В предыдущем посте про JMeter я описывал создание примитивного нагрузочного теста. При разработке более сложных сценариев не обойтись без отладки. К сожалению, в JMeter эта техника не совсем очевидна. Ниже на несложном примере покажу несколько приемов отладки тест-плана. Заодно продемонстрирую использование таких элементов, как HTTP Request Defaults, Regular Expression Extractor, If Controller и некоторых других.
Тестировать будем механизм поиска на сайте. Пускай сценарий берет слово или фразу из файла, задает вопрос поисковику, получает ответ в виде одной или нескольких страниц, случайным образом выбирает одну из страниц, так же случайно выбирает одну из ссылок и идет по ней. Итого три запроса, за исключением особых случаев (когда найдено мало или не найдено ничего).
Понеслась.
Запустим GUI JMeter и для порядка переименуем предлагаемый пустой тест-план (Test plan) в Search test (вообще сегодня постараюсь вести себя культурно и, в частности, уделять время внятному именованию элементов сценария, это помогает). Правой кнопкой наступим на элемент Search test в дереве слева и, сказав Add->Config element->HTTP Request Defaults, забьем туда адрес сервера:
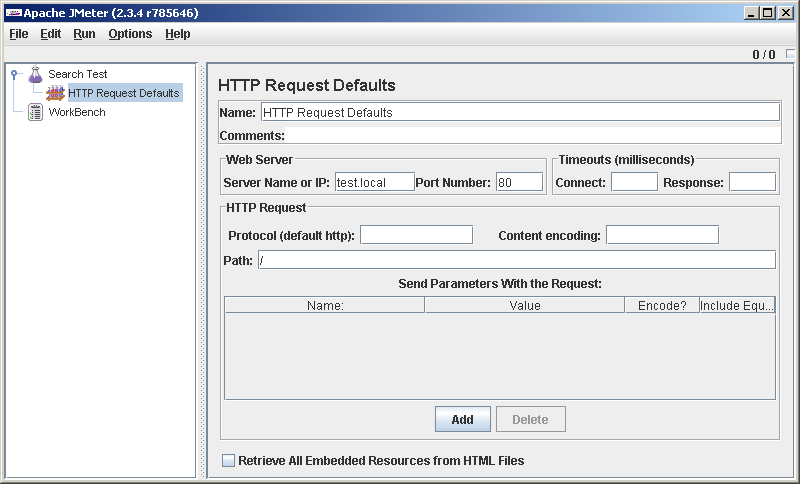
Я завел HTTP Request Defaults, чтобы не вписывать адрес сервера в каждый запрос. А когда его надо будет поменять? Избежим дублирования. Я собирался вести себя культурно, вот и стараюсь.
Search Test->Add->Thread Group. Здесь пока оставим все по умолчанию.
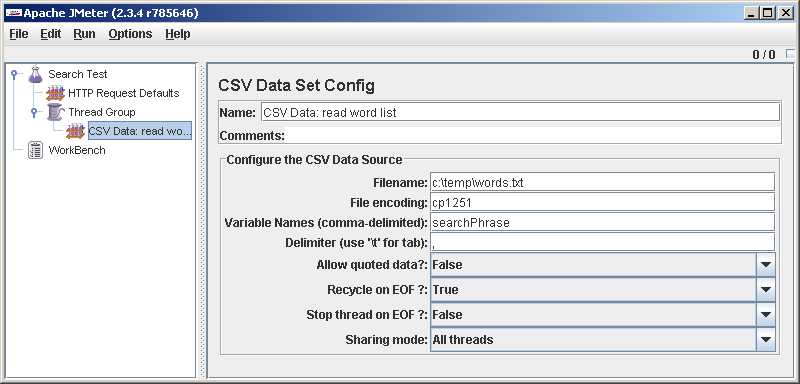
Thread Group->Add->Config Element->CVS Data Set Config. С помощью этого элемента будем читать из файла наши слова, в каждой строке по запросу.
Между прочим, у нас уже есть, что отлаживать. Сценарий пока никуда не ходит, но уже читает что-то из файла и кладет в переменную (я ее назвал searchPhrase). Чем раньше начнем тестировать, тем здоровее будем. Давайте добавлять элементы для отладки.
Thread Group->Add->Sampler->Debug Sampler.
Thread Group->Add->Listener->View Results Tree. Тут и там оставляем все настройки по умолчанию.
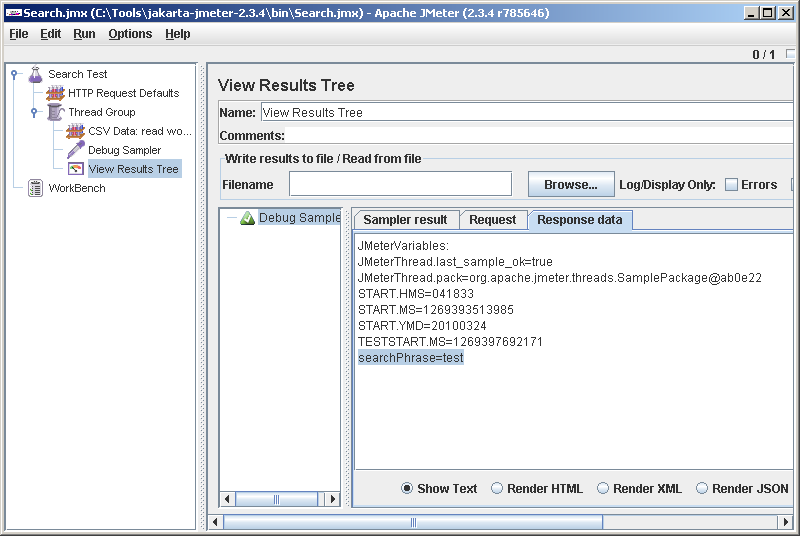
Сохраняемся (File->Save), запускаемся (Run->Clear All, Run->Start). Смотрим во View Results Tree и видим, что сценарий, как нам и хотелось, выполнился один раз. Кликаем на единственный результат в Results Tree (Debug Sampler) и переходим в третью закладку Response data. В последней строчке видим: searchPhrase=test. Как раз у меня в первой строчке файла со словами написано test. Ура, оно как-то работает.
Попробуем теперь подправить сценарий так, чтобы он пробегал весь файл со словами и завершался. Для этого в свойствах
Проверяем. File->Save, Run->Clear All, Run->Start. Видим, что цикл выполнился 17 раз, по числу строчек у меня в файле. Чудесно.
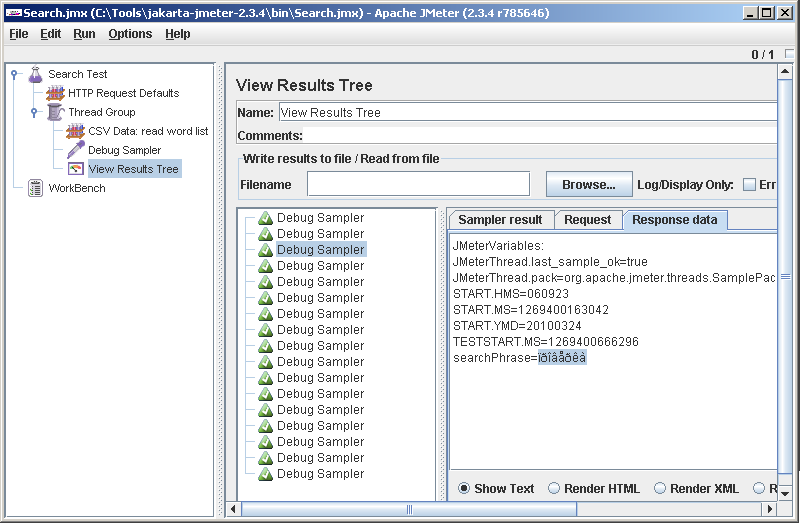
Несколько омрачает радость то, что кириллицу JMeter отображает криво. Забегая вперед скажу, что читает он ее на самом деле нормально и в запрос пишет то, что надо, так что с этим косяком можно смириться. В старых версиях он русские имена элементов не понимал, потом починили, наверно и этот починят со временем.
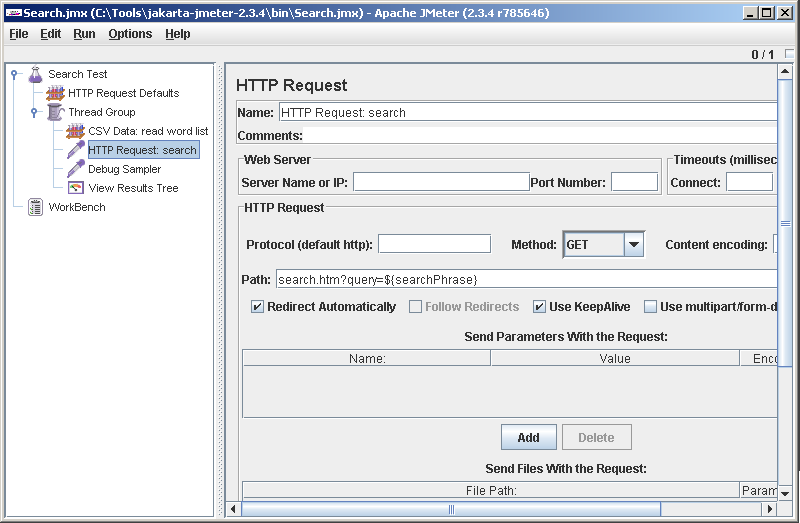
Добавляем HTTP запрос. Обратите внимание на синтаксис, как мы обращаемся к нашей переменной, в которую прочиталась фраза: ${searchPhrase}. Поле Server Name or IP пустое — значение подставляется из HTTP Request Defaults. Запрос переименуем в HTTP Request: search (у нас будет несколько запросов и путать их между собой неправильно).
Пробуем. Опаньки, ошибка!
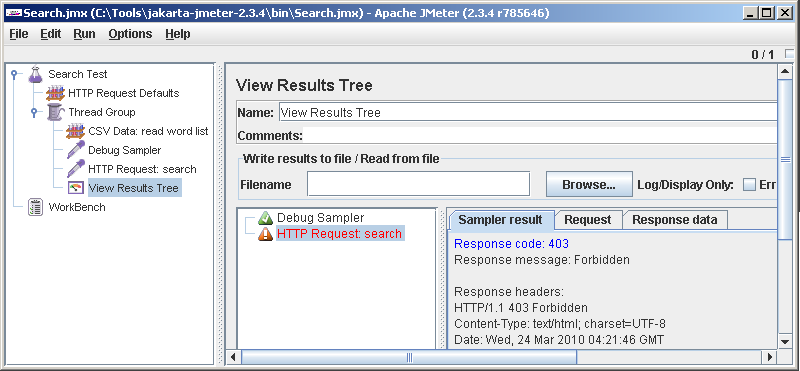
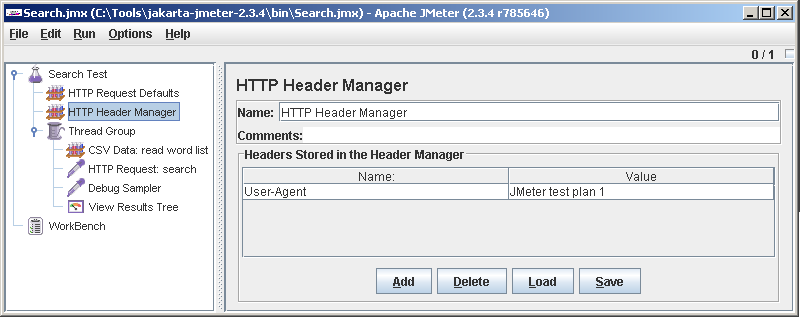
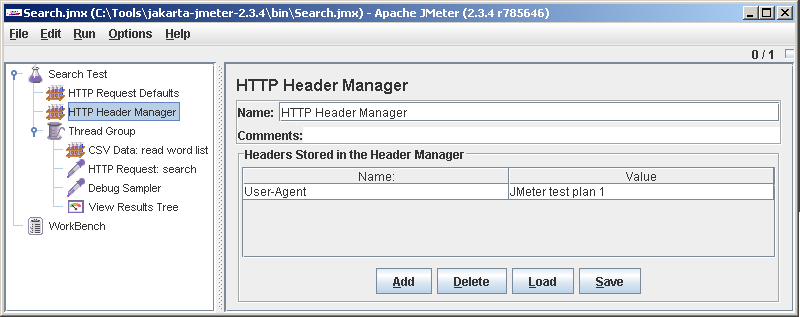
Мы же отлаживаемся, куда ж без ошибок. Почитав внимательно ответ сервера, вспоминаем, что ему нужен заголовок User-Agent. Легко. Добавляем под Search test еще один элемент: HTTP Header Manager. Видно, что по умолчанию никаких заголовков JMeter не передает. Жмем Add и добавляем User-Agent.
Пробуем. На этот раз все прошло гладко. HTTP Request: search в дереве результатов позеленел. Наступив на него, можно рассмотреть детали: в закладке Sampler result — заголовки ответа сервера, Request — URL и заголовок HTTP, который мы добавили, а в Response data — тело респонса.
Вспомним, что мы хотели, получив ответ, если он состоит из нескольких страниц, выбрать случайную страницу, и уже с нее взять ссылку на документ. Идем парсить респонс и добывать из него ссылку на страницу. На HTTP Request: search говорим Add->Post Processors->Regular Expression Extractor. Начнем с малого: попробуем выцепить из страницы конкретную ссылку. Из полученного чуть выше ответа сервера возьмем ссылку на страницу и вставим ее в поле Regular Expression. Возвращаемую переменную назовем pageLink (звучит лучше, чем var1 или reResult).
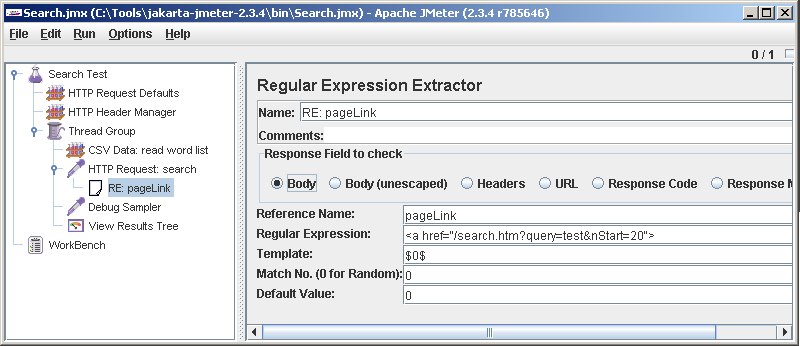
по результатам исполнения мы ожидаем, что в переменную у нас попадет ровно это самое <a href="/search.htm?query=test&nStart=20">.
Пробуем. \File->Save, Run->Clear All, Run->Start.
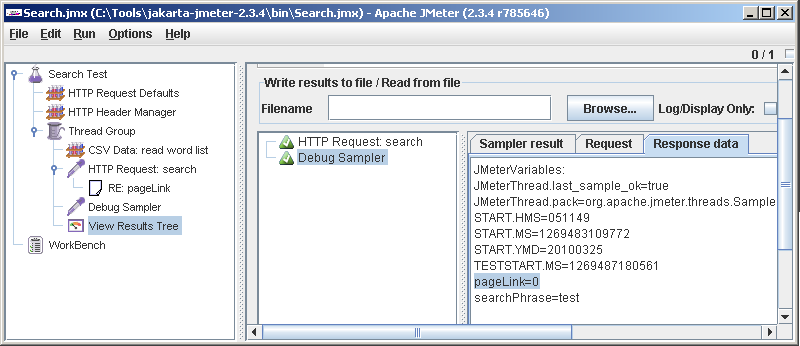
Э… А почему pageLink=0? Потому что регексп не нашелся. Почему не нашелся? Потому что вопросительный знак надо эскейпить, вот почему!Бивис, ты баклан
Тогда так: <a href="/search.htm\?query=test&nStart=20">.
Совсем другое дело. Теперь в результатах:
Доводим регексп до ума:
Меняем Template на $1$ — мы будем забирать себе первую группу. Выделять группы 2 и 3 — ([^&]*), ([^"]*) — совсем необязательно, можно и без скобок. Просто не всем так везет, как нам сегодня, и часто приходится брать не готовый URL, а конструировать его из кусков, и тут как раз использовать Template очень удобно, например, можно написать туда
После выполнения получаем:
Честно говоря, отладка регулярных выражений для JMeter — отдельная песня и порой отнимает очень много времени. Мануал справедливо советует для их отладки сделать отдельный тест-план и подгружать страницу из локального файла, чтоб не мучить удаленный сервер и не терять время. Иногда регекспы в JMeter ведут себя странно, например, выражение, которое прекрасно работает в Notepad++ может ничего не находить в JMeter. Пишут, что движок — Apach Jakarta ORO. Надо будет почитать при случае.
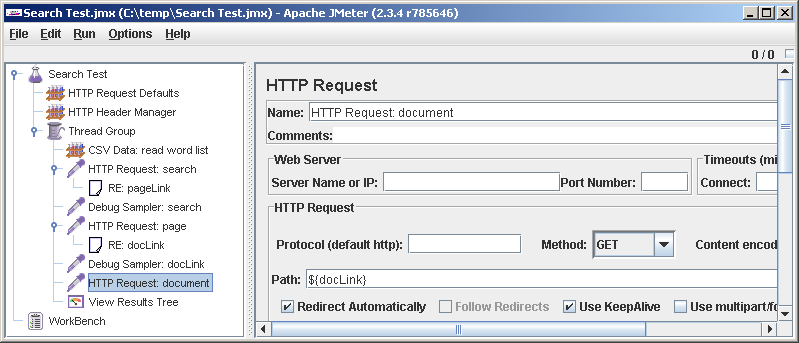
Добавляем в тест-план второй HTTP-запрос и парсим его результат. В форме HTTP Request все оставляем по умолчанию, только в поле Path прописываем
Наконец добавляем последний запрос — обращение к найденному документу. Поскольку его результат парсить мы не собираемся, то и Debug Sampler после него не ставим, он нам ничего нового не покажет.
Еще немного доработаем тест-план. Если в результатах поиска у нас будет всего одна страница или вообще ничего, JMeter пойдет на какой-то небывалый URL вроде
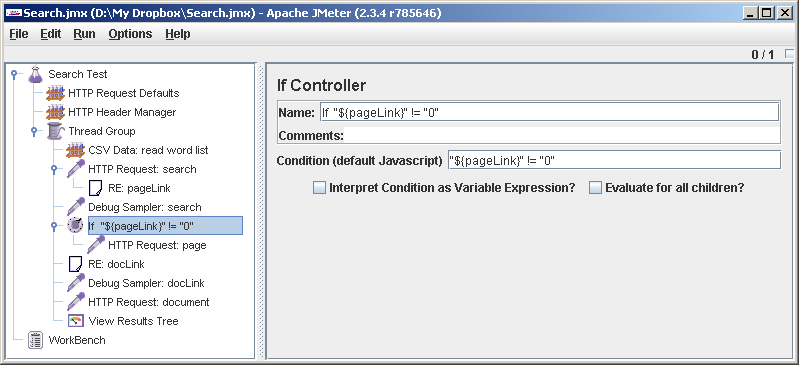
Получается вот что. Респонс, с которым работают пост-процессоры (в том числе Regular Expression Extractor) — глобальный для потока. Если If Controller сказал «нет» и
В нашем файле со списком слов портим первое слово так, чтобы оно точно не нашлось. Пробуем: работает. Во View Results Tree
Надо постепенно закругляться. Вокруг последнего HTTP запроса If Controller разводить не будем. В качестве последних штрихов добавим после каждого запроса случайную задержку в размере 0-30 с (для реалистичности), а в конец тест-плана — листенеры Summary Report и Graph Results.
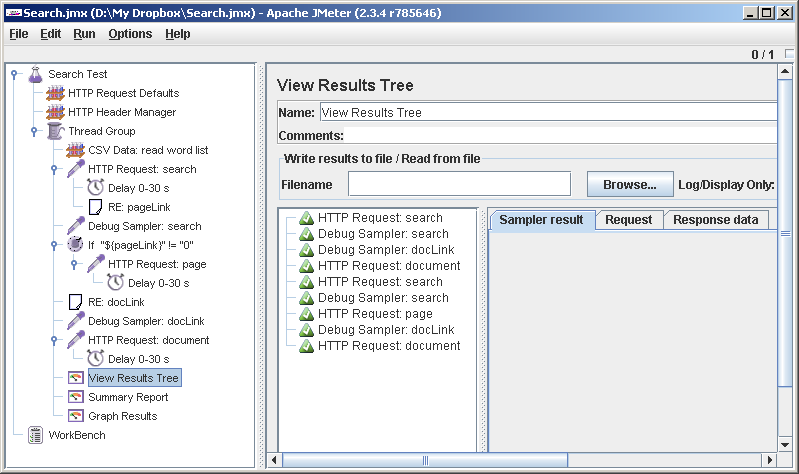
Ну вот, логику выполнения мы отладили. Можно приступать к тестированию, но это уже другой разговор.
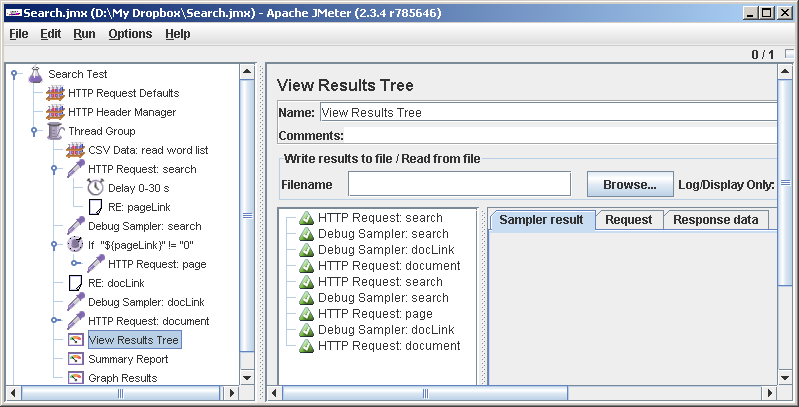
Единственно: прежде чем начинать гонять тест на всю катушку, желательно отключить элементы отладки, в том числе, в том числе View Results Tree, поскольку они изрядно тормозят:
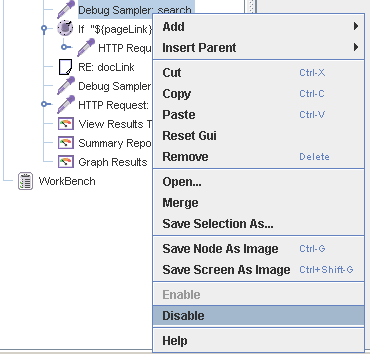
На всякий случай напомню: прежде чем долбить продуктивный сервер, особенно чужой, стоит еще раз подумать, все ли мы делаем правильно. А то случаи всякие бывают.
Удачи!
P.S.
Окружение:
Apache Jmeter 2.3.4
java full version «1.6.0_13-b03»
Windows Vista Home
P.P.S. Вот неплохая статья про отладку тест-планов, но просит регистрации:
Tips for debugging your JMeter tests
Тестировать будем механизм поиска на сайте. Пускай сценарий берет слово или фразу из файла, задает вопрос поисковику, получает ответ в виде одной или нескольких страниц, случайным образом выбирает одну из страниц, так же случайно выбирает одну из ссылок и идет по ней. Итого три запроса, за исключением особых случаев (когда найдено мало или не найдено ничего).
Понеслась.
Запустим GUI JMeter и для порядка переименуем предлагаемый пустой тест-план (Test plan) в Search test (вообще сегодня постараюсь вести себя культурно и, в частности, уделять время внятному именованию элементов сценария, это помогает). Правой кнопкой наступим на элемент Search test в дереве слева и, сказав Add->Config element->HTTP Request Defaults, забьем туда адрес сервера:
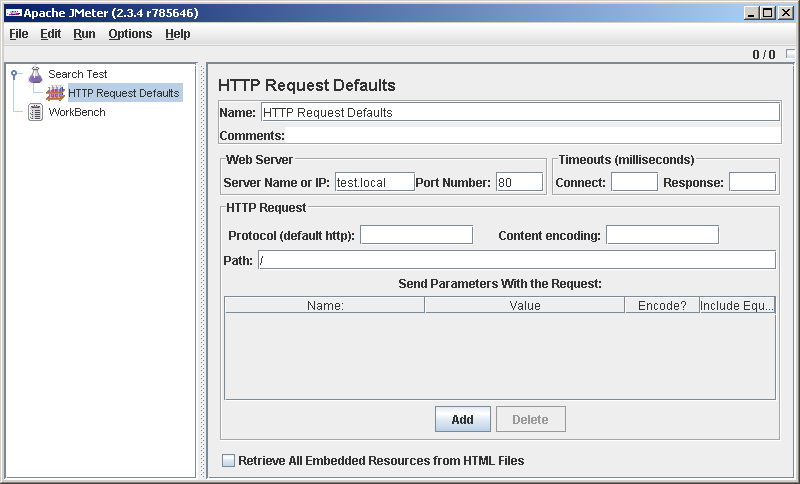
Я завел HTTP Request Defaults, чтобы не вписывать адрес сервера в каждый запрос. А когда его надо будет поменять? Избежим дублирования. Я собирался вести себя культурно, вот и стараюсь.
Search Test->Add->Thread Group. Здесь пока оставим все по умолчанию.
Thread Group->Add->Config Element->CVS Data Set Config. С помощью этого элемента будем читать из файла наши слова, в каждой строке по запросу.
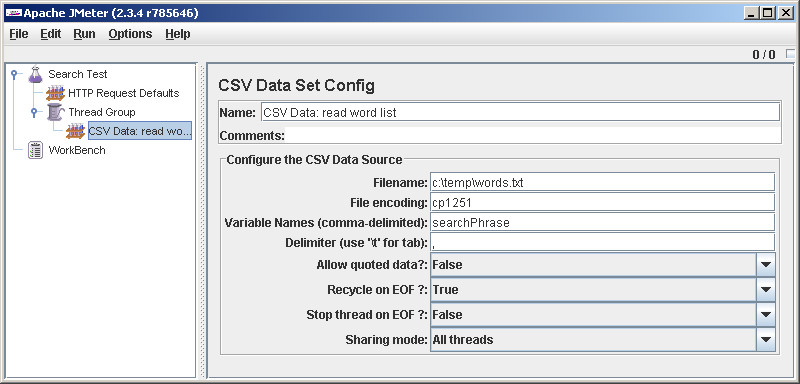
Между прочим, у нас уже есть, что отлаживать. Сценарий пока никуда не ходит, но уже читает что-то из файла и кладет в переменную (я ее назвал searchPhrase). Чем раньше начнем тестировать, тем здоровее будем. Давайте добавлять элементы для отладки.
Thread Group->Add->Sampler->Debug Sampler.
Thread Group->Add->Listener->View Results Tree. Тут и там оставляем все настройки по умолчанию.
Сохраняемся (File->Save), запускаемся (Run->Clear All, Run->Start). Смотрим во View Results Tree и видим, что сценарий, как нам и хотелось, выполнился один раз. Кликаем на единственный результат в Results Tree (Debug Sampler) и переходим в третью закладку Response data. В последней строчке видим: searchPhrase=test. Как раз у меня в первой строчке файла со словами написано test. Ура, оно как-то работает.

Попробуем теперь подправить сценарий так, чтобы он пробегал весь файл со словами и завершался. Для этого в свойствах
Thread Group ставим Loop Count: Forever, а для CSV Data: read word list Recycle on EOF?=False, Stop thread on EOF?=True.Проверяем. File->Save, Run->Clear All, Run->Start. Видим, что цикл выполнился 17 раз, по числу строчек у меня в файле. Чудесно.
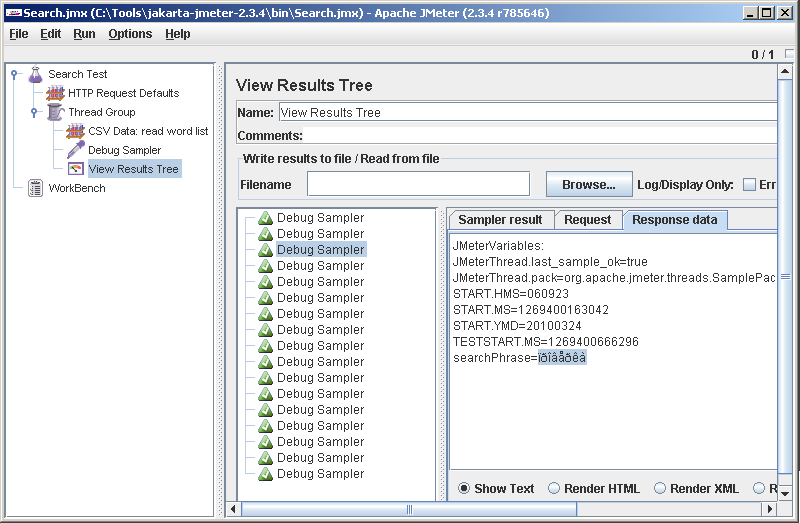
Несколько омрачает радость то, что кириллицу JMeter отображает криво. Забегая вперед скажу, что читает он ее на самом деле нормально и в запрос пишет то, что надо, так что с этим косяком можно смириться. В старых версиях он русские имена элементов не понимал, потом починили, наверно и этот починят со временем.
Добавляем HTTP запрос. Обратите внимание на синтаксис, как мы обращаемся к нашей переменной, в которую прочиталась фраза: ${searchPhrase}. Поле Server Name or IP пустое — значение подставляется из HTTP Request Defaults. Запрос переименуем в HTTP Request: search (у нас будет несколько запросов и путать их между собой неправильно).
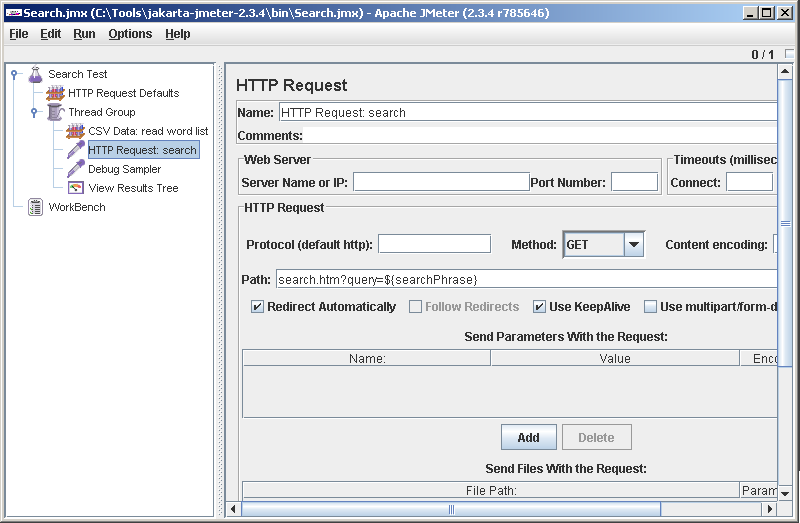
Пробуем. Опаньки, ошибка!

Мы же отлаживаемся, куда ж без ошибок. Почитав внимательно ответ сервера, вспоминаем, что ему нужен заголовок User-Agent. Легко. Добавляем под Search test еще один элемент: HTTP Header Manager. Видно, что по умолчанию никаких заголовков JMeter не передает. Жмем Add и добавляем User-Agent.
Пробуем. На этот раз все прошло гладко. HTTP Request: search в дереве результатов позеленел. Наступив на него, можно рассмотреть детали: в закладке Sampler result — заголовки ответа сервера, Request — URL и заголовок HTTP, который мы добавили, а в Response data — тело респонса.
Вспомним, что мы хотели, получив ответ, если он состоит из нескольких страниц, выбрать случайную страницу, и уже с нее взять ссылку на документ. Идем парсить респонс и добывать из него ссылку на страницу. На HTTP Request: search говорим Add->Post Processors->Regular Expression Extractor. Начнем с малого: попробуем выцепить из страницы конкретную ссылку. Из полученного чуть выше ответа сервера возьмем ссылку на страницу и вставим ее в поле Regular Expression. Возвращаемую переменную назовем pageLink (звучит лучше, чем var1 или reResult).

по результатам исполнения мы ожидаем, что в переменную у нас попадет ровно это самое <a href="/search.htm?query=test&nStart=20">.
Пробуем. \File->Save, Run->Clear All, Run->Start.

Э… А почему pageLink=0? Потому что регексп не нашелся. Почему не нашелся? Потому что вопросительный знак надо эскейпить, вот почему!
Тогда так: <a href="/search.htm\?query=test&nStart=20">.
Совсем другое дело. Теперь в результатах:
pageLink=<a href="/search.htm?query=test&nStart=20">
pageLink_g=0
pageLink_g0=<a href="/search.htm?query=test&nStart=20">
searchPhrase=testДоводим регексп до ума:
<a href="/(search.htm\?query=([^&]*)&nStart=([^"]*))">.Меняем Template на $1$ — мы будем забирать себе первую группу. Выделять группы 2 и 3 — ([^&]*), ([^"]*) — совсем необязательно, можно и без скобок. Просто не всем так везет, как нам сегодня, и часто приходится брать не готовый URL, а конструировать его из кусков, и тут как раз использовать Template очень удобно, например, можно написать туда
find.pl?text=$1$&start=$2$. В результате в переменной pageLink у нас окажется собранный URL.После выполнения получаем:
pageLink=<a href="/search.htm?query=test&nStart=20">
pageLink_g=3
pageLink_g0=<a href="/search.htm?query=test&nStart=20">
pageLink_g1=search.htm?query=test&nStart=20
pageLink_g2=test
pageLink_g3=20
searchPhrase=testЧестно говоря, отладка регулярных выражений для JMeter — отдельная песня и порой отнимает очень много времени. Мануал справедливо советует для их отладки сделать отдельный тест-план и подгружать страницу из локального файла, чтоб не мучить удаленный сервер и не терять время. Иногда регекспы в JMeter ведут себя странно, например, выражение, которое прекрасно работает в Notepad++ может ничего не находить в JMeter. Пишут, что движок — Apach Jakarta ORO. Надо будет почитать при случае.
Добавляем в тест-план второй HTTP-запрос и парсим его результат. В форме HTTP Request все оставляем по умолчанию, только в поле Path прописываем
${pageLink}. Мы договорились со второй страницы поиска уйти на документ. Регексп, соответственно, будет другой: <p class="r"> <a href="([^"]+)">. После запроса и Regular Expression Extractor добавляем Debug Samlper. Конечно, даем всем элементам уникальные и осмысленные имена. Отлаживаемся. Наконец добавляем последний запрос — обращение к найденному документу. Поскольку его результат парсить мы не собираемся, то и Debug Sampler после него не ставим, он нам ничего нового не покажет.
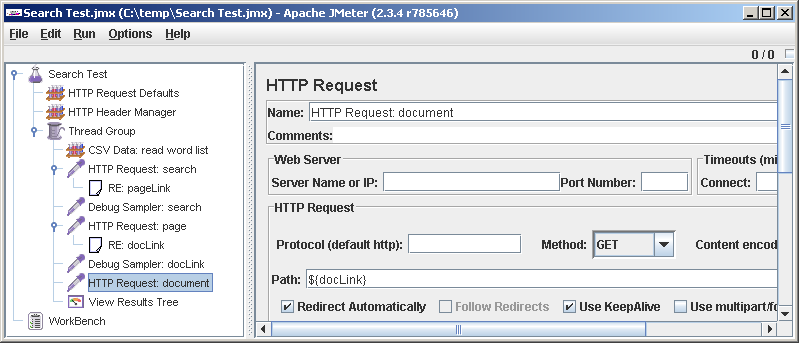
Еще немного доработаем тест-план. Если в результатах поиска у нас будет всего одна страница или вообще ничего, JMeter пойдет на какой-то небывалый URL вроде
http://0, и может на нас обидеться. Чтобы такого не происходило, добавим проверку. Thread Group->Add->Logic Controller->If Controller. В поле Condition прописываем "${pageLink}" != "0". Для ясности переименовываем контроллер (ясность лишней не бывает). Теперь перетаскиваем его, ставим после Debug Sampler: page. Затаскиваем HTTP Request: page под If Controller. Теперь внимание: вытаскиваем RE: docLink из-под HTTP Request: page и ставим его после If Controller-а. 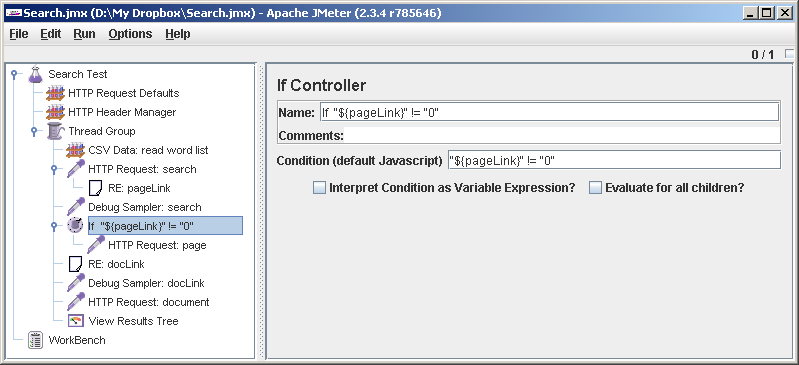
Получается вот что. Респонс, с которым работают пост-процессоры (в том числе Regular Expression Extractor) — глобальный для потока. Если If Controller сказал «нет» и
HTTP Request: page не выполнился, RE: docLink разберет респонс, оставшийся после первого HTTP-запроса. То, что я раньше делал Regular Expression Extractor потомком HTTP Request, особого смысла не несет, важно лишь, чтобы он шел позже (но мне кажется, так план выглядит понятнее, если пост-процессор стоит потомком сэмплера).В нашем файле со списком слов портим первое слово так, чтобы оно точно не нашлось. Пробуем: работает. Во View Results Tree
HTTP Request: page не появилось, а HTTP Request: document дал ошибку. Ну, может быть, не с первого раза работает. Даже скорее всего не с первого. Я, например, сначала написал ${pageLink} != "0", и это условие всегда давало False, а с кавычками все сработало, как надо. Надо постепенно закругляться. Вокруг последнего HTTP запроса If Controller разводить не будем. В качестве последних штрихов добавим после каждого запроса случайную задержку в размере 0-30 с (для реалистичности), а в конец тест-плана — листенеры Summary Report и Graph Results.

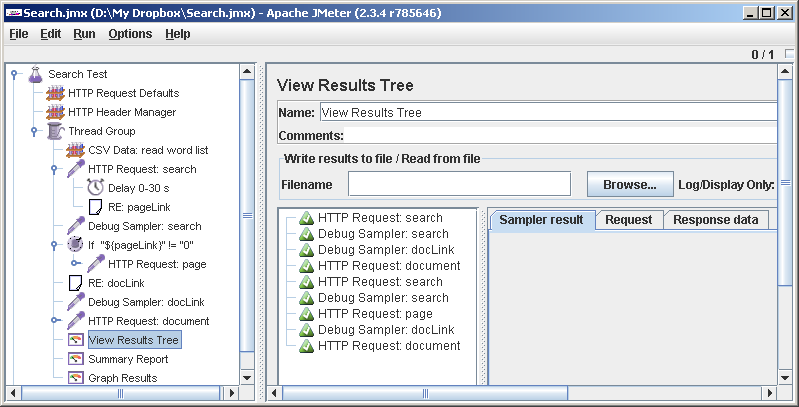
Ну вот, логику выполнения мы отладили. Можно приступать к тестированию, но это уже другой разговор.
Единственно: прежде чем начинать гонять тест на всю катушку, желательно отключить элементы отладки, в том числе, в том числе View Results Tree, поскольку они изрядно тормозят:
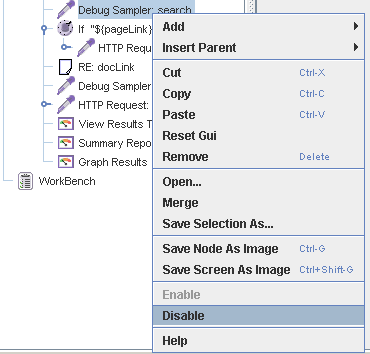
На всякий случай напомню: прежде чем долбить продуктивный сервер, особенно чужой, стоит еще раз подумать, все ли мы делаем правильно. А то случаи всякие бывают.
Удачи!
P.S.
Окружение:
Apache Jmeter 2.3.4
java full version «1.6.0_13-b03»
Windows Vista Home
P.P.S. Вот неплохая статья про отладку тест-планов, но просит регистрации:
Tips for debugging your JMeter tests
