['building:flats'].dropna())/len(gdf_aparts['building:flats']), 2)Давайте посчитаем сколько людей проживает в этих домах, основываясь на следующих предположениях:
Ok, Гугл: сколько в среднем квартир на этаже?
Гугл вещает, что кол-во квартир напрямую зависит от класса жилья:
эконом - в среднем 10
комфорт - в среднем 6-8
бизнес - в среднем 4-6
Мы можем (как отчаянные дата - сатанисты) углубиться в эту тему и парсить объявления авито/циан и на основе стоимости 1 кв. м определять класс объекта, да и данных по объектам недвижимости будет больше, чем с OSM
Но мы здесь собрались не для того, чтобы парсить авито/циан, поэтому дальше будем использовать в среднем 10 квартир на этаж (доля бизнес и комфорт класса не так велика в Краснодаре)
# добавим фичу - население
lat_g, lon_g = get_lat_lon(gdf_aparts['geometry'])
gdf_aparts['lat'] = lat_g
gdf_aparts['lon'] = lon_g
itog_table_people = itog_table.merge(gdf_aparts[['lat', 'lon', 'building:levels']], on = ['lat', 'lon'], how = 'left')
itog_table_people['building:levels'] = itog_table_people['building:levels'].fillna(1)
itog_table_people = itog_table_people.rename(columns = {'building:levels' : 'levels'})
apartments = ['apartments' , 'dormitory']
houses = ['house', 'semidetached_house', 'detached', 'terrace']
people_ctn = []
# в среднем возьмем 3 чел. на семью
for i in range(len(itog_table_people)):
if itog_table_people['type'].iloc[i] in apartments:
people = int(itog_table_people['levels'].iloc[i])*10*3
elif itog_table_people['type'].iloc[i] in houses:
people = int(itog_table_people['levels'].iloc[i])*3
else:
people = 'not living area'
people_ctn.append(people)
itog_table_people['count_people'] = people_ctn
table_people = itog_table_people.query("count_people != 'not living area'")
table_people['count_people'] = table_people['count_people'].astype(int)Посмотрим что у нас вышло с плотностью "гипотетического" населения в Краснодаре:
def create_heatmap(data, lat_lon_feature):
m = folium.Map(location=[sum(data['lat'])/len(data['lat']), sum(data['lon'])/len(data['lon'])], zoom_start=13, tiles='cartodbpositron')
HeatMap(data[lat_lon_feature].groupby(lat_lon_feature[0:2]).sum().reset_index().values.tolist(),
radius = 70, min_opacity = 0.05, max_val = int((data[lat_lon_feature[2]]).quantile([0.75])), blur=30).add_to(m)
return m
# карта плотности населения
create_heatmap(table_people, ['lat', 'lon', 'count_people'])")
Где открыть кофейню? Определяем лучшее место для поиска потенциального помещения
Где открыть кофейню? Вопрос для отдельной статьи, а сюда я пришла, чтобы показать вам пример как можно творить магию геаналитику на открытых данных. Логично, что одним из ключевых факторов будет много людей и мало конкурентов, т. е. я предлагаю вам рассчитать фичу население/кол-во кофеен в гексагоне. Так мы сможем выбрать ТОП гексагоны для поиска потенциальных мест для открытия кофейни. Итого:
Добавим фичу население/кол-во кофеен в гексагоне.
Выберем гексагон с наибольшим значением.
Выберем этот гексагон и его 6 соседей (быстро это можно сделать с помощью KDTree библиотеки scipy), чтобы на всякий пожарный не упустить ближайшие области из-за каких-либо перекосов в данных OSM (опционально).
Открываем авито/циан и ищем там помещение для кофейни.

Какие еще фичи можно рассчитать?
Количество якорей трафика (ТЦ, БЦ, фаст фуд рестораны, супермаркеты и т. д.) поделим на кол-во кофеен/на кол-во населения
Huff (а вот про модель Huff я расскажу позже :)

Моя первая статья на Habr. Не кидайте помидоры :)
