Одной из целей создания bullshitbingo.ru было посмотреть как ведёт себя google application engine (GAE) в более-менее реальных условиях. Особенно меня интересовала возможность получения собственной статистики, потому что то, что дают GAE и google analitics меня не устраивает по причинам, которые я приведу ниже. На сам пост особой реакции не было, но на главную он вышел и за день сайт получил примерно 15 тысяч загрузок, чего было вполне достаточно. Пик нагрузки составил 3-4 запроса в секунду, в итоге отведённый GAE лимит бесплатных ресурсов превышен не был.
Дальше описание особенностей работы со статистикой в GAE и во второй части графики про полученную нагрузку: собственные и те, которые формирует google. Постарался написать так, чтобы было понятно и тем, кто с GAE вообще не сталкивался.
Часть первая: статистика
GAE, конечно, показывает собственные графики, но есть ряд вопросов:
Проблема: GAE принципиально не умеет возвращать больше 1000 записей. Связано это с нереляционной моделью данных, и, возможно, кому-то это совсем не мешает, но при работе со статистикой мешает и сильно. Ещё одно соображение: строить какие-то сложные запросы и что-то вычислять прямо на стороне GAE может оказаться очень накладно, за процессорное время и хранение больших объёмов данных придётся платить. Так как статистика это, вообще говоря, «мёртвые» данные, не необходимые для функционирования, то её вполне можно забирать с серверов GAE куда-то себе, и уже там обрабатывать. Даже удобнее. Поэтому было решено выгружать статистику в виде csv-файлов и работать с ней уже как-то локально.
Выгрузка данных
Выгрузить данных это отдельная задача, потому что выбирать записи со смещением GAE тоже не умеет. Вернее умеет, но реализуется это фактически на стороне клиента (приложения, а не http-клиента, конечно). То есть, когда я хочу получить 10 записей начиная с 100-й, то сделать это можно, и для этого даже есть соответствующий параметр у вызова fetch(), но по факту из базы будут извлечены все 110 записей, просто первые сто API оставит себе. То есть просто так получить 100 записей начиная с 1000-й вообще нельзя никак. Об этом даже написано в документации, но как-то несколько туманно.
Выйти из положения можно если в качестве смещения использовать не номер строки, как я привык в реляционных БД, а дату/время. Время в GAE хранится аж с шестью знаками после запятой, так что вероятность внесения нескольких записей с абсолютно одинаковым временем крайне мала. Строго говоря, можно создать искусственное уникальное поле с монотонно возрастающими значениями, но такой необходимости я не вижу.
Всю статистику можно отсортировать по дате и выбирать по 1000 штук, каждый раз запоминая до какой даты удалось добраться, и в следующий раз отступать уже от неё. После того, как статистику гарантированно удалось выгрузить, её можно удалять. Дальше я эти фрагменты по 1000 записей называю страницами. Можно выбрать и другое число, но 1000 оказалась ничем не хуже, скажем 100, так что я остановился на 1000.
Скрипт выгрузки статистики в качестве параметра принимает максимальную дату (именно дату, без времени), до которой требуется выдать данные. На это есть две причины:
1) статистика поступает постоянно, но данные «за вчера и ранее» уже не изменятся;
2) выгружать сразу всю статистику может просто не получиться из-за большого объёма данных и ограничений на время выполнения, а так будет возможность выгружать хоть по одному дню.
Таким образом, алгоритм крупными мазками получился следующий:
При сравнении с $last_date используется «нестрого больше» потому что теоретически возможность точного совпадения времени у двух разных запросов всё-таки существует. Чтобы строки на стыке страниц не дублировались нужно сверить их уникальные ключи (а GAE такой ключ генерирует для любых хранимых в БД объектов) и опустить строку, если она уже была выгружена.
В случае с bullshitbingo данные за день, в который я опубликовал пост на хабре, выгрузились за 20 с небольшим секунд, то есть на грани фола. Если данных будет немного больше, то всё-таки придётся разбивать выгрузки не на дни, а уже на часы.
Удаление статистики. С этим, конечно, опять проблемы. Документация уверяет, что эффективнее удалять записи из базы данных массово, а не по одной. При попытке просто удалить всё что меньше заданной даты неизменно получался timeout. Причём когда я проверял эту процедуру на сравнимых объёмах локально, она медленно, но работала. Пришлось переписать процедуру удаления по одной записи. За отведённые на время выполнения скрипта 30 секунд удалялось по 400-600 записей. Я переписал процедуру ещё раз и стал удалять записи по 100 штук, это вроде бы процесс ускорило, разбираться что именно там случилось уже не было сил. Удаляет и ладно, приёмов в 10 всё получилось.
Часть вторая: «хабраэффект?»
На эту тему уже было несколько статей, например вот статья именно про GAE, но на java и там просто отдаётся картинка, а у меня то полнофункциональный проект.
В общем, особо эффектом я бы это дело тоже не называл: в пике нагрузка составила 4 запроса в секунду. На протяжении не более часа нагрузка была около двух запросов в секунду, после чего стабильно падала, это всё видно из графиков.
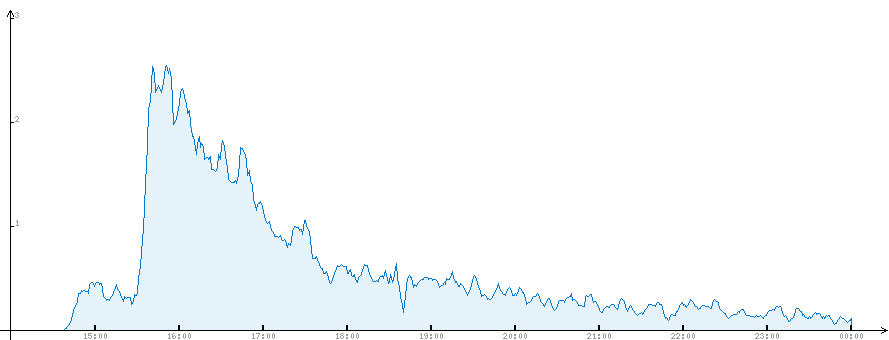
Полная статистика. Пиковой нагрузки в 4 запроса здесь не видно из-за усреднения.
Время — московское, пост опубликован в 14:40, очевидно примерно через час он вышел на главную. GAE время хранит в GMT, я преобразование выполнял уже на этапе рисования графиков, хотя можно было бы и при загрузке csv-файлов, пожалуй.
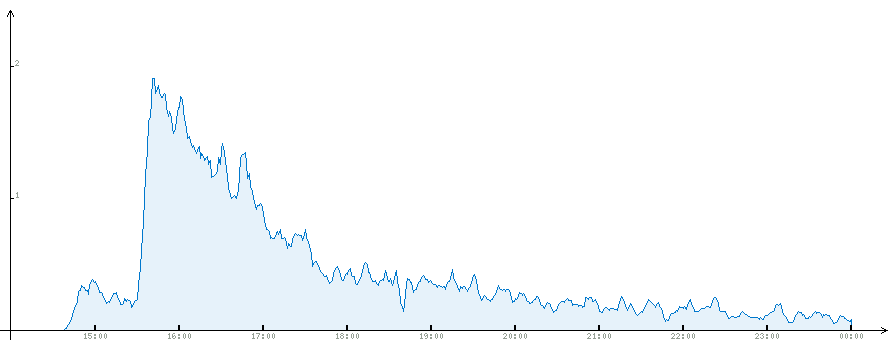
Отдельно статистика по главной странице.

Статистика по хабра-игре.

Статистика на следующий день: к 11 утра основная масса людей дочитывает до второй страницы хабраленты.

Административный интерфейс GAE. Здесь же видно и израсходованные ресурсы, скриншоты сделаны часов через 10 после публикации поста. Мне мои рисунки нравятся больше.
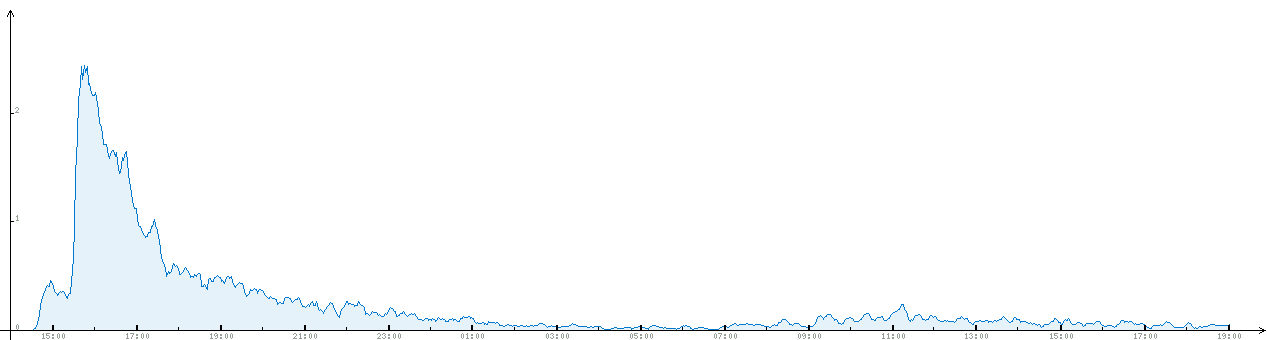
Ещё есть статистика за два дня, можно оценить масштаб.
Следует отметить, что никакой оптимизацией я вообще не занимался. То есть при каждом запросе всё что можно (всякие подписи, заголовки, названия и описания, все слова для игр) выбиралось из базы данных, разве что искусственных пустых циклов не расставил. Сделано так во-первых из-за лени, во-вторых чтобы посмотреть что получится. В итоге израсходовано примерно 70% ресурсов, которые GAE предоставляет бесплатно. Узким местом оказался CPU, от всех остальных ресурсов было израсходовано по 1-2%. Кроме того, было получено несколько ошибок вида timeout при обращении к базе данных, поэтому большая часть работы с базой данных позже была перенесена на memcach.
Ещё немного статистики
После поста порядка 150-ти человек попробовали посмотреть на административный интерфейс, было создано 90 игр, почти 30 из них непустые и штук 15 вполне себе с осмысленным содержимым, их авторам – привет.
Всего зашло человек (по ip адресам): 6814
Загрузили более одной страницы: 3573 или 52%
Загрузили более двух страниц: 2334, 34%
Более десяти: 215, 3%
Выводы
Работать с большими объёмами данных в GAE не очень удобно, но вполне можно. Для реальной работы придётся написать скрипты, которые по расписанию будут выгружать статистику, автоматизировано её проверять на корректность и после этого инициализировать очистку выгруженного на стороне GAE. То есть это всё приводит к довольно заметным накладным расходам и создаёт вполне определённые, но преодалимые трудности.
Дальше описание особенностей работы со статистикой в GAE и во второй части графики про полученную нагрузку: собственные и те, которые формирует google. Постарался написать так, чтобы было понятно и тем, кто с GAE вообще не сталкивался.
Часть первая: статистика
GAE, конечно, показывает собственные графики, но есть ряд вопросов:
- посмотреть их через какое-то время становится невозможно, графики доступны только за последние сутки;
- представление данных фиксировано и не настраивается;
- нет возможности построить график по каким-то своим условиям, в случае bullshitbingo мне интересно было бы посмотреть отдельно разные игры.
Проблема: GAE принципиально не умеет возвращать больше 1000 записей. Связано это с нереляционной моделью данных, и, возможно, кому-то это совсем не мешает, но при работе со статистикой мешает и сильно. Ещё одно соображение: строить какие-то сложные запросы и что-то вычислять прямо на стороне GAE может оказаться очень накладно, за процессорное время и хранение больших объёмов данных придётся платить. Так как статистика это, вообще говоря, «мёртвые» данные, не необходимые для функционирования, то её вполне можно забирать с серверов GAE куда-то себе, и уже там обрабатывать. Даже удобнее. Поэтому было решено выгружать статистику в виде csv-файлов и работать с ней уже как-то локально.
Выгрузка данных
Выгрузить данных это отдельная задача, потому что выбирать записи со смещением GAE тоже не умеет. Вернее умеет, но реализуется это фактически на стороне клиента (приложения, а не http-клиента, конечно). То есть, когда я хочу получить 10 записей начиная с 100-й, то сделать это можно, и для этого даже есть соответствующий параметр у вызова fetch(), но по факту из базы будут извлечены все 110 записей, просто первые сто API оставит себе. То есть просто так получить 100 записей начиная с 1000-й вообще нельзя никак. Об этом даже написано в документации, но как-то несколько туманно.
Выйти из положения можно если в качестве смещения использовать не номер строки, как я привык в реляционных БД, а дату/время. Время в GAE хранится аж с шестью знаками после запятой, так что вероятность внесения нескольких записей с абсолютно одинаковым временем крайне мала. Строго говоря, можно создать искусственное уникальное поле с монотонно возрастающими значениями, но такой необходимости я не вижу.
Всю статистику можно отсортировать по дате и выбирать по 1000 штук, каждый раз запоминая до какой даты удалось добраться, и в следующий раз отступать уже от неё. После того, как статистику гарантированно удалось выгрузить, её можно удалять. Дальше я эти фрагменты по 1000 записей называю страницами. Можно выбрать и другое число, но 1000 оказалась ничем не хуже, скажем 100, так что я остановился на 1000.
Скрипт выгрузки статистики в качестве параметра принимает максимальную дату (именно дату, без времени), до которой требуется выдать данные. На это есть две причины:
1) статистика поступает постоянно, но данные «за вчера и ранее» уже не изменятся;
2) выгружать сразу всю статистику может просто не получиться из-за большого объёма данных и ограничений на время выполнения, а так будет возможность выгружать хоть по одному дню.
Таким образом, алгоритм крупными мазками получился следующий:
- выбрать 1000 самых старых записей при помощи примерно такого запроса: SELECT * FROM request where date < $date order by date limit 1000;
- по каждой строке сформировать csv-запись;
- запомнить $last_date — максимальная полученная дата;
- выполнить запрос, дополнив его условием с $last_date: SELECT * FROM request where date < $date and date >= $last_date order by date limit 1000;
- пока результат запроса непустой goto 2.
При сравнении с $last_date используется «нестрого больше» потому что теоретически возможность точного совпадения времени у двух разных запросов всё-таки существует. Чтобы строки на стыке страниц не дублировались нужно сверить их уникальные ключи (а GAE такой ключ генерирует для любых хранимых в БД объектов) и опустить строку, если она уже была выгружена.
В случае с bullshitbingo данные за день, в который я опубликовал пост на хабре, выгрузились за 20 с небольшим секунд, то есть на грани фола. Если данных будет немного больше, то всё-таки придётся разбивать выгрузки не на дни, а уже на часы.
Удаление статистики. С этим, конечно, опять проблемы. Документация уверяет, что эффективнее удалять записи из базы данных массово, а не по одной. При попытке просто удалить всё что меньше заданной даты неизменно получался timeout. Причём когда я проверял эту процедуру на сравнимых объёмах локально, она медленно, но работала. Пришлось переписать процедуру удаления по одной записи. За отведённые на время выполнения скрипта 30 секунд удалялось по 400-600 записей. Я переписал процедуру ещё раз и стал удалять записи по 100 штук, это вроде бы процесс ускорило, разбираться что именно там случилось уже не было сил. Удаляет и ладно, приёмов в 10 всё получилось.
Часть вторая: «хабраэффект?»
На эту тему уже было несколько статей, например вот статья именно про GAE, но на java и там просто отдаётся картинка, а у меня то полнофункциональный проект.
В общем, особо эффектом я бы это дело тоже не называл: в пике нагрузка составила 4 запроса в секунду. На протяжении не более часа нагрузка была около двух запросов в секунду, после чего стабильно падала, это всё видно из графиков.
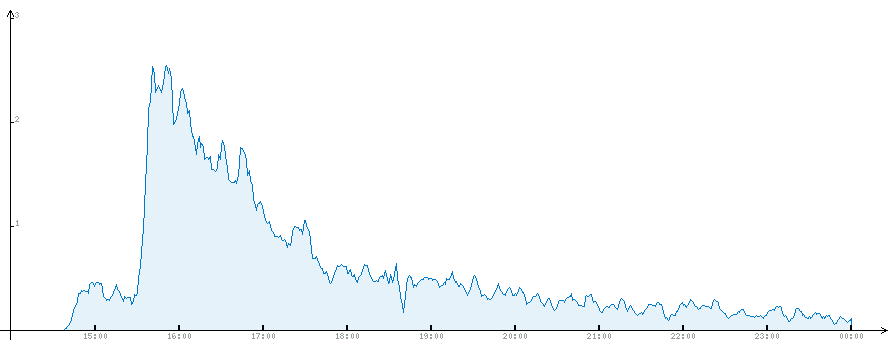
Полная статистика. Пиковой нагрузки в 4 запроса здесь не видно из-за усреднения.
Время — московское, пост опубликован в 14:40, очевидно примерно через час он вышел на главную. GAE время хранит в GMT, я преобразование выполнял уже на этапе рисования графиков, хотя можно было бы и при загрузке csv-файлов, пожалуй.

Отдельно статистика по главной странице.

Статистика по хабра-игре.

Статистика на следующий день: к 11 утра основная масса людей дочитывает до второй страницы хабраленты.

Административный интерфейс GAE. Здесь же видно и израсходованные ресурсы, скриншоты сделаны часов через 10 после публикации поста. Мне мои рисунки нравятся больше.
Ещё есть статистика за два дня, можно оценить масштаб.
Следует отметить, что никакой оптимизацией я вообще не занимался. То есть при каждом запросе всё что можно (всякие подписи, заголовки, названия и описания, все слова для игр) выбиралось из базы данных, разве что искусственных пустых циклов не расставил. Сделано так во-первых из-за лени, во-вторых чтобы посмотреть что получится. В итоге израсходовано примерно 70% ресурсов, которые GAE предоставляет бесплатно. Узким местом оказался CPU, от всех остальных ресурсов было израсходовано по 1-2%. Кроме того, было получено несколько ошибок вида timeout при обращении к базе данных, поэтому большая часть работы с базой данных позже была перенесена на memcach.
Ещё немного статистики
После поста порядка 150-ти человек попробовали посмотреть на административный интерфейс, было создано 90 игр, почти 30 из них непустые и штук 15 вполне себе с осмысленным содержимым, их авторам – привет.
Всего зашло человек (по ip адресам): 6814
Загрузили более одной страницы: 3573 или 52%
Загрузили более двух страниц: 2334, 34%
Более десяти: 215, 3%
Выводы
Работать с большими объёмами данных в GAE не очень удобно, но вполне можно. Для реальной работы придётся написать скрипты, которые по расписанию будут выгружать статистику, автоматизировано её проверять на корректность и после этого инициализировать очистку выгруженного на стороне GAE. То есть это всё приводит к довольно заметным накладным расходам и создаёт вполне определённые, но преодалимые трудности.

{kind=link}