Компания у нас на full-remote, поэтому заседание кружка параноиков мы проводим как-то так. Иногда под банджо в углу.
В жизни любого проекта наступает катастрофа. Мы не можем заранее знать, что именно это будет - короткое замыкание в серверной, инженер, дропнувший центральную БД или нашествие бобров. Тем не менее, оно обязательно случится, причем по предельно идиотской причине.
Насчет бобров, я, кстати, не шутил. В Канаде они перегрызли кабель и оставили целый район Tumbler Ridge без оптоволоконной связи. Причем, животные, как мне кажется, делают все для того, чтобы внезапно лишить вас доступа к вашим ресурсам:
Макаки жуют провода. Цикады принимают кабели за ветки, и расковыривают их, чтобы отложить внутрь яйца. Акулы жуют трансатлантические кабели Google. А в топе источника проблем для крупной телекоммуникационной компании Level 3 Communications вообще были белки.
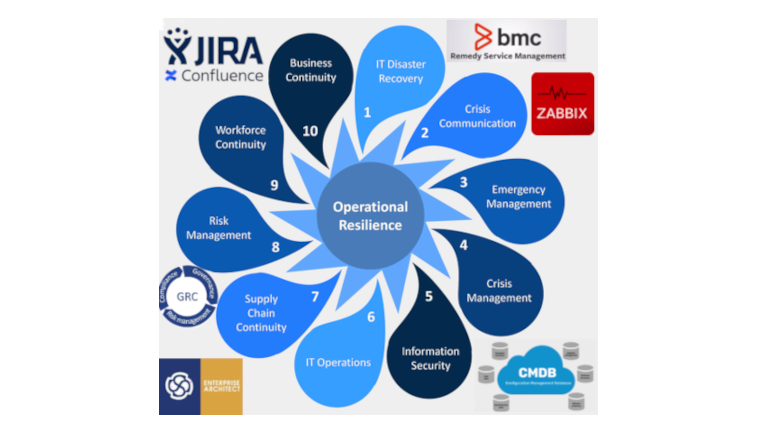
Короче, рано или поздно, кто-то обязательно что-то сломает, уронит, или зальет неверный конфиг в самый неподходящий момент. И вот тут появляется то, что отличает компании, которые успешно переживают фатальную аварию от тех, кто бегает кругами и пытается восстановить рассыпавшуюся инфраструктуру - DRP. Вот о том, как правильно написать Disaster Recovery Plan я сегодня вам и расскажу.