
Сталкиваетесь ли Вы с необходимостью использовать внешние источники данных? Если да, то Вам пригодится алгоритм автоматизированного сбора информации с сайта – парсер. Разберём процесс создания такого алгоритма на примере сайта ЕФРСБ.
Перед Data Science специалистами регулярно встают задачи, для решения которых необходима информация из внешних источников, и часто её объёмы такие, что ручной поиск занимает непозволительно много времени. Автоматизированный сбор данных с сайта (парсинг) позволяет получить необходимые для задачи сведения, экономя время.
Одна из таких задач встала перед нашей командой: понадобились данные о процедуре признания физических лиц банкротами. Для этого был разработан алгоритм парсинга сайта Единого федерального реестра сведений о банкротстве (ЕФРСБ) с использованием библиотек requests и bs4. В настоящей статье предлагаю рассмотреть процесс создания этого парсера и познакомить Вас с решениями некоторых проблем, с которыми мы столкнулись.
Разработку алгоритма мы решили разбить на 2 части:
Извлечение данных по одному клиенту с проработкой всех возможных сценариев (см. далее)
Обёртка в цикл
for client in clientsИтак, мы имеем ФИО и дату рождения клиента:
lastName, firstName, middleName, birthDateи хотим узнать следующее: дата судебного решения о признании его банкротом (если клиент есть в реестре) и дата получения требований кредитора. Для этого необходимо: на странице DebtorSearch ввести в соответствующие поля ФИО (поле поиска по ДР отсутствует), перейти к результатам поиска, затем перейти к карте клиента. С карты клиента необходимо будет перейти к сообщениям: «сообщение о судебном акте» и «уведомление и получении требований кредитора».
Как осуществить каждый из этих переходов? Метод requests.get(), реализующий отправку GET запроса, имеет множество параметров, но нас будут интересовать 2: url и headers. Мы видим, что url страницы до ввода ФИО и нажатия «поиск» совпадает с url страницы после этих действий. Разница между этими страницами заключается в Request Headers (мы можем увидеть их при включённых DevTools). Обратим внимание на header cookie:
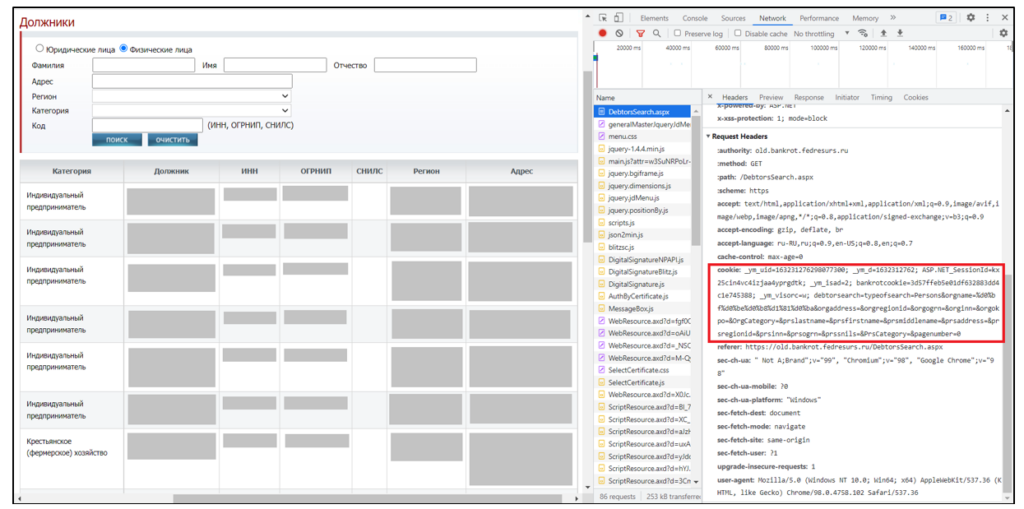
DebtorSearch до ввода ФИО
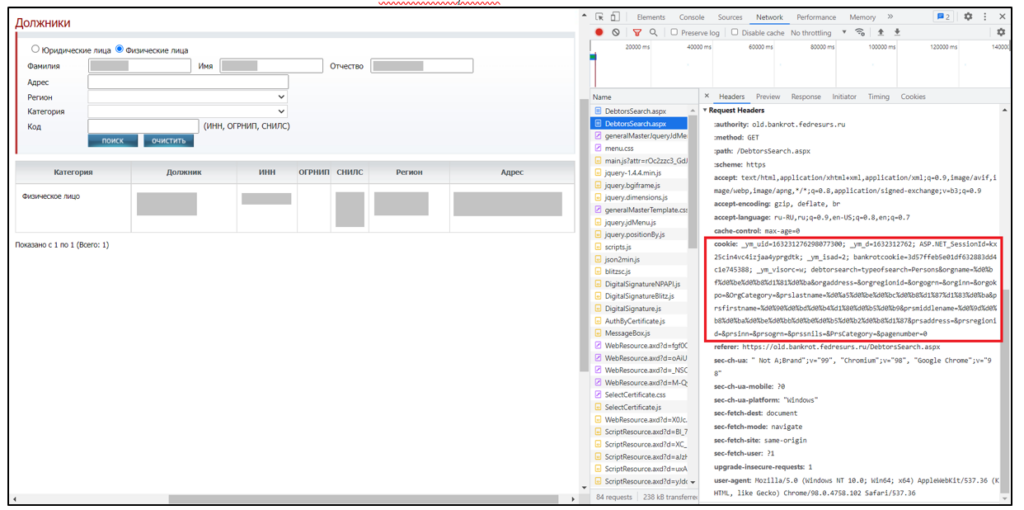
DebtorSearch после ввода ФИО и поиска
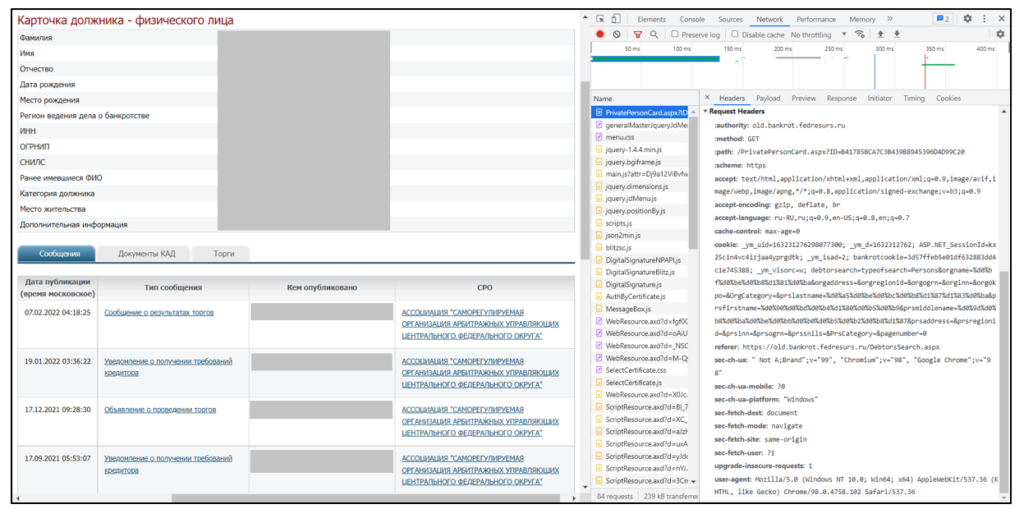
PersonPrivateCard
Мы видим, что в cookie заключена информация о введённом ФИО, т.е. мы можем перейти к этой странице следующим запросом (закодировав ФИО в URL с помощью библиотеки urllib):
def get_headers_given_names(last_name, first_name, middle_name):
"""
Возвращает Request Headers для urlDebtorSearch для данного ИНН
"""
return {
'cookie': '_ym_uid=163231276298077300; _ym_d=1632312762; bankrotcookie=3fc2d76c5528e08666189e359ecccc4d; ASP.NET_SessionId=0dcvz4pmoczmscpu040gjacq; _ym_isad=2; _ym_visorc=w; bankrotcookie=d924485957220205521f7e0c20b77824; debtorsearch=typeofsearch=Persons&orgname=%d0%bf%d0%be%d0%b8%d1%81%d0%ba&orgaddress=&orgregionid=&orgogrn=&orginn=&orgokpo=&OrgCategory=&prslastname=' + urllib.parse.quote_plus(last_name) + '&prsfirstname=' + urllib.parse.quote_plus(first_name) + '&prsmiddlename=' + urllib.parse.quote_plus(middle_name) + '&prsaddress=&prsregionid=&prsinn=&prsogrn=&prssnils=&PrsCategory=&pagenumber=0',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
response_debtors_search = requests.get('https://old.bankrot.fedresurs.ru/DebtorsSearch.aspx', headers=get_headers_given_names(last_name, first_name, middle_name))В response_debtors_search.text теперь содержится текст html-страницы ответа, и в нём мы можем найти ссылку для перехода на карту клиента. Отметим здесь, что мы стараемся предусмотреть все возможные сценарии, т.е. должны предположить, что найдутся два и более клиента с одинаковыми ФИО. Мы знаем дату рождения клиента, поэтому будем открывать по очереди карты всех найденных по ФИО клиентов, пока не найдём клиента с нужной датой рождения. Ссылки извлечём с помощью библиотеки re:
links_given_name = re.findall('PrivatePersonCard\.aspx\?ID=.*"', response_debtors_search.text)Переход на карту первого клиента:
response_private_debtor_card = requests.get('https://old.bankrot.fedresurs.ru/' + links_given_name[0], headers=get_headers_given_names(last_name, first_name, middle_name))Имея текст html-страницы карты клиента, мы должны получить дату рождения и ссылки для перехода на сообщения о судебном акте и уведомлении требований кредитора. Здесь следует отметить, что существует 2 разных подхода к поиску данных в тексте ответа: один заключается в поиске паттернов в тексте (так мы искали ссылки для перехода к картам клиентов). Другой подход подразумевает использование библиотеки bs4: она позволяет создать вложенную структуру данных из текста html-страницы, которая повторяет структуру html-разметки:
soup_private_debtor_card = BeautifulSoup(response_private_debtor_card.text, 'lxml')В такой структуре можно осуществлять поиск не по фрагменту текста, а, например, по атрибутам html-тегов. Преимущество такого подхода в том, что он не привязан к паттерну в тексте, в котором может быть опечатка (и тогда поиск по паттерну не даст результата). С другой стороны, у него есть и существенный недостаток: нельзя быть уверенным, что атрибуты тегов (например, id) не менялись в течение эксплуатации сайта.
Мы извлечём дату из текста с помощью регулярного выражения (подразумевающего любой формат) из подстроки, начинающейся с искомого паттерна:
def get_date_after_pattern(text, pattern):
"""
Возвращает дату из подстроки text, начинающейся с pattern
"""
date_regex = r'\b(0[1-9]|[12][0-9]|3[01])[- /.](0[1-9]|1[012])[- /.](19|20\d\d)\b'
try:
date_parts = re.findall(date_regex, text[text.index(pattern):text.index(pattern) + 250])
return ['.'.join(map(str, x)) for x in date_parts][0]
except:
return '(н/д)'Теперь мы можем извлечь дату рождения с карты клиента:
date_birth = get_date_after_pattern(text.lower(), 'дата рождения')Чтобы продемонстрировать возможности bs4, найдём ссылки для перехода на необходимые сообщения, перебирая все теги <a> (ссылки), пока не найдём ссылки с заданным текстом:
def get_ref_for_message_window(soup, text):
"""
Возвращает список ссылок для перехода к окнам сообщений “text”
"""
links_all = soup.find_all('a')
return [link['href'].split('.aspx?')[1] for link in links_all if text in link.text.lower()]
links_for_message_1 = get_ref_for_message_window(soup_private_debtor_card, 'сообщение о судебном акте')
links_for_message_2 = get_ref_for_message_window(soup_private_debtor_card, 'уведомление о получении требований кредитора')Отметим, что из логики процесса следовало, что нас интересует последнее по дате сообщение о судебном акте, т. е. links_for_message_1[-1], откуда возьмём дату принятия решения так же, как и дату рождения из карты клиента. Что касается второго сообщения, мы будем перебирать все уведомления, пока не найдём в тексте уведомления название компании-кредитора; в нём извлечём дату (опять же, аналогично дате рождения с карты клиента). Сам процесс перебора идентичен перебору карт клиентов до обнаружения нужной даты рождения – поэтому мы не будем приводить здесь этот код, а отметим последний важный факт для реализации запросов в цикле.
На сайте реестра установлено ограничение на количество запросов в единицу времени, и при превышении этого порога (точное значение неизвестно) ip-адрес блокируется на час. Решить эту проблему можно либо с помощью проксирования, либо добавив в циклы паузы – например, с помощью time.sleep(random.random() * 2).
В заключение отметим, что я показал основные инструменты, которыми осуществляется парсинг, и опустил описание таких тонкостей, как обработка исключений, создание чекпойнтов и т. д. Также отмечу, что в ходе работы над этим алгоритмом я не столкнулся с таким механизмом защиты, как captcha, и способы его обхода/избегания стали для меня дальнейшим направлением развития в теме парсинга.
Надеюсь, что описанные методы окажутся Вам полезными и
Спасибо за внимание!
