
Люди часто думают, что код на ассемблере читается не просто плохо, а очень плохо. Но я думаю, что это совершенно не так.
Я всегда считал, что читаемость кода на совести программистов и язык здесь совершенно не причём.
Так вот, когда работал над одним из своих проектов, мне понадобился алгоритм для поиска следующего или предыдущего листа дерева. Алгоритм тривиальный, но реализация получилась такой компактной и простой, что решил опубликовать её в качестве иллюстрации того, что на ассемблере можно (и нужно) писать удобочитаемый код.
Честно говоря, я сомневаюсь, что на языке высокого уровня можно написать это более компактно и понятно.
Но возможно я ошибаюсь. Увидим далее в статье.
Дерево для которого писался код, является упорядоченным, двусвязным и с произвольным количеством дочерних узлов. Каждый узел, описывается следующей структурой:
struct Node
.parent dd ? ; к родительскому узлу
.f_child dd ? ; к первому дочернему узлу
.l_child dd ? ; к последнему дочернему узлу
.next dd ? ; к следующему узлу в списке дочерних узлов
.prev dd ? ; к предыдущему узлу в списке дочерних узлов
ends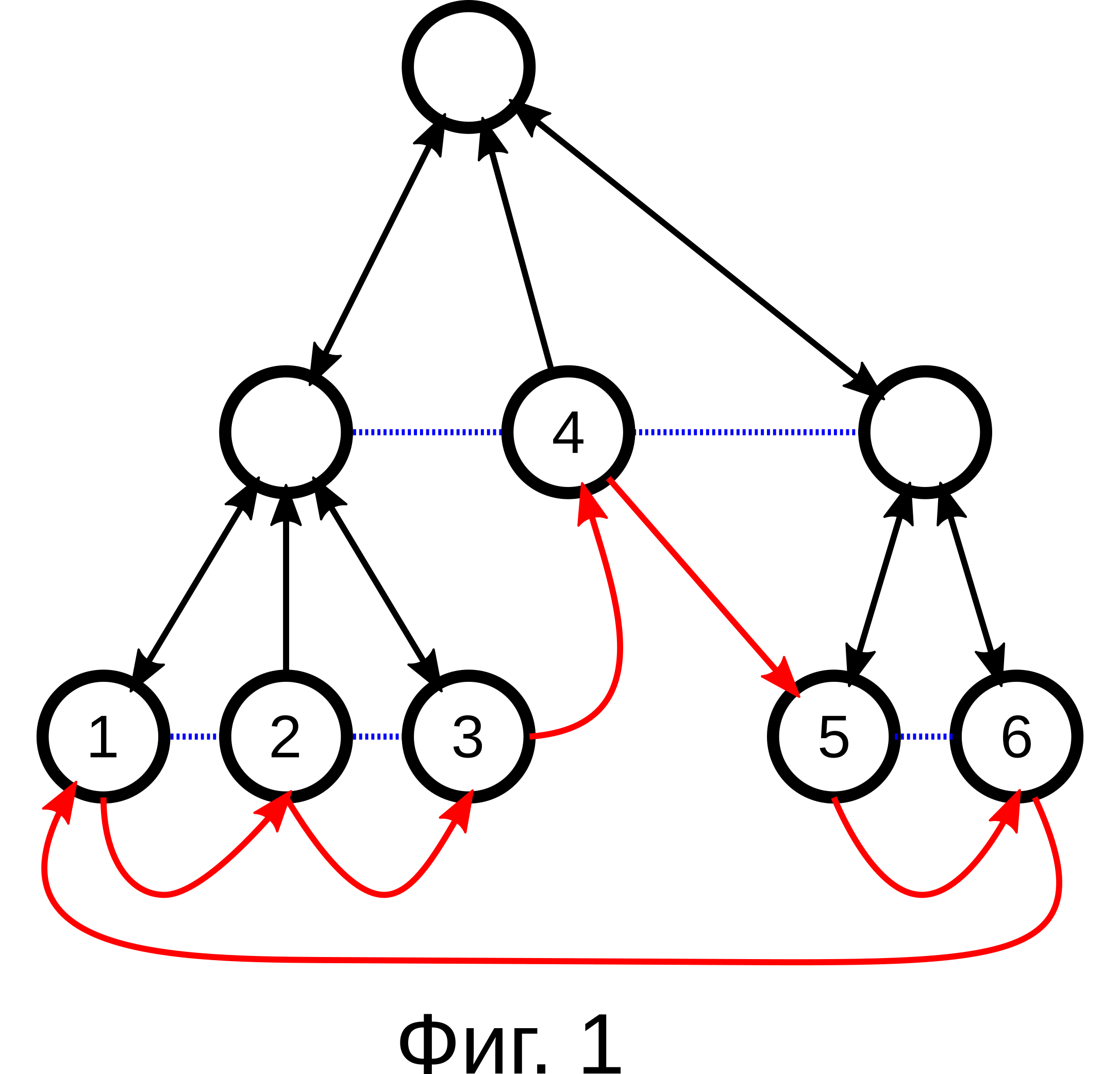 Все дочерние узлы родительского узла образуют двусвязный список (поля .next, .prev). Родительский узел указывает только на начало и конец этого списка, соответственно через указатели
Все дочерние узлы родительского узла образуют двусвязный список (поля .next, .prev). Родительский узел указывает только на начало и конец этого списка, соответственно через указатели .f_child и .l_child.
Задача: По заданному листу дерева, надо найти следующий лист. Если лист последний, найти первый лист дерева.
Это показано на Фиг.1; Синим пунктиром изображены связи через .prev и .next, черными линиями связи через .parent, .f_child и .l_child, а красными линиями, изображена последовательность переходов по алгоритму.
Я работаю над ОС-независимой GUI библиотекой на ассемблере. В этой библиотеке, каждое окно, представляет узел дерева с такой структурой.
Обсуждаемый поиск по листьям нужен, для передачи фокуса вперёд или назад при нажатии на клавиши Tab или Shift+Tab.
Конечно, в библиотеке это сложнее – нужно проверять хочет ли данное окно фокус и может ли его принять (например окно невидимое, или неактивное) в данный момент. Но это детали, которые никак не влияют на обсуждаемой теме.
В обсуждаемом коде используются только 3 инструкции:
CMP– сравнивает два операнда и устанавливает флаги состояния.
CMOVcc– условная пересылка данных – если условиеccвыполнено, данные пересылаются из второго операнда в первый. Если условие не выполнено, то ничего не делается. Условия могут быть разными, но здесь используется толькоNE– не равно, то есть, инструкцияCMOVNE.
Jcc– условный переход. Условия те же самые как вCMOVcc. Если условие выполнено, переход делается. Если нет, исполнение продолжается вниз.
Квадратные скобки в выражениях на ассемблере означают содержание памяти на данном адресе. А значение в скобках, это адрес. То есть, примерно[eax+Node.f_child]означает, что вычисляется адрес как сумма содержания регистраeaxи константыNode.f_child(Node.f_child == 4 в этом случае), читается содержимое так полученного адреса и с ним что-то делается – пересылается куда-то (mov, cmov) или сравнивается с чем-то (cmp) и т.д.
А вот и сам код в девяти инструкциях:
; Поиск следующего листа
; EAX == указатель к исходному листу дерева.
.next:
cmp [eax + Node.next], 0
cmovne eax, [eax + Node.next]
jne .to_leaf
cmp [eax + Node.parent], 0
cmovne eax, [eax+Node.parent]
jne .next
.to_leaf:
cmp [eax + Node.f_child], 0
cmovne eax, [eax + Node.f_child]
jne .to_leaf
; Здесь EAX содержит указатель к следующему листу дерева.; Поиск следующего листа
; EAX == указатель к исходному листу дерева.
.next: ; Ищем следующий узел:
cmp [eax + Node.next], 0 ; Это последний узел?
cmovne eax, [eax + Node.next] ; если нет, берём следующий...
jne .to_leaf ; ...и идём к выходу.
cmp [eax + Node.parent], 0 ; это корневой узел?
cmovne eax, [eax+Node.parent] ; если нет, берём родительский узел...
jne .next ; ...и ищем следующий узел.
.to_leaf: ; Идём вниз к листьям:
cmp [eax + Node.f_child], 0 ; это лист?
cmovne eax, [eax + Node.f_child] ; если нет, идём вниз...
jne .to_leaf ; ...и повторяем
; Здесь EAX содержит указатель к следующему листу дерева.У этого кода есть только один изъян. Если у дерева есть несколько корневых узлов, то алгоритм не будет переходить правильно от последнего к первому листу.
Конечно, это уже будет не одно дерево, а несколько несвязанных между собой деревьев (точнее связанные только через .prev и .next). Но структура позволяет такое, так что было бы хорошо, если алгоритм корректно работал с такими деревьями.
Этого можно достичь, добавив еще три инструкции. А точнее, те же три инструкции еще раз:
.next:
cmp [eax + Node.next], 0
cmovne eax, [eax + Node.next]
jne .to_leaf
cmp [eax + Node.parent], 0
cmovne eax, [eax+Node.parent]
jne .next
.to_first: ; Вот здесь.
cmp [eax + Node.prev], 0
cmovne eax, [eax + Node.prev]
jne .to_first
.to_leaf:
cmp [eax+Node.f_child], 0
cmovne eax, [eax+Node.f_child]
jne .to_leafТот же самый код можно использовать и для поиска предыдущего листа, поменяв prev на next и f_child на l_child:
.prev:
cmp [eax + Node.prev], 0
cmovne eax, [eax + Node.prev]
jne .to_leaf
cmp [eax + Node.parent], 0
cmovne eax, [eax+Node.parent]
jne .prev
.to_last:
cmp [eax + Node.next], 0
cmovne eax, [eax + Node.next]
jne .to_last
.to_leaf:
cmp [eax + Node.l_child], 0
cmovne eax, [eax + Node.l_child]
jne .to_leafВы наверное заметили, что весь код состоит из одинаковых триплетов:
cmp [variable], 0
cmovne REG, [variable]
jne somewhereЭто дополнительно увеличивает удобочитаемость кода. Достаточно однажды понять, как эти три инструкции работают в связке, чтобы понять весь код.
А теперь давайте сравним этот код с эквивалентным кодом на C++.
У меня, с трудом (я не силён в C++), но получилось как-то так:
Структура:
struct Node {
Node *parent;
Node *f_child;
Node *l_child;
Node *prev;
Node *next;
};И сам код:
// Поиск следующего листа
// leaf == указатель к исходному листу дерева.
while (1) {
if (leaf->next) {
leaf = leaf->next;
break;
};
if (leaf->parent)
leaf = leaf->parent;
else {
while (leaf->prev) leaf = leaf->prev;
break;
};
};
while (leaf->f_child) leaf = leaf->f_child;
// Здесь, leaf указывает на следующий лист.Я оставил только код, который непосредственно делает работу. Постарался оформить его, так, чтобы был более читабельным. Но все равно, ассемблерный код читается легче.
В коде на C++ нет никакого общего шаблона. Чтобы понять, как он работает, надо рассматривать каждую линию в отдельности и в связке с остальными.
А может это мне только кажется и зависит от знания языка? Или этот код можно написать лучше?
Компилировал так:
g++ -m32 -Os ./test.cpp -o ./testРезультатом компиляции стал следующий код (я намерено использовал те же самые метки как в ассемблерном коде, чтобы легче было сравнивать):
.next:
mov edx, [eax + Node.next]
test edx, edx
jnz .to_leaf
mov edx, [eax + Node.parent]
test edx, edx
jz .to_first
mov eax, edx
jmp .next
.to_first:
mov edx, eax
mov eax, [eax + Node.prev]
test eax, eax
jnz .to_first
.to_leaf:
mov eax, edx
mov edx, [edx + Node.f_child]
test edx, edx
jnz .to_leafНадо сказать, что код получился достойным. Не идеальным для чтения, но этого от компилятора и не требуется.
Но даже этот неидеальный код, мне кажется, читается лучше, чем оригинальный код на C++.
Напишите в комментариях, считаете ли вы ассемблерный код сложным для чтения? А что вам мешает – незнание языка, программисты, которые пишут плохо читаемый код, или вы думаете, что это свойство ассемблера и ничего нельзя сделать в принципе?
