
Очень часто при работе мы обращаем внимание на то, что все люди знают, что такое распознавание речи, но не знают, что такое Voice Activity Detector (VAD) или детектор речи. А ведь именно VAD на самом деле самый важный алгоритм при работе с речью людей в естественной среде обитания.
Как ни странно, если поискать поддерживаемые и высококачественные решения данной задачи в публичном доступе — найдутся буквально пара проектов достаточного уровня. Но вот незадача — академические решения тяжелы (и иногда работают запретительно долго) и зачастую принимают только целые аудио на вход (нельзя использовать потоково). Решение от Google (WebRTC) очень быстрое но плохо отличает речь от шума (но его можно использовать потоково). А некоторые коммерческие решения "привязаны" к личному кабинету и шлют какую-то телеметрию.
Мы решили исправить это недоразумение и сделать уникальный VAD мирового уровня (судите сами по метрикам), который работает на 1 ядре процессора с задержкой в 1 миллисекунду на кусочках аудио от 30 миллисекунд. В этой статье мы расскажем вам, что такое VAD, покажем на примерах как использовать его и наглядно потестировать на своем голосе.
Что такое VAD
Voice activity detection (VAD) — алгоритм, позволяющий обнаружить голосовую активность в непрерывном аудиопотоке. VAD выполняет роль "первого шага" в большинстве современных задач по обработке речи, ведь именно его сигнал служит триггером к началу их работы.
Примеры задач решаемых с использованием VAD:
- Детекция речи в мобильных устройствах, IOT;
- Подготовка и фильтрация аудиоданных;
- Автоматизация работы колл-центров;
- Голосовые помощники;
- Голосовые интерфейсы;
Задача VAD сводится к выделению речи из шума или тишины. На входе — кусочек аудио, размер которого зависит от желаемого времени реакции системы. На выходе — вероятность того, что этот кусочек содержит в себе речь. Все просто! По сути, задача бинарной классификации. Однако, в современных реалиях алгоритм детекции речи должен удовлетворять ряду условий:
- Задержка, ведь пользователи не любят лаги:) 100 миллисекунд — приемлемо, меньше 50 — круто (стоит отметить, речь тут идет не о скорости работы алгоритма самого по себе, а о времени, что мы ждем, прежде чем выделить кусочек и отправить его в VAD, т.е о длине фрагмента аудио);
- Точность. Чтоб его не пришлось переспрашивать, VAD должен минимизировать количество False Positive. Приоритет метрик варьируется от задачи к задаче (важнее найти речь или не ошибиться, принимая шум за речь);
- Генерализуемость. Алгоритм детекции речи должен работать с аудио из разных источников, с разным уровнем шума и разной громкостью голоса;
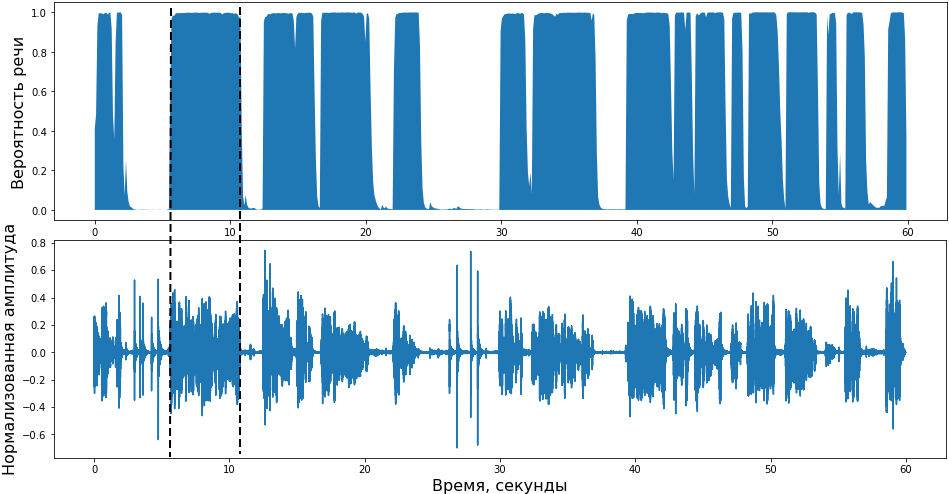
На практике хорошо натренированный VAD ведет себя примерно так:
Аудиопоток преобразованный VADом в вероятности
Наше решение
На днях мы опубликовали масштабное обновление нашего Silero VAD, опробовать его на своем голосе можно тут (но это работает не так быстро как работает сам VAD ввиду ограничений google colab), либо здесь. Под капотом — нейросеть на stft спектрограммах. Вкратце, наш VAD теперь:
- Быстрее, прогон одного кусочка аудио занимает меньше 1 миллисекунды (хотя WebRTCVAD, конечно, все еще быстрее);
- Точнее, метрики и методику тестирования можно глянуть чуть ниже либо тут;
- Работает с разным sampling rate, в данный момент поддерживается
8000и16000 Гц; - Работает с длиной аудиофрагментов от 30 миллисекунд и больше;
Простой python пример на готовом аудио (нужен torch 1.9 и выше):
SAMPLING_RATE = 16000 ## модель обучена на 16к и 8к
import torch
from IPython.display import Audio
from pprint import pprint
torch.set_num_threads(1)
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True)
(get_speech_timestamps, _, read_audio, _, _) = utils
files_dir = torch.hub.get_dir() + '/snakers4_silero-vad_master/files'
## аудио - семинар моего преподавателя по стат. физике:)
wav = read_audio(f'{files_dir}/ru.wav', sampling_rate=SAMPLING_RATE)
speech_timestamps = get_speech_timestamps(wav, model,
sampling_rate=SAMPLING_RATE,
visualize_probs=True,
return_seconds=True)
print('Speech timings:')
pprint(speech_timestamps)
Audio(f'{files_dir}/ru.wav')Тестовые данные и методика
Сбор данных для тестирования моделей — это вызов. В идеальном сценарии следовало бы поделить каждое аудио на кусочки минимального размера (в нашем случае 30 миллисекунд), а затем пометить, есть ли речь в каждом из кусочков.
Однако, от такого подхода пришлось отказаться, потому что определение на слух начала и конца речи с точностью до 30 миллисекунд — это трудоемкий и весьма неточный подход, который влечет за собой ряд ошибок при разметке.
Выбранный нами подход тестирования гораздо более прост и лаконичен — помечать все аудио целиком. Правила таковы:
- Если голос достаточно громкий (в микрофон), то это речь;
- Голоса на заднем фоне считаем речью только в том случае, если она разборчива;
- Принимаем за речь Смех, крик, лепетание в микрофон;
- Разборчивое человеческое пение считаем речью;
- Не принимаем за речь звуки домашних животных, пение птиц на фоне, и т.д;
- Не считаем речью городские звуки, шум толпы на фоне, аплодисменты и т.д;
- Иные нечеловеческие звуки — не речь;
Характеристики размеченного нами тестового датасета:
- 30+ языков;
- 2,200 аудио средней длины ~7 секунд, из которых 55% с речью;
- Широкое разнообразие источников аудио (звонки, студийные записи, шумные аудио с фоновыми голосами и т.д);
На этом моменте возникает вопрос — как быть? Ведь тестовые аудио длиной 7 секунд, а модели классифицируют фрагменты вплоть до 30 миллисекунд, то есть каждый цельный звуковой отрывок содержит сотни таких маленьких кусочков. Как показала практика, в реальной жизни длительность речи ограничена снизу ~250 миллисекундами. Конечно, есть исключения, например, короткий возглас "А!" и ему подобные, но такими редкими случаями можно пренебречь. Хорошо, получается, если алгоритм предсказал 250 мс речи подряд, то мы помечаем все аудио меткой речь есть. Если речевая последовательность заканчивается, мы ждем еще 250 мс прежде чем обрезать ее.
Порог (threshold). VAD предсказывает вероятность в диапазоне [0, 1] для каждого куска аудио. При превышении этой вероятностью некоего порога, который подбирается заранее, данный кусок помечается речью. В 90% случаев дефолтный порог 0.5 работает замечательно, для остальных 10% случаев его нужно подбирать под конкретный домен (как правило, делать меньше)
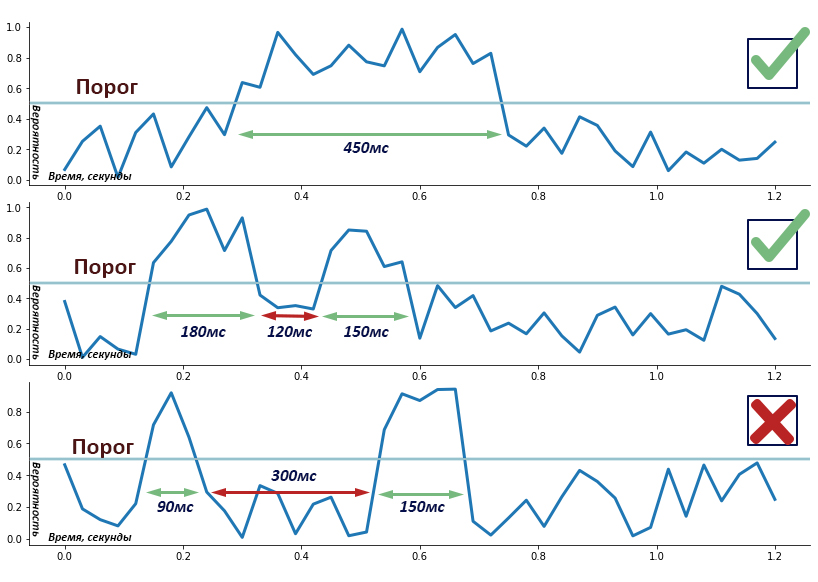
Весь метод тестирования можно описать так:
- Получить последовательность предсказаний модели для каждого аудио в тестовой выборке;
- Используя последовательность предсказаний посчитать, есть ли речь в целом аудио (для разных пороговых значений в диапазоне
[0, 1]); - Посчитать Recall и Precision для каждого порогового значения;
- Нарисовать кривую Precision-Recall;
Результаты
Для сравнения с новой моделью было решено взять:
- WebRTCVAD. Древнее, хорошо зарекомендовавшее себя решение от гугла. Очень быстрое (но лично нам не совсем понятно как извлечь оттуда вероятности);
- Picovoice VAD. Быстрый, отличный по качеству;
- OLD Silero VAD. Наша старая модель, работала только с кусками длиной 250мс, справлялась с ними хорошо.
Все тесты были проведены при следующих параметрах: 16000 Гц частота дискретизации, 30 мс длина кусочков аудио (кроме старой модели, у нее 250).
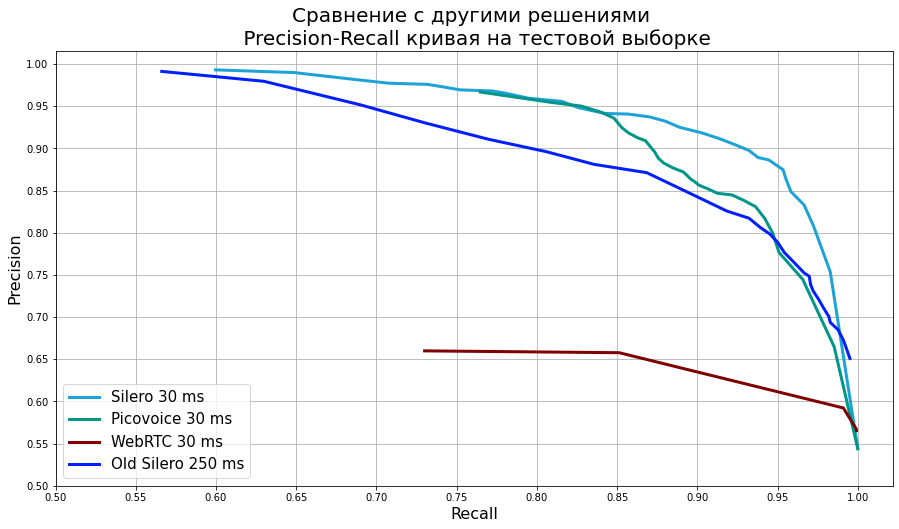
На графике видно, что наша новая модель стала значительно лучше относительно прошлой модели как по качеству, так и по минимальному размеру чанка. Picovoice хорошо показал себя при этом методе тестирования, но его удалось обойти.
Полные метрики можно найти здесь.
