В этой статье я бы хотел рассказать о совместной работе с @elizavetakluchikova и командой над тем, как мы применяем машинное обучение для облегчения поиска и оценки людей с суицидальными наклонностями по постам в социальных сетях, в частности, в Твиттере.
Прежде всего, мы отсылаем читателя к предыдущей статье, где рассказывалось о суицидальных играх, о команде людей, которая за шиворот вытаскивает детей из петли или с подоконника, а также о проблемах, с которыми сталкивается команда. Я прочитал эту статью и подумал, что мог бы помочь им, применив свои знания в обработке естественного языка. В результате работы, был собран датасет, который можно скачать здесь, а также была написана научная статья, которая была опубликована на конференции Диалог 2022.
Этот же пост был написан совместно с Лизой, где мы углубленно рассказываем о психологической подоплеке работы, а также о некоторых деталях работы, которые не были упомянуты в статье.
UPD: Если вы знаете кого-то, кто по вашему мнению, может идти к совершению суицида или вы после прочтение поняли, что кто-то из ваших знакомых подходит под описание, вы можете сообщить об этом мне.
Содержание
Глобальная проблема
Вообще, когда мы говорим о разных психологических трудностях и расстройствах, довольно характерная проблема заключается в том, что люди просто не обращаются за помощью. Например, при клинически выраженной депрессии время от начала заболевания до первого обращения к специалисту может занять несколько лет. Это связано как с тем, что некоторые психические заболевания (та же депрессия) не выражают себя явно, так и с рядом социально-культурных факторов, которые мы разберем чуть позже.
Другой проблемой может являться то, что человек недостаточно хорошо функционирует, чтобы за помощью обратиться. Это может выражаться как в тотальной неспособности к целенаправленной деятельности, как в случае депрессии, так и, например, в локальных трудностях с коммуникацией своих потребностей, как при выраженной социальной тревоги.
Если же говорить про людей с высоким риском суицида, то парадокс заключается в том, что они демонстрируют особенные трудности в обращении за помощью, при том, что наиболее остро в ней нуждаются.
Какие пережитые события и состояния характерны для людей с повышенным суицидальным риском
Здесь мы кратко опишем типичные сценарии из жизни, которые значительно повышают вероятность развития суицидального поведения
Проблемы в семье - насилие, неисполнение родительских обязанностей, конфликтные отношения между родителями и т.д.
Насилие - буллинг в школе, кибербуллинг, сексуальный абьюз и т.д.
Особенности развития - нетипичное нейроразвитие, психосексуальное развитие.
Психические расстройства - панические атаки, социальная фобия, депрессия, БАР, ПРЛ, РПП, химические зависимости.
Что мешает людям обращаться за психиатрической помощью
Давайте разберем, какие же социально-культурные факторы мешают людям обращаться за помощью.
Первой в списке идет стигматизация такой помощи, а также людей с психическими заболеваниями. Если вы поспрашиваете своих знакомых, чем грозит психиатрический диагноз, то вам обязательно встретится что-то похожее на “ну у меня возникнут проблемы с работой/получением прав/получением разрешения на оружие/т.д.”. Кроме этого добавляется еще боязнь травли, в основном, для подростков, и отчуждения, в основном, для взрослых, т.к. психиатрический диагноз автоматически притягивает к себе образ юродивого, “больного на голову” или “опасного для окружающих”.
Следующим фактором является насильственный или безрезультатный опыт получения помощи. Несмотря на то, что метод карательной психиатрии в нашей стране перестали применять с развалом Советского союза, отголоски той практики трансформировались в методы воспитания некоторых родителей, когда в адрес детей поступают угрозы по типу “если будешь плохо себя вести, то сдам тебя в психушку”. К сожалению, в некоторых случаях угрозы переходят в действие. Другим отголоском этого является то, что если ребенок говорит о своей гендерной дисфории (грубо говоря, он мальчик внутри тела девочки или наоборот) или гомосексуальности, психиатрическая помощь может принимать форму конверсионной терапии, когда ребенка насильственно пытаются сделать “нормальным”, что наносит непоправимый вред человеку, и без того находящемуся в тяжелом психическом состоянии.
Эти и некоторые другие случаи сопровождает переживание безрезультатности – человек приходит возможно даже с собственным желанием решить какие-то внутренние проблемы, но в конечном итоге не получает ничего. В более общем случае, врачи часто оказывают неквалифицированную помощь – по разным причинам, из которых можно ярко выделить две: непрофессиональность и слабая заинтересованность. Возможно, вы могли наблюдать то же самое, когда ходили в обычные государственные больницы. Большое ли у вас потом было желание туда вернуться?
Третий фактор – банальное отсутствие знания куда обратиться за помощью. Все знают, где находится больница, а также что в неотложном случае надо звонить 112. Но знаете ли вы, где находится ближайший психоневрологический диспансер, например? А знаете ли координаты кризисных линий – таких, например, как Твоя Территория или детский телефон доверия (8 800 2000 122)? Кризисная линия бесплатно предоставляет услугу психологической поддержки. На нее можно позвонить или написать и поделиться практически любыми проблемами, а профессиональные психологи помогут успокоиться и подскажут как быть в данной ситуации. Отсутствие информированности о подобных линиях помощи и поддержки тесно связано со вторым фактором - субъективно кажется, что такие службы не смогут помочь или обязательно передадут информацию о звонившем в “соответствующие органы” (после чего на дальнейшей жизни можно поставить крест). А диспансеров боятся потому, что это и есть те самые “соответствующие органы”.
Четвертый фактор - негативные убеждения
Этот фактор мы рассмотрим отдельно, т.к. можно сказать, что он включает в себя первые два фактора и именно он демотивирует человека от поиска и обращения за помощью. В частности, мы рассмотрим, как этот фактор влияет на формирование суицидальных установок.
Негативные убеждения можно представить в виде треугольника, где на вершинах мы обозначим объект этих убеждений. Заметим, что группы убеждений взаимодействуют между собой.

Вот так выглядят негативные установки о себе
Я скучный, неинтересный, поэтому никто не захочет выслушивать мои жалобы.
Я сломанный, дефектный, поэтому меня все равно не получится вылечить.
Я слабый и беспомощный,поэтому я не смогу справиться со своим состоянием.
Я не имею ценности, поэтому если я погибну, это не будет большой потерей.
Первая и четвертая установки часто формируются при регулярной травле и социальной изоляции, особенно, если это происходит и внутри семьи. Вторая же формируется при закономерном сравнении себя с другими, в случае выраженных особенностей развития. А когда неудачные попытки справиться с проблемой сталкиваются с социальной установкой на то, что нужно справляться со своими проблемами самостоятельно, формируется третья установка.
А вот так выглядят негативные установки о мире:
Этот мир – ужасное место. Ничего удивительного, что мне так плохо; как может быть иначе?
Другие люди – холодные и равнодушные, поэтому им нет смысла жаловаться и обращаться к ним за поддержкой.
Другие люди будут испытывать слишком большие неудобства, если я буду говорить им о своих переживаниях, так что лучше их не беспокоить.
Специалисты на самом деле бессильны чем-то помочь; их единственная цель – обогащение, поэтому к ним нет смысла обращаться.
Опять же, здесь мы видим последствия травли и социальной изоляции (первый фактор). Вторая и третья установка формируются тогда, когда человек делится своими проблемами, а ему начинает рассказывать, что он все придумал, что на самом деле он очень хорошо живет, а вот дети в Африке голодают. Также, вполне естественно, что не каждый готов выслушивать проблемы другого – хотя бы потому, что это так или иначе портит настроение слушающему. Поэтому, послушав раз-другой, слушающий может начать избегать разговоров, подавая сигнал для формирования третьей установки. Четвертая же установка является продуктом второго фактора – вредительской и неквалифицированной помощи.
И, наконец, негативные убеждения о будущем выглядят так:
Поскольку я пропащий человек, ничего хорошего мне не светит, поэтому нет смысла пытаться улучшить свою жизнь.
Если я буду лечиться у психиатра, эта информация потом обязательно всплывет, и мне не позволят поступить в ВУЗ и не возьмут ни на одну работу, поэтому лучше не лечиться вовсе.
Моя семья все равно не позволит мне получить лечение, поэтому я не буду сообщать о своих симптомах.
Первая установка является чисто логической. Если человек не видит ничего хорошего в мире и себе и на полном серьезе поставил на себе крест, то следствием является отсутствие каких-либо целей в принципе. А там где нет цели, нет и мотивации что-то делать. Вторую установку мы уже обсуждали выше: мы пока, как общество в целом, не созрели признать, что ментальные проблемы существуют и их надо лечить с помощью профессионалов, как, например, язву желудка или аппендицит. Третья установка перекликается со второй установкой – про мир, где люди холодные. Страшно, когда эти люди – твоя семья. Мотивация у родителей может быть самая разная, включая представление о том, что в ВУЗ нельзя будет поступить и на работу не возьмут.
Теперь давайте сделаем шаг назад и посмотрим, на то, как переплетаются эти установки и факторы. Мы можем видеть, что они подпитывают друг друга и человек, особенно неокрепший умом ребенок, оказывается в ловушке собственных убеждений. С какого то момента, человек незаметно начинает считать свое состояние нормальным, поэтому даже не думает о том, чтобы обратиться за помощью. Проблема в том, что подобные установки очень сильно конфликтуют с тем, что он видит вокруг – а он видит людей смеющихся, влюбляющихся, проводящих время вместе, преуспевающих в чем-то – и с тем, что происходит внутри: такое состояние конфликта сил не прибавляет и вот уже кажется, что выход в окно неплохой способ прекратить этот кошмар или, неосознанно, добиться того, чтобы, наконец, другие люди услышали крик о помощи.
Так, а причем тут социальные сети?
В процессе развития суицидальных симптомов человек не перестает искать способы облегчения своих страданий, прежде чем перейти к радикальному решению. Часто, чтобы облегчить негативное душевное состояние, достаточно бывает выговориться, поделиться наболевшим и социальные сети выступают здесь площадкой, где это можно сделать. Таким образом, посты в социальных сетях служат клапаном внутреннего напряжения, сродни гласу вопиющего в пустыне - ты написал куда-то о своих чувствах, вынес их из себя и не так важно, в сущности, что это, может быть, никто и не прочитает.
Однако простое ответное сообщение в духе “я тебя понимаю”, случайный ретвит или лайк разрушают установку о том, что до человека никому нет дела, что снижает суицидальный риск, да и, в целом, градус внутренней напряженности. А уж если человеку кто-то скажет “расскажи об этом подробнее”, то у него вообще переворачивается мир. Именно на этом механизме работают волонтеры. Они отыскивают потенциальных суицидентов, просят рассказать о проблеме и делятся информацией о ресурсах помощи – например, о кризисных линиях, где уже профессионалы смогут им помочь. На этой же, кстати, механике работают и группы смерти: куратор суицидальной игры – это такой человек, который демонстрирует живую заинтересованность в игроке и его проблемах. Только он настаивает на том, что лучшее решение – это как раз суицид.
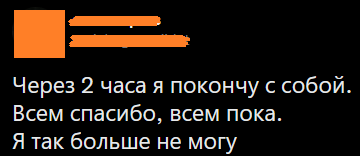
В таком крайнем случае, как на скрине выше, люди сообщают в социальных сетях о своем намерении уйти из жизни. Если вовремя отловить такое сообщение, можно успеть избежать трагедии.
Ниже представлены два скрина из твиттера, показывающие как могут выглядеть сообщения, помогающие выпустить пар.


Один в поле – не воин
Проблема в том, что таких людей достаточно много, и они не только пишут о своих душевных переживаниях, но и делятся произошедшим с ними за день, обсуждают тренды, смеются над мемами и т.д. Причем на нейтральные темы они пишут гораздо больше, чем на резко негативные. Поэтому искать такие сигнальные сообщения бывает затруднительно.
Если пользоваться таким наивным подходом, как поиск по словам, то окажется, что в выдачу попадает множество нерелевантных постов, где слова используются не в том контексте, с саркастическим или ироническим оттенком. Прибавить к этому катастрофически малое количество волонтеров, и получается весьма сложная ситуация, когда значительную часть времени человек тратит на просеивание нерелевантной информации. Собственно, эта проблема была отражена в прошлой статье Лизы.
Когда я ее прочел, мне пришла в голову идея: а почему бы не фильтровать такие неинформативные сообщения, чтобы упростить работу волонтера? Предполагалось, что получится сделать некий сервис, куда волонтер мог бы ввести ссылку на твиттер-аккаунт, а в ответ выводились бы сигнальные сообщения, по которым волонтер уже мог бы решать, что делать. Я написал Лизе о своей идее, и работа закипела.
Последовательность работы
На картинке ниже представлена последовательность работ по реализации этой идеи. Я буду стараться описывать ход работ так, чтобы его мог понять человек, никогда ранее не сталкивавшийся с проектами машинного обучения, но для желающих разобраться в деталях оставлю ссылку на этот замечательный пост.

Постановка задачи
Любой проект, включая проекты в машинном обучении, начинается с постановки задачи, от этого зависит успех всего предприятия.
Итак, мы хотим, чтобы финальная модель определяла сигнальные сообщения из всей массы сообщений. Для этого мы разработали следующую классификацию сообщений
Исторические или текущие негативные события – сообщения, носящие фактический характер, описывающие негативные ситуации, которые могут произойти с человеком, такие как попытки и факты изнасилования, проблемы с родителями, издевательства в школе и травля, бедность (личная или семейная).
Текущее негативное эмоциональное состояние – сообщения, содержащие отображение субъективного негативного отношения к себе и окружающим: сообщения о том, что нет сил, терпения, присутствует желание умереть, ощущение одиночества, ненависть к себе и т.д.
Сообщения о намерении совершить суицид, содержащие указания на конкретные действия, как на первом скриншоте. Сюда же входит поиск способов совершения суицида
Суицидальная тематика – все то, что как-то связано с суицидом, но трудно поддается классификации или не попадает в другие категории.
Сообщения, не имеющие отношения к суицидальной тематике
Первая категория была сформирована по соображениям, что негативные события могут оставлять эмоциональные воспоминания, которые, актуализируясь при встрече с ассоциативно связанными триггерами, могут дестабилизировать человека, увеличивая риск суицида. Чем больше таких воспоминаний и триггеров в окружающей среде, тем более уязвимым является человек.
Вторая категория является косвенным показателем психологического состояния человека: если увеличивается плотность сообщений с таким содержанием, то это говорит о психической нестабильности человека в моменте.
Название третьей категории говорит само за себя в контексте поиска людей с суицидальным поведением.
Иногда люди выражают свои эмоции и состояния напрямую, а используют косвенные способы, как например: поэзия, связанная со смертью, или какие-то выражения, или цитаты. Поскольку их трудно отнести к предыдущим категориям, мы выделили их отдельно.
Сбор и разметка данных
Поскольку на тот момент, когда я присоединился к команде, в наличии уже были обработанные аккаунты, мне оставалось только написать краулер, который ходил бы по этим аккаунтам и собирал тексты постов. Хочу заметить, что в качестве целей использовались только те аккаунты, которые были помечены как “подозрительные” и “кризисные”. Первые – это такие аккаунты, где проскакивают сообщения о тяжелом прошлом, но также присутствует позитивная информация: например, о друзьях или целях в жизни. В кризисные же попадают аккаунты, где сообщается о самоповреждениях, тяжелой судьбе и отсутствии помощи. Сюда же входят люди, сообщающие о совершенных или планируемых попытках суицида.
По мере накопления данных, мы запустили процесс разметки данных согласно вышеприведенной классификации. Поскольку волонтеров было мало, нам необходимо было привлечь сторонних людей.
Мы составили инструкцию, в которой описали категории, явления, подпадающие под определенные категории, а также дали некоторые общие рекомендации.
Сперва мы прибегли к краудсорсингу – разметке с помощью большего количества людей за вознаграждение, которую можно организовать на платформе Яндекс.Толока. Имея в прошлом неудачный опыт, мы подошли к организации по всем правилам: составили учебный набор из 10 задач на категорию, на котором тренировали пользователей, отбирали тех, кто завершил 90 процентов задач без ошибок, и только затем давали реальные данные. К сожалению, даже такие пользователи не показали хороших результатов на реальных данных, поэтому мы решили нанять индивидуальных разметчиков. Несмотря на их дороговизну относительно краудсорсинга, у индивидуальных разметчиков выше уровень личной ответственности за выполнение задач и, кроме того, они получали регулярные отзывы о своей работе. Также, уже исходя из отзывов разметчиков, мы постоянно улучшали инструкцию.
Среди проблем, с которыми сталкивались разметчики, мы можем выделить:
попытки интерпретировать тексты, основываясь на своих собственных убеждениях и личном опыте, что приводит к неправильной классификации;
неоднозначность некоторых текстов (например, потому что изначально это была серия твитов или ответ на какое-то сообщение).
тексты, содержащие сложные фразеологизмы, сарказм, сокращения и мемы
тексты, подпадающие под две категории.
Хочется также отметить, что мы не могли позволить себе разметить тексты несколькими индивидуальными разметчиками, чтобы обеспечить перекрытие и посчитать согласованность, поэтому, чтобы обеспечить какой-то уровень качества, мы организовали процесс следующим образом.
Разметчики получали тексты в виде блоков по 3-5 тысяч сообщений. В процессе разметки они могли оставить любое количество текстов, в которых они сомневались, на проверку – они должны были указать категорию, которую они считают нужной, и комментарий, почему они так считают, после чего отправить сообщения на супервизию. После того, как блок был размечен, его присылали нам обратно. Мы принимали блок, если в случайно отобранной пятипроцентной выборе примеров на каждую тысячу было не больше 3 ошибок. Имеется в виду, что если блок был на 3 тысячи, то случайно отбиралось 150 текстов и пределом было 9 ошибок.
Вдобавок к этому, к получившемуся датасету мы применили алгоритм удаления шума TracIn, про который можно более подробно почитать в этой статье.
Анализ и выявление признаков
В первую очередь, было интересно посмотреть на распределение категорий в получившемся датасете. Оно представлена в таблице ниже:
Имя класса | Количество текстов |
Нейтральный текст | 27619 |
Негативное эмоциональное состояние | 2809 |
Описание негативных событий | 2131 |
Суицидальная тематика | 205 |
Намерение суицида | 21 |
Как видно, несмотря на то, что аккаунты были отобраны подозрительные и кризисные, нейтральных текстов – подавляющее большинство. Сразу становится понятен масштаб исходной проблемы. Нужно также отметить, что в ходе нашей работы, к сожалению, нам пока не удалось собрать достаточное количество примеров для 3 и 4 категории, поэтому мы исключили их из анализа.
Что обычно рассматривают при анализе текстовых датасетов – это распределение по текстам длины сообщений в токенах (в словах, поясню для читателей, незнакомых с NLP).

Как видно из диаграммы распределения, в целом все классы ведут себя одинаково – и предсказуемо с точки зрения того, что сообщения были написаны на платформе для микроблогов.
Поскольку эмоджи стали значимой частью текстового общения, мы не могли обойти их стороной и решили посмотреть, каким образом эмоджи связаны с категориями. В общей сложности в нашем датасете присутствует 12551 случаев использования эмоджи c набором из 481 уникальных. Мы выделили 10 самых часто встречаемых эмоджи и построили распределение отношения частоты употребления эмоджи к числу текстов в категории по, собственно, категориям. Результат показан на картинке ниже

Как можно видеть, самым частым эмоджи является "громко плачущее лицо" 😭 и для 2 категории этот эмоджи является самым значимым, что согласуется со значением категории. Но при этом для других категорий он тоже стоит на первом месте по значимости. Заметно также, что смайлики с сердцем(❤️, 💓, 💖) являются значимыми с большим перевесом только для 5 категории.
Далее, нам была интересна лексика людей, проявляющих склонность к суицидальному поведению. Для ответа на этот вопрос мы использовали три подхода.
Первым, наиболее простым способом было сравнение лексики с каким-то более общим корпусом (набором текстов), в качестве которого выступил известный датасет для обучения классификации сантиментов, составленный из постов в Твиттере. Мы привели слова к нормальной форме (существительные и прилагательные к первому лицу, единственному числу, глаголы – к неопределенной форме) и вычленили слова, которые были уникальны для нашего датасета, затем выделили самые часто встречающиеся. Их вы можете видеть в таблице
Слово | Кол-во | Слово | Кол-во |
мем | 102 | бсд | 52 |
дазай | 97 | секси | 50 |
геншин | 82 | ментальный | 50 |
мью | 81 | пж | 49 |
тикток | 76 | атсума | 48 |
краш | 74 | рпп | 48 |
рп | 65 | фд | 46 |
хорни | 63 | осама | 45 |
дилюк | 57 | эстетика | 43 |
вайб | 55 | косплей | 40 |
Из этой таблицы мы можем выделить несколько групп. В первую группы мы можем выделить
современный сленг-англицизмы: мем, краш, хорни, вайб;
слова, относящиеся к играм и аниме: геншин, дилюк (игра Genshin Impact), бсд, атсума, дазай, осама (аниме Bungou stray dogs или Великий из бродячих псов),
язык твиттера: мью (mutual - взаимный подписчик), рп (реплай - ответ), фд (фендом), пж (пожалуйста).
Исходя из того, что аккаунты, с которых проводился сбор данных, принадлежат подросткам, подобные группы кажутся естественными.
Картинка-мем

Следующий метод, которым мы воспользовались, называется аллотаксонометрия. Его суть заключается в сравнении двух систем, результат которого, показывает, какие элементы двух систем сильнее всего отличаются между собой, таким образом можно характеризовать системы относительно друг друга. В качестве системы в нашем случае выступил датасет. И вновь в качестве сравнительного корпуса мы использовали датасет сентиментов. В качестве выходных данных при использовании этого метода мы получаем таблицу, в которой показано, насколько сильно изменился ранг каждого элемента, а также насколько значимым является это изменение при сравнении систем. Рангом в данном случае называется индекс элемента системы (слова, в нашем случае) в списке частот. Важным условием является то, что элементы должны быть распределены согласно закону Ципфа, что выполняется для частот слов.
Индекс | Слово | RTD | Ранг в нашем корпусе | Ранг в общем корпусе | Индекс | Слово | RTD | Ранг в нашем корпусе | Ранг в общем корпусе |
0 | бл**ь | 3.070 | 7 | 175 | 25 | обидно | 1.241 | 868 | 131 |
1 | завтра | 2.429 | 70 | 8 | 26 | день | 1.240 | 8 | 4 |
2 | блин | 2.403 | 82 | 9 | 27 | зачет | 1.239 | 5573 | 334 |
3 | на**й | 1.968 | 44 | 745 | 28 | заболевать | 1.239 | 763 | 122 |
4 | болеть | 1.941 | 136 | 19 | 29 | киев | 1.227 | 12436 | 473 |
5 | скучать | 1.834 | 517 | 44 | 30 | аниме | 1.226 | 249 | 2786 |
6 | сегодня | 1.688 | 15 | 5 | 31 | приходиться | 1.218 | 387 | 83 |
7 | человек | 1.632 | 4 | 11 | 32 | комп | 1.217 | 1995 | 214 |
8 | жаль | 1.553 | 429 | 57 | 33 | просто | 1.215 | 5 | 10 |
9 | жалко | 1.553 | 1075 | 92 | 34 | дома | 1.209 | 232 | 60 |
10 | пробка | 1.516 | 3516 | 165 | 35 | винд | 1.208 | 25752 | 640 |
11 | нг | 1.463 | 2243 | 149 | 36 | друг | 1.208 | 27 | 76 |
12 | тип | 1.456 | 75 | 558 | 37 | по**й | 1.207 | 183 | 1435 |
13 | школа | 1.382 | 123 | 32 | 38 | печально | 1.194 | 5553 | 365 |
14 | свой | 1.375 | 6 | 14 | 39 | заканчиваться | 1.194 | 328 | 77 |
15 | жизнь | 1.360 | 16 | 46 | 40 | снег | 1.186 | 971 | 152 |
16 | серия | 1.346 | 556 | 87 | 41 | ппц | 1.181 | 9842 | 478 |
17 | буквально | 1.338 | 178 | 2093 | 42 | выздоравливать | 1.171 | 8477 | 460 |
18 | печаль | 1.338 | 2509 | 194 | 43 | блиин | 1.169 | 22574 | 672 |
19 | нету | 1.332 | 2371 | 191 | 44 | выходной | 1.163 | 505 | 106 |
20 | чел | 1.309 | 219 | 2915 | 45 | обновлять | 1.153 | 4337 | 354 |
21 | пятница | 1.305 | 1683 | 169 | 46 | скоро | 1.138 | 125 | 42 |
22 | е**ть | 1.291 | 111 | 740 | 47 | ау | 1.138 | 820 | 32308 |
23 | пи***ц | 1.254 | 41 | 144 | 48 | личность | 1.138 | 457 | 7089 |
24 | суицид | 1.251 | 615 | 31353 | 49 | порез | 1.121 | 800 | 26578 |
Первое, что бросается в глаза: ненормативная лексика, особенно популярное междометие, является весьма значимой частью лексики нашего датасета. Интересно также то, что хотя эти тексты были написаны подростками, такие слова как "школа, пятница, нг (новый год)" имеют более высокий ранг в общем корпусе, а "человек, жизнь, личность, друг" – наоборот. Кроме того, мы видим, что слова "суицид" и "порез" также очень характерны для нашего корпуса. Ну и, разумеется, про аниме подростки в нашем корпусе говорят чаще, чем в общем.
Последний метод, который мы применили для изучения лексики, мне подсказал мой научный руководитель Илья Соченков. Точнее, это не метод, а характеристика тематической значимости. Если в предыдущих методах мы прибегали к другому корпусу, то благодаря характеристике тематической значимости можно увидеть различия внутри датасета в зависимости от категорий. В двух словах, эта характеристика подсчитывает значимость каждого слова для каждой категории относительно всех других. Чем-то это похоже на предыдущий метод, только предпосылки различаются. Мы выделили по двадцать слов в каждой категории, которые имели наибольшее значение характеристики. Результат представлен в таблице ниже:
| Класс 1 | Класс 2 | Класс 5 |
| Класс 1 | Класс 2 | Класс 5 |
0 | прл | сато | мью | 10 | диагноз | прорыдать | дазай |
1 | антидепрессант | чудовище | чуять | 11 | селфхармить | упорно | петь |
2 | рвота | усталый | сезон | 12 | препарат | рас***рить | солнышко |
3 | больничка | медосмотр | вайб | 13 | желчь | здохнуть | фанфик |
4 | галлюцинация | поплакать | хорни | 14 | выстраивать | ничтожный | спи**ить |
5 | побочка | подпускать | добавлять | 15 | тревожка | пусто | геншин |
6 | бессонница | забиваться | картинка | 16 | трезвый | шататься | рт |
7 | частичка | унижение | читатель | 17 | биполярка | уе**сь | косплей |
8 | кп | подавлять | вкус | 18 | до**ывать | кулак | мило |
9 | порез | комок | ау | 19 | перечить | будовать | тикток |
В целом, мы видим согласованность групп слов со значением категорий. В первой категории мы видим упоминание болезней (прл – пограничное расстройство личности), разных симптомов и медицинской лексики. Во второй категории представлены слова, выражающие эмоциональное состояние, а в пятой – нейтральные слова, причем они в значительной степени пересекаются со словами, выделенные первым методом.
Помимо лексических признаков, мы попытались найти синтаксические особенности классов. Для этого мы получили частеречную разметку наших текстов (имя существительное, прилагательное, глагол и т.д.), сгруппировали их по три штуки, триграммы, и посчитали силу взаимосвязи каждой триграммы с соответствующим классом. В качестве метрики взаимосвязи воспользовались поточечной взаимной информацией. В результате мы получили следующую таблицу (расшифровка граммем находится здесь)
Класс 1 | Класс 2 | Класс 5 |
V|S-PRO|S | V|S-PRO|ADV | PR|V|S |
CONJ|S-PRO|S-PRO | CONJ|V|S-PRO | CONJ|ADV|PR |
CONJ|V|S-PRO | PR|A-PRO=m|S | A=pl|S|NONLEX |
S-PRO|ADV-PRO|V | ADV|V|S | S-PRO|PR|A-PRO=pl |
S|CONJ|PART | S|NONLEX|NONLEX | PRAEDIC|V|<none> |
V|V|S-PRO | ADV|V|PR | CONJ|S-PRO|A=n |
ADV-PRO|S-PRO|V | V|CONJ|S | A=n|CONJ|S-PRO |
PART|PART|V | PRAEDIC|<none>|<none> | CONJ|CONJ|S |
V|CONJ|PR | ADV|V|V | S|S-PRO|A=m |
S|CONJ|PR | ADV|V|CONJ | S-PRO|S-PRO|CONJ |
К сожалению, я не смог их как-то интерпретировать. Единственное, что я могу сказать, что по статистическому тесту, называемому U-тест Манна-Уитни, связи этих наборов статистически значима. Причем, интересно, что различия между первым и вторым классом не носят значимого характера.
| Класс 1 | Класс 2 | Класс 5 |
Множество тегов 1 класса | 1 | 8.5e-1 | 1.8e-4 |
Множество тегов 2 класса | 7.0e-1 | 1 | 3.1e-3 |
Множество тегов 5 класса | 2.4e-3 | 2.4e-3 | 1 |
Построение модели
Закончив изучение нашего датасета, мы приступили к построению, собственно, модели, которая должна помочь в работе волонтерам. Как обычно это бывает, мы протестировали несколько моделей.
Для того, чтобы представить тексты в виде векторов, с которыми могут работать модели, мы использовали стандартный для NLP подход счетного вектора, когда каждый текст у нас представляется вектором размерности V, где V - это объем словаря (набор уникальных слов), а отдельные размерности является количеством употребления соответствующего слова в тексте. Вторым способом представления текстов в виде вектора мы использовали современную модель BERT. Конкретно, мы использовали реализацию ruberttiny-2.
Вы спросите, для чего нужен был тот анализ, если мы вообще не используем его результаты? Дело в том, что мы продолжаем собирать датасет, включая не только Твиттер, чтобы повысить репрезентативность всех классов. Подобный анализ же позволит нам при сборе данных фильтровать явно уж не релевантные тексты. А также, поможет нам составлять датасеты из других доменов.
Кстати говоря о репрезентативности. Поскольку текстов для категории негативных событий и эмоционального состояния по отдельности совсем мало, сравнивая с нейтральными текстами, мы решили объединить эти классы в один за счет их родства в негативности.
В качестве метрик мы использовали точность, полноту и F1-метрику. А в качестве моделей мы использовали
три модели из класса детекции выбросов:
IsolationForest,
Local Outlier Factor
OneClassSVM;
три ансамблевые модели:
LogReg Stacking,
RandomForest
XGBoost;
и, разумеется, простую логистическую регрессию.
Мы решили рассмотреть алгоритмы детекции выбросов в виду того, что даже объединенный класс значительно уступал в количестве нейтральным текстам, поэтому можно было бы рассмотреть нейтральные тексты нормальными, а интересующие нас - выбросами.
Результаты проведения экспериментов показаны в таблице ниже
|
|
| Точность | Полнота | f1 | f1 macro | ||||
|
|
| Средн. | СКО | Средн. | СКО | Средн. | СКО | Средн. | СКО |
Метод | Век-я | Класс |
|
|
|
|
|
|
|
|
Isolation Forest | BERT | 0 | 0.558 | 0.351 | 0.000 | 0.000 | 0.001 | 0.000 | 0.334 | 0.000 |
1 | 0.500 | 0.000 | 1.000 | 0.000 | 0.667 | 0.000 | ||||
Count | 0 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.333 | 0.000 | |
1 | 0.500 | 0.000 | 1.000 | 0.000 | 0.667 | 0.000 | ||||
Local Outlier Factor | BERT | 0 | 0.301 | 0.022 | 0.009 | 0.001 | 0.017 | 0.001 | 0.338 | 0.001 |
1 | 0.497 | 0.001 | 0.979 | 0.003 | 0.659 | 0.001 | ||||
Count | 0 | 0.502 | 0.000 | 0.997 | 0.000 | 0.668 | 0.000 | 0.344 | 0.002 | |
1 | 0.768 | 0.033 | 0.011 | 0.002 | 0.021 | 0.004 | ||||
Logistic Regression | BERT | 0 | 0.948 | 0.002 | 0.765 | 0.005 | 0.847 | 0.003 | 0.680 | 0.003 |
1 | 0.382 | 0.004 | 0.777 | 0.011 | 0.512 | 0.004 | ||||
Count | 0 | 0.909 | 0.007 | 0.754 | 0.018 | 0.824 | 0.013 | 0.617 | 0.018 | |
1 | 0.313 | 0.021 | 0.598 | 0.030 | 0.410 | 0.024 | ||||
LogReg Stack | BERT | 0 | 0.947 | 0.002 | 0.774 | 0.004 | 0.852 | 0.002 | 0.680 | 0.005 |
1 | 0.391 | 0.010 | 0.770 | 0.006 | 0.518 | 0.009 | ||||
Count | 0 | 0.923 | 0.035 | 0.632 | 0.299 | 0.693 | 0.302 | 0.617 | 0.018 | |
1 | 0.292 | 0.078 | 0.656 | 0.190 | 0.384 | 0.065 | ||||
OneClassSVM | BERT | 0 | 0.486 | 0.015 | 0.577 | 0.220 | 0.512 | 0.108 | 0.685 | 0.005 |
1 | 0.491 | 0.013 | 0.401 | 0.202 | 0.414 | 0.130 | ||||
Count | 0 | 0.621 | 0.006 | 0.374 | 0.001 | 0.467 | 0.001 | 0.538 | 0.180 | |
1 | 0.552 | 0.002 | 0.772 | 0.007 | 0.644 | 0.003 | ||||
Random Forest | BERT | 0 | 0.856 | 0.004 | 0.994 | 0.001 | 0.920 | 0.002 | 0.558 | 0.006 |
1 | 0.770 | 0.032 | 0.112 | 0.007 | 0.196 | 0.010 | ||||
Count | 0 | 0.856 | 0.005 | 0.991 | 0.001 | 0.918 | 0.003 | 0.545 | 0.010 | |
1 | 0.671 | 0.028 | 0.098 | 0.012 | 0.171 | 0.019 | ||||
XGBoost | BERT | 0 | 0.899 | 0.004 | 0.931 | 0.003 | 0.915 | 0.001 | 0.703 | 0.007 |
1 | 0.548 | 0.018 | 0.445 | 0.016 | 0.491 | 0.013 | ||||
Count | 0 | 0.899 | 0.004 | 0.923 | 0.003 | 0.911 | 0.002 | 0.693 | 0.005 | |
1 | 0.516 | 0.016 | 0.442 | 0.009 | 0.476 | 0.009 | ||||
Из нее мы видим, что Isolation Forest и Local Outlier Factor не работают на наших данных - идеальная полнота и половинчатая точность говорит о том, что алгоритм присвоил всем примерам одинаковый класс. Также, мы видим, BERT векторизация показала лучшие результаты почти со всеми моделями в сравнении со счетной векторизацией. Единственная модель, где счетная векторизация дала лучший результат это OneClassSVM, она же единственная работающая модель из класса детекции выбросов. Стоит еще также отметить, что модель OneClassSVM дала лучший результат по метрике F1 по детекции интересующего нас первого класса.
Лучший результат по точности дала модель RandomForest, при том, что имеет самые худшие показатели по полноте для первого класса. А лучшей моделью по полноте у нас получилась логистическая регрессия.
Интересно заметить, что XGBoost, что RandomForest дали очень хорошие показатели по нулевому классу, т.е. по сути фильтровать его они научились хорошо, но поскольку XGBoost показывает не такую ужасную полноту по первому классу, даже при условии половинчатой точности, она дала лучший результат по F1 macro, что делает ее победителем среди всех моделей.
Эксплуатация модели
Построив модель, я написал небольшое web-приложение, которому можно скормить ссылку на Твиттер и Телеграмм конференцию и получить список всех негативных, позитивных сообщений (для этого использовалась библиотека Dostoevskiy).
У нас есть далеко идущие планы - мы хотим сделать небольшую платформу для психологов-суицидологов и волонтеров, чтобы им было проще мониторить своих подопечных.
Дальнейшие планы
Мы планируем расширение датасета и улучшение его качества. Кроме этого датасета, у нас в планах собрать мультимодельный датасет - картинки, видео, аудио, а также социальные связи. А вообще, глобальная наша цель - это научиться прогнозировать кризисность аккаунтов, чтобы волонтер сразу видел степень кризисности, а также факторы, на основании которых модель приняла соответствующее решение.
Помогите нам
Однако, так как мы будем делать это уже на чистом энтузиазме, денег на разметку и оплату серверов просто напросто не всегда можно будет выделить. Поэтому, если вы хотите нам помочь, вы можете поддержать нас финансово здесь.
А может вы FullStack разработчик и вы хотели бы нас поддержать своими скилами в создании и развитии платформы. Если так, то свяжитесь либо со мной, либо с Лизой.
Благодарности
Мы хотим выразить благодарности нашим разметчикам: Ермаковой Дарине, Ульяновой Ирине и Калиновской Татьяне. Также, мы благодарим нашего героя-волонтера Бродскую Александру.
