Большая доля data science и машинного обучения зависит от чистых и корректных источников данных, поэтому неудивительно, что скорость роста рынка разметки данных продолжает увеличиваться. В этой статье мы расскажем о многих крупных игроках отрасли, а также об используемых ими методиках, чтобы вы могли иметь возможность выбора наилучшего партнёра в соответствии со своими требованиями.

Рынок разметки данных развивается невиданными ранее темпами. В прошлом году его сегмент сторонних решений достиг более 1 миллиарда долларов; ожидается, что он продолжит стабильное расширение в течение следующих пяти лет, и к 2027 году превзойдёт 7 миллиардов долларов. Наблюдая впечатляющий ежегодный рост на 25-30%, некоторые источники, в том числе и Grand View Research, считают, что к 2028 году рынок будет стоить не менее 8,2 миллиарда.
Разметка данных — это область, возникшая в результате исследований машинного обучения, начавшихся с простых алгоритмов и постепенно превратившихся в современных виртуальных помощников и беспилотные автомобили. Машинное обучение прошло долгий путь — от оригинальной статьи 1950 года Алана Тьюринга об искусственном интеллекте и статьи 1959 года Артура Самуэля про первый алгоритм обучения компьютера до появления Deep Blue компании IBM в 1996 году и Google Brain в 2011 году.
Сегодня разметка данных является неотъемлемой частью разработки машинного обучения (machine learning, ML) и искусственного интеллекта. Без размеченных данных мы бы не могли обучить алгоритмы ML. Именно поэтому многие стремились найти эффективные способы быстрой и экономной разметки данных. Всё просто: чем лучше решение, тем быстрее сможет развиваться ИИ.
Для аннотирования данных обучения уровня продакшена существует различное сложное ПО. Однако правильный выбор сделать нелегко. Разнообразные решения проделали долгий путь развития. Их можно разбить на категории по формату, открытости и методикам.
В первых двух категориях разобраться достаточно просто. Под форматом подразумевается тип размечаемых данных, например, текст, изображения, звук или видео.
Открытость подразумевает доступность и приемлемость цены решения. Она зависит от того, является ли ПО проприетарным (обычно такой вид требует оплаты) или open-source (а следовательно, бесплатным). Существуют проприетарные решения с бесплатным пробным режимом и без него.
Методика разметки — это гораздо более сложная категория, поэтому давайте рассмотрим её подробнее.
С точки зрения методик разметки данных (самой важной для бизнеса категории) сегодня существует широкий выбор решений. Согласно нашей статье, самыми распространёнными являются следующие:
Считается самой надёжной методикой с точки зрения точности размеченных данных, однако в тоже время одной из самых дорогих и времязатратных. В рамках этой методики компании поручают задачи по разметке данных собственным коллективам. Команды разметчиков могут быть уже готовы к работе или требовать предварительной подготовки. На каждом этапе процесса разметки обеспечивается полный контроль.
Ещё один вариант — это формирование команды внешних разметчиков, большинство из которых является фрилансерами. Их можно найти на специализированных сайтах наподобие UpWork, а также в соцсетях, например, в LinkedIn, Facebook и Twitter. Для начала компании необходимо выстроить целостный рабочий процесс с участием этих специалистов. Затем ей нужно скоординировать их обязанности, согласовать подходящее ПО и написать чёткие инструкции.
Эта методика похожа на предыдущую, однако в данном случае вместо множества разметчиков компании нанимают только одну организацию. Поэтому эта методика более дорога, зато теоретически менее времязатратна и более надёжна с точки зрения точности. Каждая из таких специализированных компаний сама выбирает программные инструменты и методики, при этом не всегда раскрывая их заказчикам.
При такой методике генерируются имитируемые данные обучения, напоминающие по своим базовым параметрам реальные данные. Такие данные можно относительно быстро сгенерировать и использовать для разметки. В рамках синтетической разметки существует три подмодели: Generative Adversarial Networks (GAN), AutoRegressive models (AR) и Variational Autoencoders (VAE). Все три имеют применение на практике, от распознавания мошенничества в финансовой сфере до создания медицинских массивов данных. Однако для выполнения таких моделей требуются серьёзные вычислительные ресурсы, доступные не каждому отделу ИТ.
При такой полностью автоматизированной методике выполняется код с функциями разметки, позволяющий машинам проделывать всю работу. Хоть эта методика и менее точна по сравнению с другими, однако программирование данных — это наименее трудоёмкий из всех перечисленных в этом списке способов. Генерируемые им зашумлённые массивы данных можно использовать для моделей с частичным контролем или очистить для других целей, например, для дискриминантного обучения.
Платформы краудсорсинга, считающегося самой быстрой и экономной методикой, используют свои обширные резервы пользователей и разделяют задачи на мелкие и более удобные в работе части. Такие микрозадачи выполняются и проверяются множеством участников, часто работающих в небольших группах, а затем собираются воедино для получения конечных результатов. Основной проблемой этой методики остаётся точность разметки данных.
При выборе подходящего ПО нужно быть хорошо осведомлённым о плюсах и минусах каждого пакета, чтобы минимизировать вероятность возникновения мешающих бизнесу проблем. Можно начать с ответа на следующие простые вопросы:
Дорога ли эта платформа? Каково её соотношение цены и качества?
Будут ли затраты времени минимальными?
Есть ли в ней встроенные механизмы контроля качества?
Не слишком ли сложно обучать пользователей?
Предоставляет ли она исчерпывающие инструкции для новичков?
Поддерживаются ли все типы данных?
Требует ли она большой вычислительной мощности?
На сегодняшний момент существует более десятка различных инструментов и платформ разметки данных. Давайте их рассмотрим.
Компания: Appen
Веб-сайт: https://appen.com
Краткое описание:
Appen предлагает решения для бизнесов по управлению данными продуктов. Компания собирает и размечает данные для создания и совершенствования собственных систем искусственного интеллекта. Appen работает в таких областях, как финансовые услуги, розничная торговля, здравоохранение и госсектор. Заявляется, что на Appen работает 1 миллион разметчиков данных из 170 стран.
Компания: Lionbridge AI
Веб-сайт: https://lionbridge.ai/
Краткое описание:
Находящаяся в штате Массачусетс компания Lionbridge предлагает услуги в сфере сбора, аннотирования и валидации данных, в том числе текста, звука, видео, изображений и географической информации. Компания гордится тем, что поставляет качественные данные, размеченные людьми. Она задействована во множестве отраслей, включая автомобильную, медицинскую и сферу электронной коммерции. (Приобретена канадской TELUS Corporation)
Компания: Scale
Веб-сайт: https://scale.com/
Краткое описание:
Находящаяся в Кремниевой долине Scale — одна из лучших компаний, гарантирующая предоставление услуг высококачественной разметки данных, начиная от аннотирования и проверки (в том числе при помощи масштабируемых, всеобъемлющих и современных решений) до генерации синтетических наборов данных. Scale сотрудничает с компаниями в сферах робототехники, распознавания речи и языков, беспилотных автомобилей, электронной коммерции и обработки документов, а также многих других.
Компания: «Толока» (Toloka)
Веб-сайт: https://toloka.ai/
Краткое описание:
Компания была основана в 2014 году и с тех пор разрослась до работы с двумя тысячами клиентов. «Толока» имеет несколько миллионов пользователей (называемых «толокерами») более чем в ста странах. Двести тысяч из них активны ежемесячно и готовы к выполнению задач разметки данных по заказу. Впоследствии для разработки беспилотного транспорта, NLP, чат-ботов и голосовых помощников, а также систем электронной коммерции применяются обученные алгоритмы машинного обучения. Кроме того, «Толока» активно участвует в исследованиях ИИ. Команда проекта регулярно делится своими результатами на лучших конференциях по ML/AI/DS и мастер-классах по всему миру.
Компания: MTurk (Amazon Mechanical Turk)
Веб-сайт: https://www.mturk.com/
Краткое описание:
MTurk — одна из крупнейших и известных современных платформ краудсорсинга. После своего основания в 2005 году компания быстро расширялась, в том числе и благодаря популярности бренда Amazon. Имея большой резерв участников (называемых «Turkers»), сто тысяч из которых доступны в любой момент времени, компания обслуживает клиентов по всему миру и делает упор на HIT (Human Intelligence Tasks, задачи для человеческого разума).
Компания: Hive
Веб-сайт: https://thehive.ai/
Краткое описание:
Ещё одна базирующаяся в Кремниевой долине компания Hive была основана в 2013 году. Она имеет две основных бизнес-парадигмы: Hive Models (ИИ-решения «под ключ» для предварительно обученных моделей глубокого обучения) и Hive Data (внутренние решения аннотирования данных для снабжения и разметки моделей ML). Утверждается, что для последней у компании есть 2 миллиона участников, работающих на её платформе. В 2021 году компания собрала 85 миллионов долларов дополнительного финансирования.
Компания: Webtunix AI
Веб-сайт: https://www.webtunix.com/
Краткое описание:
Расположенная в Нью-Йорке Webtunix, основанная индийскими предпринимателями — это консалтинговая компания в сфере Big Data, помогающая бизнесам достигать своих целей в области ИИ. В их число входят различные услуги разметки данных в компьютерном зрении, звуке, NLP и семантической сегментации, а также аннотирования видео и разметки линиями. Компания была основана в 2015 году.
Компания: iMerit
Веб-сайт: https://imerit.net/
Краткое описание:
iMerit была основана в 2012 году. Компания сочетает MAA и ручное аннотирование для упрощения бизнес-процессов и предоставления размеченных данных корпоративным клиентам. В основном компания работает в сферах компьютерного зрения и NLP и использует собственную команду опытных специалистов. iMerit, имеющая более четырёх тысяч сотрудников, сертифицирована по SOC 2 и обладает ещё одним сертификатом о защите данных — ISO 27001:2013. При разметке данных компания может использовать свои собственные инструменты аннотирования, инструменты клиента или сторонние инструменты.
Компания: CloudFactory
Веб-сайт: https://www.cloudfactory.com/
Краткое описание:
Базирующаяся в Рединге (Англия) CloudFactory заявила о своём присутствии на рынке в 2010 году и с тех пор предлагает аутсорсинговые и краудсорсинговые услуги разметки данных клиентам по всему миру. Компания специализируется на компьютерном зрении, NLP, наполнении данными и обогащении данных. CloudFactory называет свои конвейеры поставок «виртуальными сборочными линиями», на которых трудится примерно 1 миллион человек из развивающихся стран. Компания «выращивает их как лидеров, чтобы они способствовали решению проблемы бедности в своём обществе».
Компания: Clickworker
Веб-сайт: https://www.clickworker.com/
Краткое описание:
Находящаяся в Германии Clickworker, основанная в 2008 году — это платформа краудсорсинга, которая специализируется на компьютерном зрении и NLP. Имея почти 3 миллиона участников (называемых «Clickworkers») из 136 стран, компания заявляет, что уже завершила более 1 миллиона проектов по разметке данных. Также у компании есть специализированное приложение Clickworker для смартфонов и планшетов.
Основной сложностью в разметке данных является их качество. Эта сложность становится особенно актуальной при создании сложных моделей машинного обучения, в частности, при параллельном выполнении нескольких моделей. Сегодня уже существует множество готовых инструментов разметки, поэтому главной сложностью для дата-саентистов является подбор ПО для решения задачи — определение того, в каких ситуациях одни инструменты имеют преимущество перед другими. Это приводит к одному простому вопросу: как выполнить разметку данных с наименьшим объёмом усилий, времени и денег, в то же время обеспечив максимально возможные результаты?
Методики, в которых используется исключительно человеческий труд, постепенно оттесняются на обочину, поскольку учёные разработали способы разметки данных, сочетающие в себе ручные и компьютерные компоненты. Дальнейшее развитие, совершенствование и прогресс этих новых современных инструментов однозначно зададут темп на ближайшие годы, поскольку всё больше ИТ-компаний будут следовать по этому пути.

Рынок разметки данных развивается невиданными ранее темпами. В прошлом году его сегмент сторонних решений достиг более 1 миллиарда долларов; ожидается, что он продолжит стабильное расширение в течение следующих пяти лет, и к 2027 году превзойдёт 7 миллиардов долларов. Наблюдая впечатляющий ежегодный рост на 25-30%, некоторые источники, в том числе и Grand View Research, считают, что к 2028 году рынок будет стоить не менее 8,2 миллиарда.
Введение
Разметка данных — это область, возникшая в результате исследований машинного обучения, начавшихся с простых алгоритмов и постепенно превратившихся в современных виртуальных помощников и беспилотные автомобили. Машинное обучение прошло долгий путь — от оригинальной статьи 1950 года Алана Тьюринга об искусственном интеллекте и статьи 1959 года Артура Самуэля про первый алгоритм обучения компьютера до появления Deep Blue компании IBM в 1996 году и Google Brain в 2011 году.
Сегодня разметка данных является неотъемлемой частью разработки машинного обучения (machine learning, ML) и искусственного интеллекта. Без размеченных данных мы бы не могли обучить алгоритмы ML. Именно поэтому многие стремились найти эффективные способы быстрой и экономной разметки данных. Всё просто: чем лучше решение, тем быстрее сможет развиваться ИИ.
Категории программных решений
Для аннотирования данных обучения уровня продакшена существует различное сложное ПО. Однако правильный выбор сделать нелегко. Разнообразные решения проделали долгий путь развития. Их можно разбить на категории по формату, открытости и методикам.
В первых двух категориях разобраться достаточно просто. Под форматом подразумевается тип размечаемых данных, например, текст, изображения, звук или видео.
Открытость подразумевает доступность и приемлемость цены решения. Она зависит от того, является ли ПО проприетарным (обычно такой вид требует оплаты) или open-source (а следовательно, бесплатным). Существуют проприетарные решения с бесплатным пробным режимом и без него.
Методика разметки — это гораздо более сложная категория, поэтому давайте рассмотрим её подробнее.
Методики разметки данных
С точки зрения методик разметки данных (самой важной для бизнеса категории) сегодня существует широкий выбор решений. Согласно нашей статье, самыми распространёнными являются следующие:
- Разметка внутри компании
Считается самой надёжной методикой с точки зрения точности размеченных данных, однако в тоже время одной из самых дорогих и времязатратных. В рамках этой методики компании поручают задачи по разметке данных собственным коллективам. Команды разметчиков могут быть уже готовы к работе или требовать предварительной подготовки. На каждом этапе процесса разметки обеспечивается полный контроль.
- Аутсорсинг сторонним работникам
Ещё один вариант — это формирование команды внешних разметчиков, большинство из которых является фрилансерами. Их можно найти на специализированных сайтах наподобие UpWork, а также в соцсетях, например, в LinkedIn, Facebook и Twitter. Для начала компании необходимо выстроить целостный рабочий процесс с участием этих специалистов. Затем ей нужно скоординировать их обязанности, согласовать подходящее ПО и написать чёткие инструкции.
- Аутсорсинг специализированным компаниям
Эта методика похожа на предыдущую, однако в данном случае вместо множества разметчиков компании нанимают только одну организацию. Поэтому эта методика более дорога, зато теоретически менее времязатратна и более надёжна с точки зрения точности. Каждая из таких специализированных компаний сама выбирает программные инструменты и методики, при этом не всегда раскрывая их заказчикам.
- Синтетическая разметка
При такой методике генерируются имитируемые данные обучения, напоминающие по своим базовым параметрам реальные данные. Такие данные можно относительно быстро сгенерировать и использовать для разметки. В рамках синтетической разметки существует три подмодели: Generative Adversarial Networks (GAN), AutoRegressive models (AR) и Variational Autoencoders (VAE). Все три имеют применение на практике, от распознавания мошенничества в финансовой сфере до создания медицинских массивов данных. Однако для выполнения таких моделей требуются серьёзные вычислительные ресурсы, доступные не каждому отделу ИТ.
При такой полностью автоматизированной методике выполняется код с функциями разметки, позволяющий машинам проделывать всю работу. Хоть эта методика и менее точна по сравнению с другими, однако программирование данных — это наименее трудоёмкий из всех перечисленных в этом списке способов. Генерируемые им зашумлённые массивы данных можно использовать для моделей с частичным контролем или очистить для других целей, например, для дискриминантного обучения.
- Краудсорсинг
Платформы краудсорсинга, считающегося самой быстрой и экономной методикой, используют свои обширные резервы пользователей и разделяют задачи на мелкие и более удобные в работе части. Такие микрозадачи выполняются и проверяются множеством участников, часто работающих в небольших группах, а затем собираются воедино для получения конечных результатов. Основной проблемой этой методики остаётся точность разметки данных.
7 вопросов, которые нужно задать себе
При выборе подходящего ПО нужно быть хорошо осведомлённым о плюсах и минусах каждого пакета, чтобы минимизировать вероятность возникновения мешающих бизнесу проблем. Можно начать с ответа на следующие простые вопросы:
Дорога ли эта платформа? Каково её соотношение цены и качества?
Будут ли затраты времени минимальными?
Есть ли в ней встроенные механизмы контроля качества?
Не слишком ли сложно обучать пользователей?
Предоставляет ли она исчерпывающие инструкции для новичков?
Поддерживаются ли все типы данных?
Требует ли она большой вычислительной мощности?
Обзор инструментов разметки данных
На сегодняшний момент существует более десятка различных инструментов и платформ разметки данных. Давайте их рассмотрим.
Компания: Appen
Веб-сайт: https://appen.com
Краткое описание:
Appen предлагает решения для бизнесов по управлению данными продуктов. Компания собирает и размечает данные для создания и совершенствования собственных систем искусственного интеллекта. Appen работает в таких областях, как финансовые услуги, розничная торговля, здравоохранение и госсектор. Заявляется, что на Appen работает 1 миллион разметчиков данных из 170 стран.
| Тип данных: | Большинство, включая текст, изображения, звук и видео |
| Открытость: | Проприетарная (есть пробная версия) |
| Методика: | Краудсорсинг (подкатегории: по запросу, удалённый, защищённый и выезд сотрудников в компанию) на платформе ADAP + платформа для услуг найма (собственные специалисты клиента) |
| Отрасли: | Технологическая, автомобильная, финансовые услуги, здравоохранение, госсектор и розничная торговля |
| Соотношение цены и качества: | Выше среднего |
| Оптимальность времязатрат: | Высокая |
| Инструкции для новичков: | Да (набор учебных материалов) |
| Скорость обучения пользователей: | Средняя или высокая (в зависимости от подкатегории) |
| Механизмы контроля качества: | Параметры контроля качества: минимальное время на страницу, максимальное количество решений на одного участника, отключение Google Translate для участников и правила распределения ответов.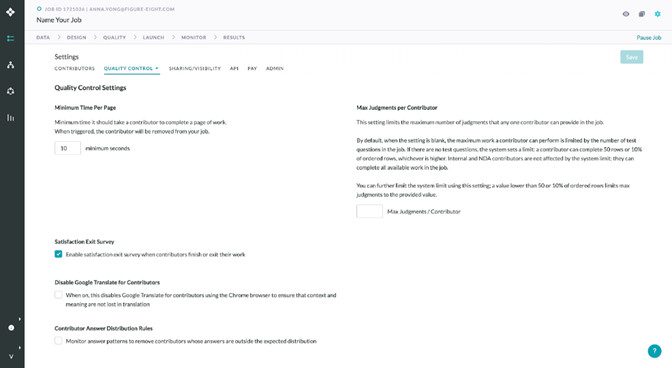 Источник: веб-сайт Appen |
| Вычислительные мощности: | От клиента не требуются, за исключением случаев работы с выездом к клиенту |
Компания: Lionbridge AI
Веб-сайт: https://lionbridge.ai/
Краткое описание:
Находящаяся в штате Массачусетс компания Lionbridge предлагает услуги в сфере сбора, аннотирования и валидации данных, в том числе текста, звука, видео, изображений и географической информации. Компания гордится тем, что поставляет качественные данные, размеченные людьми. Она задействована во множестве отраслей, включая автомобильную, медицинскую и сферу электронной коммерции. (Приобретена канадской TELUS Corporation)
| Тип данных: | Большинство, включая текст, изображения, звук, видео и данные географической локализации |
| Открытость: | Проприетарная |
| Методика: | Краудсорсинг и аутсорсинг (для задач с узкой специализацией) / собственная платформа с обширными резервами собственных сотрудников и работников на аутсорсе/краудсорсе |
| Отрасли: | Технологическая, коммуникационная и медийная, финтех и финансовые услуги, путешествия и гостиничный бизнес, игры, электронная коммерция и здравоохранение |
| Соотношение цены и качества: | От среднего до хорошего (зависит от задачи и методики) |
| Оптимальность времязатрат: | От средней до высокой (зависит от задачи и методики) |
| Инструкции для новичков: | Да (публикации и пошаговый разбор) |
| Скорость обучения пользователей: | Средняя или высокая (зависит от методики) |
| Механизмы контроля качества: | Встроенная валидация, выборочная проверка и система старшинства работников для обеспечения максимального качества данных. |
| Вычислительные мощности: | От клиента в большинстве случаев не требуются |
Компания: Scale
Веб-сайт: https://scale.com/
Краткое описание:
Находящаяся в Кремниевой долине Scale — одна из лучших компаний, гарантирующая предоставление услуг высококачественной разметки данных, начиная от аннотирования и проверки (в том числе при помощи масштабируемых, всеобъемлющих и современных решений) до генерации синтетических наборов данных. Scale сотрудничает с компаниями в сферах робототехники, распознавания речи и языков, беспилотных автомобилей, электронной коммерции и обработки документов, а также многих других.
| Тип данных: | Массив данных 3D-датчиков, текст, изображения, видео, картография |
| Открытость: | Проприетарная (доступна бесплатная пробная версия) |
| Методика: | «Платформа данных для ИИ». Сочетание инструментов и контроля человеком. |
| Отрасли: | Технологическая, розничная, госсектор, робототехника, электронная коммерция |
| Соотношение цены и качества: | Среднее |
| Оптимальность времязатрат: | От средней до высокой |
| Инструкции для новичков: | Да (руководства и краткие введения) |
| Скорость обучения пользователей: | Средняя |
| Механизмы контроля качества: | Всем задачам назначаются дополнительные слои при проверке и людьми, и моделями машинного обучения. Системы обеспечения качества отслеживают и предотвращают ошибки. В соответствии с требованиями клиента предоставляются различные уровни контроля людьми и обеспечения консенсуса.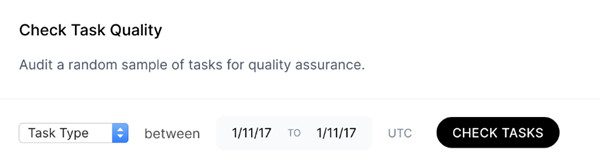 Источник: веб-сайт Scale |
| Вычислительные мощности: | От клиента не требуются, если не заказаны конкретные специализированные решения |
Компания: «Толока» (Toloka)
Веб-сайт: https://toloka.ai/
Краткое описание:
Компания была основана в 2014 году и с тех пор разрослась до работы с двумя тысячами клиентов. «Толока» имеет несколько миллионов пользователей (называемых «толокерами») более чем в ста странах. Двести тысяч из них активны ежемесячно и готовы к выполнению задач разметки данных по заказу. Впоследствии для разработки беспилотного транспорта, NLP, чат-ботов и голосовых помощников, а также систем электронной коммерции применяются обученные алгоритмы машинного обучения. Кроме того, «Толока» активно участвует в исследованиях ИИ. Команда проекта регулярно делится своими результатами на лучших конференциях по ML/AI/DS и мастер-классах по всему миру.
| Тип данных: | Большинство, в том числе текст, изображения, звук и видео |
| Открытость: | Проприетарная |
| Методика: | Краудсорсинг |
| Отрасли: | Электронная коммерция, розничная торговля, автомобильная, кибербезопасность, банкинг, спорт, юридические информационные технологии, исследования, производство, здравоохранение. |
| Соотношение цены и качества: | Выше среднего |
| Оптимальность времязатрат: | Высокая |
| Инструкции для новичков: | Да (база знаний) |
| Скорость обучения пользователей: | От средней до высокой |
| Механизмы контроля качества: | Выбор исполнителей: предварительная фильтрация, обучение, входное тестирование. Синхронный контроль качества: проверки поведения (CAPTCHA, мониторинг скорости, проверка определённых действий), проверка качества распределения работ (мажоритарное голосование, контрольные задания). Асинхронный контроль качества: контроль распределения работ, методики интеллектуальной агрегации.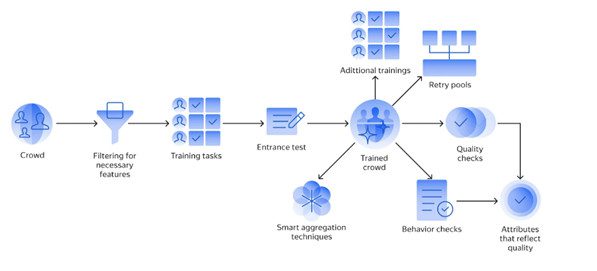 Источник: веб-сайт «Толоки» |
| Вычислительные мощности: | От клиента не требуются |
Компания: MTurk (Amazon Mechanical Turk)
Веб-сайт: https://www.mturk.com/
Краткое описание:
MTurk — одна из крупнейших и известных современных платформ краудсорсинга. После своего основания в 2005 году компания быстро расширялась, в том числе и благодаря популярности бренда Amazon. Имея большой резерв участников (называемых «Turkers»), сто тысяч из которых доступны в любой момент времени, компания обслуживает клиентов по всему миру и делает упор на HIT (Human Intelligence Tasks, задачи для человеческого разума).
| Тип данных: | Большинство |
| Открытость: | Проприетарная |
| Методика: | Краудсорсинг |
| Отрасли: | Большинство отраслей |
| Соотношение цены и качества: | Выше среднего |
| Оптимальность времязатрат: | Высокая |
| Инструкции для новичков: | Да (учебные материалы и служба поддержки) |
| Скорость обучения пользователей: | От средней до высокой |
| Механизмы контроля качества: | Система квалификаций позволяет выбирать и создавать конкретные критерии требований к работникам в вашем проекте. В MTurk есть три типа заранее заданных квалификаций — Masters, System и Premium Qualifications. |
| Вычислительные мощности: | Для клиента не требуются |
Компания: Hive
Веб-сайт: https://thehive.ai/
Краткое описание:
Ещё одна базирующаяся в Кремниевой долине компания Hive была основана в 2013 году. Она имеет две основных бизнес-парадигмы: Hive Models (ИИ-решения «под ключ» для предварительно обученных моделей глубокого обучения) и Hive Data (внутренние решения аннотирования данных для снабжения и разметки моделей ML). Утверждается, что для последней у компании есть 2 миллиона участников, работающих на её платформе. В 2021 году компания собрала 85 миллионов долларов дополнительного финансирования.
| Тип данных: | Множество, в том числе текст, изображения, звук, видео, облако 3D-точек |
| Открытость: | Проприетарная |
| Методика: | Краудсорсинг и аутсорсинг + генерация данных на заказ |
| Отрасли: | Технологическая, автомобильная, производственная, гостиничная, розничная торговля, электронная коммерция |
| Соотношение цены и качества: | От среднего до хорошего |
| Оптимальность времязатрат: | От средней до высокой (зависит от задачи) |
| Инструкции для новичков: | Да (+ поддержка от назначаемых менеджеров проектов) |
| Скорость обучения пользователей: | Высокая |
| Механизмы контроля качества: | Интегрированная разметка вручную. Валидация пограничных случаев в реальном времени, дополнительное обогащение данных при необходимости. Тестирование проектов по небольшим выборкам данных. |
| Вычислительные мощности: | В большинстве случаев от клиента не требуются |
Компания: Webtunix AI
Веб-сайт: https://www.webtunix.com/
Краткое описание:
Расположенная в Нью-Йорке Webtunix, основанная индийскими предпринимателями — это консалтинговая компания в сфере Big Data, помогающая бизнесам достигать своих целей в области ИИ. В их число входят различные услуги разметки данных в компьютерном зрении, звуке, NLP и семантической сегментации, а также аннотирования видео и разметки линиями. Компания была основана в 2015 году.
| Тип данных: | Большинство, в том числе текст, изображения и видео |
| Открытость: | Проприетарная |
| Методика: | Специализированные программные инструменты под конкретные задачи с методологией human-in-the-loop (индивидуальный аутсорсинг и программирование данных в зависимости от технологий) |
| Отрасли: | Сельскохозяйственная, автомобильная, электронная коммерция, кибербезопасность, здравоохранение, банкинг, спорт |
| Соотношение цены и качества: | Среднее |
| Оптимальность времязатрат: | От средней до высокой |
| Инструкции для новичков: | Да (поддержка 24/7) |
| Скорость обучения пользователей: | Высокая (подробные руководства) |
| Механизмы контроля качества: | Квалифицированные живые асессоры и кураторы, функции автоматизации. |
| Вычислительные мощности: | В большинстве случаев от клиента не требуются |
Компания: iMerit
Веб-сайт: https://imerit.net/
Краткое описание:
iMerit была основана в 2012 году. Компания сочетает MAA и ручное аннотирование для упрощения бизнес-процессов и предоставления размеченных данных корпоративным клиентам. В основном компания работает в сферах компьютерного зрения и NLP и использует собственную команду опытных специалистов. iMerit, имеющая более четырёх тысяч сотрудников, сертифицирована по SOC 2 и обладает ещё одним сертификатом о защите данных — ISO 27001:2013. При разметке данных компания может использовать свои собственные инструменты аннотирования, инструменты клиента или сторонние инструменты.
| Тип данных: | Текст, изображения, звук, видео, геопространственные данные |
| Открытость: | Проприетарная (бесплатная проверка на выборке набора данных) |
| Методика: | Многоуровневый подход: за оценкой проекта следует аутсорсинг, краудсорсинг или программирование данных |
| Отрасли: | Транспортная, геопространственная, медицинская, электронная коммерция, сельское хозяйство, госсектор |
| Соотношение цены и качества: | От среднего до хорошего (зависит от задачи и методики) |
| Оптимальность времязатрат: | От средней до высокой |
| Инструкции для новичков: | Да (доступна всеобъемлющая поддержка клиентов) |
| Скорость обучения пользователей: | От средней до высокой (зависит от задачи и методики) |
| Механизмы контроля качества: |  Источник: веб-сайт iMerit |
| Вычислительные мощности: | В большинстве случаев от клиента не требуются |
Компания: CloudFactory
Веб-сайт: https://www.cloudfactory.com/
Краткое описание:
Базирующаяся в Рединге (Англия) CloudFactory заявила о своём присутствии на рынке в 2010 году и с тех пор предлагает аутсорсинговые и краудсорсинговые услуги разметки данных клиентам по всему миру. Компания специализируется на компьютерном зрении, NLP, наполнении данными и обогащении данных. CloudFactory называет свои конвейеры поставок «виртуальными сборочными линиями», на которых трудится примерно 1 миллион человек из развивающихся стран. Компания «выращивает их как лидеров, чтобы они способствовали решению проблемы бедности в своём обществе».
| Тип данных: | В основном текст, изображения, видео и звук |
| Открытость: | Проприетарная (бесплатное демо) |
| Методика: | Краудсорсинг и аутсорсинг (платформа управления рабочей силой), решения «под ключ» или платформа для найма/расширения рабочей силы |
| Отрасли: | Розничная торговля, транспортная, индустрия развлечений, образовательная, фитнес, сельскохозяйственная, производственная |
| Соотношение цены и качества: | От среднего до хорошего (зависит от методики) |
| Оптимальность времязатрат: | От средней до высокой (зависит от методики) |
| Инструкции для новичков: | Да (блог, вебинары, библиотека ресурсов) |
| Скорость обучения пользователей: | Высокая |
| Механизмы контроля качества: | Описаны в The Outsourcers' Guide to Quality на веб-сайте компании. Источник: веб-сайт CloudFactory |
| Вычислительные мощности: | В большинстве случаев от клиента не требуются |
Компания: Clickworker
Веб-сайт: https://www.clickworker.com/
Краткое описание:
Находящаяся в Германии Clickworker, основанная в 2008 году — это платформа краудсорсинга, которая специализируется на компьютерном зрении и NLP. Имея почти 3 миллиона участников (называемых «Clickworkers») из 136 стран, компания заявляет, что уже завершила более 1 миллиона проектов по разметке данных. Также у компании есть специализированное приложение Clickworker для смартфонов и планшетов.
| Тип данных: | Большинство, в том числе текст, изображения, звук и видео |
| Открытость: | Проприетарная (доступна бесплатная пробная версия) |
| Методика: | Краудсорсинг (удалённое управление, самообслуживание, API) |
| Отрасли: | Электронная коммерция, розничная торговля, исследования и Big Data |
| Соотношение цены и качества: | Выше среднего |
| Оптимальность времязатрат: | Высокая |
| Инструкции для новичков: | Да (набор учебных материалов) |
| Скорость обучения пользователей: | Высокая |
| Механизмы контроля качества: | Специальные процедуры обеспечения качества, например, статистическое тестирование процессов, аудиты и взаимное рецензирование. Clickworkers выбираются согласно уровню их обучения и результатов тестов, а также результатов их работы в прошлом. Источник: веб-сайт Clickworker |
| Вычислительные мощности: | В большинстве случаев от клиента не требуются |
Подведём итог
Основной сложностью в разметке данных является их качество. Эта сложность становится особенно актуальной при создании сложных моделей машинного обучения, в частности, при параллельном выполнении нескольких моделей. Сегодня уже существует множество готовых инструментов разметки, поэтому главной сложностью для дата-саентистов является подбор ПО для решения задачи — определение того, в каких ситуациях одни инструменты имеют преимущество перед другими. Это приводит к одному простому вопросу: как выполнить разметку данных с наименьшим объёмом усилий, времени и денег, в то же время обеспечив максимально возможные результаты?
Методики, в которых используется исключительно человеческий труд, постепенно оттесняются на обочину, поскольку учёные разработали способы разметки данных, сочетающие в себе ручные и компьютерные компоненты. Дальнейшее развитие, совершенствование и прогресс этих новых современных инструментов однозначно зададут темп на ближайшие годы, поскольку всё больше ИТ-компаний будут следовать по этому пути.
Понравилась статья? Еще больше контента на темы разметки, Data Mining и ML вы можете найти в нашем Telegram канале “Где данные, Лебовски?”
- Как подготовиться к сбору данных, чтобы не провалиться в процессе?
- Как работать с синтетическими данными в 2024 году?
- В чем специфика работы с ML проектами? И как разметить 1500 пузырьков руды на одном фото и не сойти с ума?
