Comments 26
Когда-то мы защищались только от прерываний и ПДП (CLI и блокировка шины). Потом начали защищаться от псевдопараллельных потоков в одном ядре (XCHG). С тех пор, как ядра получили локальные кеши, а порядок инструкций перестал быть определен - появились заборы. В результате определить мысленно минимально-достаточный способ блокировки стало очень сложно :)
В этой статье не затрагивалась модели памяти
Помоему раздел про барьеры как раз этого и коснулся. С учетом повсеместной когерентности как раз проблема будет не в кэшах, а в возможности смены порядка чтений и записей процессором. И барьеры в этом случае как раз и помогут. Собственно, а разве барьеры нам помогут, если у нас кэш автоматически не инвалидируется? Для этого вроде как отдельные инструкции нужны.
Постарался не вводить лишние сущности в виде моделей памяти (SC интуитивно понятна - поэтому не считается)) По поводу инвалидации кэша тема вообще отдельная и непростая, строго говоря LFENCE работает сложнее и не просто "обновляет" кэш. https://www.felixcloutier.com/x86/lfence
Можно конечно, но тема блокировок - отдельная, здесь гвоздем программы были барьеры. Локи/блокировки дают очень классный (иногда колоссальный) оверхед на процессор. Особенно видно на конкурентных структурах данных. Условно, если написать стэк на DCAS (или стек на двух CAS), а потом сравнить его с стэком под локом, то на бенчмарках можно увидеть неприятную картину - количество операций в секунду может быть и в 3+ раза меньше на стэке под локом (будет зависеть от количества потоков).
Конечно, в реальных бизнесовых проектах редко встретишь конкаренси ( и это хорошо ), но если и встречается, то ограничивается synchronized в Java и спинлоками/мьютексами/фьютексами в C/C++.
Тема про барьеры описанная здесь - одна из подводок к моделям памяти. В частности хочется рассказать про JMM в более простом ключе, а не так как это описано в её спецификации (без 100 грамм не разберешься).
На мой взгляд надо начинать не этого, это технические детали нижнего уровня. А с понимания, что такое вообще многопоточное программирование. Архитектура многопоточных приложений и тп. И при грамотном подходе к архитектуре приложения, выбору языка и библиотек возможно все вышеперечисленные "ужасы" не будут вообще нужны. А если вы наступили на эти "грабли" или у вас в приложении что-то не так или вы разрабатываете какую-то низкоуровневую библиотеку.
Согласен с этой точкой зрения, я буквально полгода назад придерживался её же. Но к сожалению, современные ограничения и в частности барьеры дают такое сильное влияние, что оно рушит всю картину. Появление acquire/release и вообще моделей памяти - высокоуровневых абстракций , модели happens before , связано со слабыми моделями памяти процессора. Для меня это тот случай, когда детали реализации оказывают решающее влияние. Иногда встречаю людей, которые живут в мире некоторых правил и не сталкиваются с такими ужасами, но стараются сыграть в многопоточность и совершают примитивные ошибки. Если не заходить дальше простых элементов, это не конечно нужно, но если вам нужен первоманс на той же джаве, без этого не обойтись.
Какая основная задача в многопоточности - минимизировать синхронизацию. Синхронизация это то, что тянет обратно в монопоточность. Синхронизаия это работа с шаред данными из многих потоков и тп. И то что вы пишете в этой статье как раз относиться к нижнему уровню синхронизации. Но идеальное многопоточное приложение это приложение в котором нет вообще никакой синхронизации. Что в реальности - не реально. Поэтому если вы не являетесь гуру в разработке методов синхронизации в многопоточных приложениях, используйте стандартные, проверенные временем, подходы и объекты синхронизации, иначе вероятность сделать ошибку очень велика. Поэтому основная задача это убрать синхронизацию из приложения, не пытаться изобрести новый велосипед в синхронизации, и мыслить параллельно :)
int a = 0 // операция 1, выполнится самая первая
int b = 0 // операция 2, выполнится после операции 1
a = a + b // операция 3, выполнится после операций 1 и 2
b = a + a // операция 4, выполнится после всех операций
В упор не вижу откуда тут может взяться единица.
Поэтому представляю рабочий вариант(решение через добавление обоих барьеров), который корректно будет исполнятся в любом случае (вариант на процессоре x86).Этот пример у меня успешно завершается. А вот если заменить на mfence пару sfence + lfence, то не завершается. Ryzen 7 5800X, linux.
Как раз и не должен завершаться) это значит , что мы исключили вариант (0,0), вообще странная ситуация, по спецификации mfence это комбинация lfence и sfence
Попробую поискать информацию об этом, что то новое для меня, к сожалению на Intel не воспроизводится( надо найти AMD
sfence запрещает перестановку операций записи в память до и после себя, lfence — операций загрузки из памяти. Но они не могуг запретить выполнить чтение до записи. А mfence запрещает перестановку любых обращений к памяти.
Спасибо за статью.
Подскажите, когда вы делаете в последнем примере
// load barrier - для честности эксперимента
__asm__ __volatile__ ("lfence" ::: "memory");это ведь делается для подъёма в кеш значений переменных a и b?
Но чем гарантируется предварительный сброс значений этих переменных в память?
sfence после их присвоения не вызывается.
Это обеспечивается особенностями memory model в C (не знаю этот язык), или я упустил саму цель lfence перед валидацией значений a и b?
Хорошее замечание) по факту, да, в нашей модели должен быть еще store барьер после завершения инструкций каждого потока, я постараюсь рассмотреть этот пример еще раз в следующей статье и подробнее рассмотреть load barrier, мне уже кажется , что я принял слишком не точное его определение, которое может запутать, если действительно хочется разобраться советую почитать https://www.felixcloutier.com/x86/lfence и https://en.wikipedia.org/wiki/MESI_protocol (раздел про Memory barriers)
По просьбам трудящихся, обновил раздел про барьеры. Решил, что всё таки стоит немного углубится в кэши и очереди инвалидации, поскольку термин "обновление" кэша очень неоднозначный и вводит в заблуждение.
Спасибо, хорошо написано.
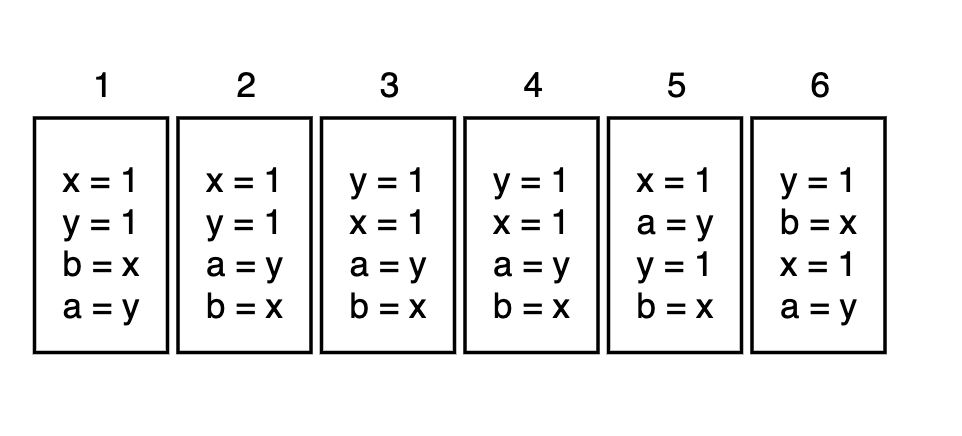
Небольшая ремарка. Вот на этой картинке https://habrastorage.org/r/w1560/getpro/habr/upload_files/5f4/81e/21c/5f481e21c932d0fcfab39e56977455c8.png варианты 3 и 4 полностью идентичны. Наверное, для варианта 4 имелось в виду: y=1 x=1 b=x a=y.
{kind=link}
Другой взгляд на многопоточность