Увидев очередную статью об утомившем всех Chat GPT от Open AI, рука невольно тянется в пистолету минусатору. Ну, в самом деле, сколько можно? Уже, кажется, все успели поиграть с чатом во всех возможных сценариях.
Однако один аспект, почему‑то, почти не затронут как на Хабре, так и в Рунете. Почему же все‑таки Chat GPT говорит по‑русски с весьма специфическим акцентом, который условно можно назвать «нейронным говорком»?
Чтобы понять суть вопроса, обратимся к теории. Чем занимается генеративная нейронная сеть такого типа?
Говоря просто и коротко она получает на вход набор токенов, пропускает их через некий «черный ящик» и выдает другой набор токенов. Вероятность выбора конкретного токена для ответа зависит от набора входящих токенов и конкретных настроек.
Но что же такое «токен»? Интересный факт заключается в том, что для английского языка токеном обычно выступают сочетания символов, зачастую совпадающие с короткими словами или часто встречающимися частями слов.
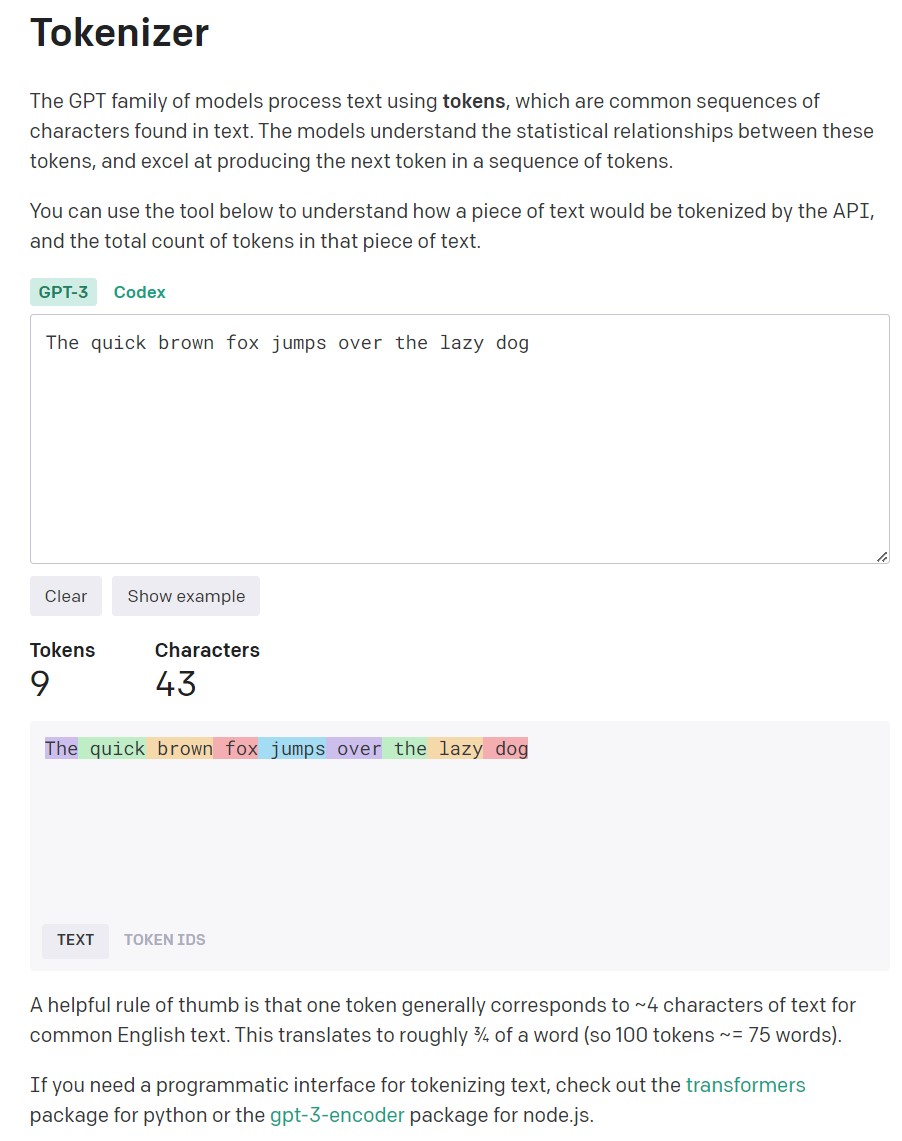
Возьмем, например, английскую панграмму:
“The quick brown fox jumps over the lazy dog”
Напомню, что панграмма — это предложение из минимального числа слов, содержащая в себе все буквы алфавита.
Официальный токенайзер Open AI
Показывает, что в этом предложении всего 9 токенов, содержащих 43 символа.
Однако с русским языком токенайзер Open AI работает совершенно иначе.
Популярная панграмма русского алфавита:
«Съешь ещё этих мягких французских булок, да выпей чаю»
Содержит 53 символа, однако на «упаковку» этой фразы токенизатору Open AI требуется 70 (Sic!) токенов.

Получается, что на вопросы на английском языке Chat GPT отвечает по словам, а на вопросы на русском языке он отвечает по буквам.
По сути выходит, что при общении на русском языке чат GPT как‑бы пропускает один дополнительный слой связанности. Тем удивительнее оказывается его умение генерировать осмысленный ответ на русском языке даже по буквам.
Кстати, специфику токенизации русского языка важно учитывать при использовании API Open AI и при работе в его песочнице.
Особо осторожно следует использовать параметр «Frequency penalty» (FP) (штраф за частоту повторов токенов), который регулирует вероятность повторения уже использованных токенов.
По задумке создателей «Frequency penalty» — снижает вероятность повторного использования слова в ответе нейросети.
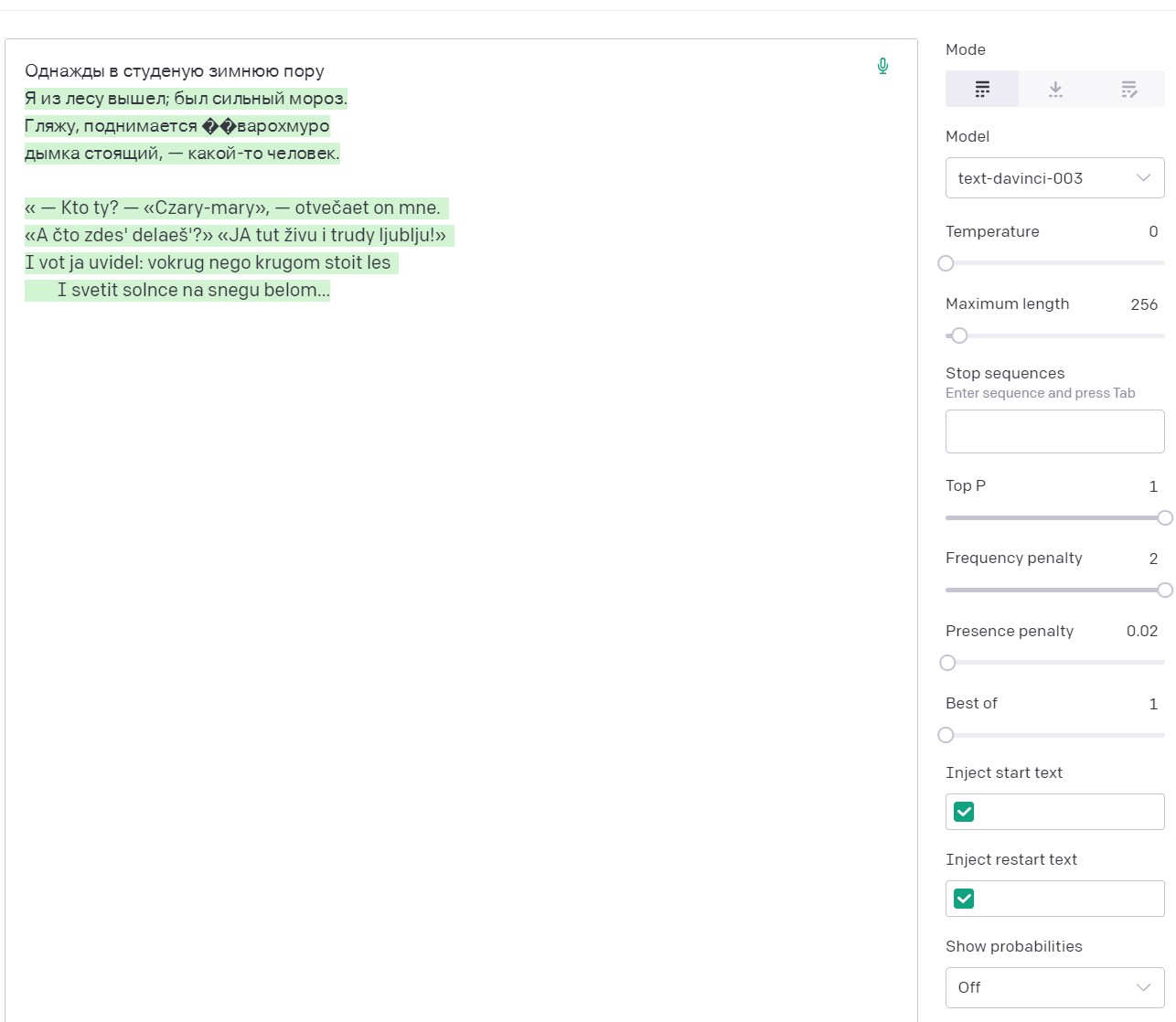
Однако, то, что работает с английским текстом не работает с русским, так как начинают штрафоваться просто повторы использования букв. И нейросети приходится идти на ухищрения, заменяя русские буквы латиницей, а потом и вовсе всем набором ASCII.
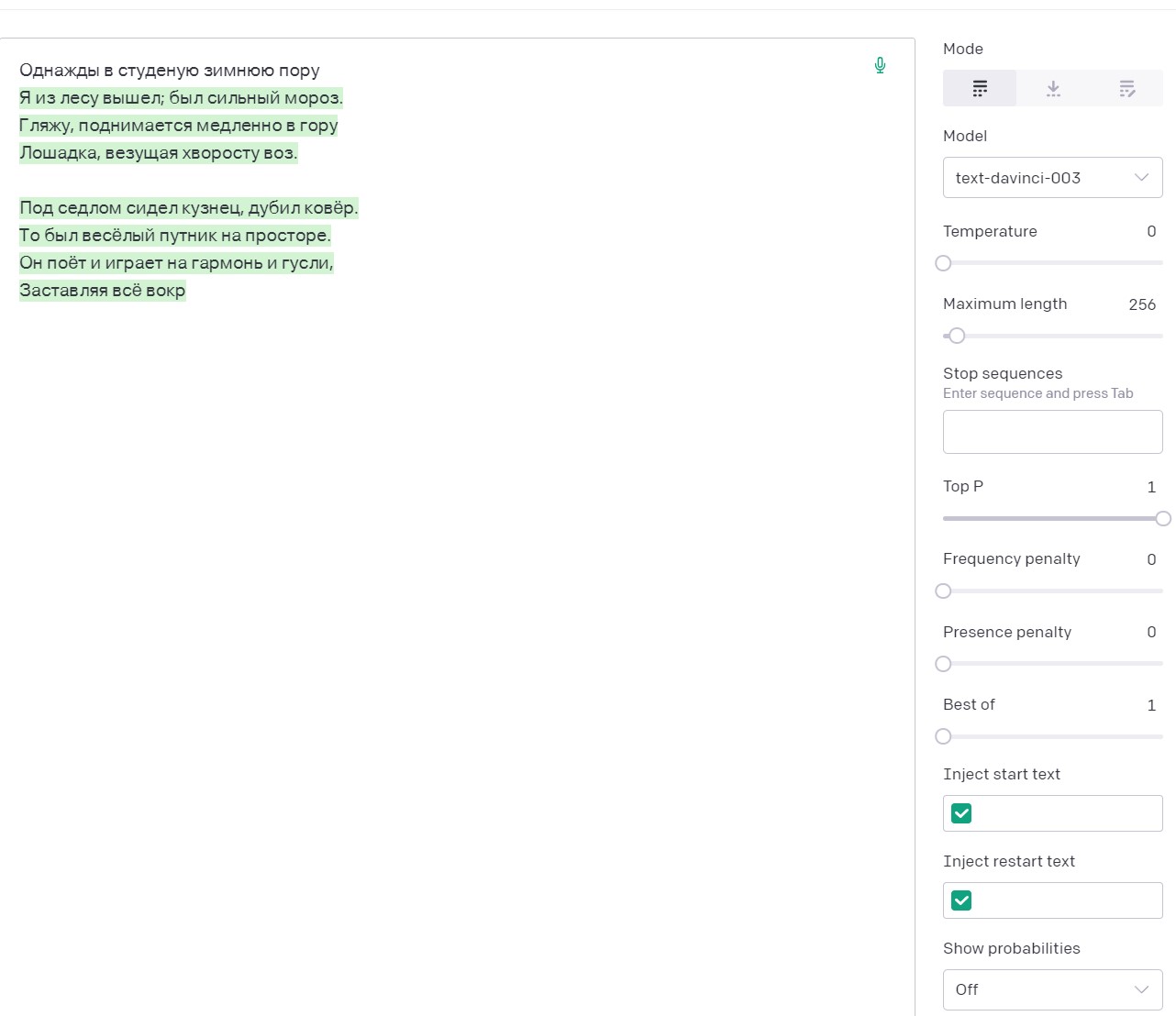
Например, затравка «Однажды в студеную зимнюю пору» в сочетанной с температурой установленной на 0, закономерно дает ожидаемое четверостишье Некрасова и лишь затем начинаются небольшие фантазии.
Та же затравка с FP=2, вначале также вспоминает Некрасова, но затем быстро переходит на латиницу.
В целом, эта ситуация помогает понять нам специфику того, как нейронная сеть понимает вопросы и генерирует ответы.
Ну и, разумеется, становится понятным почему у неройсети от Open AI возникает нейронный акцент. Слова в русском языке имеют склонения, спряжения и согласования по роду, числу, времени и т. п., которые формируются в первую очередь за счет окончаний. И зачастую в пограничной ситуации вероятность той или иной буквы в окончании для нейросети колеблется примерно на одном уровне. И она делает простительные иностранцу ошибки.
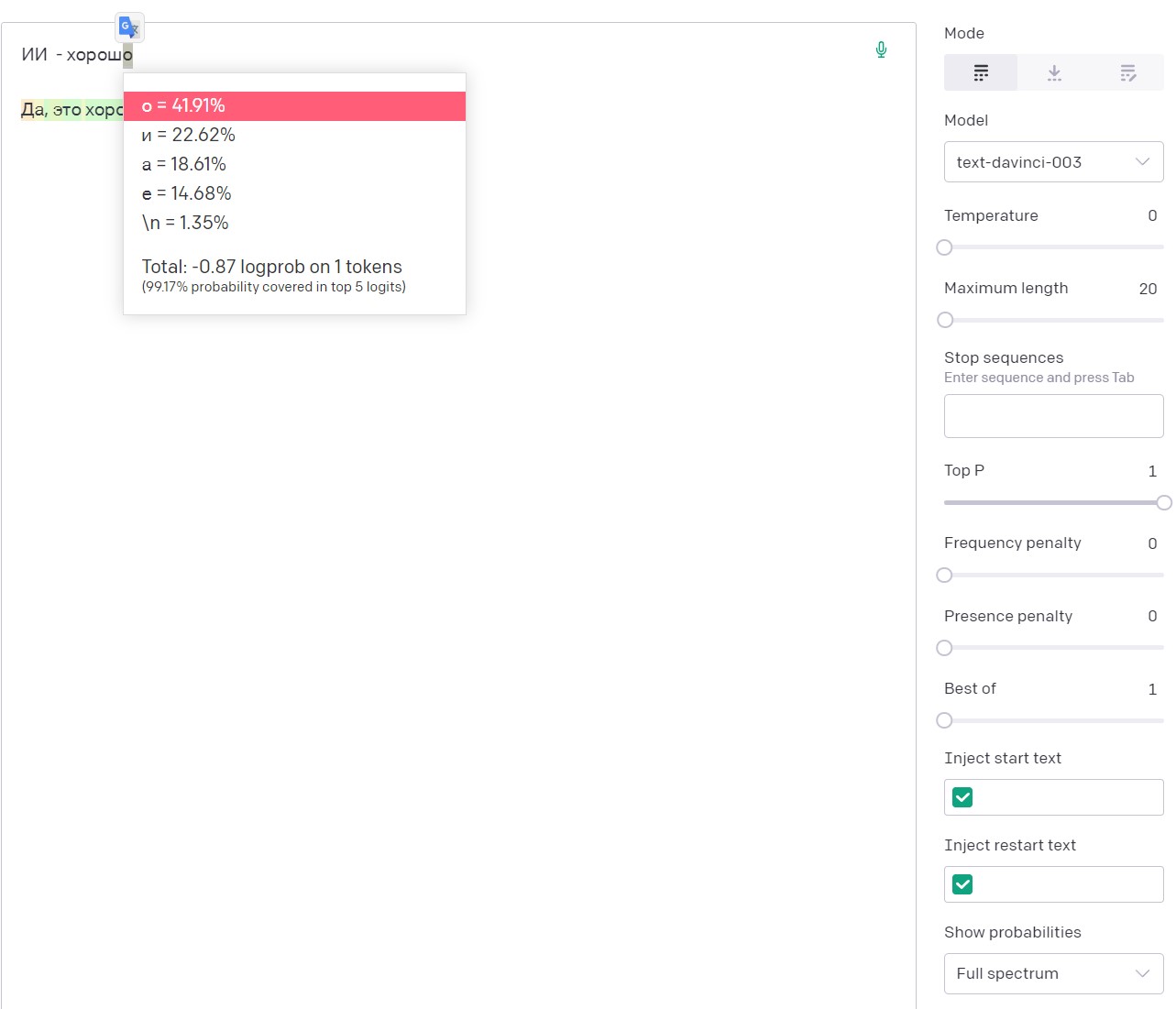
Кстати, для лучшего понимания специфики подбора очередного токена Open AI, можно в песочнице включить опцию показа вероятностей ответов Show probabilities → Full spectrum, которая покажет пять наиболее вероятных вариантов очередного токена с его конкретной вероятностью.
Видно, что с затравкой:
«ИИ — хорош»
Вероятность того, что после буквы «ш» идет токен «о» — составляет почти 42%
Итак, можно подвести итог. Специфика ответов на русском языке, сгенерированных нейронной сетью GPT-3.5 от Open AI, в первую очередь обусловлена не объемом выборки, а подходом к токенизации текста на кириллице. При работе с сетью, и в частности с ее API нужно учитывать, что при токенизации русского языка один символ <= 1 токену. Это приводит к быстрому исчерпанию лимита токенов и делает некоторые настройки (в частности FP) чрезвычайно чувствительными.
Самым актуальным остается вопрос: насколько особенности токенизации русского языка влияет на работу со смыслом текста?
А именно:
На каком уровне у нейросети возникает осмысленный ответ? (Конечно, не в том смысле, что она его понимает, а в том, что внутри сети возникает адекватная вопросу смысловая конструкция)
То‑есть формирует ли сначала нейросеть смысл ответа, а лишь затем переводит его в язык ответа (Английский или Русский)?
Или смысл проявляется непосредственно в процессе ответа?
Очевидно, что в первом случае глубина и осмысленность ответов на разных языках отличаться не будет. А во‑втором случае можно ожидать изменение качества смыслового наполнения ответа в зависимости от языка на котором отвечает модель.
Пока что я не пришел к определенному выводу. Понятно лишь, что на английском языке чат отвечает быстрее и корректнее с точки зрения грамматики. Но это полностью объяснимо спецификой токенизации в Open AI.
Буду благодарен за ваши мнения по этому вопросу.
